网页抓取 & 自定义提取
使用 CSS Path、XPath 和正则表达式从页面的 HTML 中抓取任何数据,以增强爬取功能,例如作者姓名、评论、分享等。
使用 SEO Spider 进行网页抓取和数据提取
本教程将引导您了解如何使用 Screaming Frog SEO Spider 的自定义提取功能从网站抓取数据。
自定义提取功能允许您使用 XPath、CSSPath 和正则表达式从网页的 HTML 中抓取任何数据。您可以从原始 HTML 或渲染的 HTML 中提取数据(如果启用了 JavaScript 渲染 模式)。
通过以下链接跳转到我们的视频演练或示例:
要开始使用,您需要下载并安装 SEO Spider 软件,并拥有许可证才能访问抓取所需的自定义提取功能。
打开 SEO Spider 后,开始提取数据的后续步骤如下:
1) 点击 ‘Configuration > Custom > Custom Extraction’
此菜单位于 SEO Spider 的顶级菜单中。
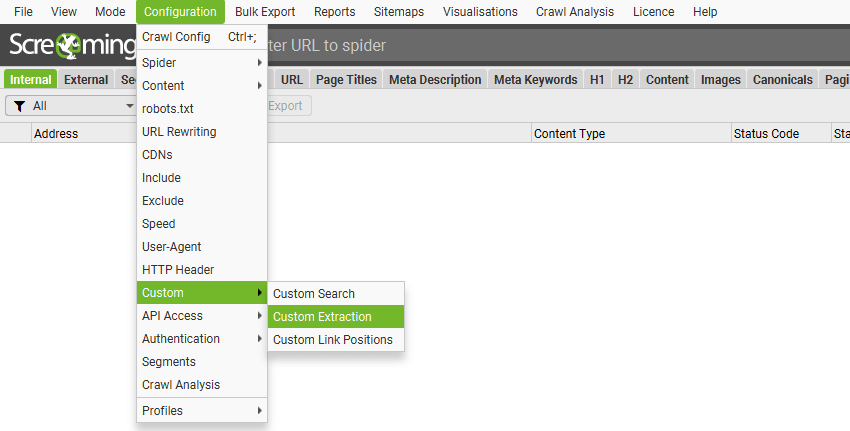
这将打开自定义提取配置�,您可以在其中配置多达 100 个独立的“提取器”。
2) 添加提取器
单击右下角的“Add”以设置提取器并开始抓取数据。
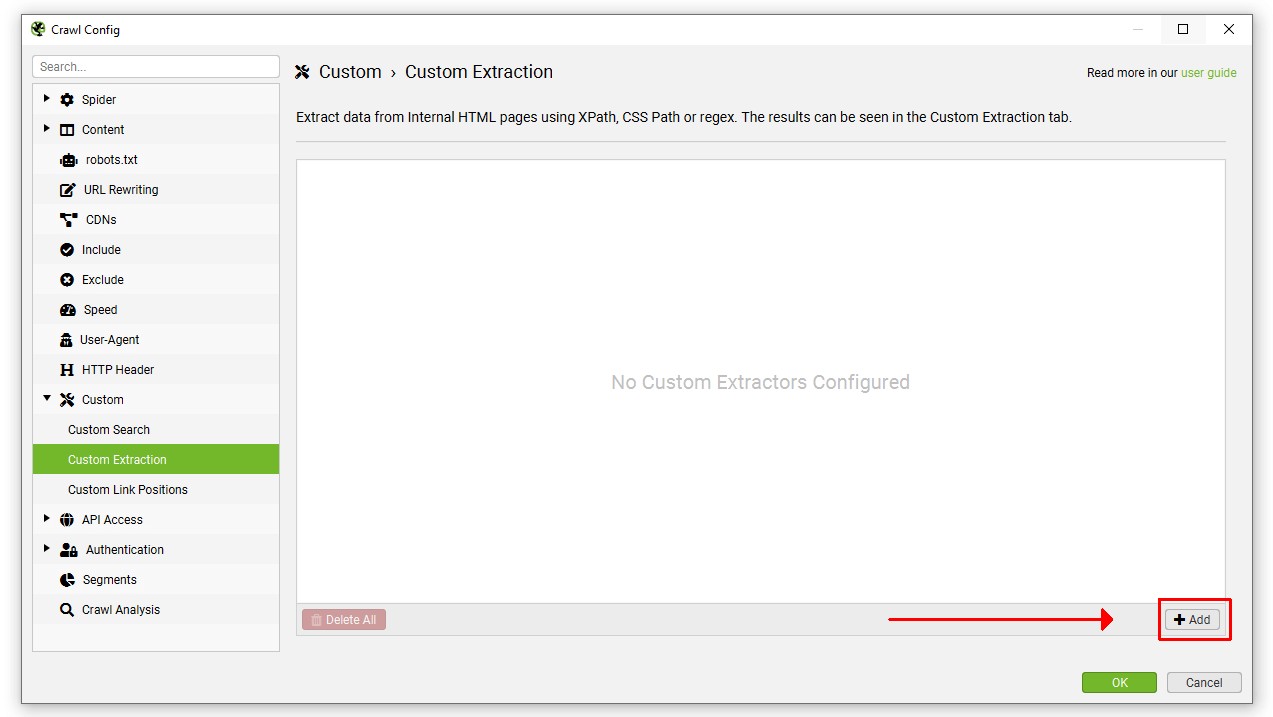
3) 输入您的表达式
Screaming Frog SEO Spider 允许您通过使用内置浏览器并选择要提取的元素,或手动设置提取器来从网站抓取数据。
可视化自定义提取
要使用可视化自定义提取,请单击提取器旁边的“browser”图标。

这将打开我们的可视化自定义提取内置浏览器。在 URL 栏中输入您要从中提取数据的 URL。
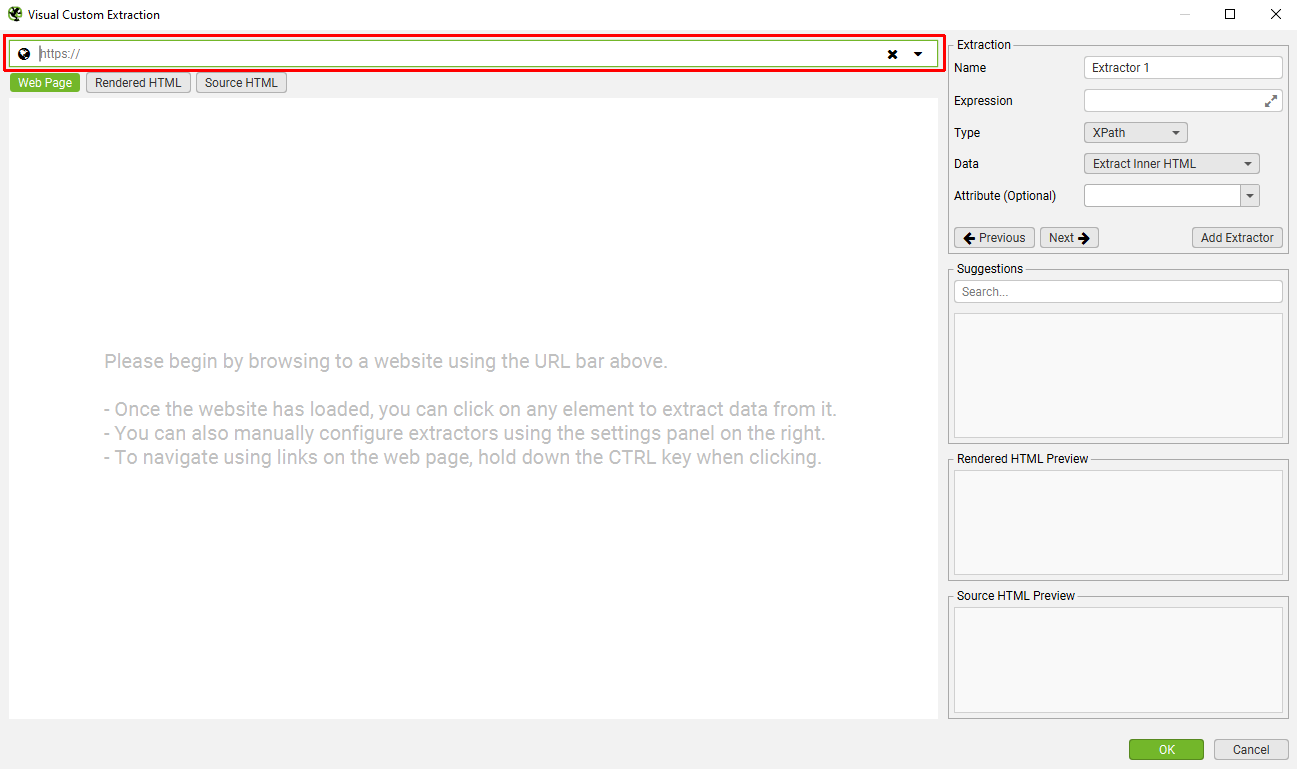
接下来,选择页面上您要抓取的元素。
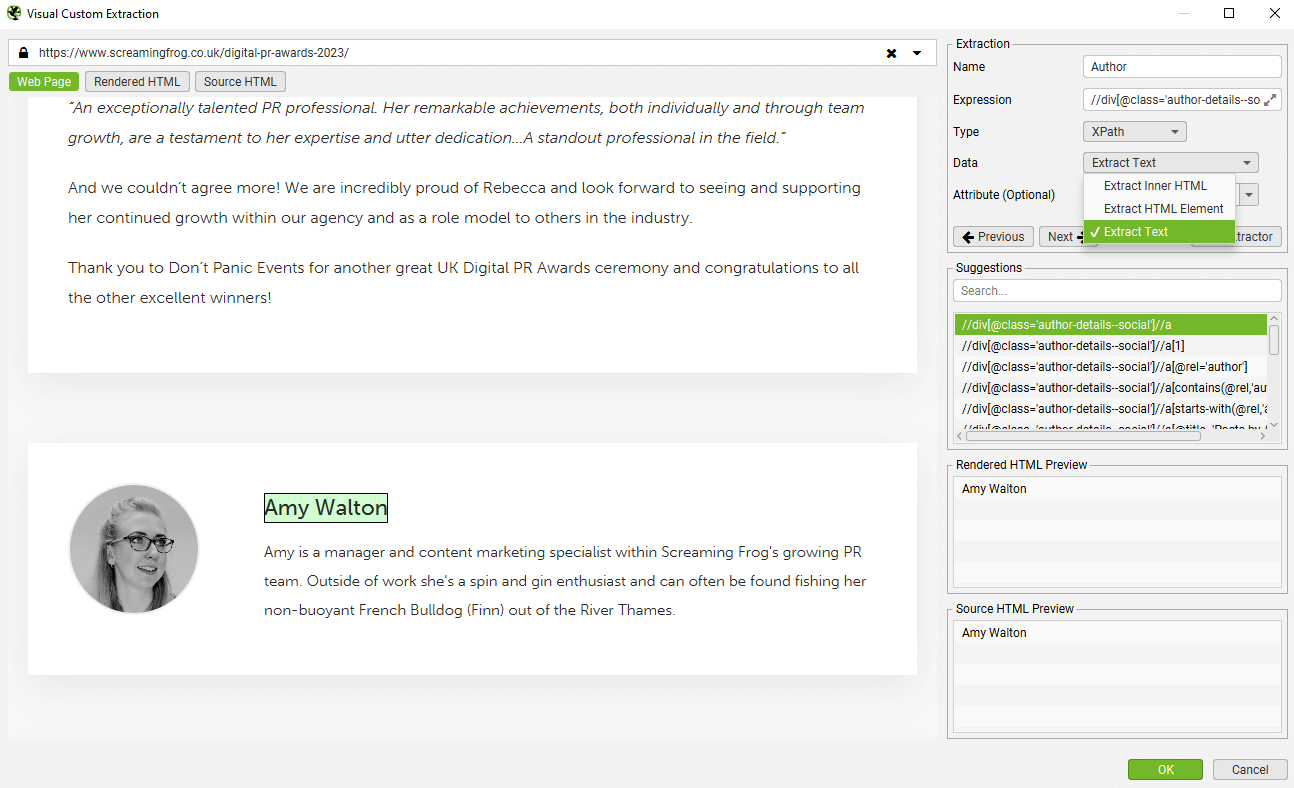
然后,SEO Spider 将突出显示页面上的区域,并创建各种建议�的表达式,以及基于原始或渲染的 HTML 将提取的内容的预览。在本例中,是从博客文章中提取作者姓名。
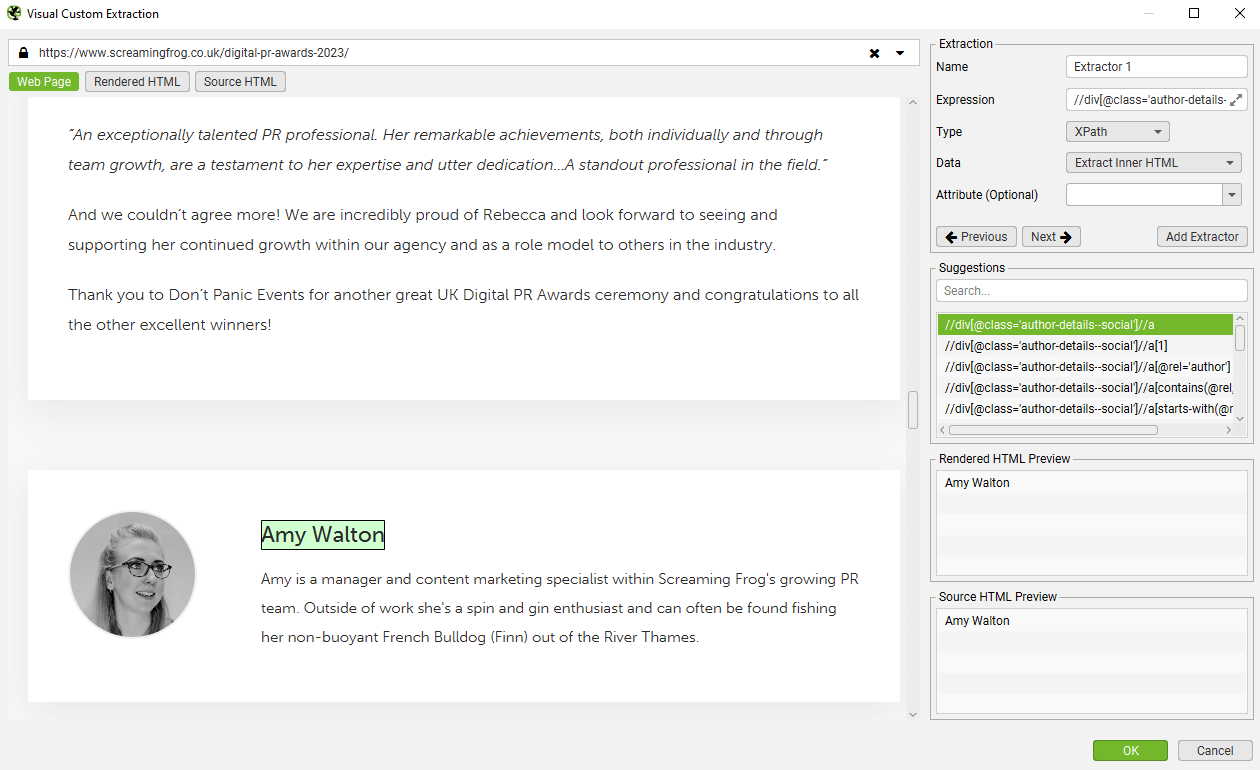
如果该元素仅出现在“Rendered HMTL Preview”中,而不出现在“Source HTML Preview”中,则它很可能依赖于 JavaScript。这意味着您需要使用 JavaScript 渲染 模式来抓取数据。
提示!
要在可视化自定义提取浏览器中导航到另一个页面,请按住 control 键并单击链接。
当使用 XPath 或 CSS Path 收集 HTML 时,您可以使用“data”下拉列表选择要提取的内容 –
- Extract HTML Element – 所选元素及其所有内部 HTML 内容。
- Extract Inner HTML – 所选元素的内部 HTML 内容。如果所选元素包含其他 HTML 元素,它们将被包括在内。
- Extract Text – 所选元素的文本内容以及任何子元素的文本内容。
- Function Value – 提供函数的返回值,例如 count(//h1) 来查找页面上 h1 标签的数量。
在本例中,它是作者文本,因此选择了“Extract Text”。提取器的“name”字段也可以更新,该字段对应于列名 – 在本例中为“Author”。
单击“OK”以设置提取器并关闭可视化自定义提取浏览器,或单击“Add Extractor”以设置提取器并保持可视化自定义提取浏览器打开以设置另一个提取器。
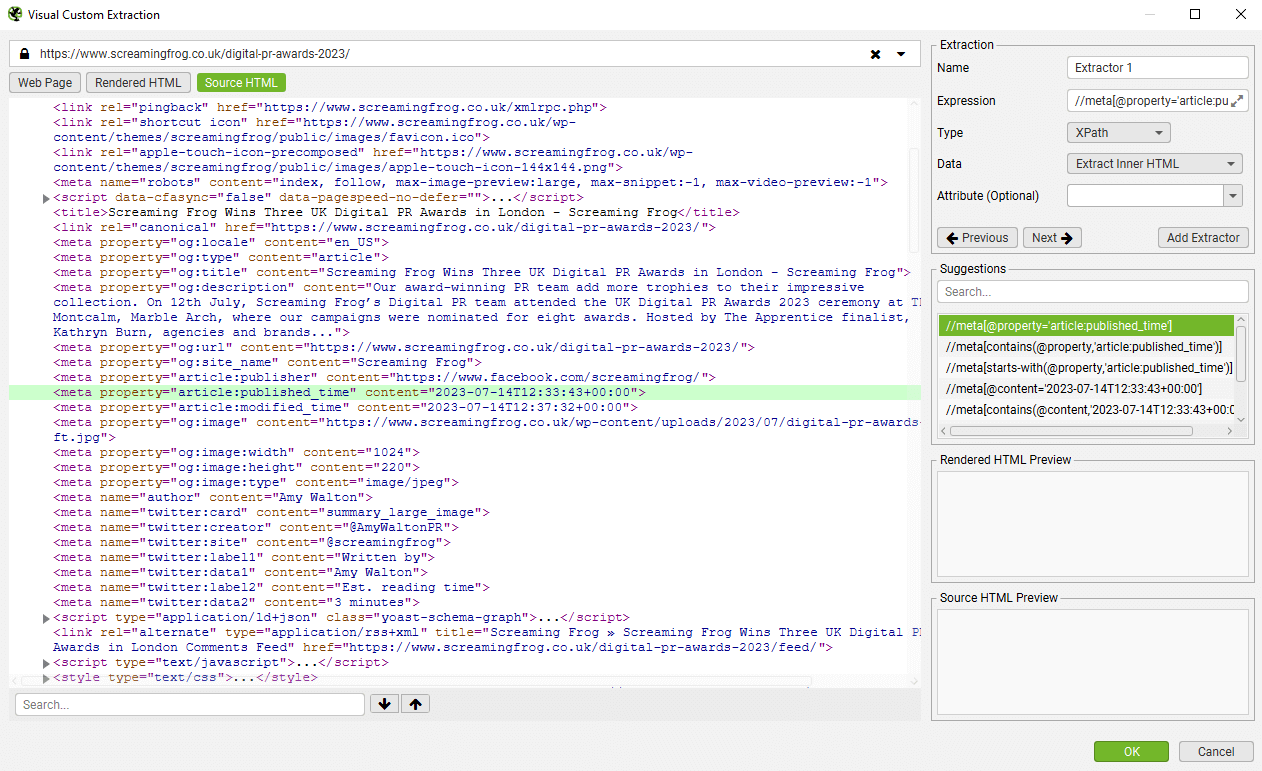
如果该元素不在页面上,您可以切换到 Rendered 或 Source HTML 视图并选择一行 HTML。例如,如果您希望提取 HTML 头部中 meta 属性标签的“content” –
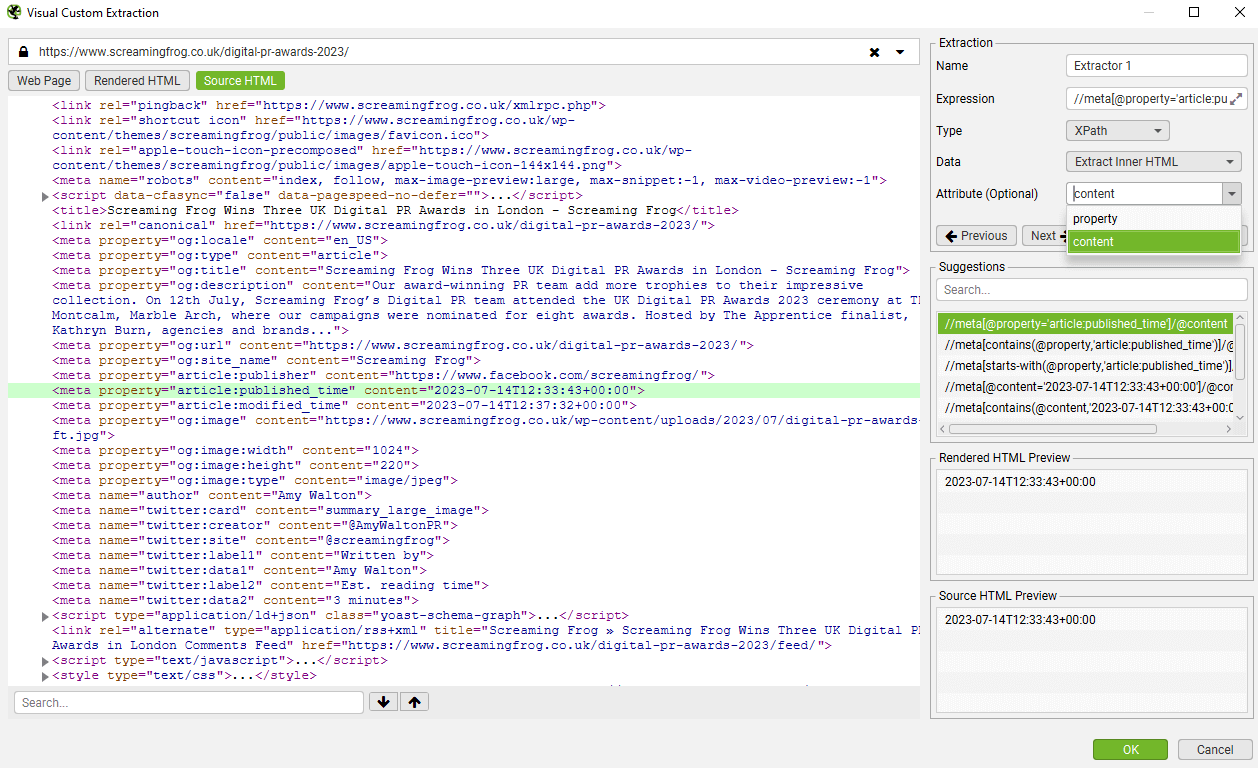
然后,您可以从下拉列表中选择要提取的属性,它将为您制定表达式。
在下面的示例中,它将抓取发布时间,在选择“content”属性后,该时间会显示在源和渲染的 HTML 预览中。
对于那些使用可视化自定义提取的人来说,这就是此步骤的结尾。
手动自定义提取
对于已经掌握 XPath、CSSPath 和正则表达式的用户,您可以手动输入您的表达式。有 3 种提取数据的方法:
- XPath – XPath 是一种查询语言,用于从类似 XML 的文档(如 HTML)中选择节点。此选项允许您通过使用 XPath 选择器(包括属性)来抓取数据。
- CSSPath – 在 CSS 中,选择器是用于选择元素的模式,通常是三种可用方法中最快的。此选项允许您通过使用 CSS Path 选择器来抓取数据。还提供了一个可选的属性字段。
- Regex – 正则表达式当然��是一个特殊的文本字符串,用于匹配数据中的模式。这最适合高级用途,例如抓取 HTML 注释或内联 JavaScript。
建议在大多数常见场景中使用 CSSPath 或 XPath,尽管两者都有其优点,但您可以简单地选择您最习惯使用的选项。对于不属于 HTML 元素的任何内容(例如在代码中找到的任何 JSON),都需要使用 Regex。
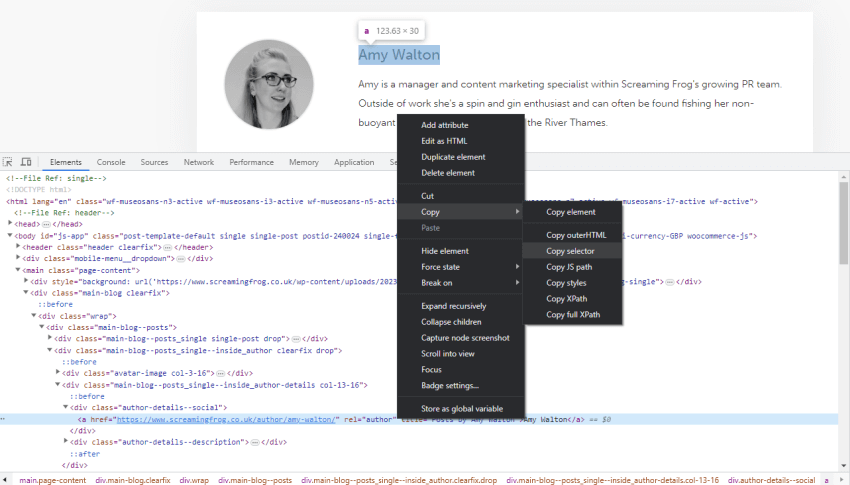
您可以使用浏览器(例如 Chrome),右键单击“inspect element”,然后将提供的 XPath 或 Selector 复制到提取器字段中。
然后重命名“extractors”,它们对应于 SEO Spider 中的列名。
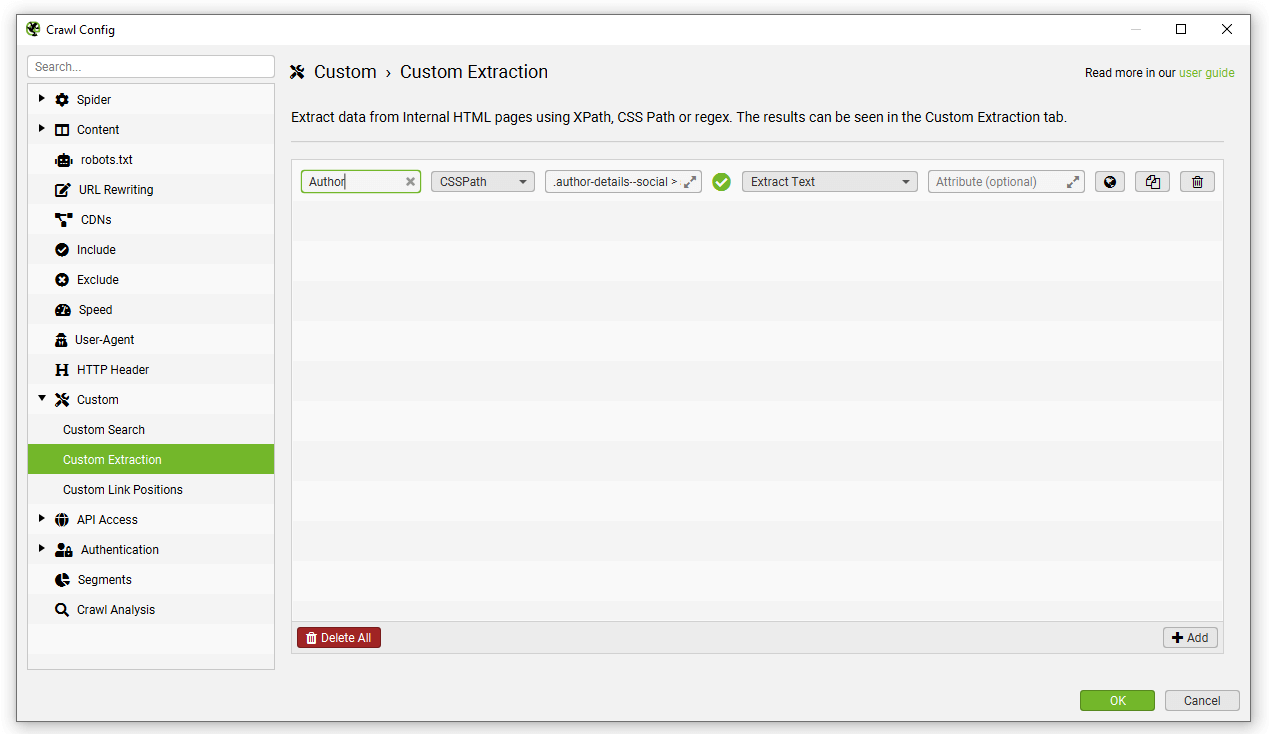
每个提取器旁边的勾号确认使用的语法有效。如果它们旁边有一个红色叉号,那么您可能需要稍微调整一下,因为它们无效。
如果您满意,只需按下底部的“OK”按钮即可。如果您想查看更多示例,请跳到本指南的底部。
注意事项
直接从浏览器复制表达式并不是构建 CSS 选择器和 XPath 表达式的最可靠方法。
使用此方法提供的表达式可能特定于元素在代码中的确切位置。这可能会发生变化,因为检查的视图是 JavaScript 处理后页面的渲染版本。默认情况下,SEO Spider 从 HTML 源代码中提取,除非启用了 JavaScript 渲染模式。
不同的浏览器可以提供不同的表达式,并且当 SEO Spider 处理存在无效标记的页面时,也可能会发生各种 HTML 清理。
w3schools 上关于 CSS 选择器 和他们的 XPath 介绍 是理解这些表达式基础知识的良好资源。
4) 爬取网站
将网站地址输入到 URL 栏中,然后单击“start”以爬取网站并开始抓取。

可以在右上角的进度条中看到爬取的进度,但您不必等到爬取完成后才能查看数据。
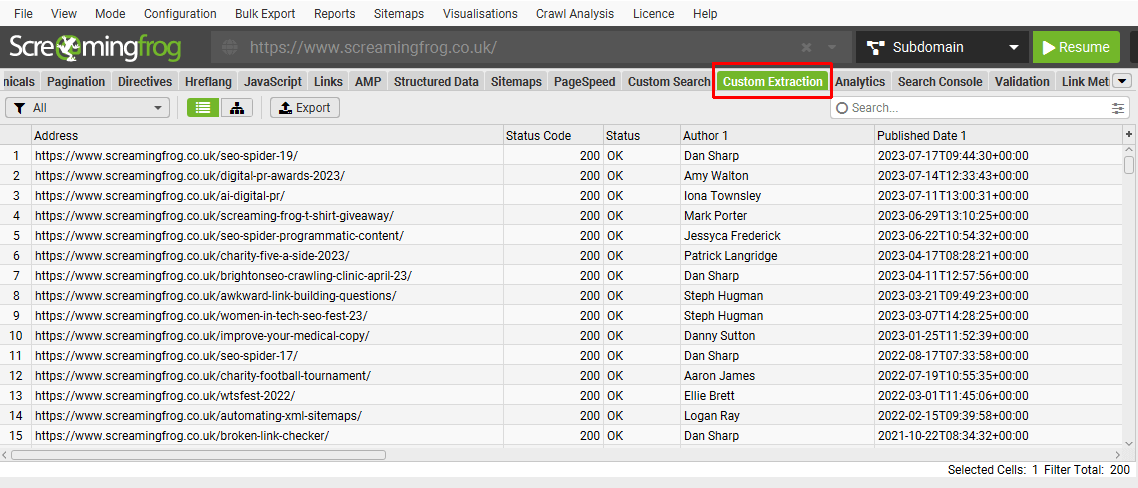
5) 在自定义提取选项卡下查看抓取的数据
抓取的数据在爬取期间实时出现在“Custom Extraction”选项卡下,以及“Internal”选项卡下,允许您将收集到的所有内容一起导出到电子表格中。
在上面概述的示例中,我们可以看到每个博客文章旁边的抓取的作者姓名和发布日期。
当进度条达到“100%”时,爬取已完成,您可以选择使用选项卡上的“export”按钮“导出”数据。
如果您已经有一个要从中提取数据的 URL 列表,而不是爬取网站来收集数据,那么您可以使用 列表模式 上传它们。
就是这样!希望以上指南有助于说明如何使用 SEO Spider 软件进行网页抓取。
视频演练
观看我们关于如何设置自定义提取的快速视频教程。
XPath 示例
SEO 们喜欢 XPath!因此,下面是一个列表,其中包含您可以使用所需 XPath 提取的各种元素。SEO Spider 支持 XPath 版本 1.0、2.0、3.0 和 3.1。
跳转到特定的 XPath 提取示例:
标题
Hreflang
结构化数据
社交 Meta 标签(Open Graph 标签和 Twitter Cards)
移动注释
电子邮件地址
iframes
AMP URLs
Meta 新闻关键字
Meta Viewport 标签
仅提取正文中的链接
提取包含锚文本的链接
提取到特定域的链接
从特定 Div 中提取内容
提取多个匹配的元素
标题
默认情况下,SEO Spider 仅收集 h1 和 h2,但如果您想收集 h3,则 XPath 为 –
//h3
提取的数据 –
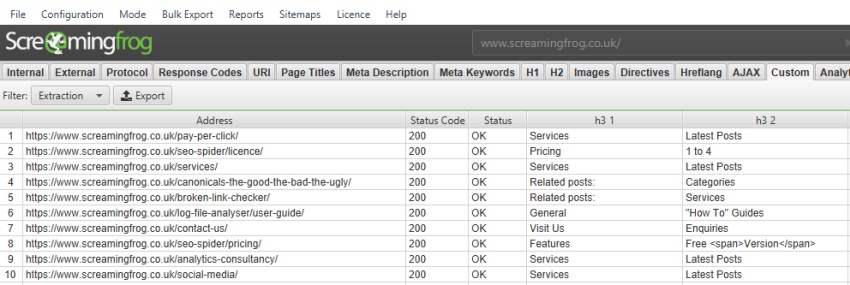
但是,您可能希望仅收集第一个 h3,尤其是在每个页面上有多个 h3 的情况下。XPath 为 –
/descendant::h3[1]
要收集页面上的前 10 个 h3,XPath 将为 –
/descendant::h3[position() >= 0 and position() <= 10]
要计算页面上 h3 标签的数量,所需的表达式为 –
count(//h3)
在这种情况下,必须将自定义提取窗口最右侧下拉列表中的“Extract Inner HTML”更改为“Function Value”,此表达式才能正确工作。
也可以使用 XPath 和“Function Value”选项计算任何提取字符串的长度。要计算页面上 h3 的长度,需要以下表达式 –
string-length(//h3)
Hreflang
以下 Xpath 与 Extract HTML Element 结合使用,将收集所有 hreflang 元素的内容 –
//*[@hreflang]
以上将收集整个 HTML 元素,包括链接和 hreflang 值。结果 –
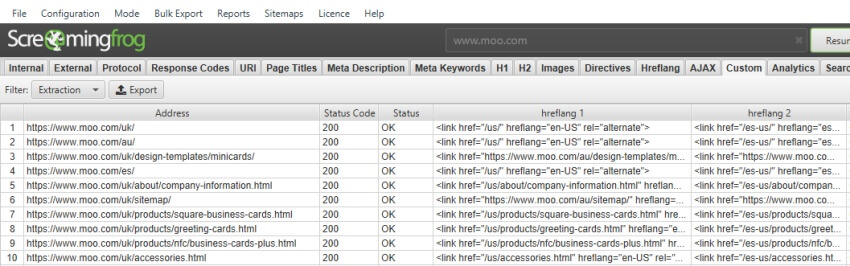
因此,也许您只想要 hreflang 值(如“en-GB”),您可以使用 @hreflang 指定属性。
//*[@hreflang]/@hreflang
提取的数据 –
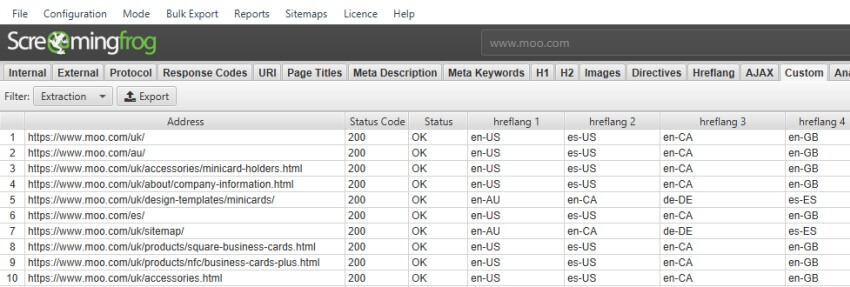
Hreflang 分析功能现在已作为标准内置于 SEO Spider 中,有关更多详细信息,请参阅 Hreflang 提取 和 Hreflang 选项卡。
结构化数据
您可能希望收集页面上各种 Schema 的类型,因此设置可能是 –
//*[@itemtype]/@itemtype
提取的数据 –
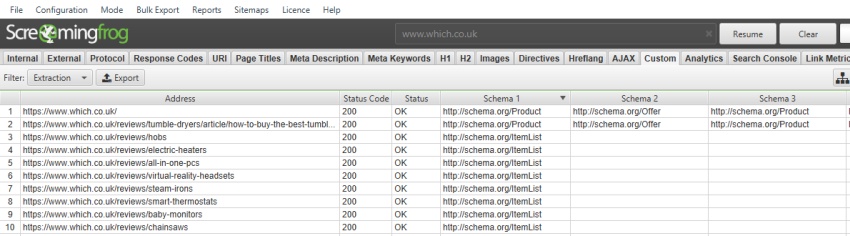
对于“itemprop”规则,您可以使用类似的 XPath –
//*[@itemprop]/@itemprop
不要忘记,SEO Spider 可以提取和验证结构化数据,而无需自定义提取。
社交 Meta 标签(Open Graph 标签和 Twitter Cards)
您可能希望提取社交 meta 标签,例如 Facebook Open Graph 标签、帐户详细信息或 Twitter Cards。例如,Xpath 是 –
//meta[starts-with(@property, 'og:title')]/@content //meta[starts-with(@property, 'og:description')]/@content //meta[starts-with(@property, 'og:type')]/@content //meta[starts-with(@property, 'og:site_name')]/@content //meta[starts-with(@property, 'og:image')]/@content //meta[starts-with(@property, 'og:url')]/@content //meta[starts-with(@property, 'fb:page_id')]/@content //meta[starts-with(@property, 'fb:admins')]/@content
//meta[starts-with(@name, 'twitter:title')]/@content //meta[starts-with(@name, 'twitter:description')]/@content //meta[starts-with(@name, 'twitter:account_id')]/@content //meta[starts-with(@name, 'twitter:card')]/@content //meta[starts-with(@name, 'twitter:image:src')]/@content //meta[starts-with(@name, 'twitter:creator')]/@content
等等。
提取的数据 –
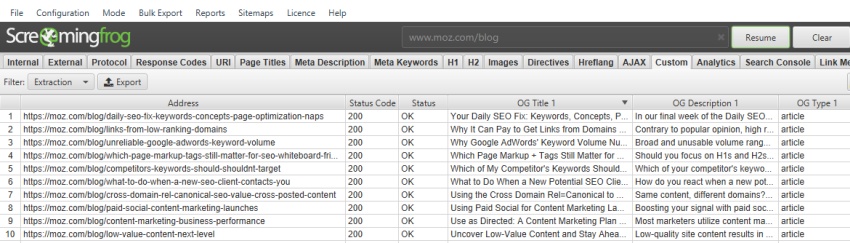
移动注释
如果您想从网站上提取移动注释,您可以使用如下 Xpath –
//link[contains(@media, '640') and @href]/@href
对于赫芬顿邮报,它将提取 –
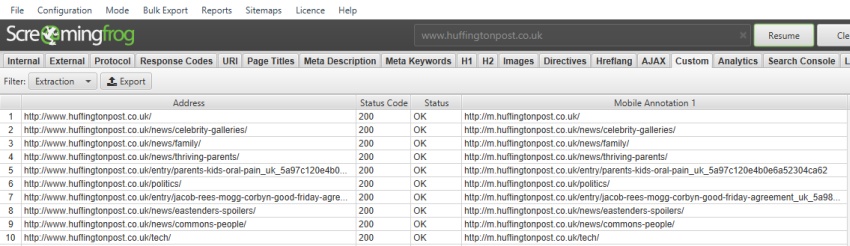
电子邮件地址
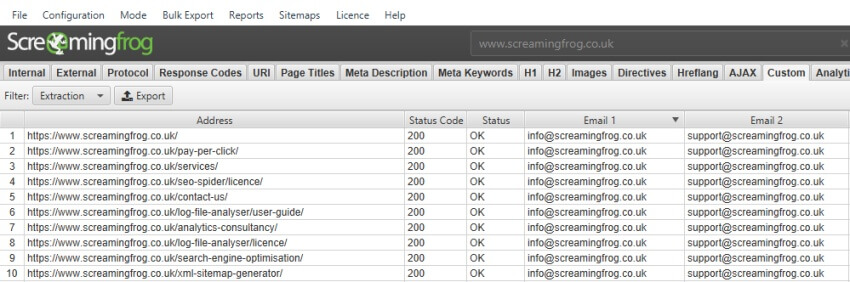
也许您想从您的网站或网站上收集电子邮件地址,Xpath 可能是这样的 –
//a[starts-with(@href, 'mailto')]
从我们的网站上,这将返回我们在每个页面页脚中的两个电子邮件地址 –
iframes
//iframe/@src
提取的数据 –
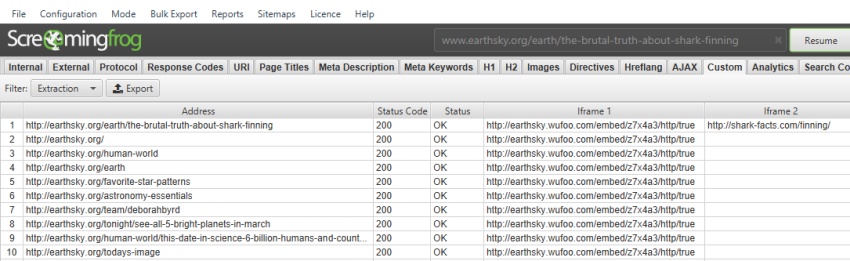
如果只想提取嵌入了 Youtube 视频的 iframe,可以使用以下代码:
//iframe[contains(@src ,'www.youtube.com/embed/')]
要提取 iframe,但不提取特定的 iframe URL(例如 Google Tag Manager URL),可以使用以下代码:
//iframe[not(contains(@src, 'https://www.googletagmanager.com/'))]/@src
要提取页面上找到的第一个 iframe 的 URL,可以使用以下代码:
(//iframe/@src)[1]
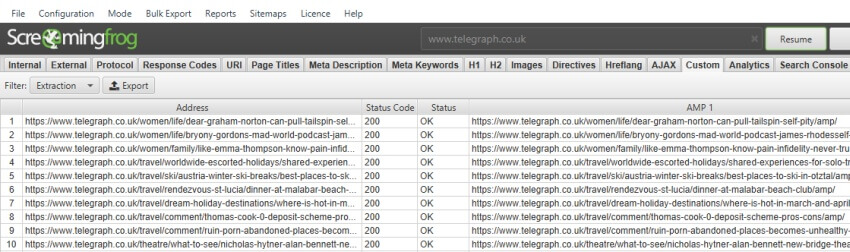
AMP URLs
//head/link[@rel='amphtml']/@href
提取的数据 –
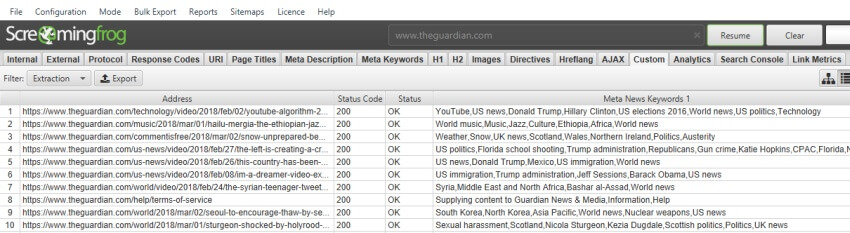
Meta News Keywords
//meta[@name='news_keywords']/@content
提取的数据 –
Meta Viewport Tag
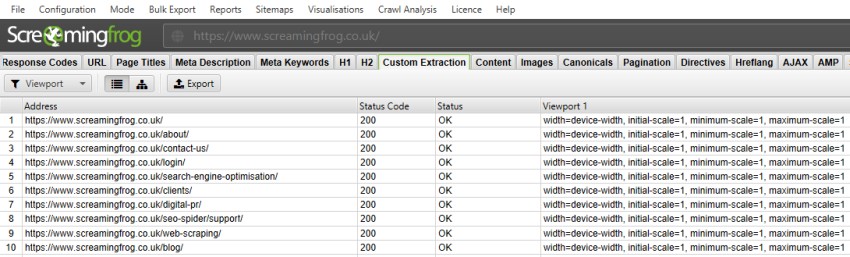
//meta[@name='viewport']/@content
提取的数据 –
仅提取正文中的链接
以下 XPath 将仅从 https://www.screamingfrog.co.uk/annual-screaming-frog-macmillan-morning-bake-off/ 上的博客文章正文中提取链接,其中博客内容包含在类 ‘main-blog–posts_single—inside’ 中。
这将使用“提取内部 HTML”获取锚文本:
//div[@class="main-blog--posts_single--inside"]//a
这将使用“提取内部 HTML”获取 URL:
//div[@class="main-blog--posts_single--inside"]//a/@href
这将使��用“提取 HTML 元素”获取完整的链接代码:
//div[@class="main-blog--posts_single--inside"]//a
提取包含锚文本的链接
要提取锚文本中包含“SEO Spider”的所有链接:
//a[contains(.,'SEO Spider')]/@href
此匹配区分大小写,因此如果“SEO Spider”有时是“seo spider”,则必须执行以下操作:
//a[contains(translate(., 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'),'seo spider')]/@href
这将把所有找到的锚文本转换为小写,允许您将其与小写的“seo spider”进行比较。
提取到特定域的链接
要提取页面上引用“screamingfrog.co.uk”的所有链接,您可以使用:
//a[contains(@href,'screamingfrog.co.uk')]
使用“提取 HTML 元素”或“提取文本”将允许您提取完整的链接代码或仅提取锚文本。
如果您只想提取链接的 URL,可以使用:
//a[contains(@href,'screamingfrog.co.uk')]/@href
从特定 Div 中提取内容
以下 XPath 将使用其类 ID 从特定 div 或 span 中提取内容。您需要将其替换为您自己的。
//div[@class="example"]
//span[@class="example"]
提取多个匹配的元素
可以在单个提取器中的表达式之间使用管道来使相关元素在导出中彼此相邻。
以下表达式匹配博客标题以及它们在博客存档页面上的评论数量:
//div[contains(@class ,'main-blog--posts_single-inner--text--inner')]//h3|//a[@class="comments-link"]

Regex 示例
跳转到特定的 Regex 提取示例:
Google Analytics 和 Tag Manager IDs
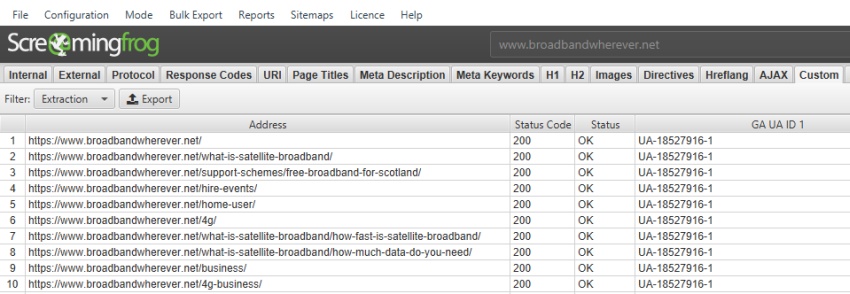
要从页面中提取 Google Analytics ID,所需的表达式为 –
["'](UA-.*?)["']
对于 Google Tag Manager (GTM),它将是 –
["'](GTM-.*?)["']

提取的数据是 –
结构化数据
如果结构化数据以 JSON-LD 格式实现,则必须使用正则表达式而不是 XPath 或 CSS 选择器。 您可能会发现某些实现方式在冒号前后有额外的空格,因此可能需要调整以下示例以匹配 HTML:
"product": "(.*?)"
"ratingValue": "(.*?)"
"reviewCount": "(.*?)"
要提取 JSON-LD 脚本标签中的所有内容,您可以使用 –
<script type=\"application\/ld\+json\">(.*?)</script>
电子邮件地址
以下内容将返回任何字母数字字符串,其中包含中间的 @:
[a-zA-Z0-9-_.]+@[a-zA-Z0-9-.]+
以下表达式将带回更少的误报,因为它需要在字符串的后半部分至少有一个句点:
[a-zA-Z0-9-_.]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+
目前��就这样,但我会随着时间的推移添加更多示例到此列表中,针对每种提取方法。
与往常一样,您可以将任何问题或疑问发送到我们的 support。