使用 SEO Spider 进行内链审计
介绍使用 SEO Spider 改进内链的各种方法。
以下情况你是否觉得熟悉?
- 你的内容已经过优化,但效果仍然不佳。
- 你有表现出色的博客文章,但你的产品页面似乎表现不佳。
- 新产品或页面需要很长时间才能达到旧产品的可见性��,或者永远无法达到。
在所有这些情况下,内链可能是一个值得考虑的因素。在我看来,它是页面SEO中仍然被严重低估的一部分。
让我解释一下。

本指南由技术 SEO 和内容营销顾问 Gabriela Troxler 撰写。在此之前,她创立了 feey,这是一个著名的瑞士电子商务品牌。她与各种规模的客户合作,从初创公司到国际企业,不仅制定战略,还提供实践培训。如果不谈论 SEO,你会发现她在做运动或阅读科幻小说。
为什么内链很重要?
搜索引擎(即它们的机器人)通过链接发现网页。一直如此,现在仍然如此。这意味着链接不良的新页面可能需要更长的时间才能被发现。
你不需要完全掌握 PageRank 的概念来理解以下事实:
- 链接到一个页面的链接越少,该页面在 Google 和其他搜索引擎眼中就越不重要。
- 链接结构 对于搜索引擎和用户理解网站架构和网站内的主题层次结构非常重要。
- 到达一个页面所需的点击次数越多(从主页算起),该页面就越不可能被抓取、索引和排名良好。
- 链接将权重从一个页面传递到另一个页面。
- 你可以主动使用内链来赋予页面重要性,并理清你的优先级。
如�果你想仔细查看你当前的优先级,也就是你的内链结构,一个小小的审计可能会大有帮助。
今天,我将向你展示如何使用 Screaming Frog SEO Spider 进行内链审计并发现链接机会。
请记住,内链不会解决你所有的问题——它需要嵌入到更广泛的 SEO 策略中。但是,我修复了我自己的电子商务业务以及客户网站的内链问题,并且可以保证其影响。
你可以选择你的战场,也可以一步一步地完成这些步骤。
通过抓取深度分析查找深层页面
还记得从主页到达某个页面所需的点击次数很重要吗?
这就是我们所说的链接深度或抓取深度。(抓取深度是从机器人角度来看的等效概念。)
这取决于你网站的大小,但一般来说,对于重要页面,你应该以最大 1-3 的链接深度为目标(再次说明——0 是主页本身)。
让我们计算 SEO Spider 中每个页面的抓取深度。
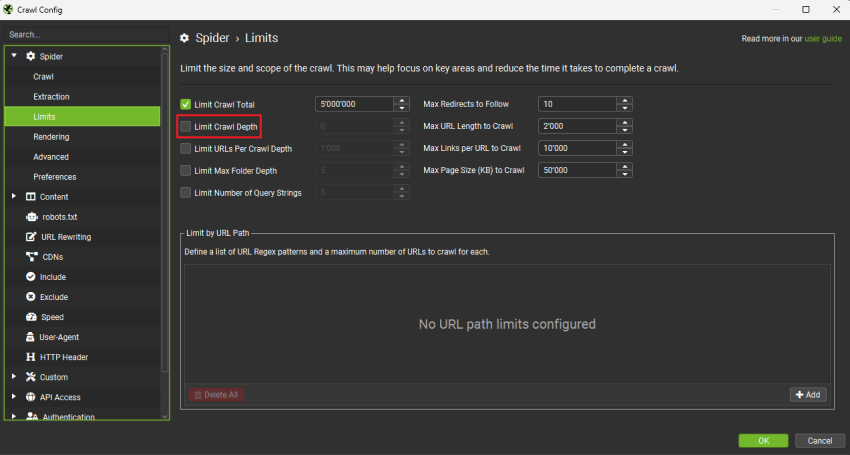
- 确保你不限制抓取深度。
- 默认情况下,不应限制。
- 要检查,请转到“Configuration > Spider > Limits”。确保你没有设置抓取深度或文件夹深度的限制,否则你将无法看到真正有问题的页面。
- 对于相当大的网站,你应该考虑将你的抓取分成几个部分,以免给你的计算机处理能力带来压力。请查看此抓取大型网站指南以获取更多信息。
- 运行你的抓取。
- 导航到“Internal”选项卡或“Links”选项卡,并查找名为“Crawl Depth”的列。
- 你可以将这些数字从高到低排序(请注意,重定向被计为额外的 +1)。
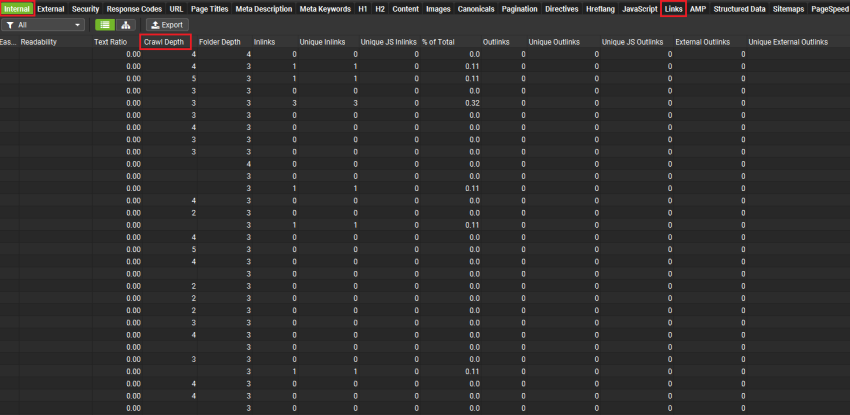
- 如果需要,你可以将列表导出到 Excel 或 Google Sheets。在那里,你可以设置一个过滤器,将抓取深度设置为高于 3。
- 在“Links”选项卡中,你还会找到一个名为“Pages with high crawl depth”的过滤器。但是,要填充该过滤器,你必须运行抓取分析。转到“Crawl Analysis > Configure”并在开始分析之前勾选“Links”框。
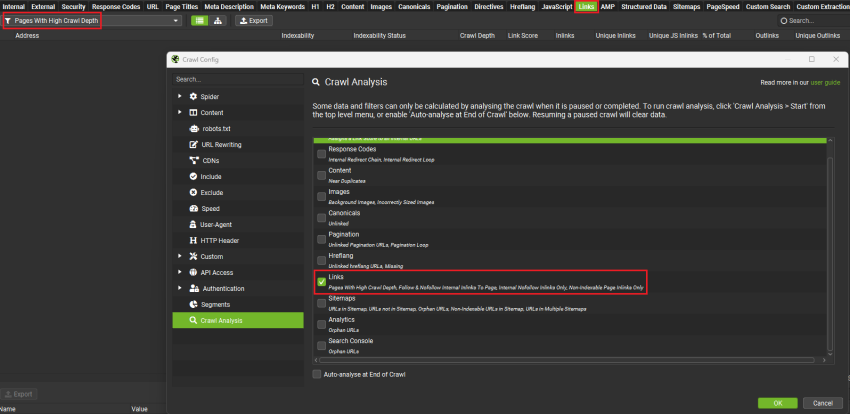
找到任何深埋在网站结构中的重要页面了吗?通过将它们从深处“提升”出来,使它们更容易访问。考虑将它们添加到你的主导航栏(如果它们是关键页面),或者从现有的相关内容内部链接到它们(稍后会详细介绍)。一般来说,保持你的网站架构整洁,你的站点地图保持最新,并控制你的 URL,以防止你的页面滑入深处并导致潜在的抓取预算问题。
使用内链计数查找链接不良的页面
链接不良的页面很常见。你可能不会立即看到内链中的问题,但是如�果你的新页面即使经过一段时间后也没有像旧页面那样吸引流量,你应该对此进行调查。
想象一下。你有一个小型在线葡萄酒业务,旁边有一个博客。你定期发布内容,专注于提供信息丰富、有用的指南并展示你的产品。你开始对你的畅销书产生感觉(和数字),并在你的博客文章中更频繁地包含这些畅销书。由于进展顺利,你扩大了你的产品范围,并提供来自不同地区的更多葡萄酒。
现在,你的英雄产品从业务角度来看,以及从内链角度来看,都具有先发优势。毕竟,你一直在努力制作内容,并将这些葡萄酒包含在你的博客文章中。较新的产品自然会不足——需要有意识地努力将它们拉到聚光灯下并从旧页面链接到它们。
Screaming Frog SEO Spider 在这里可以提供帮助。
- 像往常一样抓取你的网站。
- 点击“Link”选项卡。
- 找到“Unique Inlinks”列。
- 入链是指指向所选 URL 的超链接数量。唯一入链仅计算来自给定 URL 的每个实例一次。
- 假设你的博客文章“情人节最佳干花花束”三次链接到你的产品“干玫瑰”——这算作 1 个唯一入链,但总共有 3 个入链。
- 在“Unique Inlinks”列中,你可以按最低数字排序。
- 或者,你可以直接找到“% of Total”列。这是每个 URL 的唯一内部入链百分比,与总数相比。
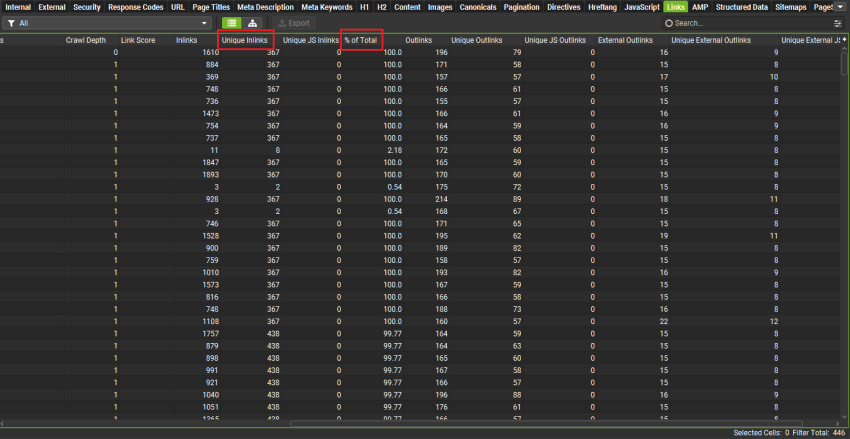
找到重要页面上的入链数量少得令人震惊吗?这就是你要找的。你的下一步将是找到指向这些页面的链接机会。接下来会介绍。
要确定弱页面,你还可以使用链接分数。链接分数 是 Screaming Frog SEO Spider 中的一个指标,用于确定页面与同一网站上的其他页面相比的相关性。它基于传入链接,但也考虑了其他因素,例如出站链接,并且它会将你的所有页面分配到从 0 到 100 的相对范围内。
使用 Screaming Frog SEO Spider 查找内部链接机会
现在你已经确定了链接权重较低的页面,现在是时候给它们一些关爱了。
自定义搜索
我喜欢在 Screaming Frog SEO Spider 中识别链接机会的一种方法是通过其自定义搜索功能。要使用它,你首先需要确定:
- 你想要加强的弱页面(参见上面的章节)。
- 你想用作链接到该页面的锚文本的关键词。
例如,你可以使用 Google Search Console 来查找这些关键词。
接下来,你将使用 Screaming Frog SEO Spider 自定义搜索来查找这些词在你整个网站上的实例:
- 打开“Configuration > Custom > Custom Search”。
- 点击“+ Add”并逐个添加你的关键词。
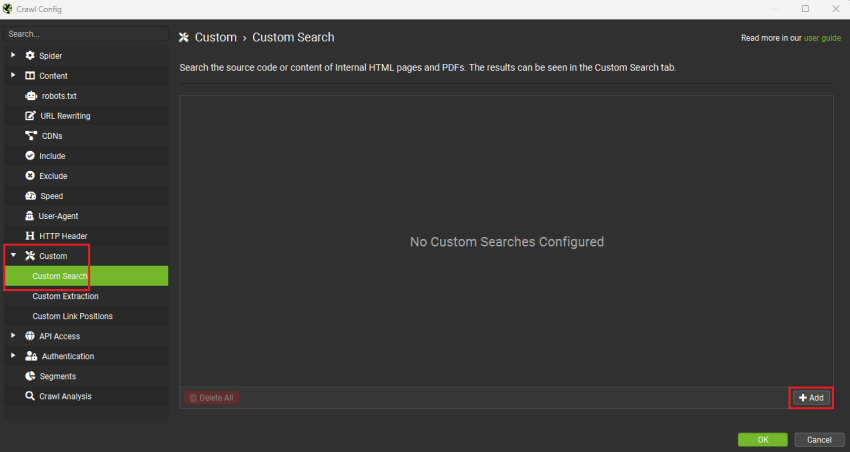
你可以在此处添加多达 100 行。
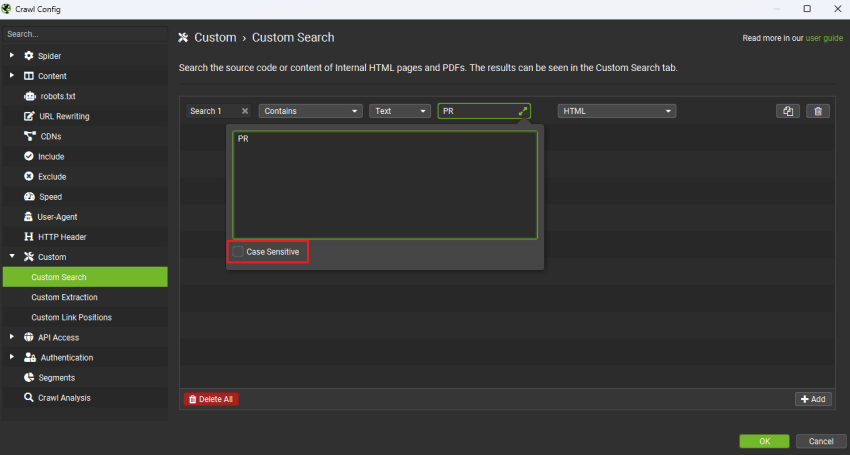
默认情况下,你的搜索不区分大小写。如果你要搜索一个简短、常用的字�母组合(例如“PR”),你可能需要包含大小写。否则,所有单词中带有“pr”的结果都会显示出来。
你可以通过点击关键词旁边的展开箭头并选中相应的框来激活区分大小写。
- 点击关键词旁边的下拉菜单,然后选择“Page Text No Anchors”。
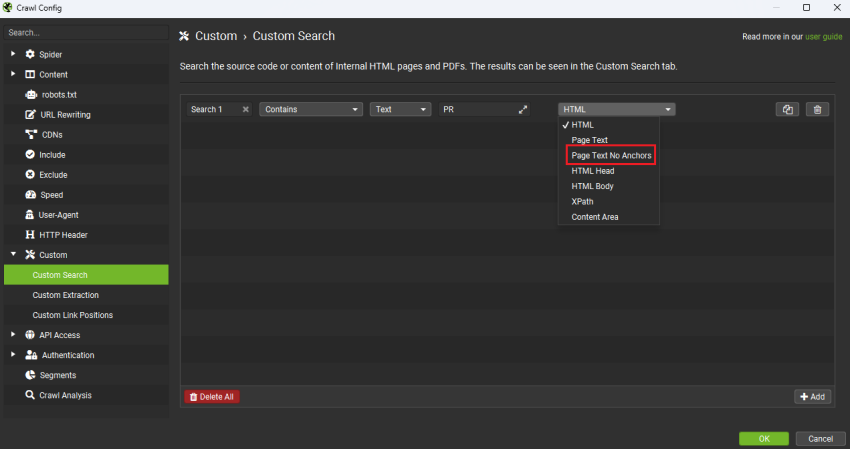
你可以按照默认设置在 HTML 中搜索。但是,如果你已经在正文中链接了很多,或者该术语是你主导航栏的一部分,这将还会返回已经链接的关键词的结果。要从一开始就排除这些结果,请选择“Page Text No Anchors”。SEO Spider 现在只会返回不在锚标记中的结果(因此未链接)。
- 在你的关键词后添加另一行。
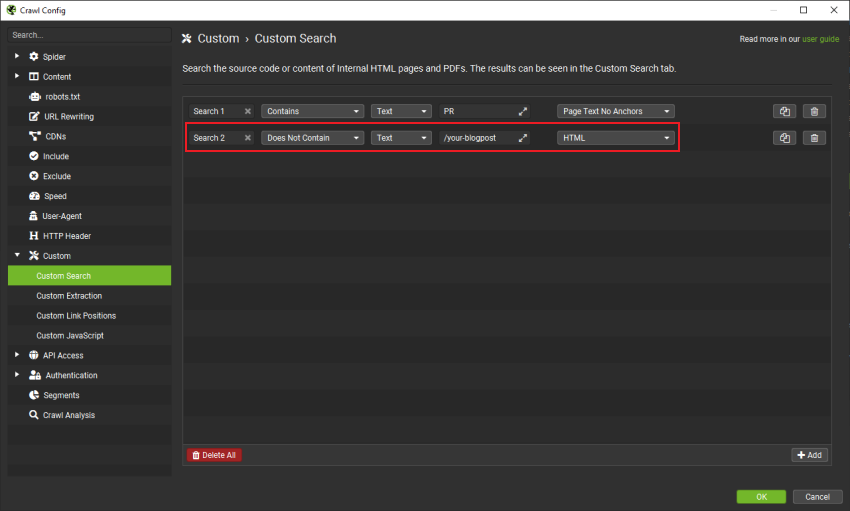
同样,你可能只会运行带有关键词的自定义搜索。但是,此附加步骤允许你排除已经链接到你要加强的页面的 URL。无需在此处包含其他链接。因此,此排除可以为你节省后续的手动步骤。
现在输入以下文本,其中包含你要链接到的 URL 的路径(你的目标页面):
/your-blogpost
在此示例中,你正在尝试优化 URL https://www.domain.com/your-blogpost。
保留默认的“HTML”,但将第一个下拉菜单从“Contains”切换为“Does not contain”。
你现在已经告诉 Spider 排除所有你已经在 HTML 中链��接到 /your-blogpost 的示例,包括此路径之后的所有子文件夹。
- 点击“OK”并运行你的抓取,然后导航到“Custom Search”选项卡。
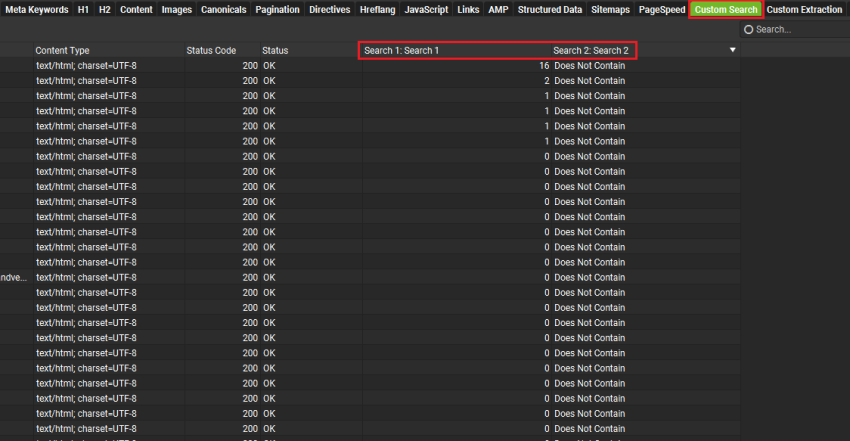
你现在将看到未链接的所需关键词提及,并且只需关注“Does Not Contain”结果,因为其他结果已经包含指向所需 URL 的链接。
注意: 默认情况下,自定义搜索将已经排除“Navigation”和“Footer”中对你的关键词的提及。如果你想进一步优化此设置或检查它,请在运行抓取之前点击“Configuration > Content > Content Area”。在这里,你可以包含和排除类和 ID。如果你想从搜索中进一步排除某些 URL(例如管理页面、受密码保护的区域、类别页面、标签页面等),请使用“Configuration > Exclude”。你可以在此处阅读有关内容区域的更多信息。
采取行动非常简单:将列表中的关键词链接到你想要获得更多链接权重的页面。
如果你的列表很长,你可能需要考虑优先从已经获得大量链接和点击的 URL 进行链接。这些是你的“强力页面”。
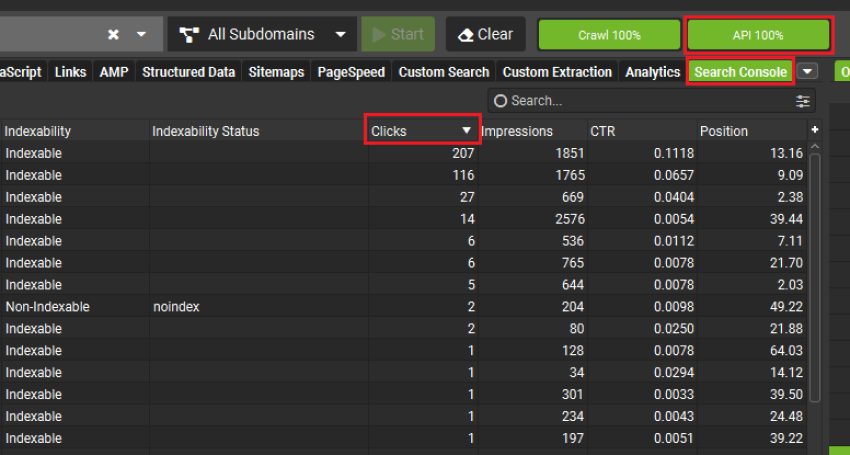
要找到这些页面,你可以使用 Google Search Console。如果你在 Screaming Frog SEO Spider 中启用 API,你可以直接提取数据:“Configuration > API Access > Google Search Console”。
连接到你的 Search Console 帐户并选择你需要的属性后,点击“Configuration > API Access > Request API Data”以填充该选项卡。
以下是提取数据后的外观:
N-Grams
查找内部链接机会的另一种方法是使用 N-grams 分析功能来查找未链接的关键词以进行内部链接。
要启用此功能,需要在“Config > Spider > Extraction”下启用“Store HTML / Store Rendered HTML”。然后可以在较低的 N-grams 选项卡中查看 N-grams。
使用 n-grams,你可以突出显示网站的某个部分,并过滤“Body Text (Unlinked)”中的关键词以识别链接机会。
点击图片以查看更大的版本。
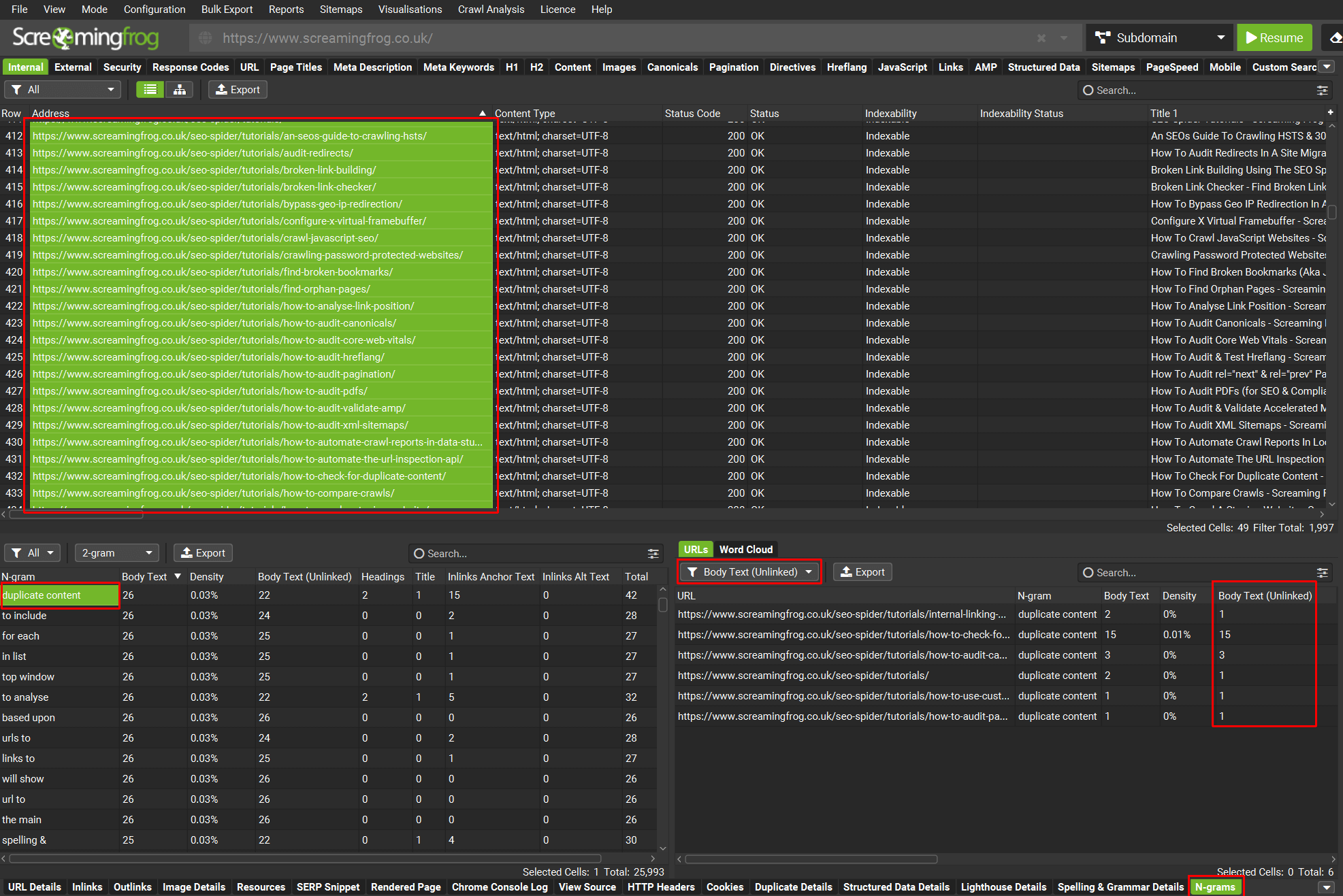
在上面的示例中,教程页面已被突出显示以搜索 2-gram“duplicate content”。
右侧的过滤器已设置为“Body Text (Unlinked)”,同名的列显示了不同教程页面上未链接的实例数量,这些实例可以被认为链接到有关如何检查重复内容的适当指南,例如。
n-grams 搜索功能使用正则表达式,因此也很容易使用以下语法搜索短语列表 -
[N-gram] Matches Regex 'word|word2|word3'
然后可以一次选择多个 n-grams,并通过各种选项批量导出。
查找网站上非描述性的锚文本
“讲述”目标 URL 的锚文本不仅对于可访问性很重要,而且对于搜索引擎理解你的网站、链接结构和主题层次结构也很重要。因此,它与排名相关。
锚文本是超链接中使用的可见文本(典型的带下划线的“蓝色链接”)。最佳实践是选择为用户和搜索引擎提供有关目标页面内容的上下文的词语。
当然,了解这一点并在你进行内链时实施“讲述”锚文本会有所帮助。即便如此,由于多人在一个网站上工作以及遗留实践,这可能会很快成为一个规模问题。
你可能已经在你的网站上看到了没有 SEO 价值的非描述性锚文本示例:“点击此处”、“更多”等。
要进一步调查此问题,请点击 Screaming Frog 中的“Configuration > Spider > Preferences”。
你已经看到了一些建议,并且可以在“Non-descriptive anchor text”字段中添加你自己的术语。
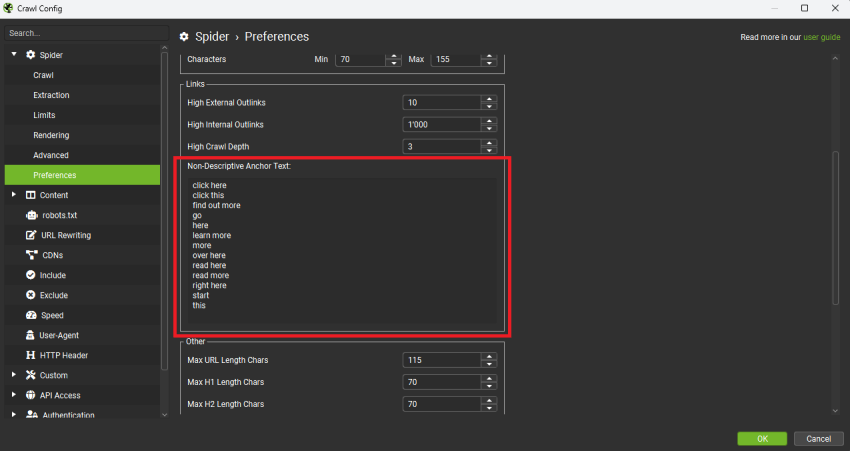
在运行你的抓取以及勾选了“Links”框的抓取分析后,你将在“Links”选项卡中的过滤器“Non-Descriptive Anchor Text In Internal Outlinks”中找到结果。
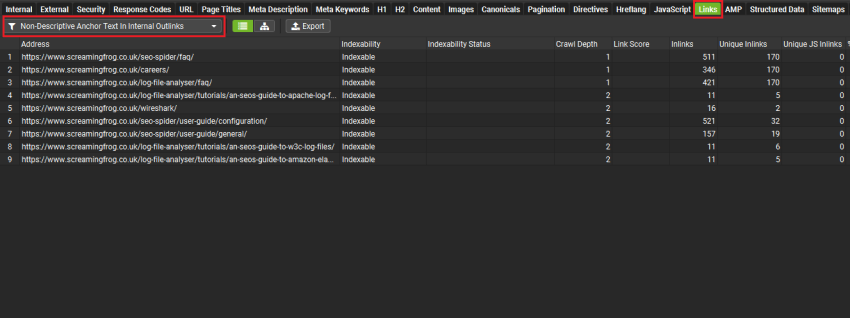
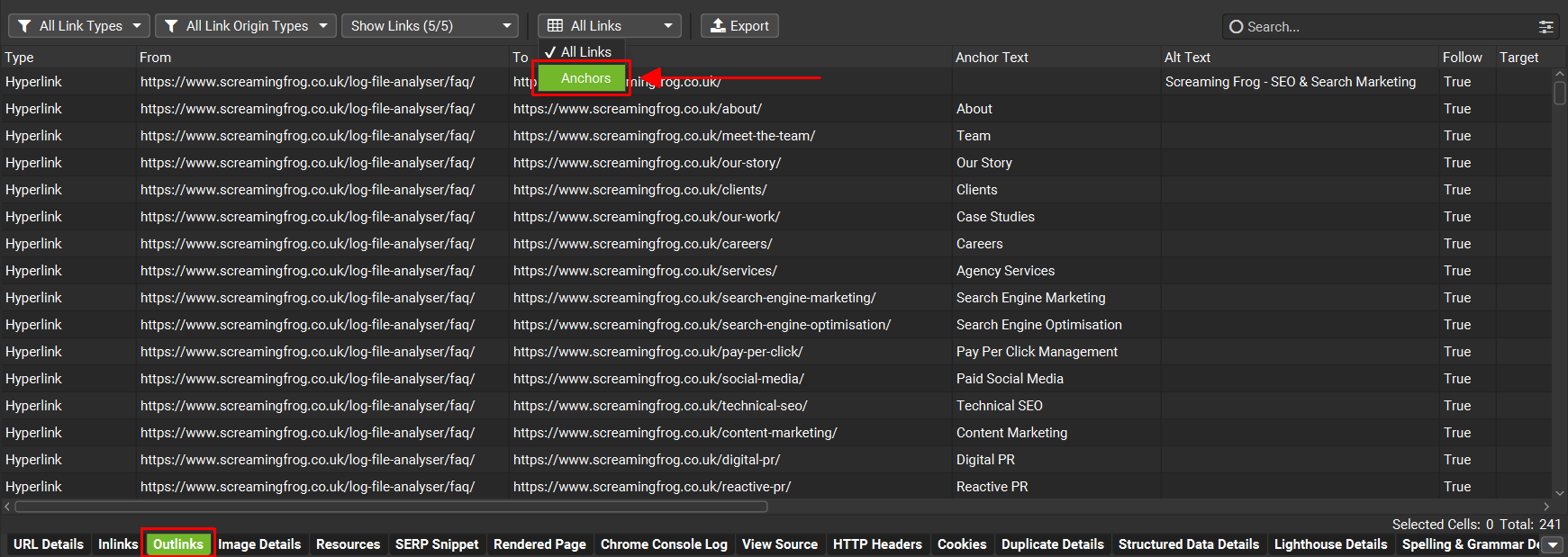
你可以通过点击顶部窗口中的 URL,然后点击下方的“出站链接”选项卡,来查看哪些内部锚文本是非描述性的。将“所有链接”筛选器调整为“锚文本”,以查看页面上按锚文本聚合的任何出站链接。
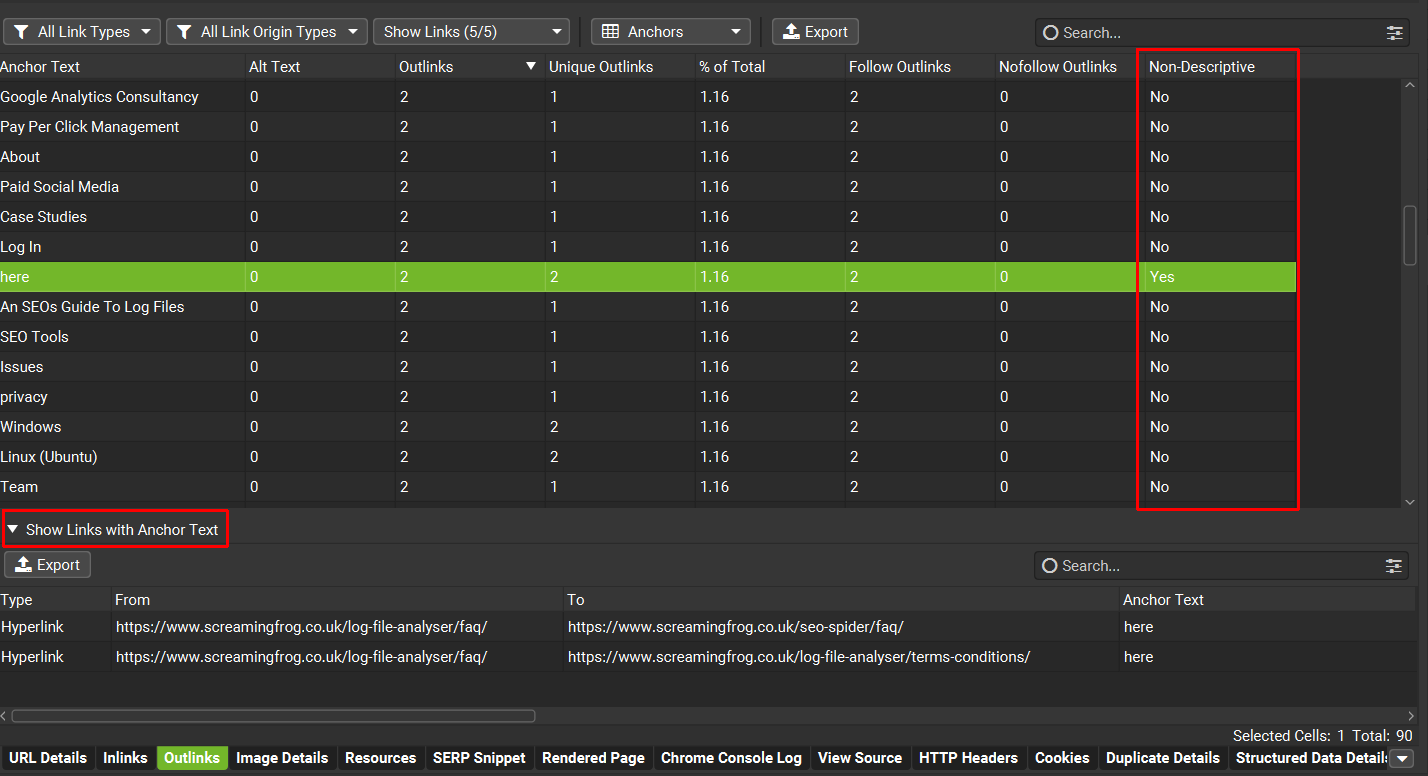
然后使用“非描述性”列快速识别锚文本,并点击“显示带有锚文本的链接”以查看它们所在的页面。
通过“批量导出 > 链接 > 内部出站链接中的非描述性锚文本”轻松批量导出这些内容。
你现在的任务是将这些词块转化为有价值的东西:描述性的、有帮助的锚文本。
查找孤立页面
孤立页面(或孤页)是指无法通过网站内部链接访问的页面。
这意味着网站访问者可能看不到存储在那里的内容,除非他们通过其他来源(外部链接、新闻通讯、书签、站点地图等)直接访问 URL。
由于爬虫和网站用户都无法轻松访问该页面,因此孤立页面不太可能被搜索引擎发现、抓取、索引和排名。
也许你认为孤立页面并不常见,但它们通常是在无意中创建的:
- 它们是技术上重要的页面,但它们的传入链接或相应的页面已被删除。
- 它们是应该被删除或重定向的页面(旧的营销活动着陆页、已停产的产品)。
- 它们本不应该存在(例如某种测试页面)。
我见过专门的“SEO 页面”,这些页面是故意创建的,不会出现在导航或站点地图中,但应该用作着陆页(带有大量指向外部的内部链接,以�便将用户发送到他们快乐的道路上)。像这样的页面根本没有设置为赢家。
让我们去寻找并消除孤立页面。但是我们如何在没有链接的工具中做到这一点呢?
嗯,我们需要这些页面何时出现的外部参考——例如在 Google Analytics、Search Console 或你自己的站点地图中。
SEO Spider 在组合这些来源方面做得非常出色,并在一个整洁的过滤器中为你提供孤立页面。
这里已经有一篇很棒的指南,介绍如何使用 Screaming Frog SEO Spider 发现孤立页面。
你的行动要点非常简单:删除、410 响应代码或重定向这些页面,或者用生命和链接填充它们!
查找 JavaScript 链接
Google 对 JavaScript 的处理和渲染本身就是一个兔子洞。
如果你是新手,Screaming Frog 团队已经编写了一份很棒的指南,介绍如何抓取 JavaScript 网站。
目前,可以说 JS 链接存在无法以与其 href 对应项相同的方式被看到或解释的风险。
以下是如何在 Screaming Frog SEO Spider 中查找 JavaScript 链接。
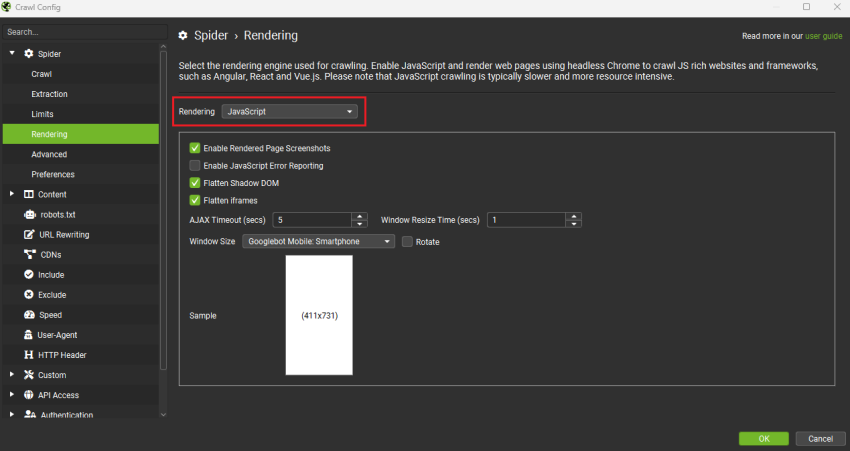
- 允许 JavaScript 渲染。
默认情况下未选择此选项,因为 JS 渲染需要更多资源,并且比“仅文本”选项花费更多时间。转到“配置 > Spider > 渲染”并选择“JavaScript”。
- 抓取你的网站。
当你现在开始抓取时,SEO Spider 会搜索原始 HTML 和渲染后的 HTML。这使得可以识别仅在客户端渲染后才可用的内容或链接的页面,并了解其他 JavaScript 依赖项。
抓取完成后,导航到“JavaScript”选项卡。你可以使用下拉菜单选择“包含 JavaScript 链接”。
此选择将显示仅在执行 JavaScript 后在渲染的 HTML 中可见的链接的页面。
如果一个页面及其链接对你很重要,请确保将它们以 href 形式包含在原始 HTML 中,以确保无故障处理。
最后想法
感谢你加入我,与 Screaming Frog SEO Spider 的各种功能和机会一起,在这段穿越内部链接审计世界的狂野旅程中。我希望你玩得开心,并在尝试这些技巧时获得更多乐趣。
你有什么问题、意见、补充吗?
我很乐意听到你对这些方法的想法和经验!请随时在 LinkedIn 上与我联系。