如何检查重复内容
通过识别完全重复的页面,以及网站上页面之间存在部分文本匹配的近似重复内容,来最大限度地减少重复内容。
如何查找重复内容
应该尽量减少网站上的重复内容,因为它会使搜索引擎难以决定为哪个版本进行排名。
虽然“重复内容惩罚”在 SEO 中是一个神话,但非常相似的内容可能会导致抓取效率低下,稀释 PageRank,并且可能是内容可以合并、删除或改进的信号。
值得记住的是,重复和相似的内容是网络的自然组成部分,对于搜索引擎来说通常不是问题,搜索引擎会按照设计规范化 URL 并在适当的情况下对其进行过滤。但是,大规模地使用可能会带来更多问题。
防止重复内容使您可以控制索引和排名的内容,而不是将其留给搜索引擎。您可以限制抓取预算的浪费,并整合索引和链接信号以帮助排名。
本教程将引导您了解如何使用 Screaming Frog SEO Spider 来查找完全重复的内容,以及网站上页面之间存在部分文本匹配的近似重复内容。
任何工具(包括 SEO Spider)识别出的重复内容都需要在上下文中进行审查。观看我们的视频,或继续阅读下面的指南。
要开始使用,请下载 SEO Spider,该软件可以免费抓取最多 500 个 URL。前 2 个步骤仅在使用 许可证 的情况下可用。如果您是免费用户,请跳至指南中的 第 3 步。
1) 通过“Config > Content > Duplicates”启用“近似重复项”
默认情况下,SEO Spider 会自动识别完全重复的页面。但是,要识别“近似重复项”,必须启用该配置,这使其可以存储每个页面的内容。
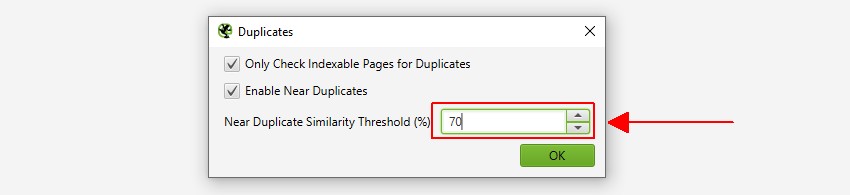
SEO Spider 将识别相似度匹配度为 90% 的近似重复项,可以调整该匹配度以查找相似度阈值较低的内容。
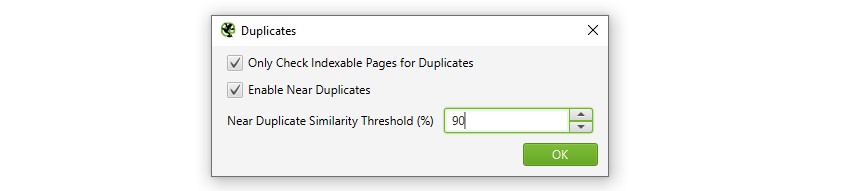
SEO Spider 还将仅检查“可索引”页面上的重复项(对于完全重复项和近似重复项)。
这意味着,如果您有两个相同的 URL,但其中一个已规范化为另一个(因此“不可索引”),则不会报告此情况,除非禁用此选项。
如果您有兴趣查找抓取预算问题,请取消选中“仅检查可索引页面上的重复项”选项,因为这有助于查找潜在的抓取浪费区域。
2) 通过“Config > Content > Area”调整用于分析的“内容区域”
您可以配置用于近似重复项分析的内容。对于新的抓取,我们建议使用默认设置,并在以后查看和考虑分析中使用的内容时对其进行优化。
SEO Spider 将自动排除导航和页脚元素,以专注于正文内容。但是,并非每个网站都使用这些 HTML5 元素构建,因此您可以根据需要优化用于分析的内容区域。您可以选择在分析中“包括”或“排除”HTML 标签、类和 ID。
例如,Screaming Frog 网站在导航元素之外有一个移动菜单,默认情况下该菜单包含在内容分析中。虽然在这种情况下这不是什么大问题,但为了帮助专注于页面的正文文本,可以将其类名“mobile-menu__dropdown”输入到“排除类”框中。
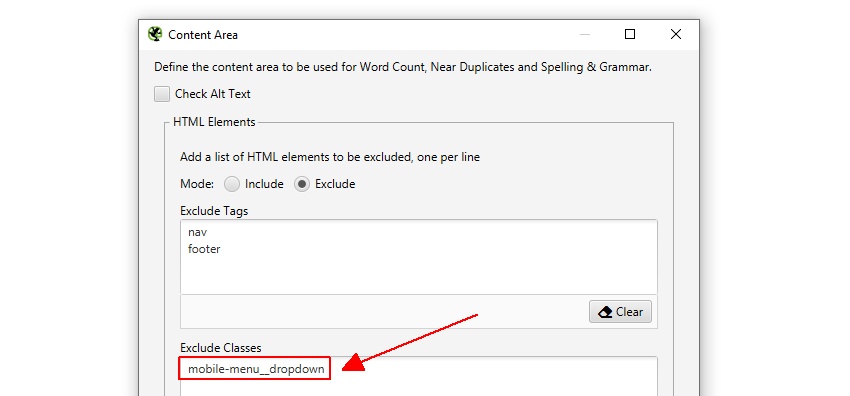
这将从重复内容分析算法中排除该菜单。稍后会详细介绍。
3) 抓取网站
打开 SEO Spider,在“输入要抓取的 URL”框中键入或复制您要抓取的网站,然后点击“开始”。
等待抓取完成并达到 100%,但您也可以实时查看一些详细信息。
4) 在“内容”选项卡中查看重复项
“内容”选项卡具有 2 个与重复内容相关的过滤器,“完全重复项”和“近似重复项”。
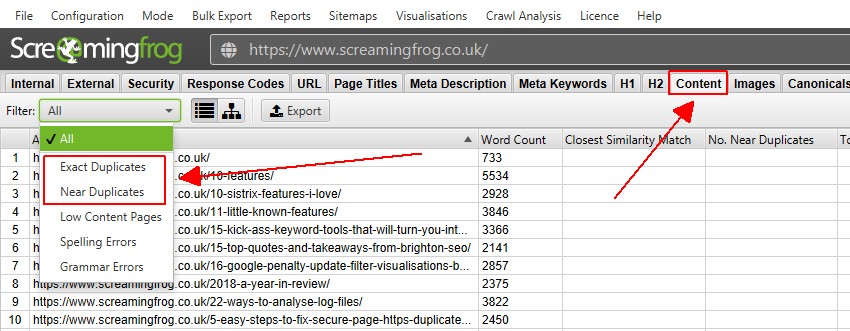
只有“完全重复项”可以在抓取期间实时查看。“近似重复项”需要在抓取结束时通过抓取后“抓取分析”进行计算,才能填充数据。
右侧的“概览”窗格针对需要抓取后分析才能填充数据的过滤器显示“(需要抓取分析)”消息。
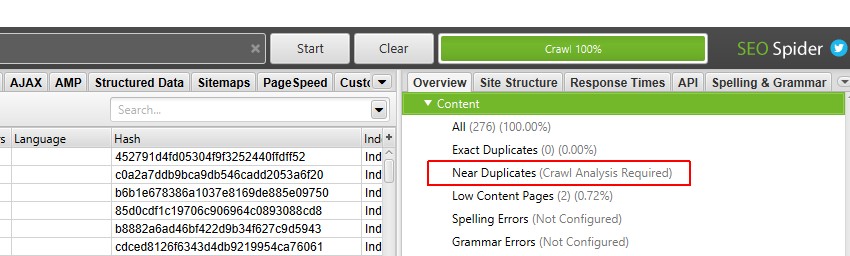
5) 点击“抓取分析 > 开始”以填充“近似重复项”过滤器
要填充“近似重复项”过滤器、“最接近的相似度匹配”和“近似重复项数量”列,您只需在抓取结束时点击一个按钮即可。

但是,如果您之前配置了“抓取分析”,您可能希望在“抓取分析 > 配置”下仔细检查是否选中了“近似重复项”。
您也可以取消选中其他也需要抓取后分析的项目,以加快此步骤。
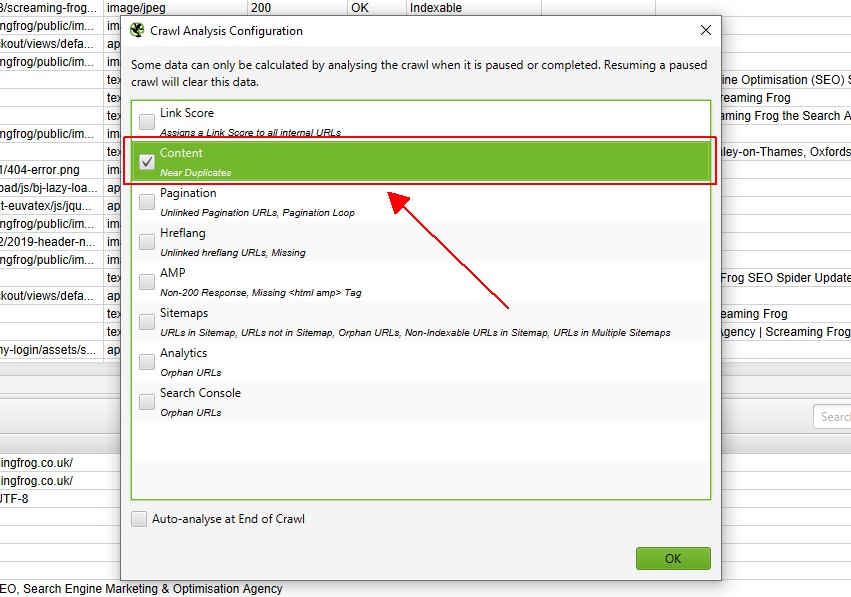
抓取分析完成后,“分析”进度条将达到 100%,并且过滤器将不再显示“(需要抓取分析)”消息。
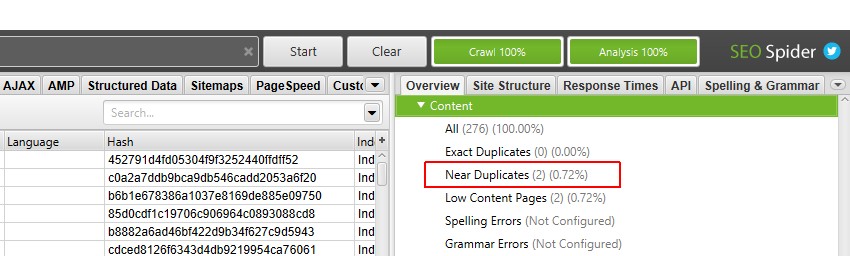
您现在可以查看已填充的近似重复项过滤器和列。
6) 查看“内容”选项卡和“完全”和“近似”重复项过滤器
执行抓取后分析后,将填充“近似重复项”过滤器、“最接近的相似度匹配”和“近似重复项数量”列。只有内容超过所选相似度阈值的 URL 才会包含数据,其他 URL 将保持空白。在这种情况下,Screaming Frog 网站只有两个。
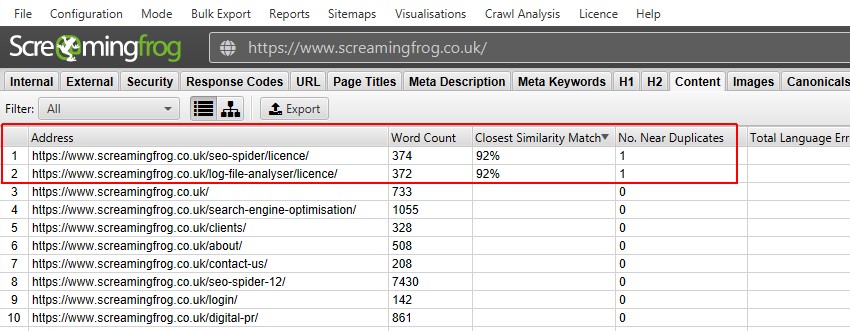
抓取更大的网站(例如 BBC)将显示更多。
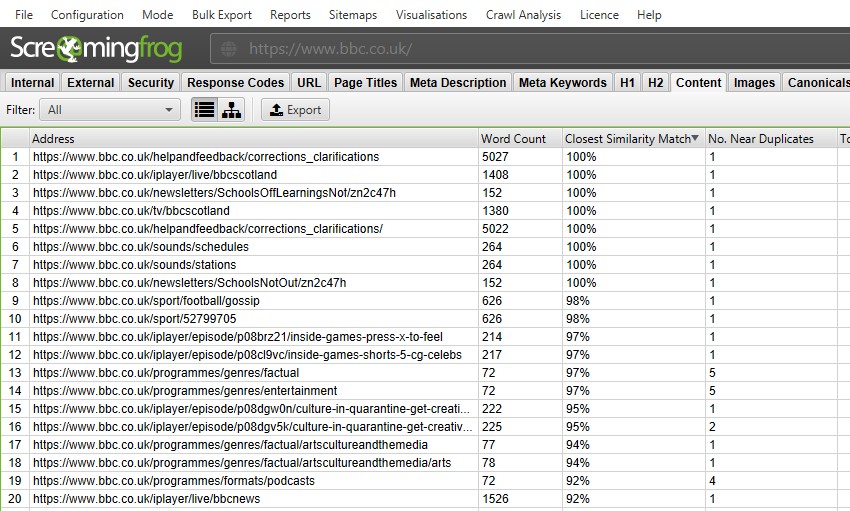
您可以按以下内容进行过滤 -
- 完全重复项 – 此过滤器将显示彼此相同的页面,使用 MD5 算法,该算法计算每个页面的“哈希”值,可以在“哈希”列中看到。此检查是针对页面的完整 HTML 执行的。它将显示具有匹配哈希值的所有页面,这些页面完全相同。完全重复的页面可能导致 PageRank 信号的分裂和排名的不可预测性。应该只有一个存在的 URL 的规范版本,并且在内部链接到该版本。不应链接到其他版本,并且应将它们 301 重定向到规范版本。
- 近似重复项 – 此过滤器将根据配置的相似度阈值,使用 minhash 算法显示相似的页面。可以在“Config > Spider > Content”下调整阈值,默认设置为 90%。 “最接近的相似度匹配”列显示与另一个页面的最高相似度百分比。“近似重复项数量”列显示基于相似度阈值与该页面相似的页面数量。该算法针对页面上的文本运行,而不是像完全重复项那样针对完整的 HTML。用于此分析的内容可以在“Config > Content > Area”下配置。页面可以具有 100% 的相似度,但只能是“近似重复项”,而不是完全重复项。这是因为完全重复项被排除为近似重复项,以避免它们被标记两次。相似度分数也会四舍五入,因此 99.5% 或更高将显示为 100%。
应手动审查近似重复页面,因为有很多合理的理由导致某些页面在内容上非常相似,例如具�有围绕其特定属性的搜索量的产品变体。
但是,应审查标记为近似重复项的 URL,以考虑它们是否应作为单独的页面存在,因为它们对用户具有独特的价值,或者是否应删除、合并或改进它们,以使内容更深入和独特。
提示! 除了识别完全重复项和近似重复项之外,SEO Spider 还可以识别语义上相似的页面和可能离题的低相关性内容。
此功能超越了通过利用 LLM 嵌入来匹配文本,这些嵌入可以理解单词的底层概念和含义。阅读我们的教程如何识别语义上相似的页面和异常值。
7) 通过“重复详细信息”选项卡查看重复 URL
对于“完全重复项”,只需使用过滤器在顶部窗口中查看它们会更容易,因为它们被分组在一起并共享相同的“哈希”值。
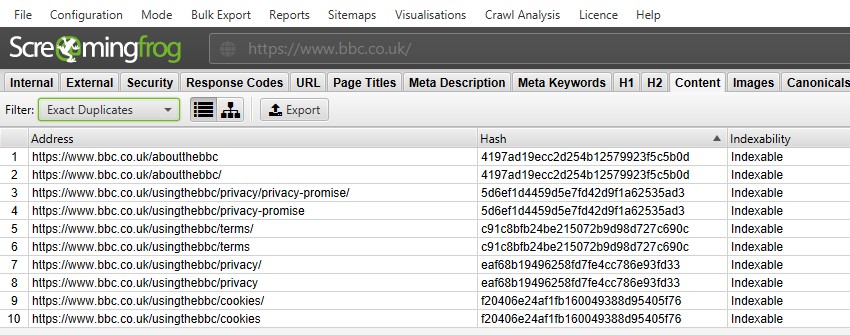
在上面的屏幕截图中,由于尾部斜杠和非尾部斜杠版本,每个 URL 都有一个相应的完全重复项。
对于“近似重复项�”,点击底部的“重复详细信息”选项卡,该选项卡会在下部窗口窗格中填充“近似重复地址”和每个发现的近似重复 URL 的相似度。
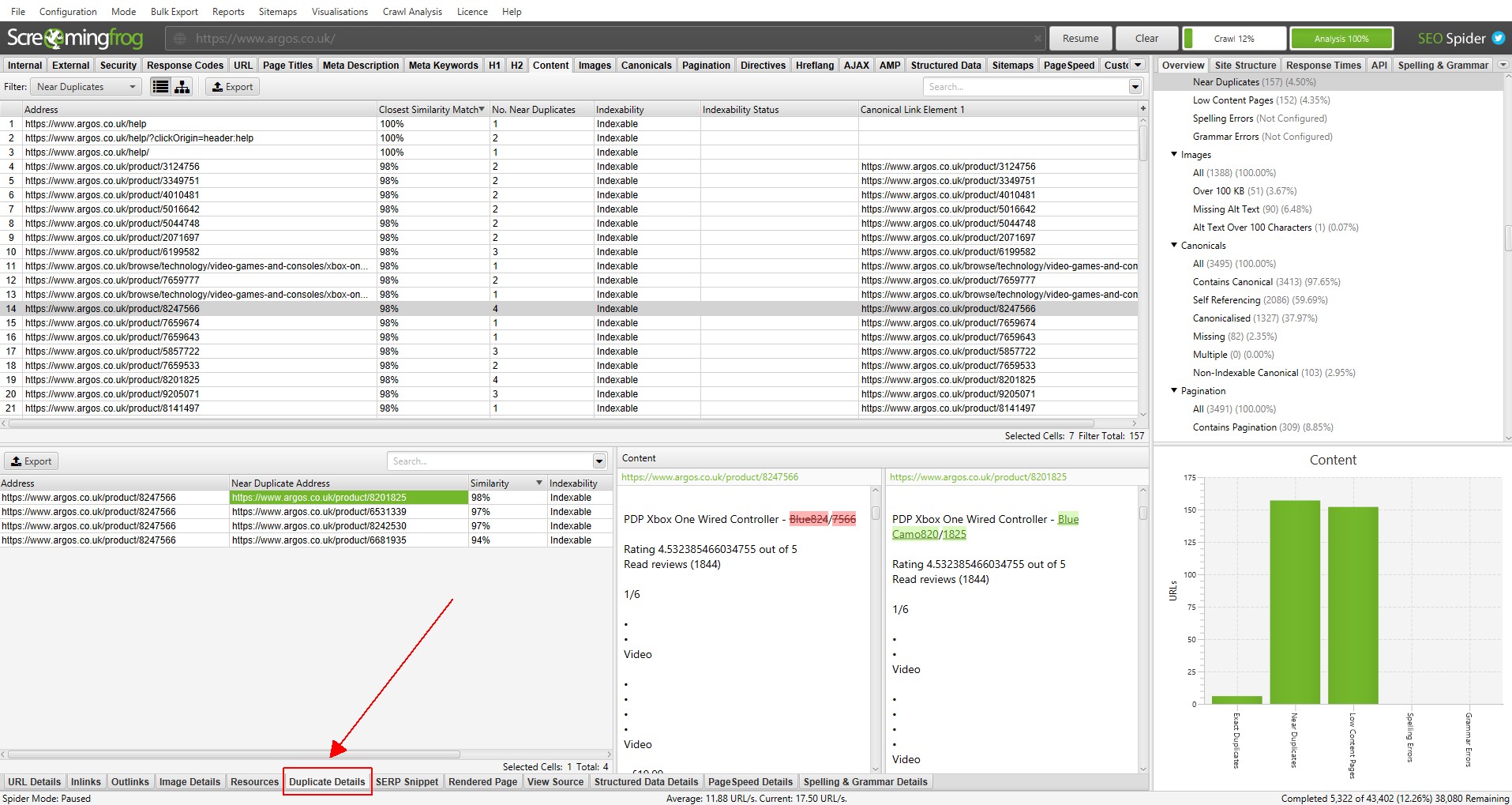
例如,如果在顶部窗口中为 URL 发现了 4 个近似重复项,则可以查看所有这些重复项。
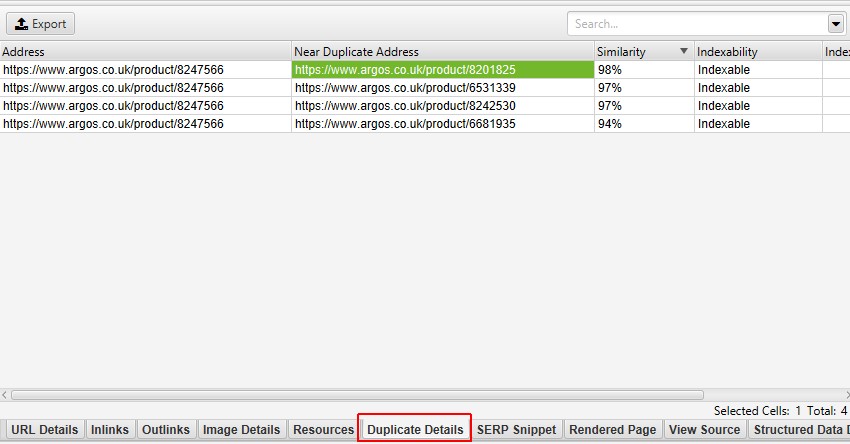
当您点击每个“近似重复地址”时,“重复详细信息”选项卡的右侧将显示从页面发现的近似重复内容,并突出显示页面之间的差异。
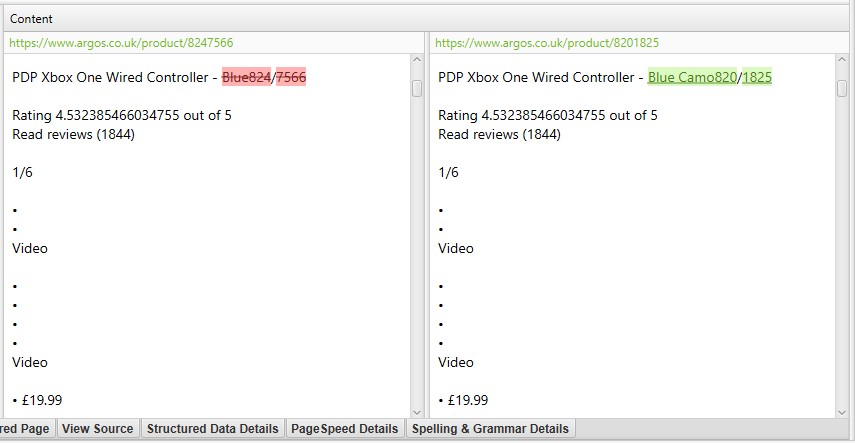
如果在重复详细信息选项卡中有任何您不希望成为重复内容分析一部分的重复内容,请排除或包括任何 HTML 元素、类或 ID(如第 2 点中所述),并重新运行抓取分析。
8) 批量导出重复项
可以通过“批量导出 > 内容 > 完全重复项”和“近似重复项”导出批量导出完全重复项和近似重复项。

最终提示!优化相似度阈值和内容区域,并重新运行抓取分析
抓取后,您可以调整近似重复相似度阈值和用于近似重复分析的内容区域。
然后,您可以再次重新运行抓取分析,以查找更多或更少相似的内容,而无需重新抓取网站。
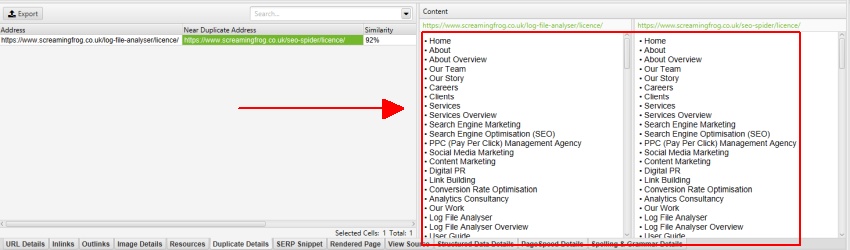
如前所述,Screaming Frog 网站在导航元素之外有一个移动菜单,默认情况下该菜单包含在内容分析中。可以在“重复详细信息”选项卡的内容预览中看到移动菜单。
通过在“Config > Content > Area”下的“排除类”框中排除“mobile-menu__dropdown”,移动菜单将从内容预览和近似重复分析中删除。
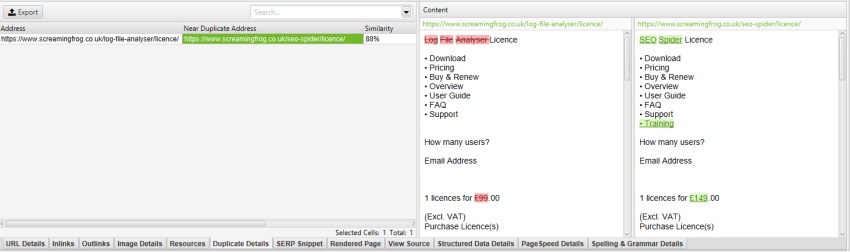
这确实有助于微调近似重复内容的识别��,使其进入主要内容区域,而无需重新抓取。
总结
上面的指南应说明如何使用 SEO Spider 作为您网站的重复内容检查器。为了获得最准确的结果,请优化用于分析的内容区域,并调整不同页面组的阈值。
另请阅读我们的 Screaming Frog SEO Spider 常见问题解答和完整的用户指南,以获取有关该工具的更多信息。
如果您有任何其他疑问、反馈或改进 SEO Spider 中重复内容工具的建议,请通过支持与我们联系。