如何在网站迁移中使用 SEO Spider
了解如何在网站迁移中使用 SEO Spider 的抓取和功能,以更高效地工作并提高成功几率。
如何在网站迁移中使用 SEO Spider
本教程解释了如何利用 Screaming Frog SEO Spider 进行网站迁移,以识别任何潜在问题,更高效地工作并提高其成功率。
首先,让我们快速总结一下网站迁移的含义。
什么是网站迁移?
网站迁移一词通常用于指网站即将发生重大变化,例如设计、平台、结构、内容、域名、URL 或它们的组合——所有这些都可能对搜索引擎的可见性产生不同的影响。
有各种类型的迁移,其中一些涉及更多的变化,潜在的机会,但也常常带来更大的风险。 重要的是要有一个共同的范围和策略,以及一个流程和清单,以减轻排名中的任何问题。
本教程的目的不是告诉您如何执行网站迁移,而是告诉您如何使用 Screaming Frog SEO Spider 进行抓取和审计,以帮助在典型的迁移过程中完成繁重的工作。
迁移前准备
在接近迁移之前,有各种范围界定、规划和审查线框的阶段。 但是,在任何迁移之前,都有几个重要的步骤,爬虫可以提供帮助,不应错过。
1) 抓取现有站点
首先,确保您已存储现有实时网站的完整抓取。 这对于以下方面至关重要:
- 用作基准并将其与暂存站点进行比较以了解更改。
- 检查您的旧 URL 是否已在启动时重定向到新的 URL。
- 备份数据,以防您需要参考它来帮助诊断迁移期间的任何问题。
在开始抓取之前,请记住调整配置以收集将来可能需要参考的任何其他数据。 这可能包括 hreflang、结构化数据、AMP 等。
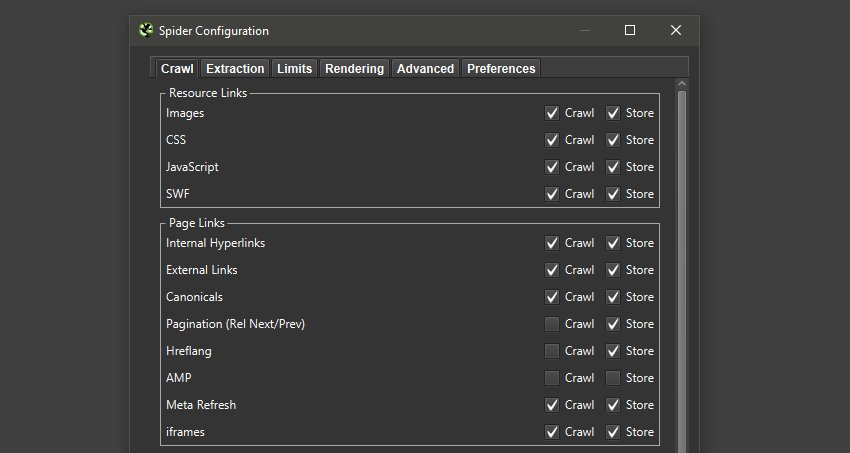
不要在此阶段遗漏任何 URL,请确保您的抓取尽可能全面。 因此请考虑:
- 是否存在需要 JavaScript 渲染 的客户端 JavaScript 依赖项。
- 任何其他域名、子域名或移动和桌面站点变体。
- 集成 XML 站点地图,并连接到 Google Analytics 和 Search Console 以确保任何可能重要(或有问题)的孤立页面不会被遗漏,方法是在其配置中启用“抓取在 GA/GSC 中发现的新 URL”。
- 从 Google Analytics 收集用户和转化数据,从 Google Search Console 收集搜索查询效果数据,以及链接数据(来自 Ahrefs、Majestic 或 Moz),以帮助根据收入、转化、流量、展示次数、点击次数和外部链接来关注重要页面。
- 如果站点经常更新,那么您可能需要在启动前的最后一刻再次运行此抓取,以确保不会遗漏任何内容。
在数据库存储模式下,抓取将自动保存,并且可以通过“文件 > 抓取”访问。 它们也可以通过“文件 > 导出”导出进行备份。 对于内存存储模式,请记住通过“文件 > 保存”保存抓取。
请在我们的用户指南中查看更多关于保存、打开、导出和导入抓取的信息。
2) 导出要重定向的 URL
如果网站 URL 发生更改,那么您需要收集一个全面的 URL 列表,以 301 永久重定向旧 URL 到新的 URL 等效项,作为您的重定向策略的一部分。
如果它是域名迁移并且 URL 路径保持不变,这可能相对简单,但如果整个网站 URL 结构发生更改,以及站点结构、设计和内容,则会迅速变得更加复杂。
您可以通过从对实时站点执行的抓取中导出 URL 来获取现有 URL 的完整列表。 只需在完成抓取后单击“内部”选项卡上的“导出”即可。
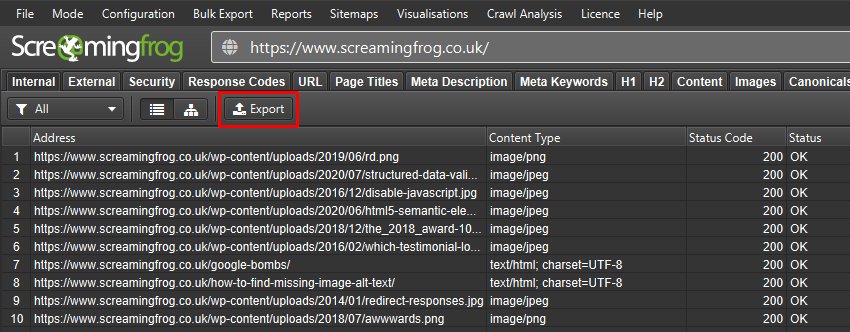
然后,这可以用作设置重定向的基础,以及其他来源,例如 GA、GSC、CMS 数据库、日志文件、Sistrix、SEMRush 以及来自 Ahrefs、Moz、Majestic 等的顶级页面,随后将它们映射到新的 URL 目标。
所有 URL 都应在适当的情况下重定向。 如果这不可能,您可以根据在步骤 1 中收集的转化、用户和链接数据,建立一组优先级最高的页面进行重定向和监控。
迁移前测试
当新站点在暂存环境中准备好进行测试时,您可以在启动前开始识别任何更改和问题。 同样,爬虫可以通过几种方式提供帮助。
3) 抓取暂存站点
您可以抓取暂存网站并查看数据,以帮助识别差异、问题和机会。
应限制搜索引擎和爬虫抓取暂存网站。 有多种方法可以防止抓取,例如 robots.txt、身份验证、IP 地址等,每种方法都需要不同的绕过方法,这在我们的“如何抓取暂存网站”教程中进行了更详细的介绍。

开发中的站点对 HTTP 请求的响应也可能与实时环境中的站点不同,并且通常具有 robots 指令,需要在 SEO Spider 中进行额外的配置。 当遇到 noindex、nofollow 等时,请阅读“如何配置设置以抓取暂存站点”。
抓取网站后,可以分析右侧的“概述”选项卡和数据。
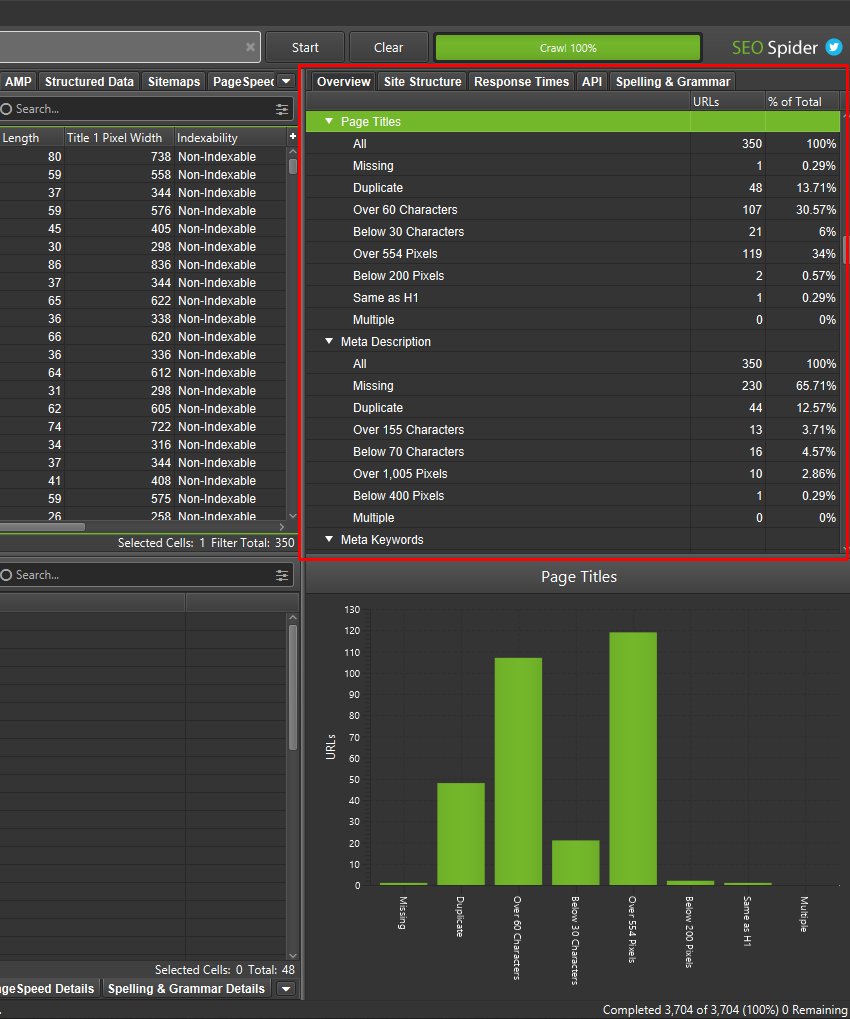
如果暂存站点完全不同——具有完全不同的架构、内容和 URL 结构,那么查看此抓取可能是迁移�前分析它的最佳方式。
但是,如果暂存站点具有相似的内容和 URL 结构,那么将其与现有网站直接比较以了解更改会更有效。
4) 使用 URL 映射比较实时站点与暂存站点
您可以直接将暂存网站与实时网站进行比较,并使用抓取比较中的“URL 映射”查看报告的差异。 此功能使您可以比较两种不同的 URL 结构,例如不同的主机名、目录,或使用正则表达式对 URL 进行更具体和细微的更改。
要将暂存站点与实时网站进行比较,您需要处于数据库存储模式,然后单击“模式 > 比较”并选择现有站点抓取和新的暂存站点抓取。

然后单击比较配置(“配置 > 比较”)和“URL 映射”。 输入一个正则表达式以将先前的抓取 URL 映射到当前的抓取。
在下面的示例中,现有网站仅映射到暂存网站主机名,因为它们共享相同的 URL 路径。
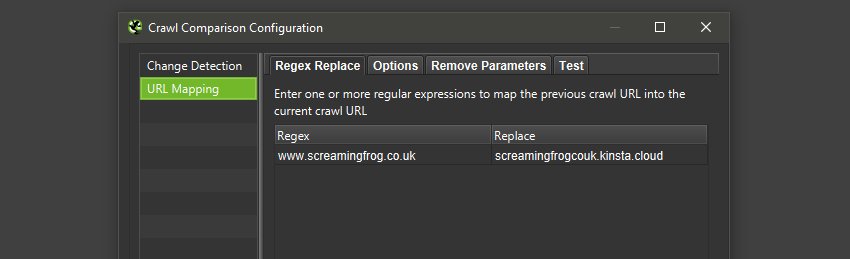
然后将现有的实时站点 URL 映射到新的暂存网站,因此将等效的 URL 相互比较以了解概述选项卡数据、问题和机会、站�点结构选项卡以及更改检测。
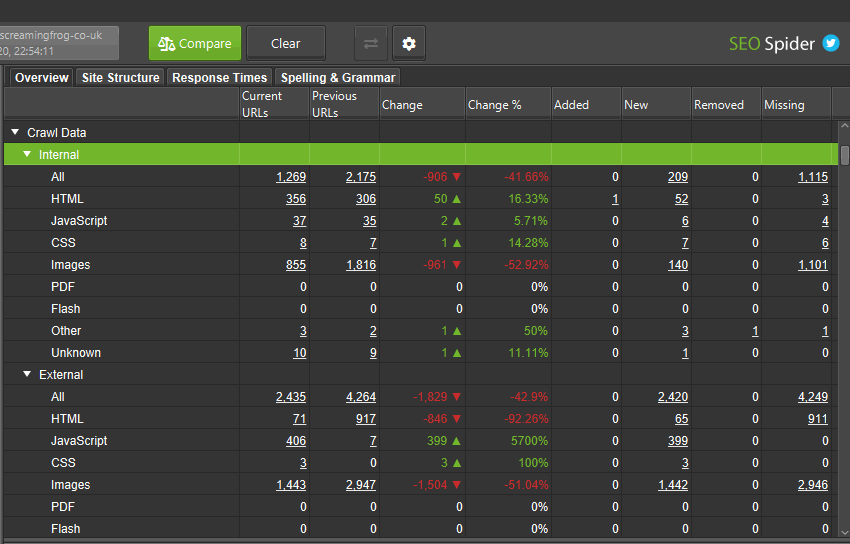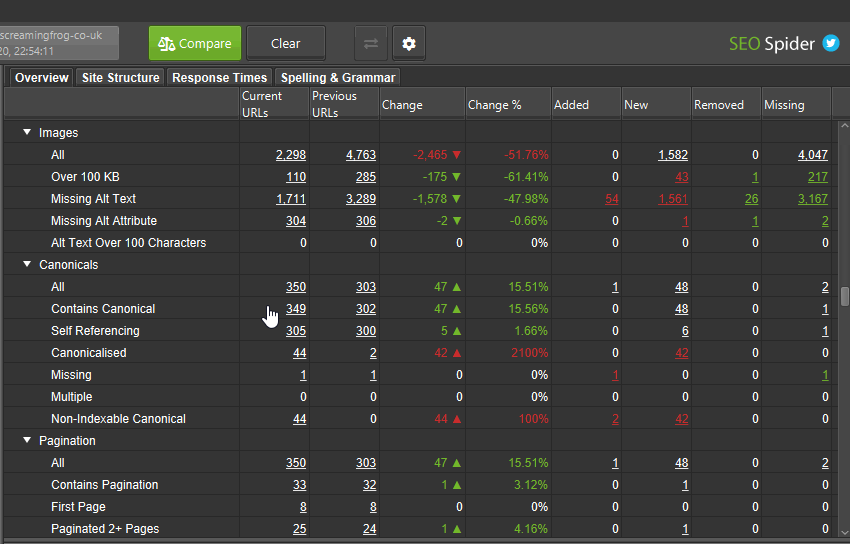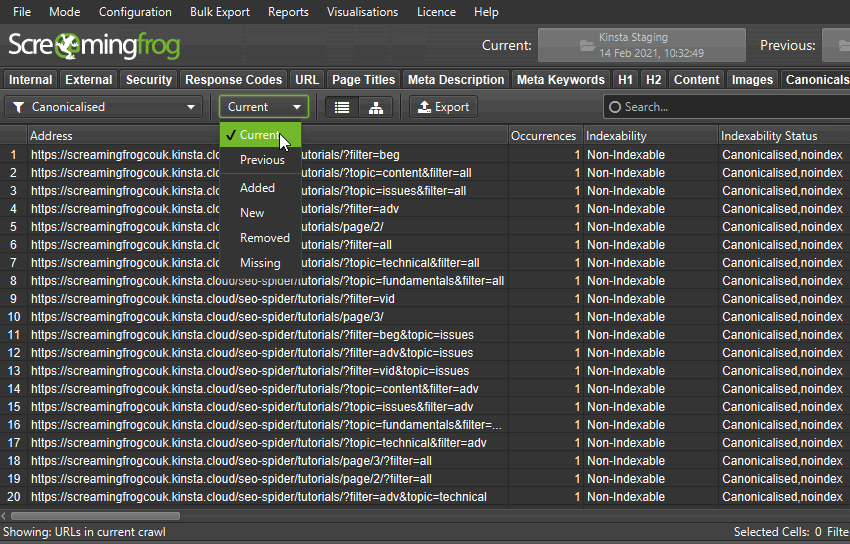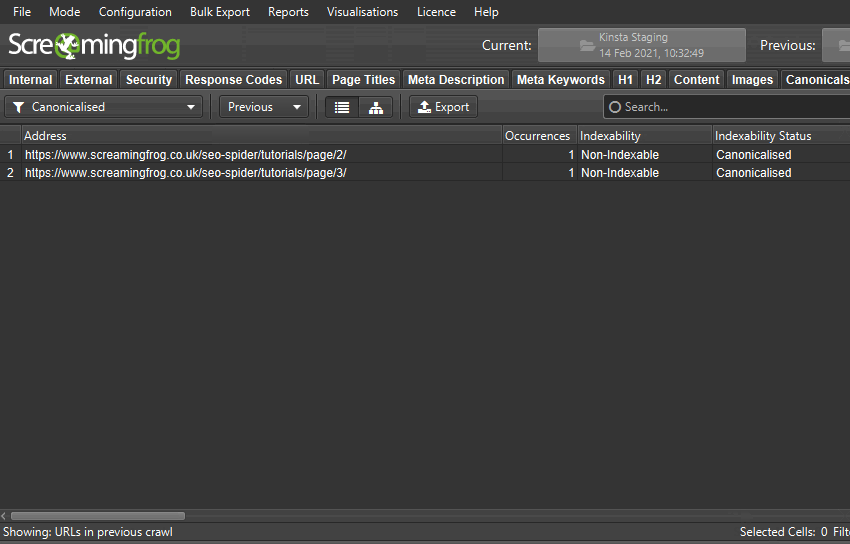
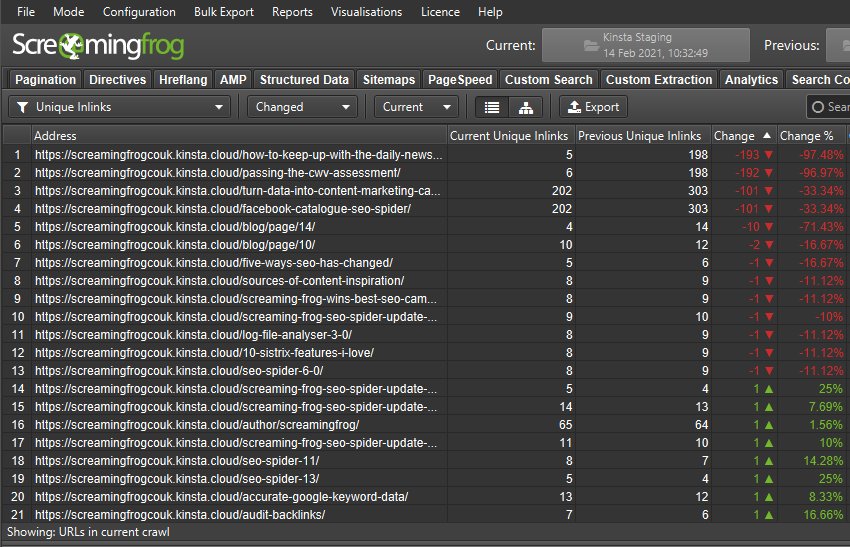
您可以单击列中的数字以查看哪些 URL 已更改,并使用主窗口视图上的过滤器在当前和先前的抓取之间切换,以及添加、新建、删除或缺失。
有四列(以及主窗口视图上的过滤器)可帮助细分选项卡和过滤器中已更改的 URL。
- 已添加 – 现有网站抓取中的 URL 已移动到暂存网站抓取的过滤器。
- 新建 – 不在现有网站抓取中的新 URL,位于暂存网站抓取和过滤器中。
- 已删除 – 现有网站抓取的过滤器中的 URL,但不在暂存网站抓取的过滤器中。
- 缺失 – 在暂存网站抓取中未找到的 URL,位于现有网站抓取和过滤器中。
总而言之,“已添加”和“已删除”是同时存在于现有网站和暂存网站抓取中的 URL。“新建”和“缺失”是仅存在于其中一个抓取中的 URL。
这有助于确定新问题或修复是针对现有 URL 还是新 URL。
请查看我们的“如何比较抓取”教程,以了解使用抓取比较的演练。
5) 使用更改检测识别差异
在执行网站迁移时,尽可能保持不变并减少可能影响网站可见性的更改数量可能很有用。 例如,保持相��同的页面标题和元描述。
您可以使用“比较”模式下的“更改检测”来提醒您抓取之间已更改的元素。
要运行更改检测,请通过“配置 > 比较”(或顶部的“齿轮”图标)单击比较配置,然后选择要识别更改的元素和指标。
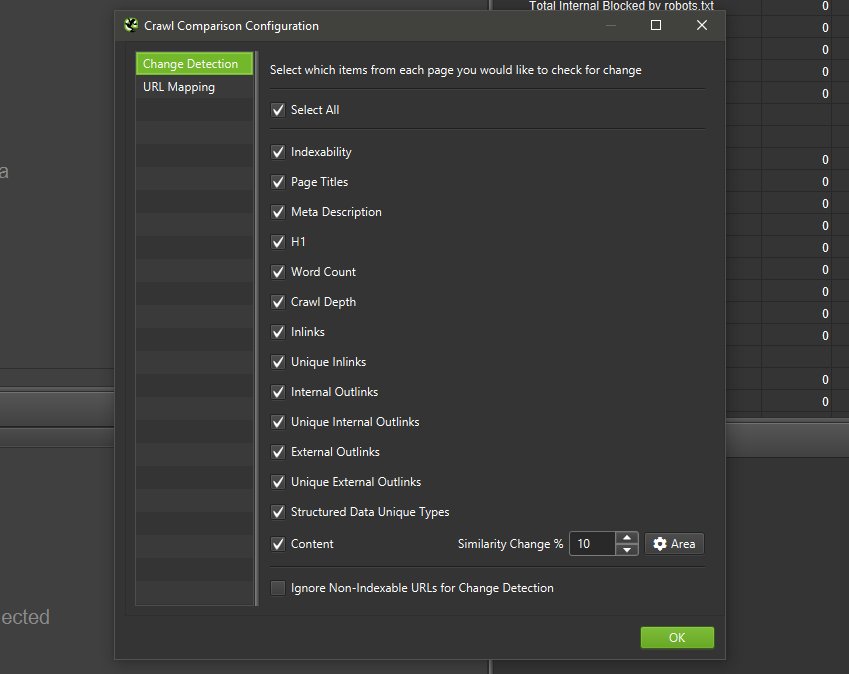
接下来,您只需单击顶部的“比较”。 然后将运行抓取比较分析,“更改检测”选项卡将显示为右侧概述选项卡和主视图中的最后一个选项卡。
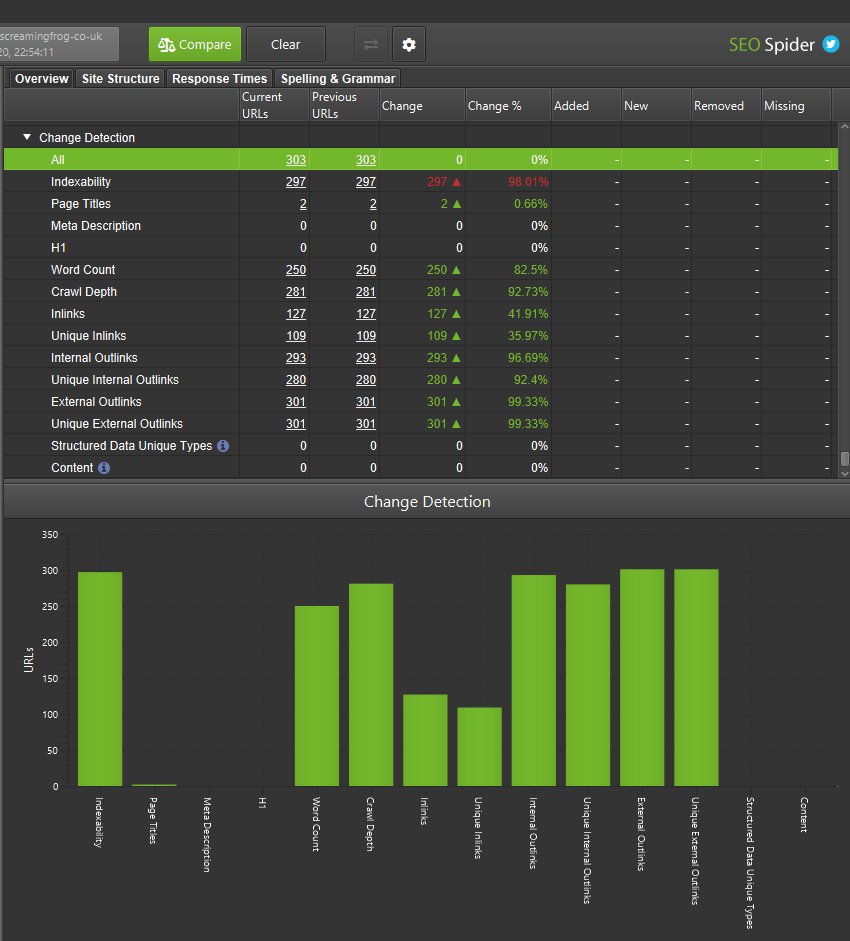
当前、先前和更改列中的数字将始终匹配。 这是因为它们都在传达当前和先前抓取之间已更改的 URL 数量。 在上面的示例中,2 个 URL 的页面标题已更改,250 个 URL 的字数已更改等。
您可以单击一个元素并在主窗口中查看更改。 例如,对于页面标题,您可以并排查看当前和先前的页面标题,以分析它们的更改方式。

如果您的网站迁移中站点结构和内部链接发生了很大变化,那么了解哪些页面丢失(或获得链接)以及更改了抓取深度非常重要。
所有这些项目对于页面在自然搜索中的表现至关重要,此功能可以��帮助您在测试期间监控和提醒您任何更改,以便可以在它们成为问题之前解决它们。
6) 重定向映射
虽然不是为此目的而构建的,但 SEO Spider 中的近重复项功能可用于帮助设置从旧 URL 到新 URL 的重定向映射(如果它们之间的内容相似)。
切换到列表模式(“模式 > 列表”)。 在“配置 > 内容 > 重复项”下“启用近重复项”并禁用“仅检查可索引页面是否存在重复项”。
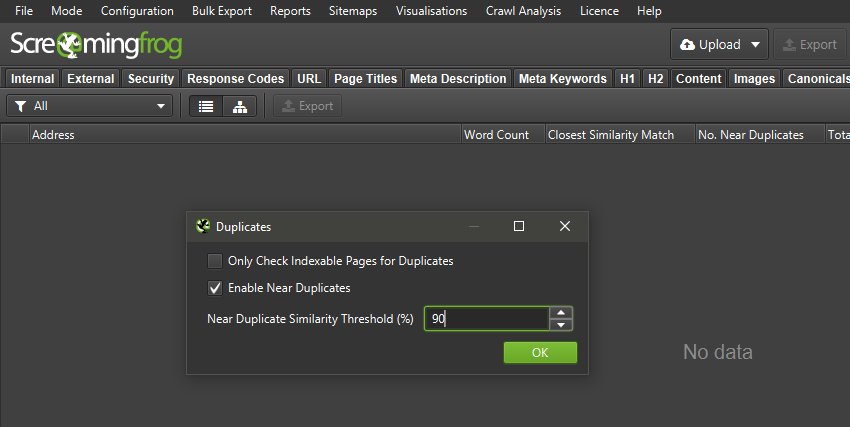
接下来,优化用于旧 URL 和新 URL 相似性分析的内容区域(“配置 > 内容 > 区域”)。
例如,如果旧站点和新站点的类别和产品描述类已更改,您可以“包括”它们。 如果模板相同,那么您可能不需要调整内容区域,该区域尝试挑选页面的主要内容区域。
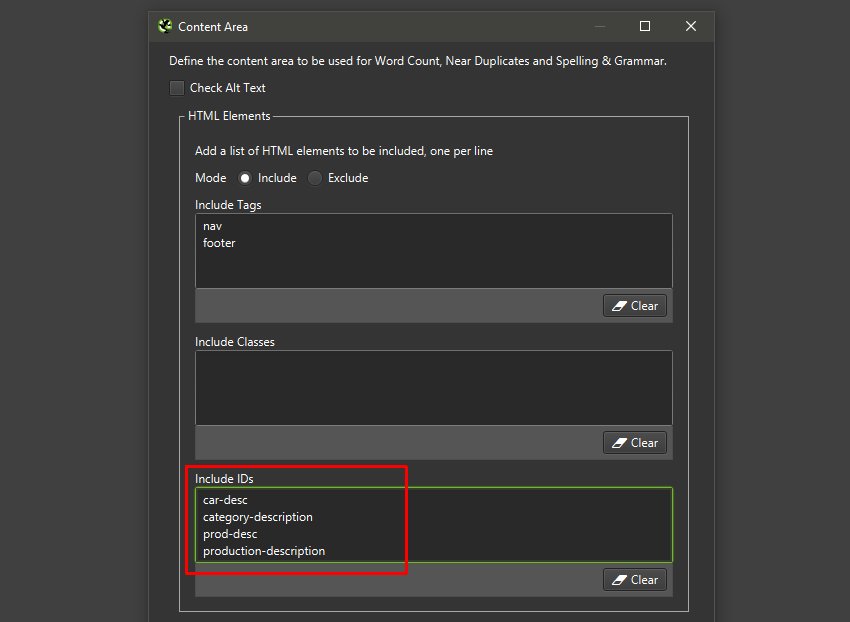
您可以上传列表模式下的新 URL 和旧 URL 并抓取它们,或者删除“配置 > 爬网 > 限制”下的抓取深度并输入现有站点和暂存网站主页。
等待抓取完成,然后在顶级菜单中点击“抓取分析 > 开始”。 导航到“内容”选项卡,该选项卡将显示近重复项及其相似性匹配的详细信息。
如果内容完全匹配,则每个 URL 将有 1 个近似重复项,相似度接近 100%。 如果内容发生重大更改,相似度得分和近似重复项的数量将有所不同。
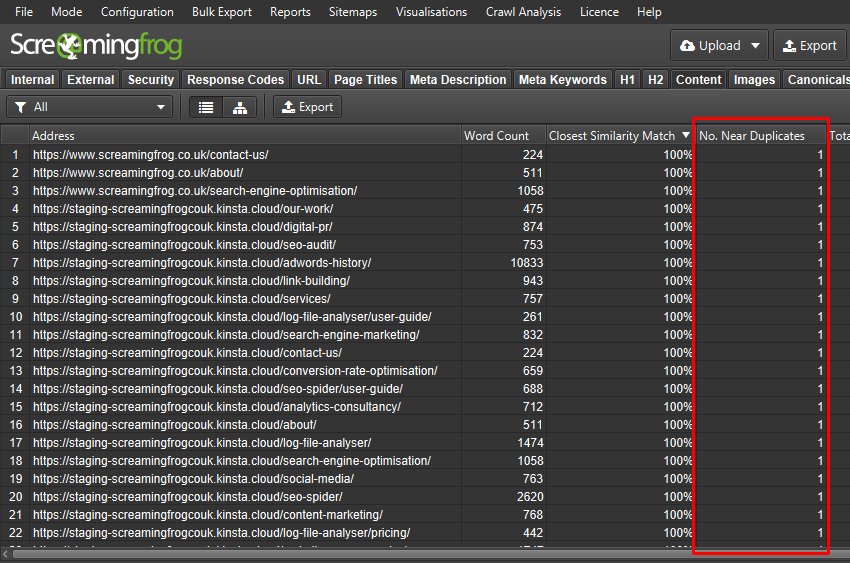
您可以在下部窗口“重复详情”选项卡中看到“地址”和“近似重复地址”。
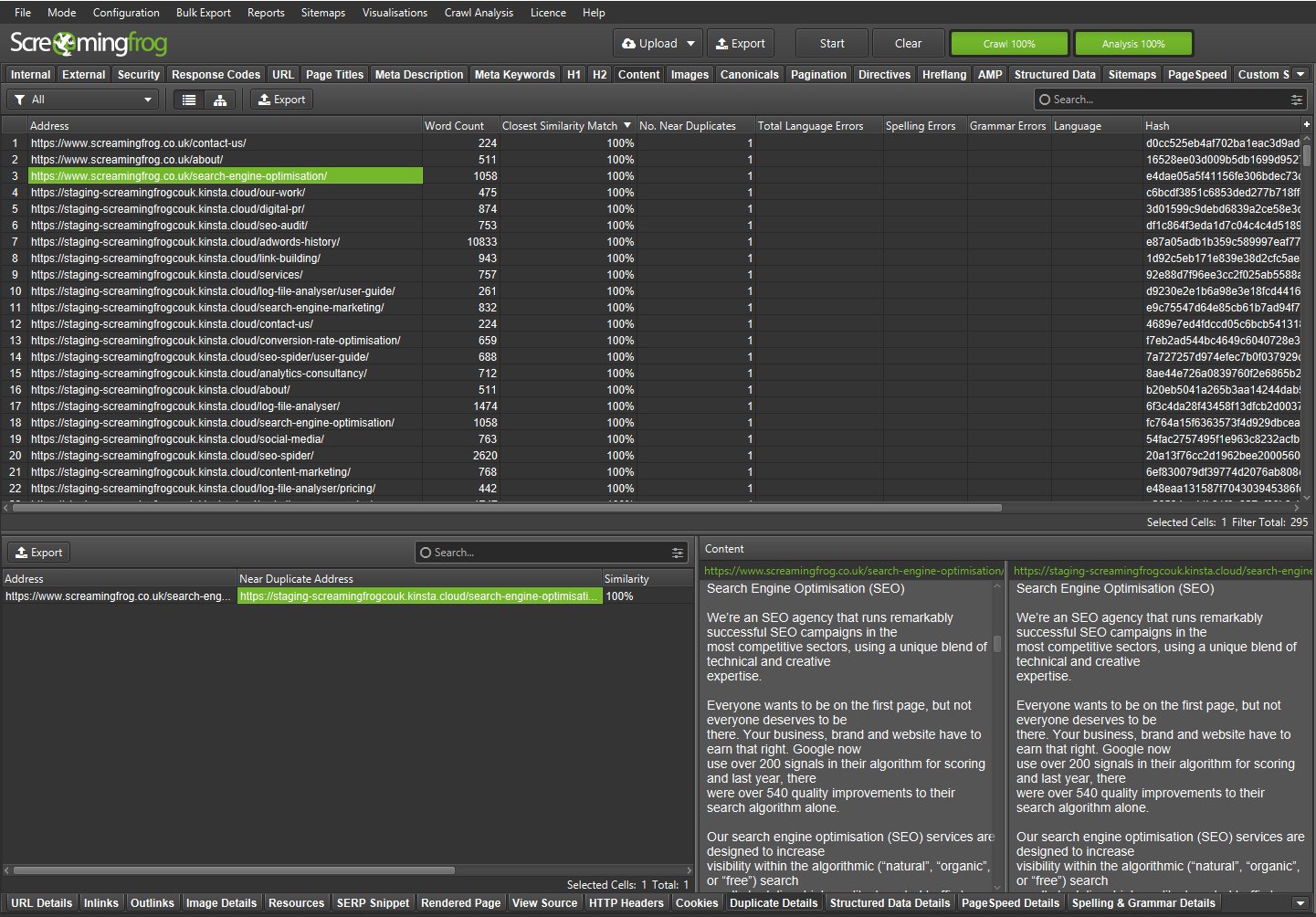
您可以通过“批量导出 > 内容 > 近似重复项”进行批量导出。
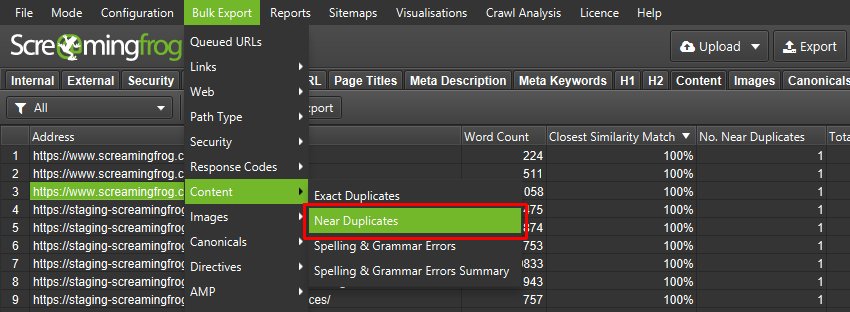
导出并不总是完美的,需要您仔细分析,但它可以为您提供一个简单的 1:1 URL 重定向映射基础。
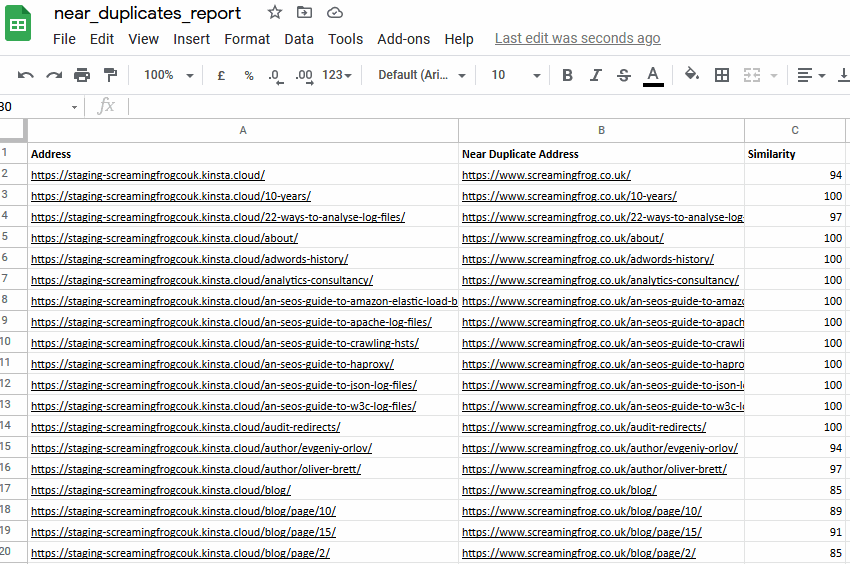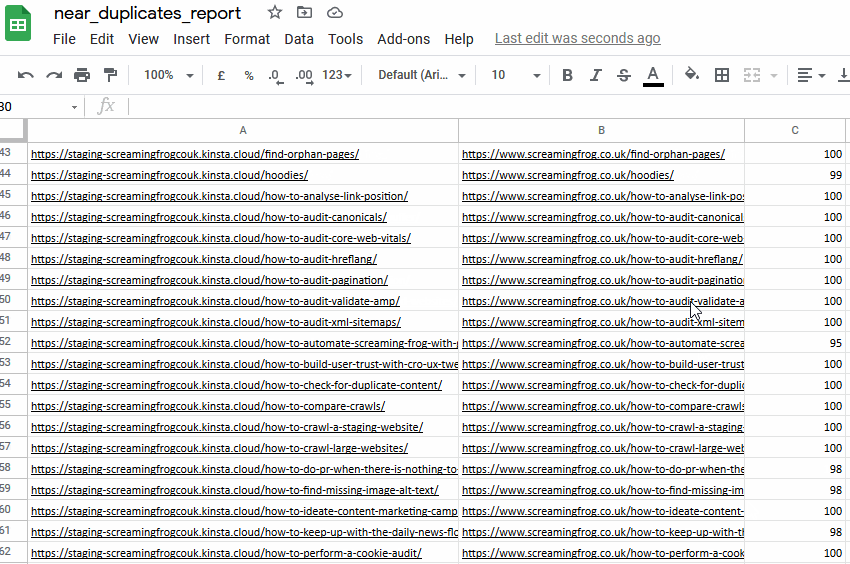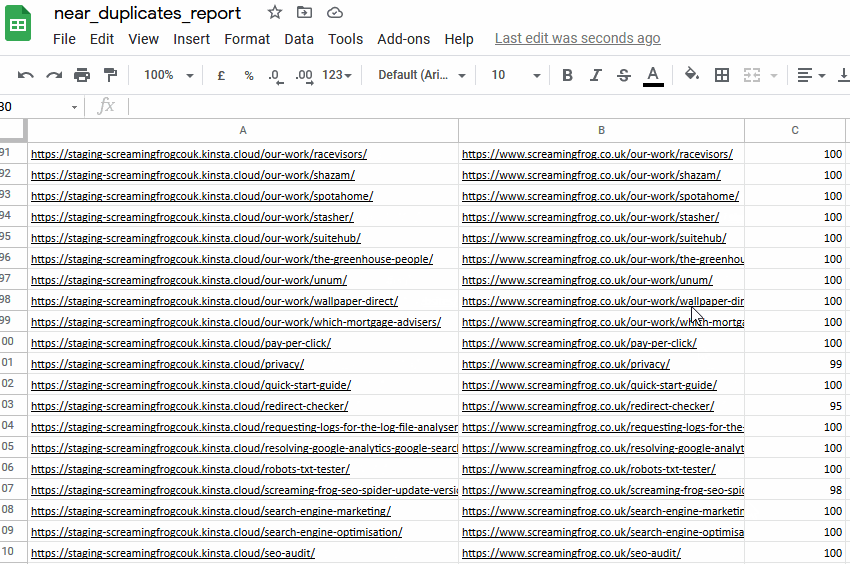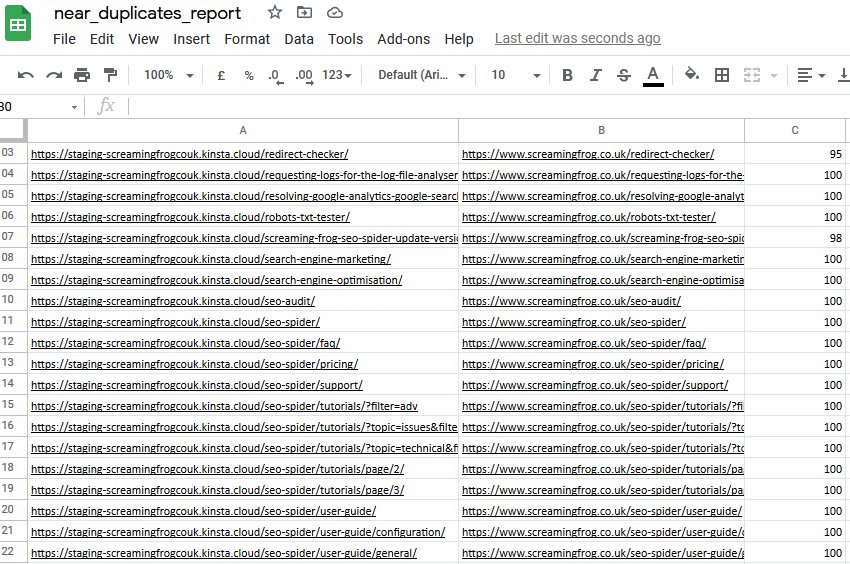
导出将包括“地址”列中的现有站点和暂存站点 URL,因此您可以在电子表格中对其进行排序并使用一个版本。
请参阅我们的教程“如何检查重复内容”,以了解有关此功能的更多信息。
迁移后
启动新网站时,通常会感到压力很大,但是爬虫可以通过几种方式来帮助您完成一些繁重的工作。
7) 启动时抓取新网站
执行网站抓取,并确保它是可抓取和可索引的。 检查站点和关键页面是否未被 robots.txt 阻止(响应代码 > 被 Robots.txt 阻止)。
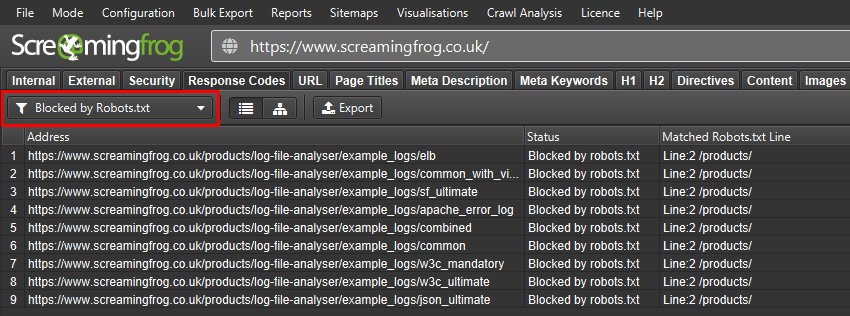
确保它们没有在 meta 标签或 HTTP 标头中携带任何 noindex、nofollow 或 none 指令(指令 > Noindex)。
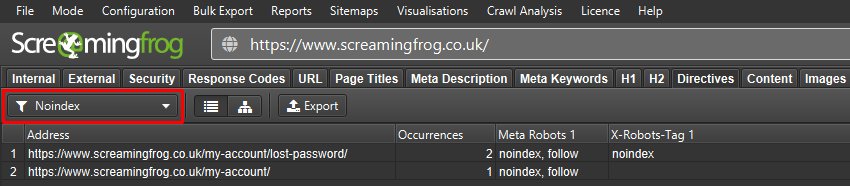
您希望在搜索引擎中排名的每个 URL 都应在“可索引性状态”列中显示“可索引”。
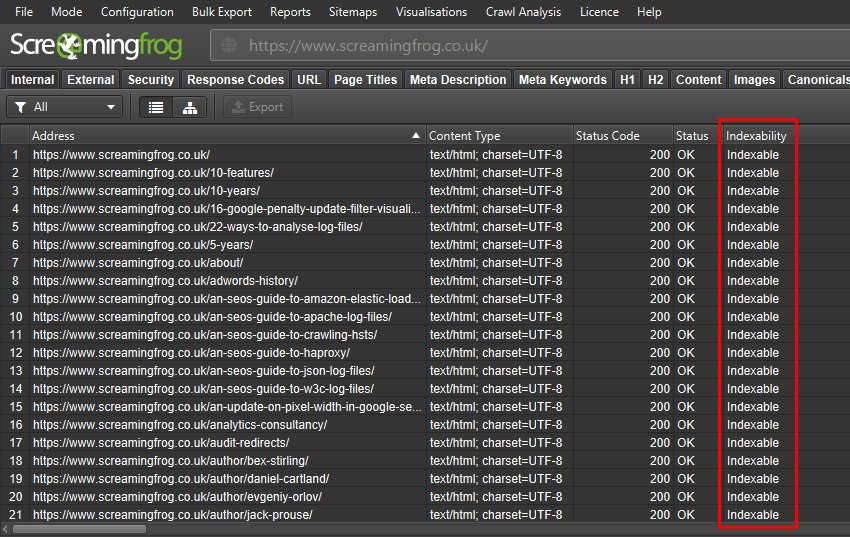
查看标题、规范、指令和 hreflang 等基本元素,以查找更多问题。
完成抓取后,您可以将抓取比较与旧站点抓取进行比较,并检查更改是否与暂存站点测试中的预期一致。
8) 审核重定向
如果 URL 发生更改,至关重要的是将它们 301 永久重定向到其新位置。 这对于确保索引和链接信号传递到新页面并避免有机可见性损失至关重要。
这意味着必须正确设置重定向到正确的目的地,没有错误、跳跃、循环、临时重定向或到不可索引的页面。 审核重定向意味着可以尽快识别和纠正任何问题。 这在大规模情况下具有挑战性,而 SEO Spider 可以提供帮助。
切换到列表模式(“模式 > 列表”),并在“配置 > 爬虫 > 高级”中启用“始终遵循重定向”。
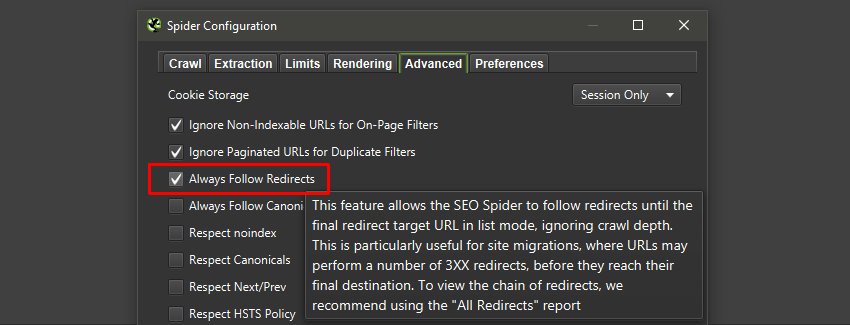
然后单击“上传”并粘贴步骤 1中的旧 URL 以进行抓取。
根据规模和时间安排,您可以首先上传优先级最高的 URL 集,以确保它们设置正确,但是您应该验证所有具有任何价值(收入、流量、链接等)的 URL 重定向(如果可能)��。
现在导出“所有重定向”报告。

此报告在电子表格中映射重定向(单击下面的小图像以查看更大的版本)。

此报告向您显示旧 URL(地址)和它们重定向到的最终 URL(最终地址),以及关键详细信息 -
- 链类型 – 例如,它是 HTTP 重定向、JavaScript 重定向还是 Meta Refresh。
- 重定向数 – 链中的跳数。
- 重定向循环 – 如果重定向返回到先前的 URL 并循环,则为 True 或 False。
- 链中的临时重定向 – 如果链中存在临时重定向,则为 True 或 False。
- 可索引性 – 最终地址 URL 是否可索引或不可索引一目了然。
- 可索引性状态 – URL 不可索引的原因。 例如,如果它是“noindex”。
- 最终内容 – 最终地址的内容类型。
- 最终状态代码 – 最终地址的 HTTP 状态代码(这将是没有响应、1XX、2XX、4XX 或 5XX)。
- 最终状态 – 最终地址的 HTTP 状态。
虽然此报告完成了许多繁重的工作,但应手动验证每个重定向的“最终地址”,以确保它是正确的目标 URL。 ��如果它转到不相关的解析页面,那么 Google 可能会忽略它,这将影响排名。
此过程可以帮助您快速识别问题,这些问题可以与开发人员共享,以便在它们开始成为大问题之前解决。 请阅读我们的教程“如何在站点迁移中审核重定向”。
9) 检查分析跟踪
启动后,检查分析跟踪是否正确设置应在每个清单上。
您可以使用自定义搜索(“配置 > 自定义 > 搜索”),使用“不包含”过滤器来搜索网站上每个页面的 HTML 头部中的完整跟踪标签。
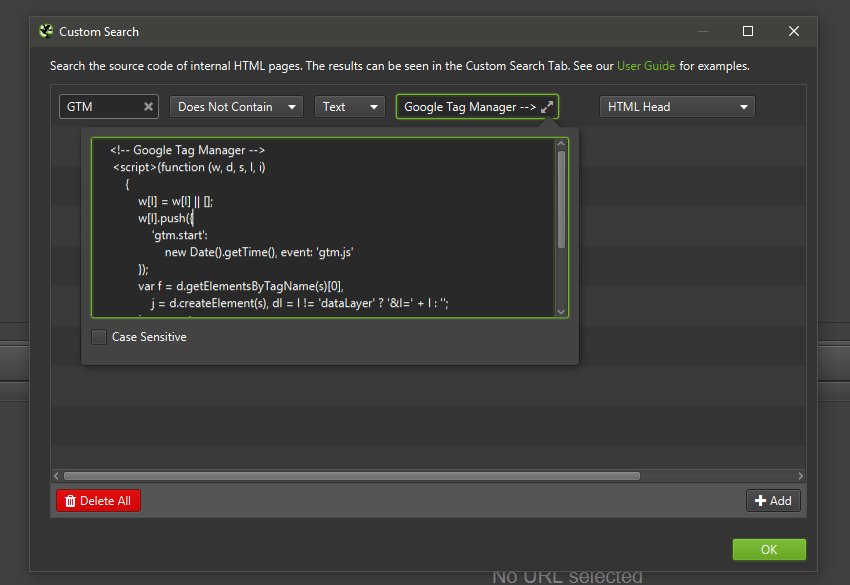
然后,自定义搜索选项卡和相应的“不包含”过滤器将标记网站上缺少分析标签的任何页面。
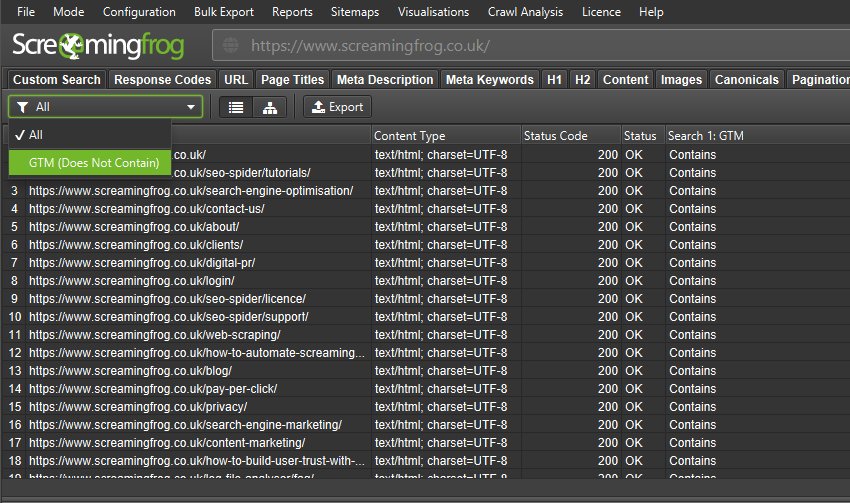
在这种情况下,每个页面都“包含”GTM 标签! 查看我们的教程如何使用自定义搜索。
10) 持续监控
执行定期抓取并将它们进行比较,以密切关注进度并掌握问题。
来自抓取概述的数据可用于站点运行状况的基准测试,并且在初始启动后,可以使用 PageSpeed Insights API 对关键区域(例如站点速度)执行更精细的分析,该 API 对每个页面执行 Lighthouse 审核。
此外,请使用 日志文件分析器(或电子表格!)密切关注日志文件(还记得那些吗?)中来自搜索机器人和抓取活动的错误。
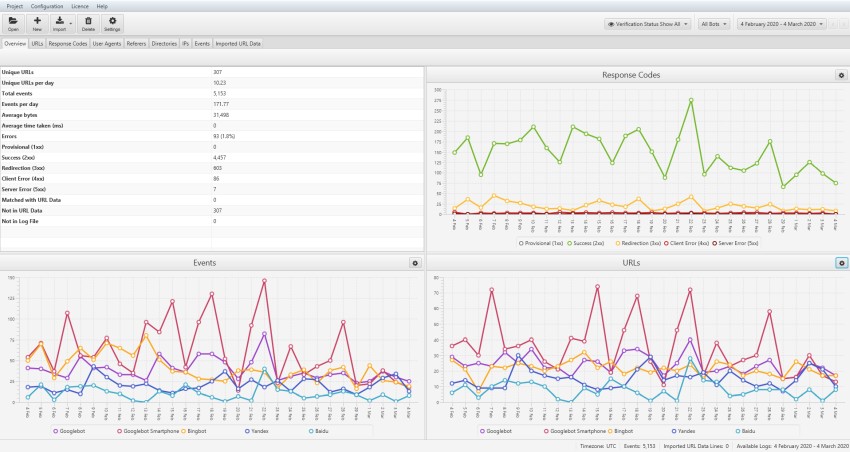
还可以使用 Google Search Console 中的“抓取统计信息”报告来监控抓取请求。
总结
本教程应帮助您更好地了解如何使用 SEO Spider,并在执行站点迁移时更有效地工作。
有关迁移策略和流程的更多建议,请从以下指南中了解更多信息 -
- 网站迁移指南:SEO 策略、流程和清单 – 来自 Modestos Siotos
- SEO 的网站迁移指南 – 来自 Faye Watt
- 成功网站迁移的终极指南 – 来自 Content King
请阅读我们的 Screaming Frog SEO Spider 常见问题解答 和完整的用户指南,以获取有关该工具的更多信息。
如果您有任何关于如何改进 SEO Spider 的疑问或反馈,请通过支持与我们的团队联系。