如何抓取 JavaScript 网站
了解如何抓取和审核富含 JavaScript 的网站和框架,例如 Angular、React 和 Vue.js。
JavaScript 抓取简介
从历史上看,像 Googlebot 这样的搜索引擎机器人不会抓取和索引使用 JavaScript 动态创建的内容,而只能看到静态 HTML 源代码中的内容。
然而,随着富含 JavaScript 的网站和框架(如 Angular、React、Vue.JS、单页应用程序 (SPA) 和渐进式 Web 应用程序 (PWA))的增长,这种情况发生了变化。Google 不断发展并弃用了其旧的 AJAX 抓取方案,现在像现代浏览器一样渲染网页,然后再对其进行索引。
虽然 Google 通常能够抓取和索引大多数 JavaScript 内容,但他们仍然建议使用服务器端渲染或预渲染,而不是依赖客户端方法,因为“处理 JavaScript 很困难,并非所有搜索引擎爬虫都能成功或立即处理它”。
由于这种增长和搜索引擎的进步,必须能够在 JavaScript 执行后读取 DOM,以了解评估网站时与原始响应 HTML 的差异。
传统上,网站爬虫也无法抓取 JavaScript 网站,直到我们在 Screaming Frog SEO Spider 软件中推出了首个 JavaScript 渲染功能。
这意味着页面首先在无头浏览器中完全渲染,然后抓取 JavaScript 执行后的渲染 HTML。
与 Google 一样,我们使用 Chrome 作为我们的 Web 渲染服务 (WRS),并保持更新,使其尽可能接近“常青”。SEO Spider 中使用的确切版本可以在应用程序中查看(“帮助 > 调试”,在“Chrome 版本”行上)。
本指南包含 4 个部分 –
如果您已经熟悉 JavaScript SEO 基础知识,则可以直接跳到如何抓取 JavaScript 网站部分,或继续阅读。
JavaScript SEO 基础知识
如果您正在审核网站,则应了解它是如何构建的,以及它是否依赖任何客户端 JavaScript 来获取关键内容或链接。JavaScript 框架彼此之间可能差异很大,并且 SEO 影响与传统的 HTML 网站不同。
核心 JavaScript 原则
虽然 Google 通常可以抓取和索引 JavaScript,但需要了解一些核心原则和限制。
- 页面的所有资源(JS、CSS、图像)都需要可供抓取、渲染和索引。
- Google 仍然需要干净、唯一的页面 URL,并且链接必须位于正确的 HTML 锚标记中(您可以提供静态链接,以及调用 JavaScript 函数)。
- 他们不会像用户一样点击并加载渲染后的其他事件(例如点击、悬停或滚动)。
- 当确定网络活动已停止或超过时间阈值时,会拍摄渲染页面的快照。如果页面花费很长时间才能渲染,则存在被跳过的风险,并且元素将无法被看到和索引。
- 通常,Google 会渲染所有页面,但是如果页面在初始 HTTP 响应或静态 HTML 中具有“noindex”,则它们不会将页面排队进行渲染。
- Google 的渲染与索引是分开的。Google 最初会抓取网站的静态 HTML,并将渲染推迟到它有资源时。只有这样,它才会发现渲染 HTML 中提供的更多内容和链接。从历史上看,这可能需要一周的时间,但 Google 已经取得了重大改进,以至于中位数时间现在降至仅 5 秒。
了解 JavaScript SEO 的这些内容至关重要,因为网站的排名取决于渲染效果。
渲染策略
Google 建议使用渐进增强进行开发,仅使用 HTML 构建网站的结构和导航,然后使用 JavaScript 改进网站的外观和界面。
Google 建议使用服务器端渲染、静态渲染或水合作为一种解决方案,而不是依赖客户端 JavaScript,这可以提高性能为用户和搜索引擎爬虫。
- 服务器端渲染 (SSR) 和预渲染执行页面的 JavaScript,并向用户和搜索引擎提供页面的渲染初始 HTML 版本。
- 水合和混合渲染(也称为“同构”)是指渲染可以在服务器端进行,用于初始页面加载和 HTML,而在客户端进行,用于非关键元素和页面。
许多 JavaScript 框架(如 React 或 Angular Universal)允许服务器端和混合渲染。
动态渲染可以用作一种解决方法,但 Google 不建议将其作为长期解决方案。当无法对前端代码库进行更改时,这可能很有用。动态渲染意味着在客户端渲染(针对用户)和预渲染内容(针对特定用户代理,在本例中为搜索引擎)之间进行切换。这意味着爬虫将获得网页的静态 HTML 版本,用于抓取和索引。
动态渲染被视为一种权宜之计,而不是一种长期策略,因为它不具备上述某些解决方案的用户体验或性能优势。如果您有此设置,则可以通过在 SEO Spider 中将用户代理切换到 Googlebot(“配置 > 用户代理”)来对其进行测试。
JavaScript 索引复杂性
即使 Google 通常能够抓取和索引 JavaScript,也还有其他注意事项。
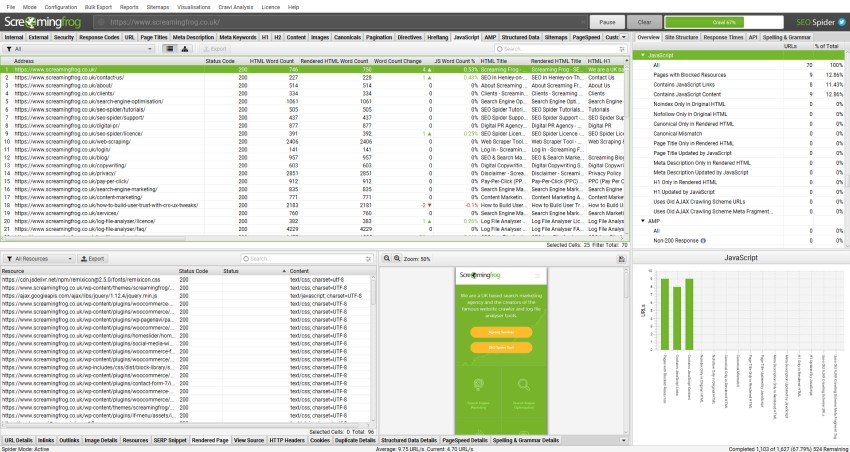
Google 有一个两阶段索引过程,他们最初会抓取和索引静态 HTML,然后在资源可用时返回以渲染页面并抓取和索引渲染 HTML 中的内容和链接。
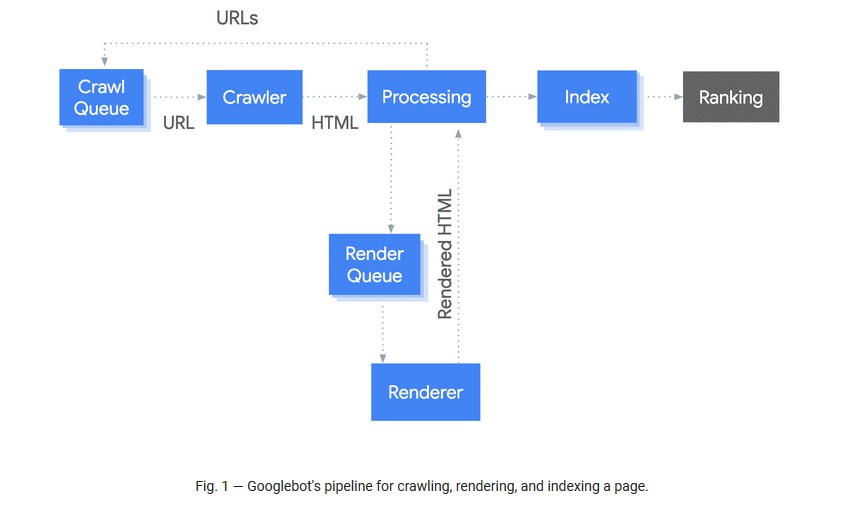
抓取和渲染之间的中位数时间为 5 秒 – 但是,它取决于资源可用性,因此可能会更长,这对于依赖及时内容的网站(例如发布商)来说可能存在问题。
如果由于某种原因渲染花费的时间更长,则可以使用原始响应中的元素(例如元数据和规范链接)来获取页面,直到 Google 在资源可用时对其进行渲染。除非它们具有指示 Googlebot 不要索引页面的 robots 元标记或标头,否则将渲染所有页面。因此,初始 HTML 响应也需要保持一致。
其他搜索引擎(如 Bing)难以大规模渲染和索引 JavaScript,并且由于 JavaScript 的脆弱性,很容易遇到错误或阻止渲染所需的资源 – 这可能会阻碍渲染和内容的索引。
总而言之,渲染和索引有很多微妙之处 –
无论是两阶段索引、JavaScript 错误、资源阻止还是原始 HTML 中的指令,这些指令指示机器人甚至不要进入渲染阶段。
虽然通常这些都不是问题,但依赖客户端渲染可能意味着一个错误或简单�的疏忽代价极其高昂,因为它会影响页面的索引。
如何识别 JavaScript
识别使用 JavaScript 框架构建的站点可能非常简单,但是,识别使用 JavaScript 动态调整的页面、部分或 HTML 元素和标记可能更具挑战性。
您可以通过多种方式了解站点是否使用 JavaScript 构建。
抓取
这是许多人的起点,您可以使用 Screaming Frog SEO Spider 使用默认设置继续并开始抓取网站。
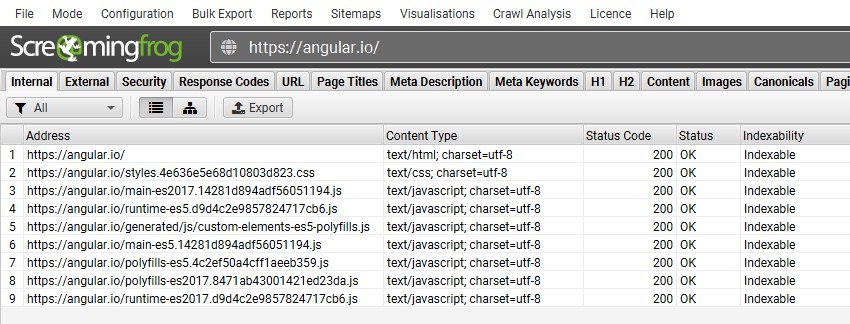
默认情况下,它将以“仅文本”模式抓取,这意味着它会在 JavaScript 执行之前抓取原始 HTML。
如果站点仅使用客户端 JavaScript 构建,那么您通常会发现只有主页被抓取,并带有 200“OK”响应,以及一些 JavaScript 和 CSS 文件。
您还会发现页面在较低的“外链”选项卡中没有超链接,因为它们没有被渲染,因此无法看到。
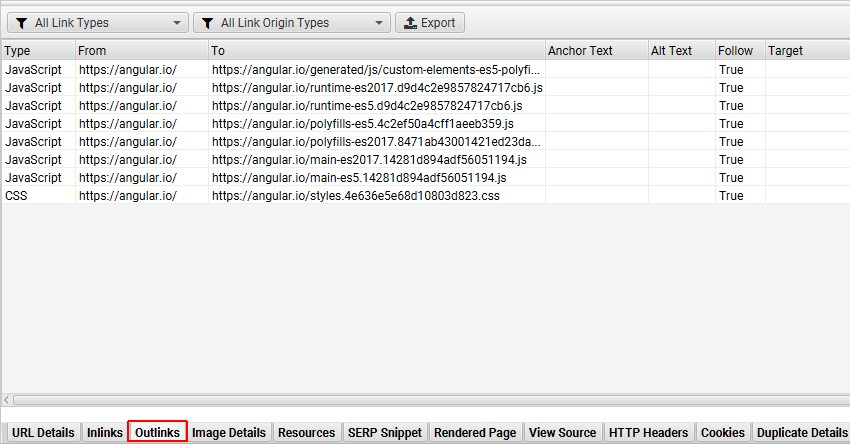
虽然这通常表明网站正在使用 JavaScript 框架进行客户端渲染,但它并没有告诉您有关整个网站的其他 JavaScript 依赖项。
例如,网站可能仅使用 JavaScript 将产品加载到类别页面上,或更新标题元素。
如何轻松找到这些?
为了更有效地识别 JavaScript,您需要切换到 JavaScript 渲染模式(“配置 > 蜘蛛 > 渲染”)并抓取站点,或来自整个网站的模板样本。
然后,SEO Spider 将抓取原始 HTML 和渲染 HTML,以识别仅在客户端可用的内容或链接的页面,并报告其他关键依赖项。
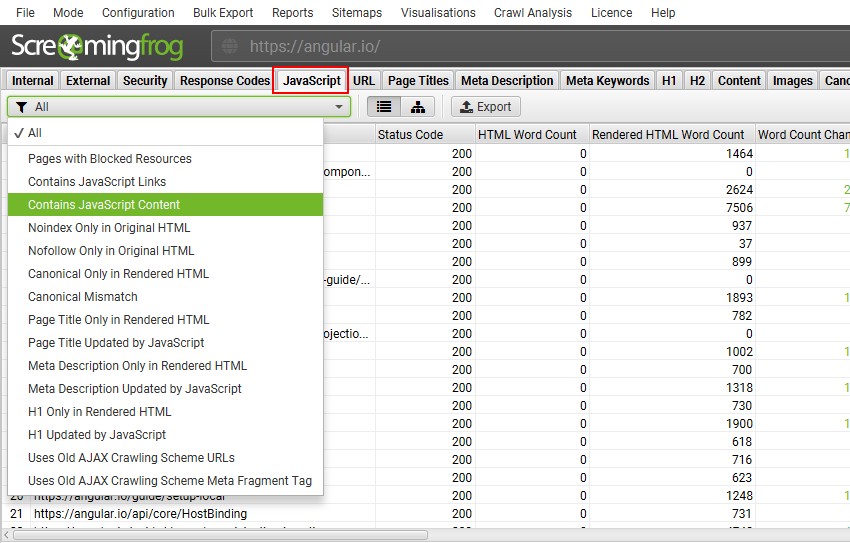
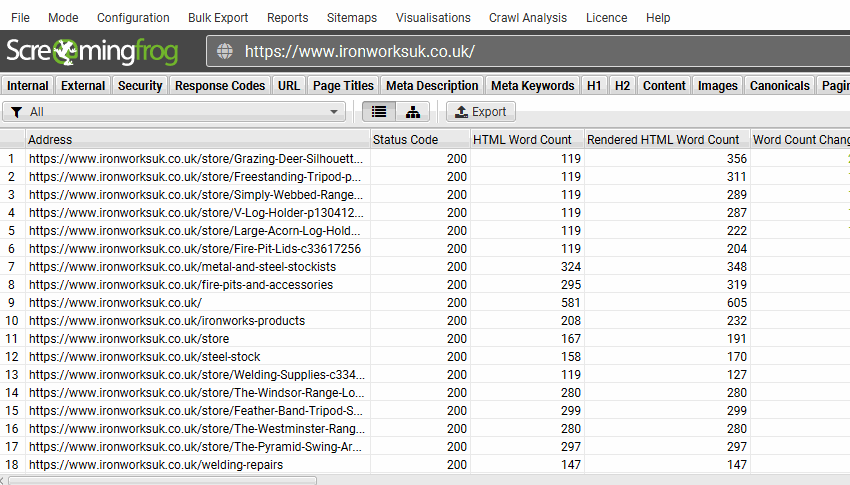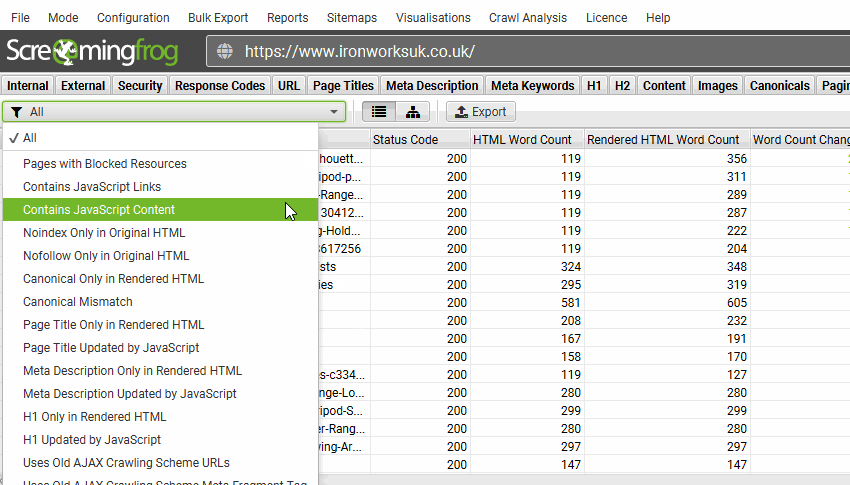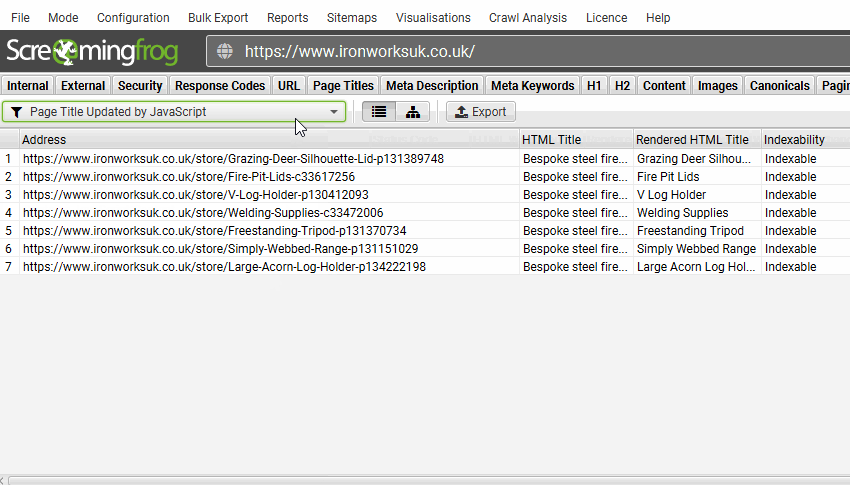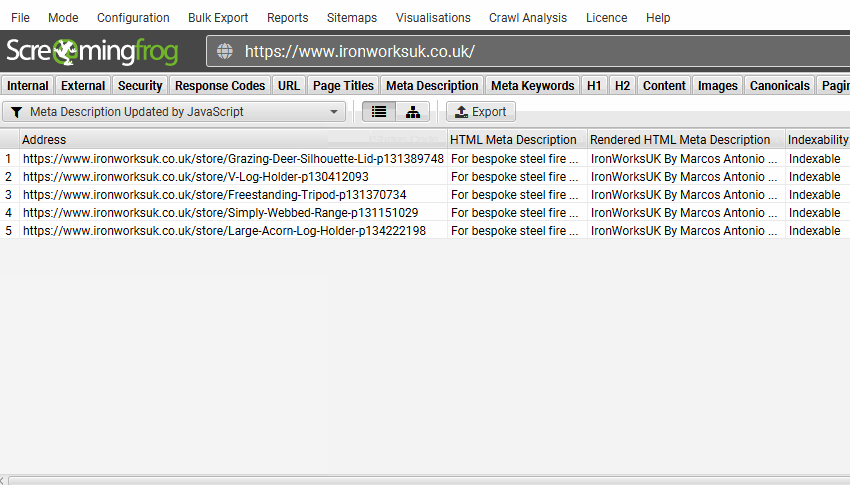
查看“JavaScript 选项卡”,其中包含围绕使用客户端 JavaScript 审核网站的常见问题的综合列表。
该工具将标记是否仅在 JavaScript 之后的渲染 HTML 中找到内容。
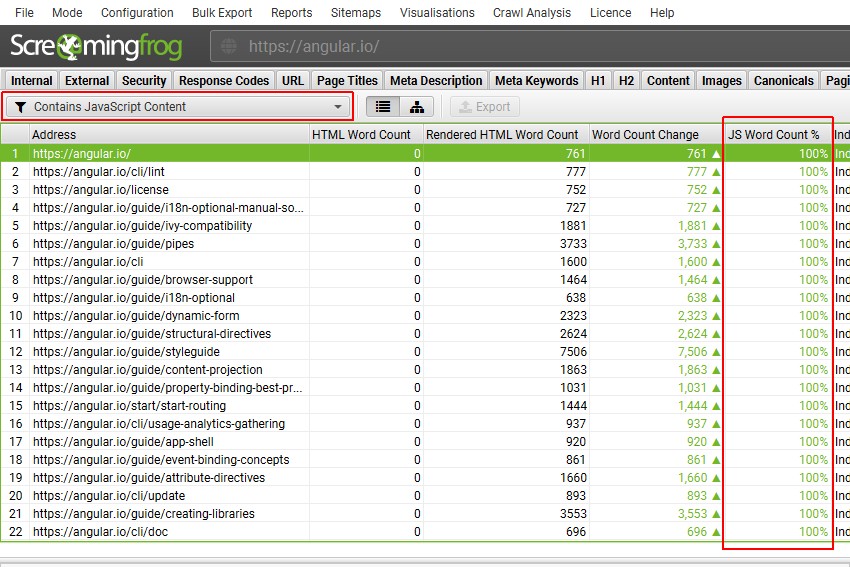
在此示例中,100% 的内容仅在渲染 HTML 中,因为该站点完全依赖于 JavaScript。
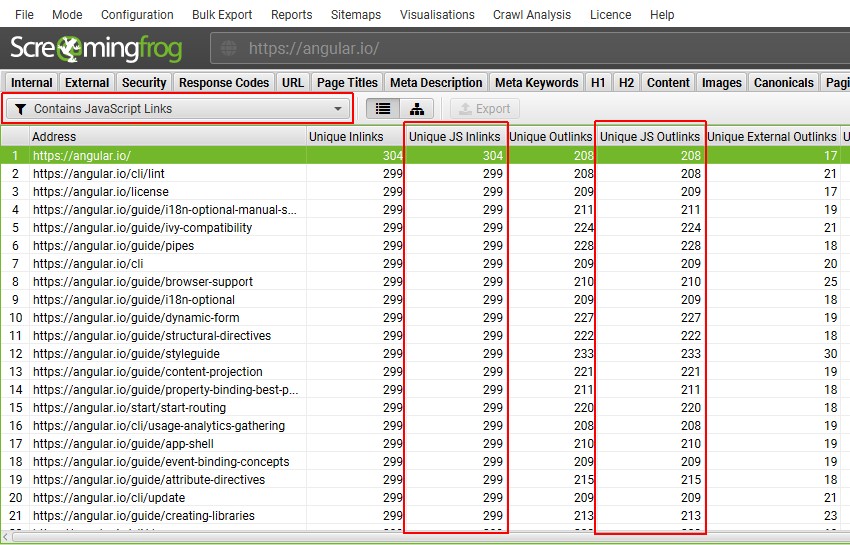
您还可以通过类似的方式找到仅在渲染 HTML 中具有链接的页面。
或者捕获 JavaScript 何时用于更新页面标题或元描述,而不是原始 HTML 中的内容。
在下一节中了解有关 JavaScript 选项卡中每个过滤器的更多信息。
虽然这些功能有助于扩展,但您可以使用其他工具和技术来进一步识别 JavaScript。
客户问答
这实际上应该是第一步。了解网站的最简单方法之一是与客户和开发团队交谈并提出问题。
该站点是用什么构建的?它是否使用 JavaScript 框架,或者是否具有任何客户端 JavaScript 依赖项来加载内容或链接?
非常明智的问题,您可能会得到有用的答案。
禁用 JavaScript
您可以在浏览器中关闭 JavaScript 并查看可用内容。这可以在 Chrome 中使用内置的开发者工具完成,或者如果您使用 Firefox,则 Web 开发者工具栏插件具有相同的功能。关闭 JavaScript 后内容是否可用?您可能只会看到一个空白页。
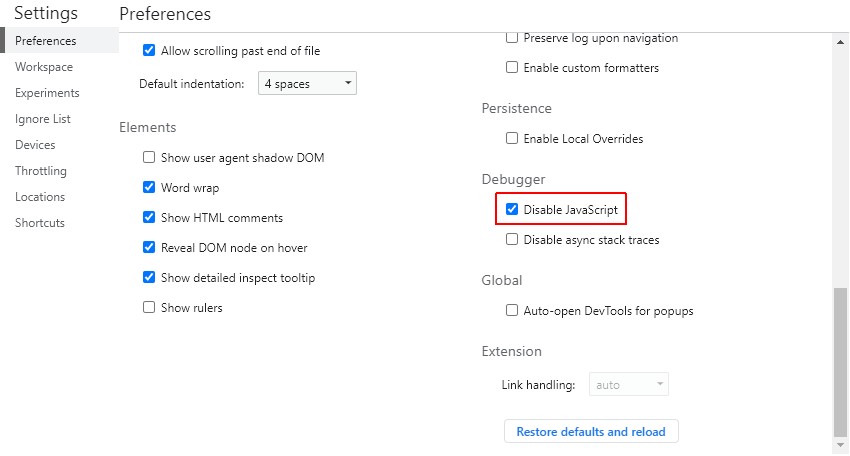
通常,在审核期间禁用 cookie 和 CSS 也很有用,以诊断可能遇到的其他抓取问题。
审核查看源代码
在 Chrome 中右键单击并“查看页面源代码”。这是 JavaScript 更改页面之前的 HTML。
是否有任何文本内容或 HTML?通常有 JS 框架和使用的库的迹象和提示。您是否能够在 HTML 源代码中看到内容和超链接?

您正在查看浏览器处理之前的代码以及 SEO Spider 将抓取的代码,而不是在 JavaScript 渲染模式下。
如果您运行搜索并且无法在源代码中找到内容或链接,那么它们将在 DOM 中动态生成,并且只能在渲染的代码中查看。
如果正文为空,如上面的示例所示,则这是一个非常明确的指示。
审核渲染的源代码
渲染的代码与静态 HTML 源代码有多大不同?在 Chrome 中右键单击并“检查元素”,以查看 JavaScript 执行后的渲染 HTML。
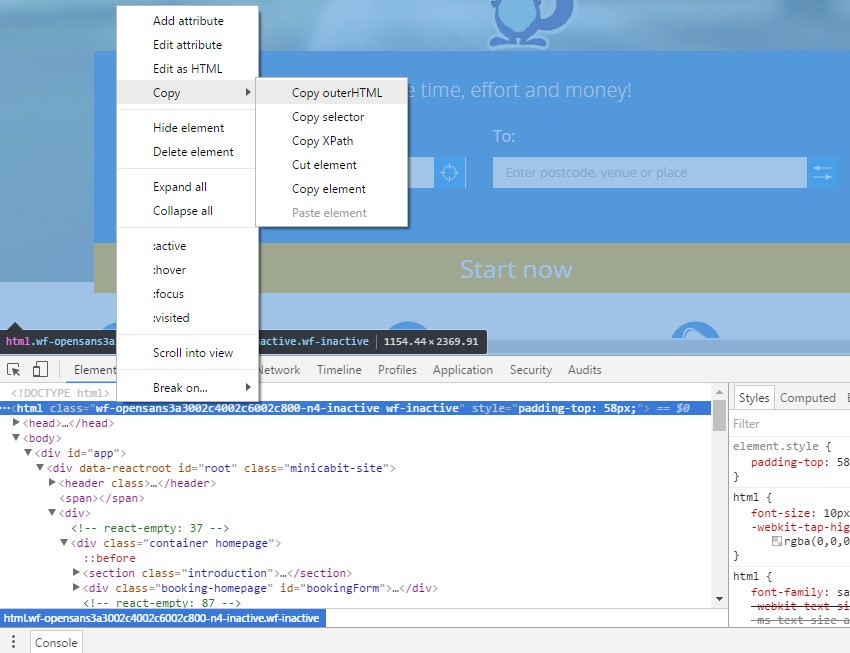
您通常可以在渲染的代码中看到 JS 框架名称,如下面的示例中的“React”。
您会发现内容和超链接位于渲染的代码中,但不在原始 HTML 源代码中。这是 SEO Spider 在 JavaScript 渲染模式下将看到的内容。
通过单击打开的 HTML 元素,然后“复制 > outerHTML”,您可以将渲染的源代码与原始源代码进行比较。
工具栏和插件
各种工具栏和插件,例如 BuiltWith 工具栏、Wappalyser 和 Chrome 浏览器的 JS 库检测器,可以帮助您一目了然地识别网页上使用的技术和框架。
这些工具并非总是准确的,但无需太多工作即可提供一些有价值的提示。
何时使用 JavaScript 抓取
虽然 Google 通常会渲染每个网页,但我们仍然建议有选择地使用 JavaScript 抓取——
- 首次分析网站以识别 JavaScript 时。
- 使用已知的客户端依赖项进行审计时。
- 在大型网站部署期间。
为什么要有选择性?
JavaScript 抓取速度较慢且强度更高,因为需要获取所有资源(无论是 JavaScript、CSS 还是图像)才能在后台的无头浏览器中渲染每个网页以构建 DOM。
虽然这对于较小的网站来说不是问题,但对于拥有成千上万甚至更多页面的大型网站来说,这可能会产生很大的影响。如果您的网站不依赖 JavaScript 来动态地大幅度操作网页,�则无需浪费时间和资源。
如果您希望默认启用 JavaScript 渲染进行抓取,请通过“配置 > 爬虫 > 渲染”设置 JavaScript 渲染模式,并保存您的配置。
如何抓取富 JavaScript 网站
要抓取富 JavaScript 网站和框架(例如 Angular、React 和 Vue.js)并识别依赖项,请切换到 JavaScript 渲染模式。
以下 10 个步骤应有助于您配置和审计大多数情况下遇到的 JavaScript 网站。
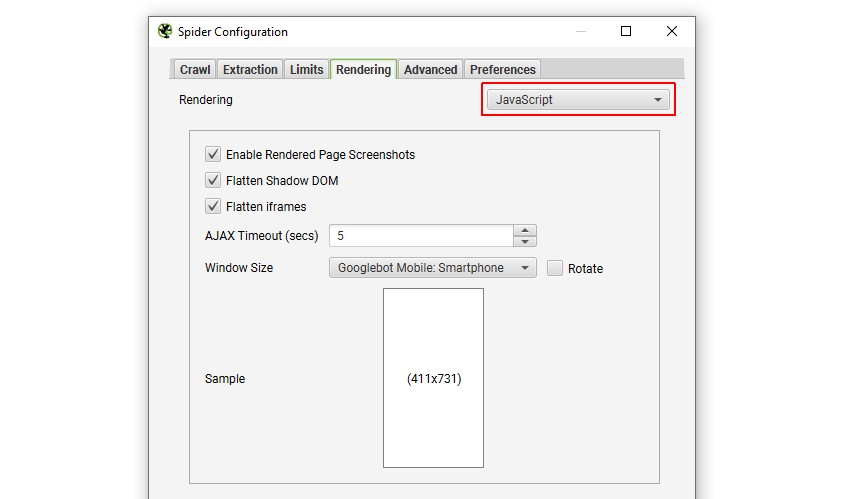
1) 将渲染配置为“JavaScript”
要抓取 JavaScript 网站,请打开 SEO Spider,单击“配置 > 爬虫 > 渲染”,然后将“渲染”更改为“JavaScript”。
2) 配置 User-Agent 和窗口大小
渲染的默认视口设置为 Googlebot 智能手机,因为 Google 主要使用其智能手机代理抓取和索引页面以进行移动优先索引。
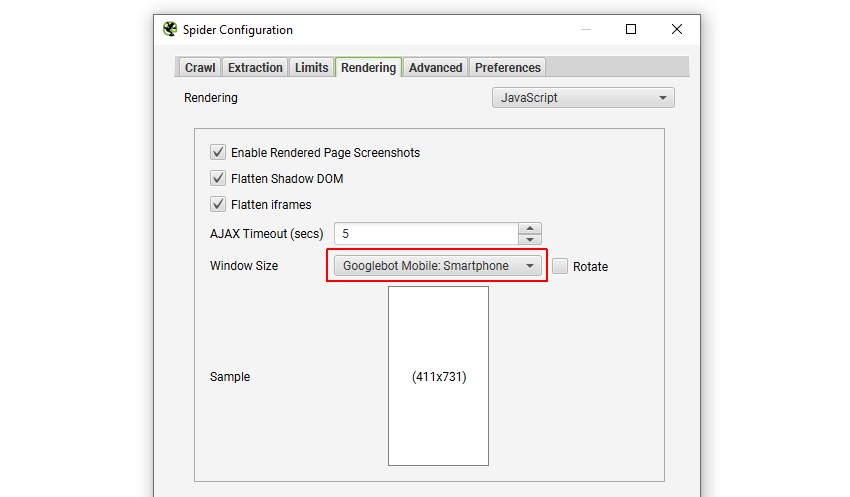
这意味着您将在较低的“渲染页面”选项卡中看到移动大小的屏幕截图。
您可以通过单击 JavaScript 渲染模式下的“配置 > 爬虫 > 渲染”,根据您自己的要求配置 user-agent(在“配置 > HTTP 标头 > User-Agent”下)和 窗口大小。
3) 检查资源和外部链接
确保在“配置 > 爬虫”下选中了 图像、CSS 和 JS 等资源。
如果资源位于不同的子域或单独的根域上,则应选中“检查外部链接”,否则它们将不会被抓取,因此也不会被渲染。
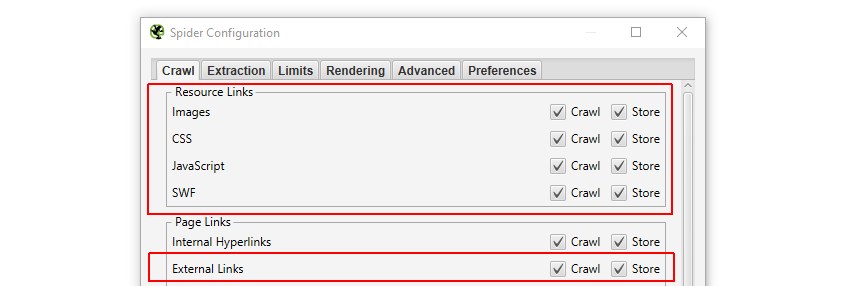
这是 SEO Spider 中的默认配置,因此您可以简单地单击“文件 > 默认配置 > 清除默认配置”以恢复到此设置。
4) 抓取网站
现在,在“输入要抓取的 URL”框中键入或粘贴您要抓取的网站,然后点击“开始”。
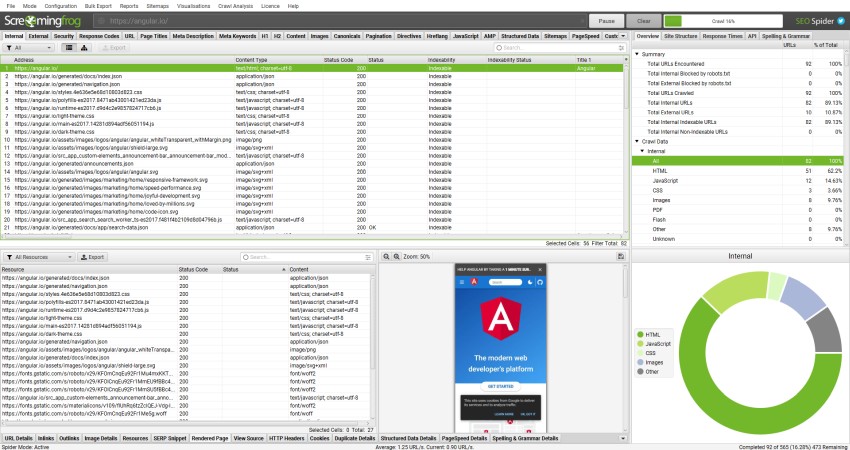
抓取体验与标准抓取不同,因为一开始可能需要一段时间才能在 UI 中显示任何内容,然后突然之间会同时出现大量 URL。这是因为 SEO Spider 会等待获取所有资源以渲染页面,然后才会显示数据。
5) 查看 JavaScript 选项卡
JavaScript 选项卡有 15 个过滤器,可帮助您了解 JavaScript 依赖项和常见问题。
您可以按以下与 SEO 相关的项目进行过滤——
- 具有被阻止资源的页面 – 具有被 robots.txt 阻止的资源(例如图像、JavaScript 和 CSS)的页面。这可能是一个问题,�因为搜索引擎可能无法访问关键资源以准确渲染页面。更新 robots.txt 以允许抓取所有关键资源并将其用于渲染网站内容。可以忽略非关键资源(例如 Google 地图嵌入)。
- 包含 JavaScript 链接 – 包含仅在 JavaScript 执行后在渲染的 HTML 中发现的超链接的页面。这些超链接不在原始 HTML 中。虽然 Google 能够渲染页面并查看仅客户端链接,但请考虑在原始 HTML 中的服务器端包含重要链接。
- 包含 JavaScript 内容 – 包含仅在 JavaScript 执行后在渲染的 HTML 中发现的正文文本的页面。虽然 Google 能够渲染页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- 仅在原始 HTML 中 Noindex – 在原始 HTML 中包含 noindex,但在渲染的 HTML 中不包含 noindex 的页面。当 Googlebot 遇到 noindex 标记时,它会跳过渲染和 JavaScript 执行。由于 Googlebot 跳过 JavaScript 执行,因此使用 JavaScript 删除渲染的 HTML 中的“noindex”将不起作用。仔细检查原始 HTML 中包含 noindex 的页面是否预计不会被索引。如果页面应该被索引,请删除“noindex”。
- 仅在原始 HTML 中 Nofollow – 在原始 HTML 中包含 nofollow,但在渲染的 HTML 中不包含 nofollow 的页面。这意味着在 JavaScript 执行之前,原始 HTML 中的任何超链接都不会被跟踪。仔细检查原始 HTML 中包含 nofollow 的页面是否预计不会被跟踪。如果应跟踪、抓取和索引链接,请删除“nofollow”。
- 仅在渲染的 HTML 中 Canonical – 仅在 JavaScript 执行后在渲染的 HTML 中包含 canonical 的页面。Google 可以处理渲染的 HTML 中的 canonical,但是他们不建议依赖 JavaScript,并且更喜欢它们在原始 HTML 中更早出现。渲染、冲突或多个 rel=”canonical” 链接标记的问�题可能会导致意外结果。在原始 HTML(或 HTTP 标头)中包含 canonical 链接,以确保 Google 可以看到它,并避免仅依赖渲染的 HTML 中的 canonical。
- Canonical 不匹配 – 在原始 HTML 中包含与 JavaScript 执行后在渲染的 HTML 中不同的 canonical 链接的页面。Google 可以在处理 JavaScript 后处理渲染的 HTML 中的 canonical,但是冲突的 rel=”canonical” 链接标记可能会导致意外结果。确保正确的 canonical 在原始 HTML 和渲染的 HTML 中,以避免向搜索引擎发出冲突的信号。
- 仅在渲染的 HTML 中页面标题 – 仅在 JavaScript 执行后在渲染的 HTML 中包含页面标题的页面。这意味着搜索引擎必须渲染页面才能看到它。虽然 Google 能够渲染页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- JavaScript 更新的页面标题 – 页面标题由 JavaScript 修改的页面。这意味着原始 HTML 中的页面标题与渲染的 HTML 中的页面标题不同。虽然 Google 能够渲染页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- 仅在渲染的 HTML 中 Meta 描述 – 仅在 JavaScript 执行后在渲染的 HTML 中包含 meta 描述的页面。这意味着搜索引擎必须渲染页面才能看到它。虽然 Google 能够渲染页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- JavaScript 更新的 Meta 描述 – meta 描述由 JavaScript 修改的页面。这意味着原始 HTML 中的 meta 描述与渲染的 HTML 中的 meta 描述不同。虽然 Google 能够渲染页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- 仅在渲染的 HTML 中 H1 – 仅在 JavaScript 执行后在渲染的 HTML 中包含 h1 的页面。这意味着搜索引擎必须渲染页面才能看到它。虽然 Google 能够渲染页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- JavaScript 更新的 H1 – h1 由 JavaScript 修改的页面。这意味着原始 HTML 中的 h1 与渲染的 HTML 中的 h1 不同。虽然 Google 能够渲染页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- 使用旧的 AJAX 抓取方案 URL – 仍然使用旧的 AJAX 抓取方案(包含 #! 哈希片段的 URL)的 URL,该方案已于 2015 年 10 月正式弃用。更新 URL 以遵循当今 Web 上的 JavaScript 最佳实践。尽可能考虑服务器端渲染或预渲染,并将动态渲染作为一种解决方法。
- 使用旧的 AJAX 抓取方案 Meta 片段标记 – URL 包含一个 meta 片段标记,表明该页面仍在使用旧的 AJAX 抓取方案,该方案已于 2015 年 10 月正式弃用。更新 URL 以遵循当今 Web 上的 JavaScript 最佳实践。尽可能考虑服务器端渲染或预渲染,并将动态渲染作为一种解决方法。如果站点仍然错误地包含旧的 meta 片段标记,则应将其删除。
6) 监控被阻止的资源
密切关注“JavaScript”选项卡中“具有被阻止资源的页面”过滤器下出现的任何内容。您可以浏览右侧的概览窗格,而不是单击选项卡。如果 JavaScript、CSS 或图像通过 robots.txt 被阻止(不响应或出错),则会影响渲染、抓取和索引。

也可以在“渲染页面”选项卡中查看每个页面的被阻止资源,该选项卡与下部窗口窗格中的渲染屏幕截图相邻。在严重的情况下,如果 JavaScript 站点完全阻止 JS 资源,则该站点将根本无法抓取。
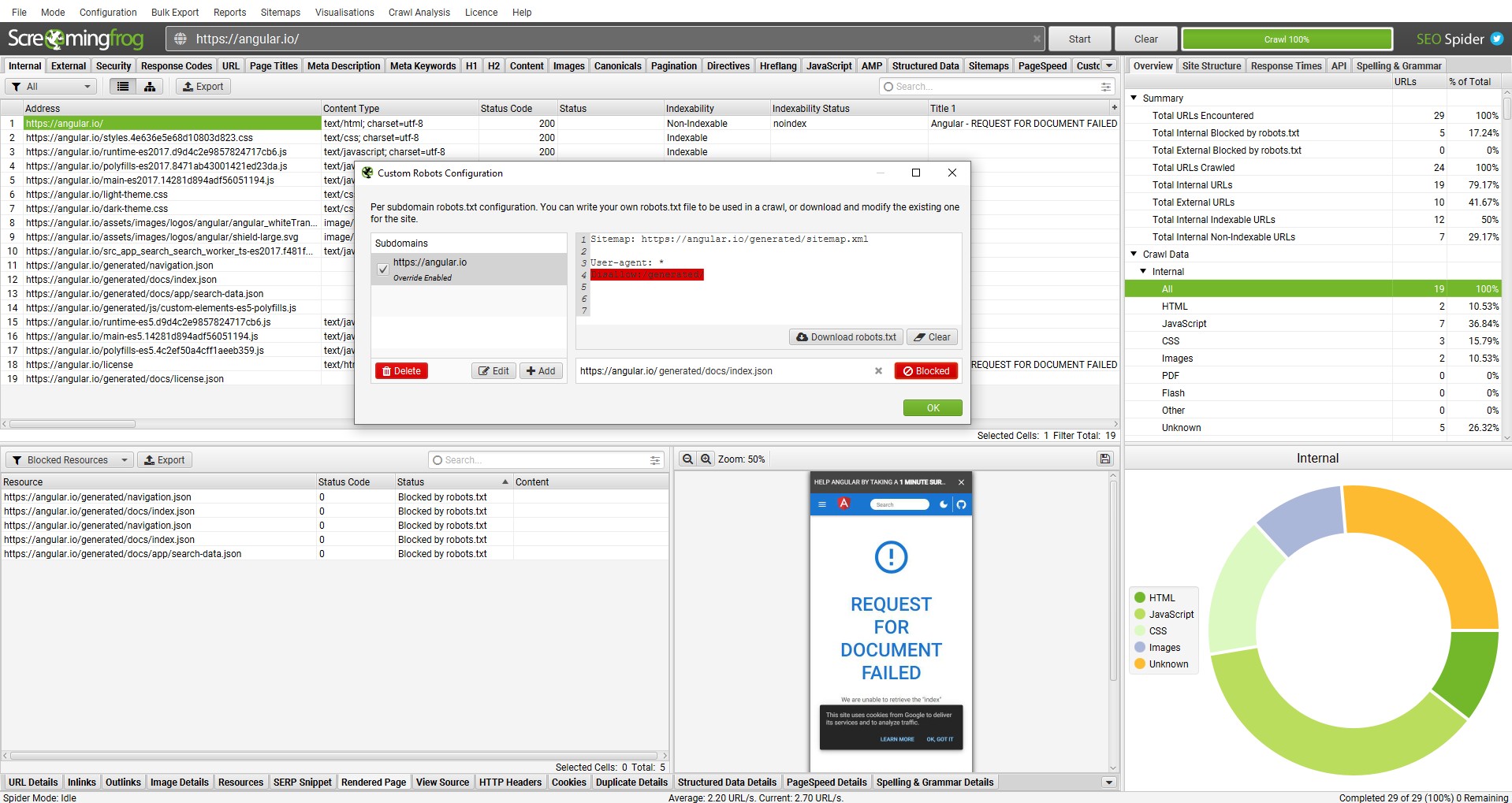
如果影响渲染的关键资源被阻止,则取消阻止它们以进行抓取(或使用 自定义 robots.txt 允许它们进行抓取)。您可以使用 排除 和自定义 robots.txt 功能测试不同的场景。
也可以在“响应代码 > 被阻止的资源”下查看各个被阻止的资源。

可以通过“批量导出 > 响应代码 > 被阻止的资源入站链接”报告批量导出它们,包括源页面。
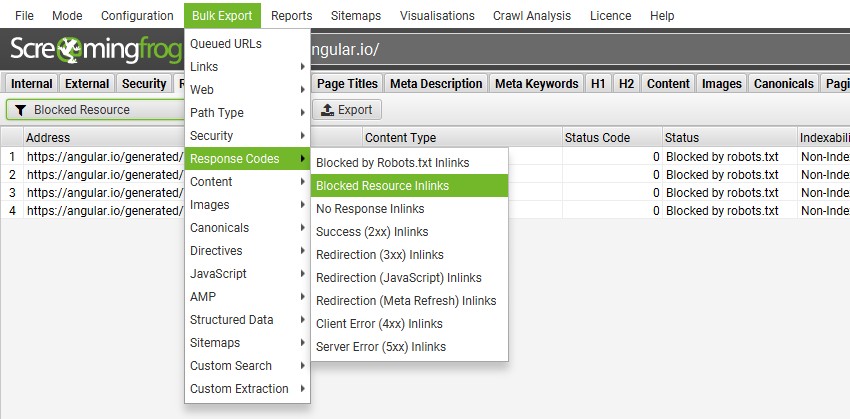
7) 查看渲染的页面
当以 JavaScript 渲染模式抓取并在顶部窗口中选择 URL 时,您可以在较低的“渲染页面”选项卡中查看 SEO Spider 抓取的渲染页面屏幕截图。
在分析现代搜索机器人能够看到的内容时,查看渲染的页面非常有用,并且在执行暂存审查时特别有用,在这种情况下,您无法使用 Google Search Console 中 Google 自己的 URL 检查工具。
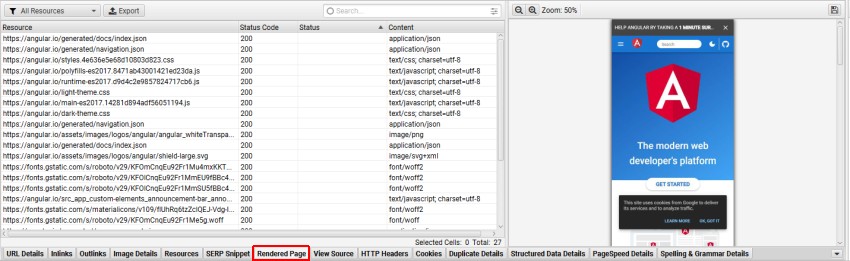
如果您在渲染的页面屏幕截图中发现任何问题,并且不是由于被阻止的资源引起的,则您可能需要考虑调整 AJAX 超时,或更深入地研究渲染的 HTML 源代码以进行进一步分析。
8) 比较原始 HTML 和渲染的 HTML 以及可见内容
在使用 JavaScript 时,您可能希望在 SEO Spider 中存储和查看 HTML 和渲染的 HTML。这可以在“配置 > 爬虫 > 提取”下进行设置,并选中相应的 存储 HTML 和 存储渲染的 HTML 选项。
然后,这会填充下部窗口“查看源代码”窗格,使您能够比较差异,并确信关键内容或链接存在于 DOM 中。单击“显示差异”以查看差异。
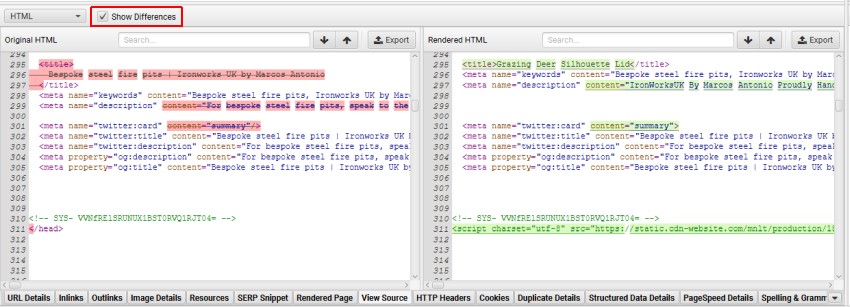
这对于各种场景都非常有用,例如调试在浏览器和 SEO Spider 中看到的内容之间的差异,或者只是在分析 JavaScript 如何渲染以及某些元素是否在代码中。
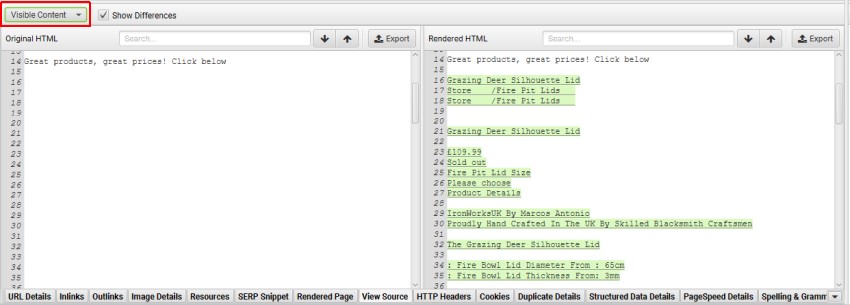
如果“JavaScript 内容”过滤器已触发某个页面,您可以将“HTML”过滤器切换为“可见内容”,以准确识别哪些文本内容仅在渲染的 HTML 中。
9) 识别仅 JavaScript 链接
如果“包含 JavaScript 链接”过滤器已触发,您可以通过单击顶部窗口中的 URL,然后单击下部“出站链接”选项卡并选择“渲染的 HTML”链接来源过滤器来识别哪些超链接仅在 JavaScript 执行后在渲染的 HTML 中发现。
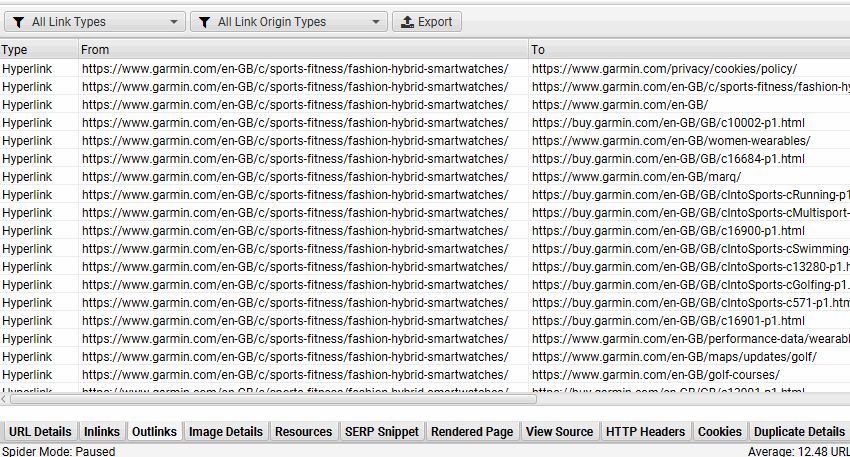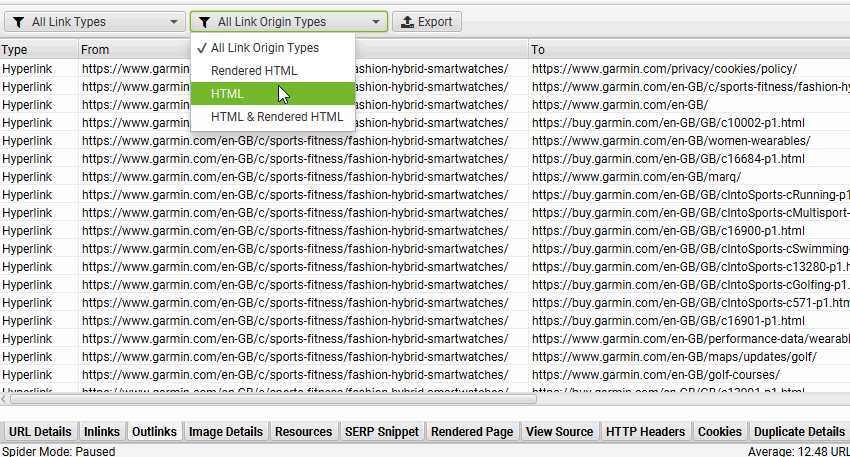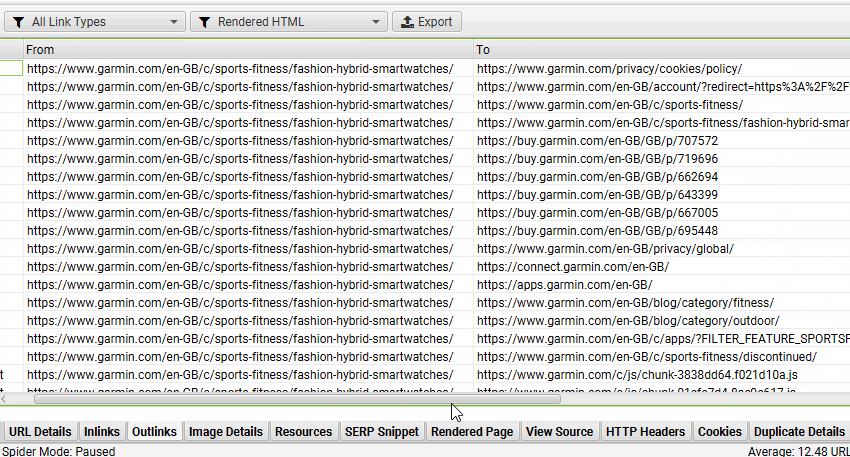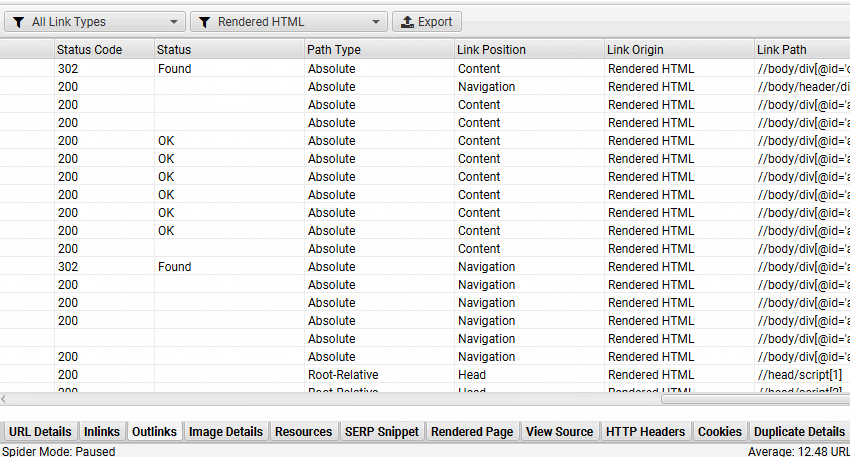
当只有特定的链接,例如类别页面上的产品,是使用 JavaScript 加载时,这会很有帮助。您可以通过“批量导出 > JavaScript > 包含 JavaScript 链接”批量导出所有依赖 JavaScript 的链接。
10) 调整 AJAX 超时
根据您爬取的响应,您可以通过调整“AJAX 超时”,来选择何时拍摄渲染页面的快照。该超时设置位于 JavaScript 渲染模式下的“配置 > Spider > 渲染”中。
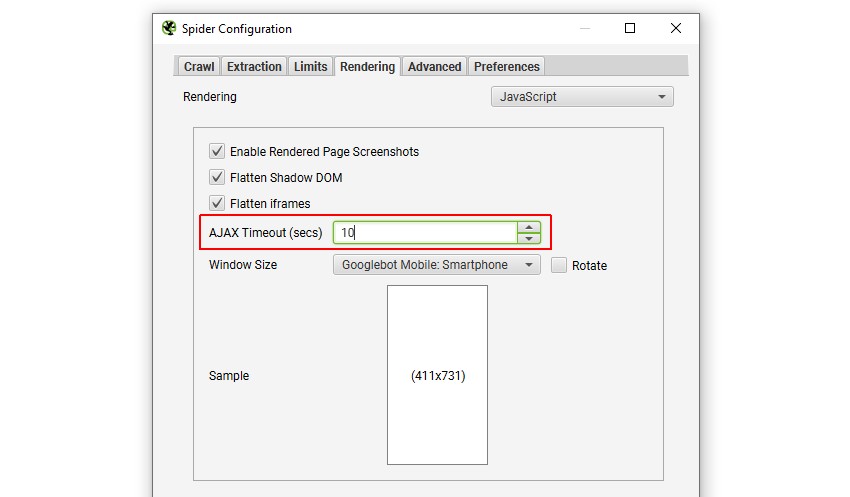
对于大多数网站来说,5 秒的超时时间通常是可以的,而且 Googlebot 更加灵活,因为它们会根据页面加载内容所需的时间进行调整,同时会考虑网络活动并执行大量缓存。然而,Google 显然不会永远等待,因此您希望被抓取和索引的内容需要快速可用,否则它将根本不会被看到。
值得注意的是,我们的软件进行的爬取通常比 Google 随时间推移进行的常规爬取更消耗资源。这可能意味着网站响应时间通常较慢,并且需要调整 AJAX 超时。
如果网站无法正确爬取,“内部”选项卡中的“响应时间”超过 5 秒,或者网页似乎没有在“渲染页面”选项卡中正确加载和渲染,您就知道可能需要调整此设置。
如何抓取 JavaScript 视频
如果您更喜欢视频,请查看我们关于抓取 JavaScript 的教程。
总结
上面的指南应该可以帮助您识别 JavaScript 网站,并使用 Screaming Frog SEO Spider 工具在 JavaScript rendering 模式下高效地抓取它们。
虽然我们已经在内部进行了大量的研究,并努力模仿 Google 自己的渲染能力,但爬虫仍然只是对真实搜索引擎机器人行为的模拟。
我们强烈建议使用 log file analysis 和 Google 自己的 URL Inspection Tool 或 Rich Results Tool 来了解它们能够抓取、渲染和索引的内容,以及 JavaScript 爬虫。
额外阅读
- Understand the JavaScript SEO Basics – 来自 Google。
- Core Principles of JS SEO – 来自 Justin Briggs。
- Progressive Web Apps Fundamentals Guide – 来自 Builtvisible。
- Crawling JS Rich Sites – 来自 Onely。
如果您在抓取 JavaScript 时遇到任何问题,或者在我们渲染和抓取的方式与 Google 之间遇到任何差异,我们很乐意听到您的声音。请直接与 our support 团队联系。