如何调试爬取中遗漏的页面
了解为什么页面可能在爬取中遗漏,以及如何调试和分析它们未被爬取的原因。
如何调试爬取中遗漏的页面
我们最常被问到的问题之一是“为什么 SEO Spider 没有找到我所有的页面?”以及“为什么这个 URL 或部分没有被爬取?”。
或者有时只是“为什么这个工具不能正常工作!?”。
学习如何调试遗漏的页面是一项重要的 SEO 技能,因为它可以帮助识别爬取和索引的潜在问题,或者至少——在努力提高自然可见性时,让您更好地从技术上了解网站设置。
如果您的网站在爬取完第一页后就停止了,请查看我们的教程“为什么我的网站无法爬取?”。
本教程将引导您了解在使用 Screaming Frog SEO Spider 时,如何识别爬取中遗漏页面的原因,包括从哪里开始以及遇到的最常见问题。
为什么页面可能会从爬取中遗漏?
重要的是要记住像 Screaming Frog SEO Spider 这样的爬虫的工作原理,以了解为什么它可能无法发现页面。
SEO Spider 通过扫描 HTML 代码中带有 href 属性的 <a> 标签来发现链接,从爬取的起始页面开始。然后它将爬取这些链接以发现更多链接。
爬取是广度优先的,这意味�着它将爬取当前深度的 URL,然后再爬取下一深度级别的 URL。这意味着它将首先从起始页面爬取,然后爬取它链接到的 URL,然后再爬取它们链接到的 URL,依此类推——直到完成爬取。
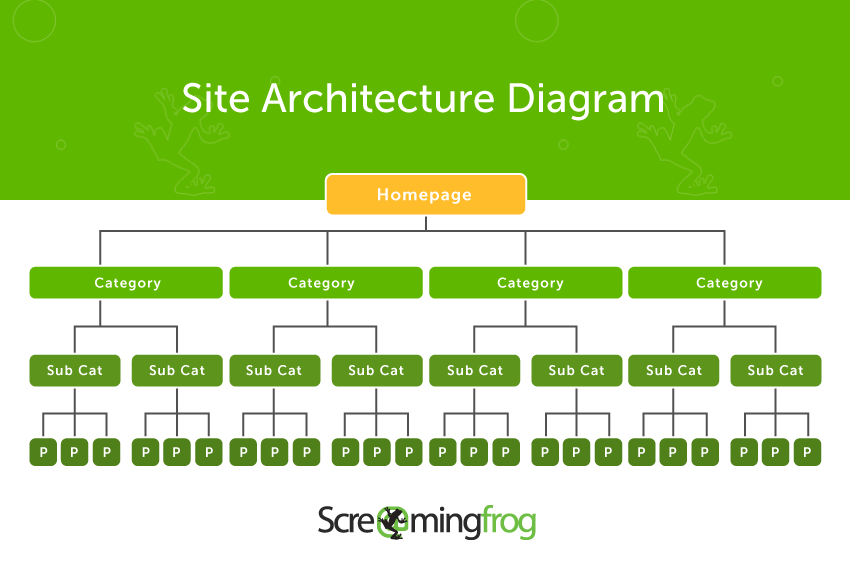
在典型的网站架构中,这意味着将爬取主页,然后是类别、子类别和产品。爬取顺序并不总是那么重要,但爬取路径很重要——为了能够找到一个页面,必须存在从爬取的起点通过内部链接到该页面的可爬取路径。
虽然有时可以假设爬虫存在问题,导致无法发现页面,但通常有两个主要原因。
- 1) 它们没有以可以被发现的方式(通过可爬取的链接路径)链接到。
- 2) SEO Spider 的配置未设置为查找它们。
重要的是要记住,SEO Spider 不像搜索引擎那样爬取整个网络,因此它只会找到内部链接到的页面。由于爬取方式的差异,Google 索引中的内容与 SEO Spider 爬取的内容之间可能存在一些差异。
尽管存在差异,但爬取数据仍然非常有用,它可以帮助发现仅从 Google 索引数据中可能被认为不是问题的差距。
为什么这很重要?
用户需要链接来浏览网站并找到他们想要的内容。搜索引擎使用链接来发现页面并对其进行索引,以便能够在搜索结果中显示它们。
如果网站没有以 Google 可以跟踪的方式链接到某个页面,则该页面可能不会被索引。
搜索引擎使用链接作为其 PageRank 算法中排名的投票。如果网站没有链接到某个页面,则该页面在搜索结果中的排名可能不会那么好。
Google 还使用链接来更好地理解页面之间的关系,以及它们通过锚文本和其他上下文信号的相关性。
从哪里开始调试遗漏的页面?
要找到一个页面,必须存在从爬取的起点到该页面的可爬取路径,以便 SEO Spider 能够跟踪。因此,开始调试过程的最佳位置是回答:
- 1) 哪些页面没有被爬取?
- 2) 网站上的哪些页面链接到它们?
分析 SEO Spider 的“内部”选项卡中找到的 URL,以查看爬取中缺少哪些页面。您可以按字母顺序对 URL 进行排序,然后滚动浏览以按 URL 模式扫描它们,查找遗漏的部分或页面。
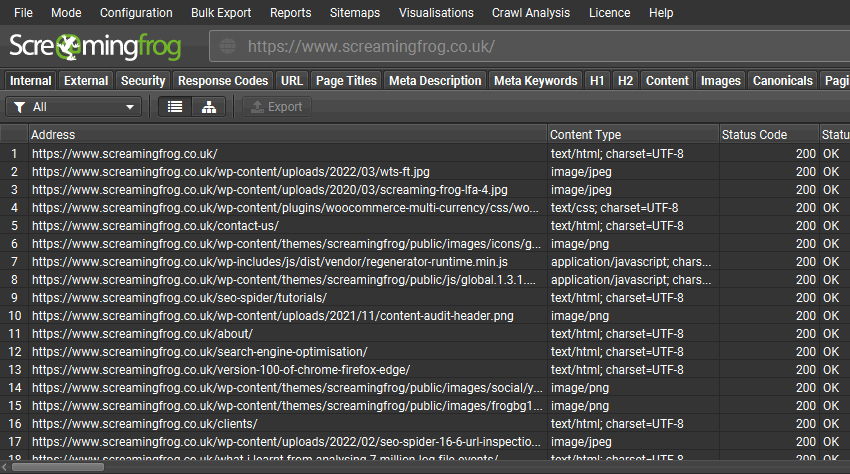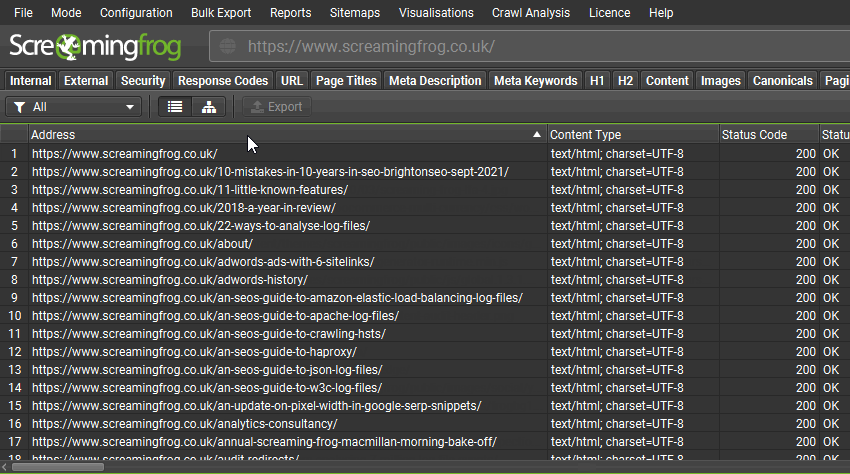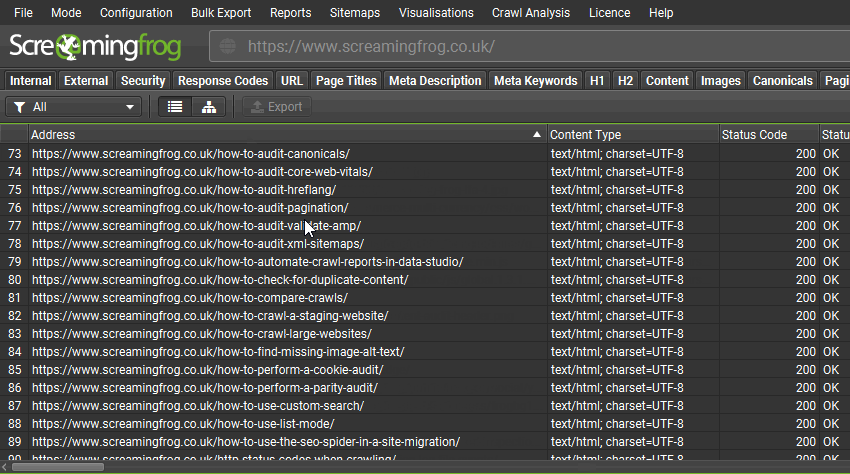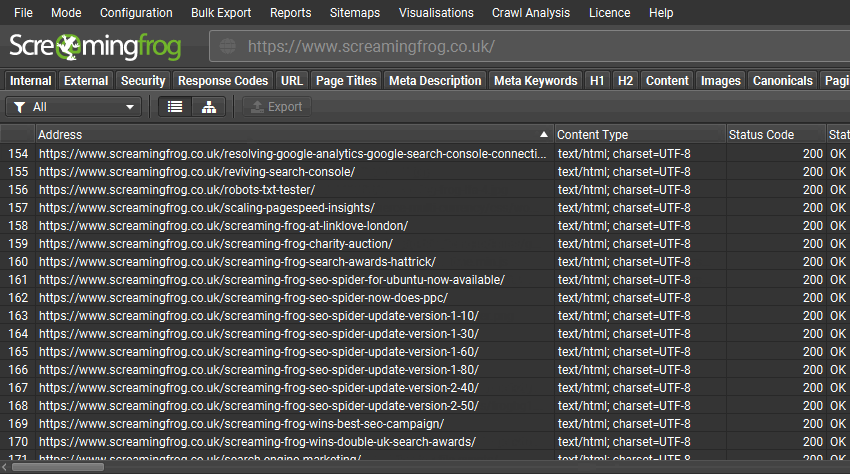
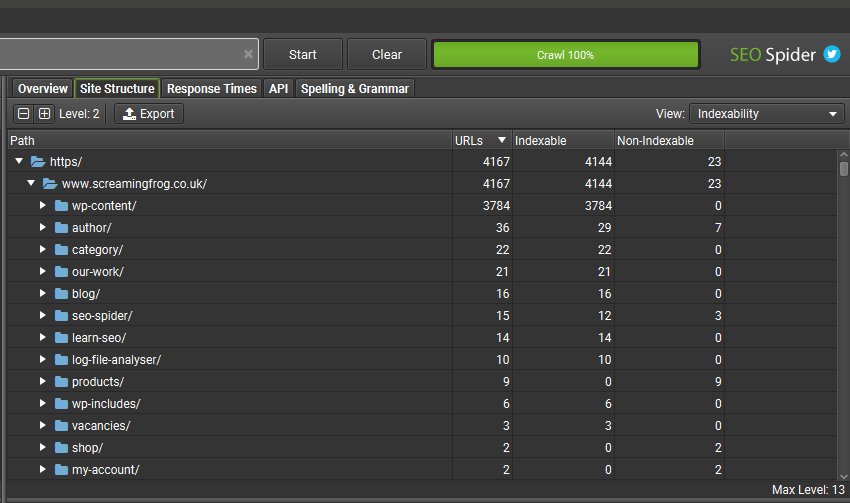
或者使用右侧的“网站结构”选项卡来概述按部分发现的 URL 数量。如果某个部分在结构中缺失,或者 URL 数量少于预期,那么这就是需要进一步分析的地方。
如果您能够回答哪些页面链接到它们,那么下一个问题是——它们是否在爬取中被找到?同样,您可以在“内部”选项卡中快速搜索。
这可以帮助您向后追溯到问题的根源。
例如,如果未找到产品页面,并且它们是从类别页面链接的,并且这些类别页面正在被爬取——那么您就知道这是需要进一步调查的问题根源。
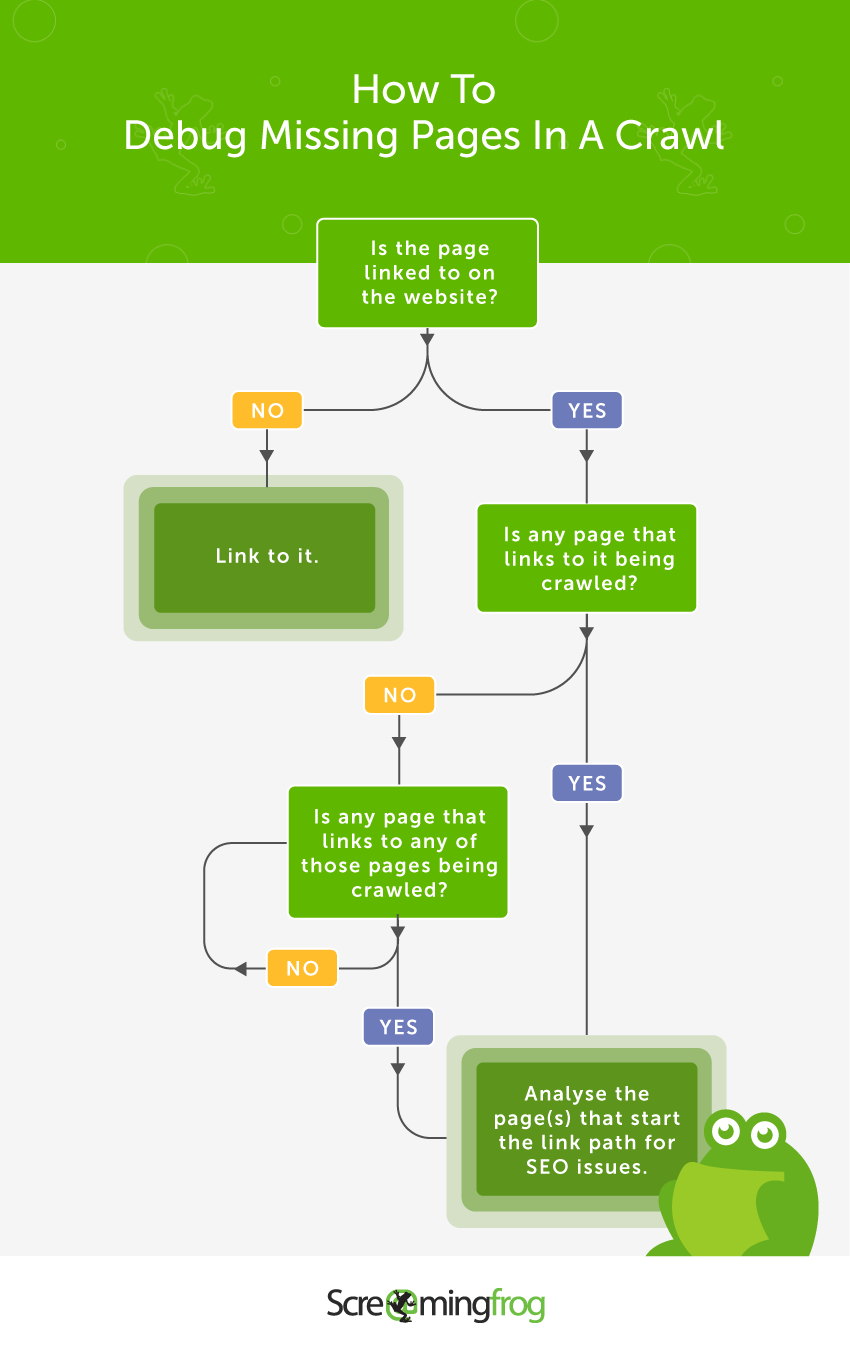
如果您到达此步骤并且无法回答“网站上的哪些页面链接到它们?”,那么这很可能是它们未被爬取的原因。
如何调试遗漏的页面?
当您确定了应该链接到遗漏页面或其爬取路径的源页面时,您需要分析它以查看它如何链接到遗漏的页面。
SEO Spider 只会跟踪在 HTML 中使用带有可解析 URL 的 <a> 标签的链接。
<a href="https://example.com" </a>
这与 Google 相同,Google 提供了关于他们可以和不能跟踪的可爬取链接的文档。
请记住,在进行任何分析之前不要与页面交互,因为 SEO Spider 和搜索机器人不会像用户一样点击并加载其他事件。在 Chrome 中打开页面,右键单击并“�查看页面源代码”。
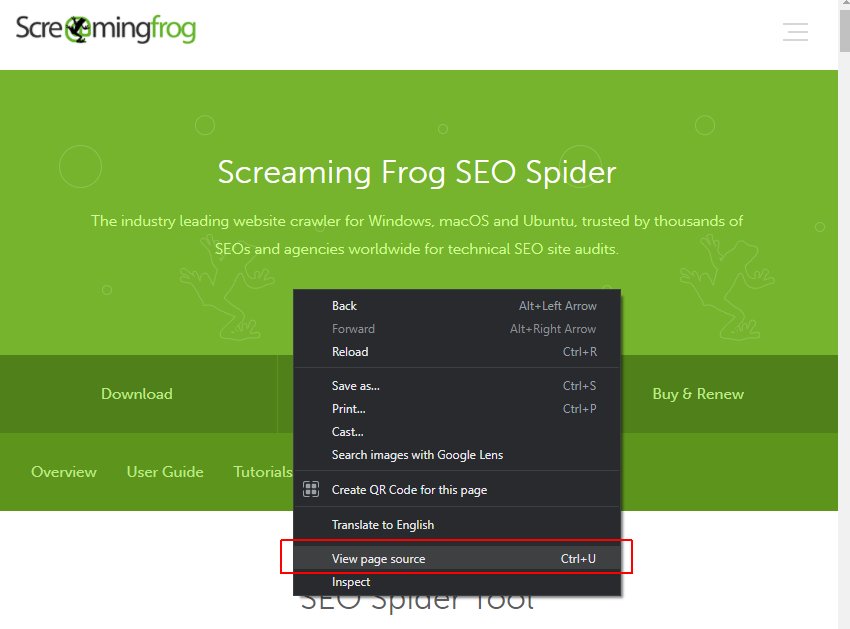
然后搜索(control + F)遗漏的 URL。这是 JavaScript 运行之前的原始 HTML。理想情况下,URL 应该存在于可爬取的链接中。
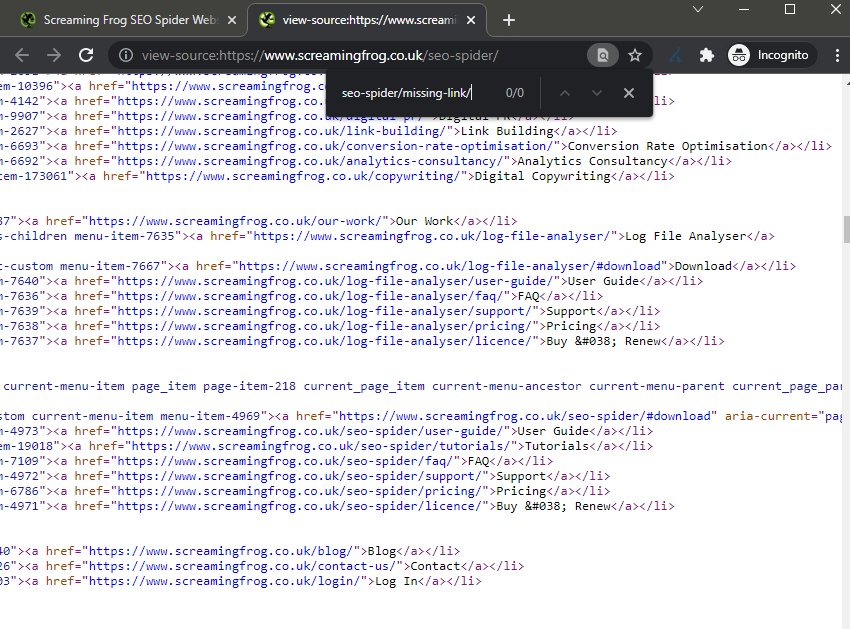
如果它不存在,请右键单击并“检查元素”,这将显示 JavaScript 运行后的呈现的 HTML,然后再次搜索。
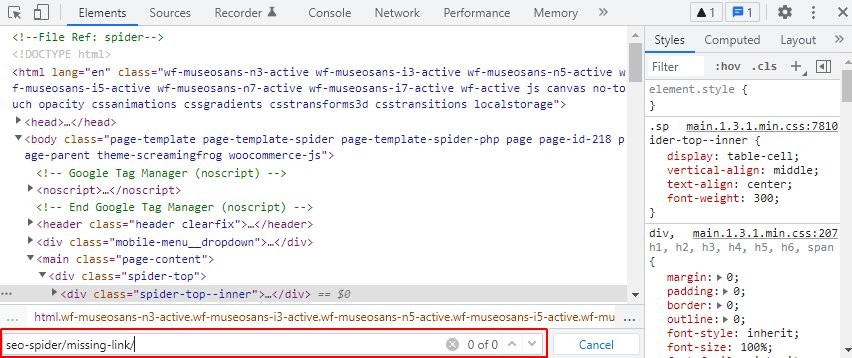
如果遗漏的 URL 存在,那么您就知道它依赖于 JavaScript。在这种情况下,请阅读我们的教程如何爬取 JavaScript 网站。
如果遗漏的页面未在原始或呈现的 HTML 中链接,或者不在带有 href 属性的 <a> 标签中,那么这有助于识别需要与他们的开发人员一起解决的网站上的 SEO 问题。
遗漏页面的常见原因
我们很幸运(?)能够看到许多不同的技术问题,这些问题会影响页面的爬取和索引。通常,在爬取中找不到所有页面的最常见原因是以下几点。
没有内部链��接
您可能会感到惊讶,但这通常是未爬取页面的最常见原因。它根本没有在网站上内部链接到。
如果没有链接到,那么 SEO Spider 默认情况下不会发现它。这显然会对用户以及搜索引擎发现和索引页面造成问题。
未内部链接到的 URL 可以称为孤立页面,可以通过将其他发现方法(例如 XML 站点地图、Google Analytics 和 Search Console API)集成到爬取中来找到。
请参阅我们关于如何查找孤立页面的教程。
JavaScript
默认情况下,SEO Spider 将在 JavaScript 执行之前爬取原始 HTML。
如果网站完全依赖于客户端 JavaScript 来填充内容和链接,那么您通常会发现只爬取了主页,并返回 200“OK”响应,以及一些 JavaScript 和 CSS 文件。
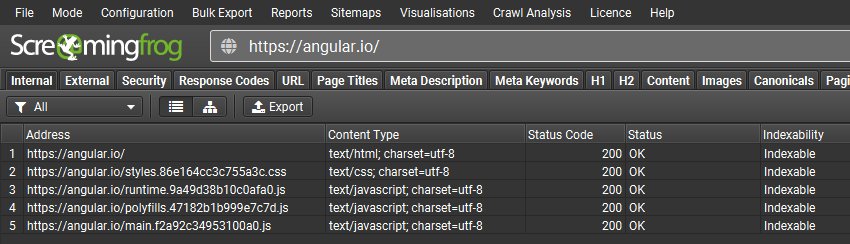
您还会发现该页面在较低的“外链”选项卡中没有超链接,因为它们没有被呈现,因此无法看到。
虽然这通常表明该网站正在使用 JavaScript 框架进行客户端渲染,但可能存在更微妙且更难发现的 JavaScript 依赖项,其中它用于特定功能。
最常见的一种是在电子商务网站的类别页面上使用 JavaScript 来加载产品。如果您已确定未爬取产品页面,但已爬取类别页面,则需要进行调查。
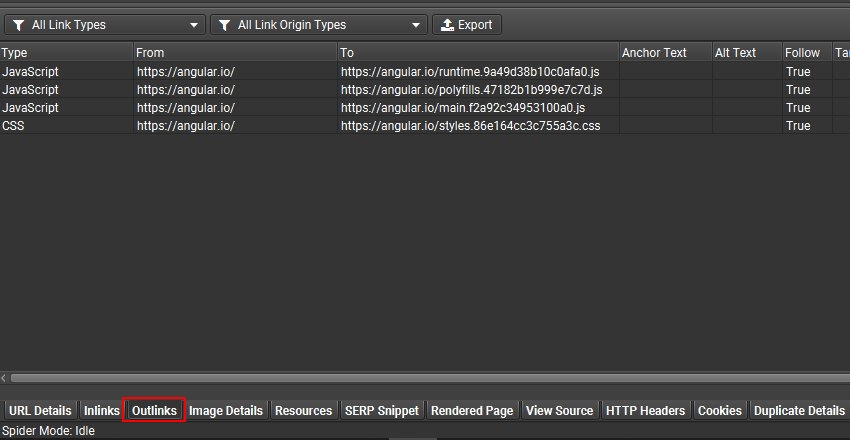
Garmin 网站上的类别页面就是这种行为的一个例子。您可以右键单击并“查看页面源代码”在 Chrome 中,并在页面上搜索产品 URL 或特定文本元素,以查看它们在 JavaScript 之前不存在。
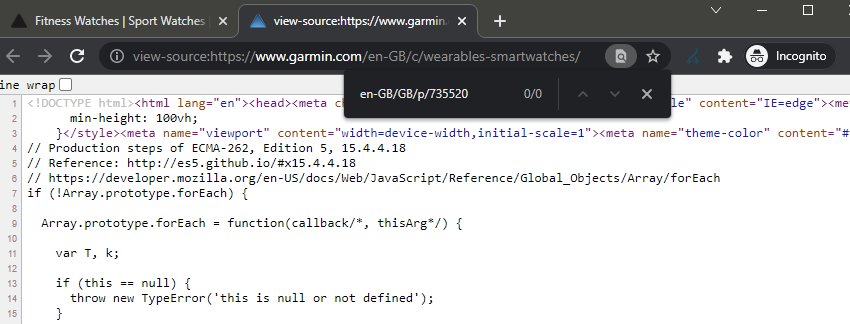
如果您右键单击并“检查元素”,这是在 JavaScript 处理之后,您将在带有 href 属性的 <a> 标签中看到链接。
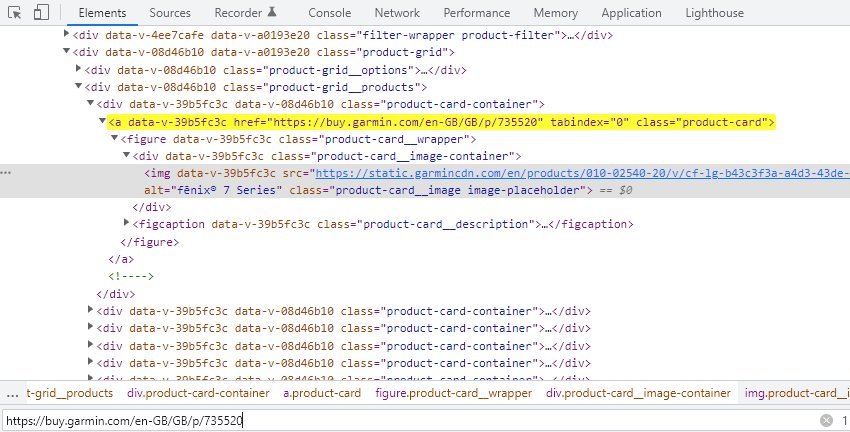
为了帮助在 SEO Spider 中识别 JavaScript 并爬取产品页面,您可以通过“配置 > 爬虫 > 渲染”启用 JavaScript 渲染模式。
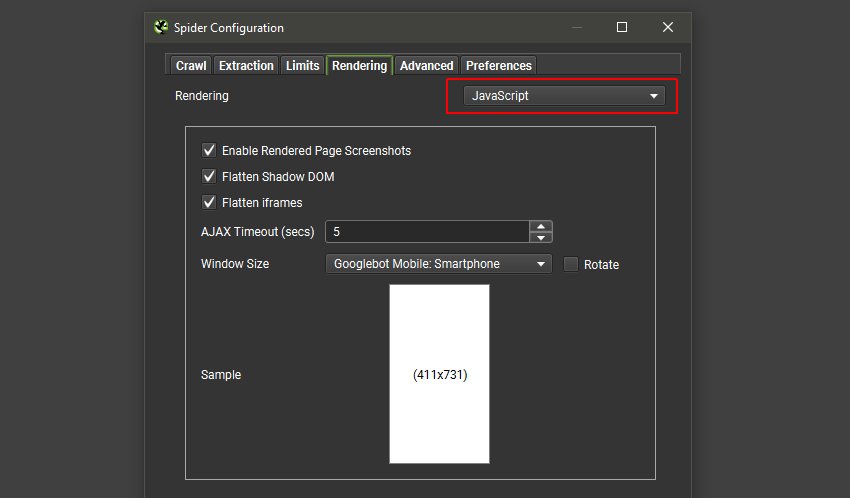
JavaScript 选项卡和相关的“包含 JavaScript 链接”和“包含 JavaScript 内容”过滤器报告了仅在 JavaScript 之后的呈现的 HTML 中具有链接或内容的页面。
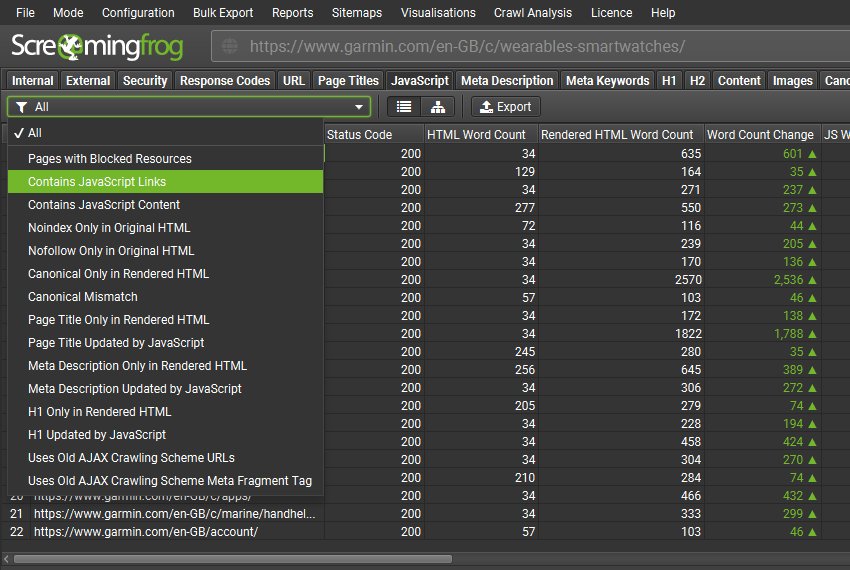
您可以查看类别页面的“外链”选项卡,以查看是否已发现产品链接,并通过将“所有链接类型”过滤器调整为“超链接”并将“所有链接来源类型”过滤器调整为仅“呈现的 HTML”来识别仅在 JavaScript 之后的呈现的 HTML 中的链接。
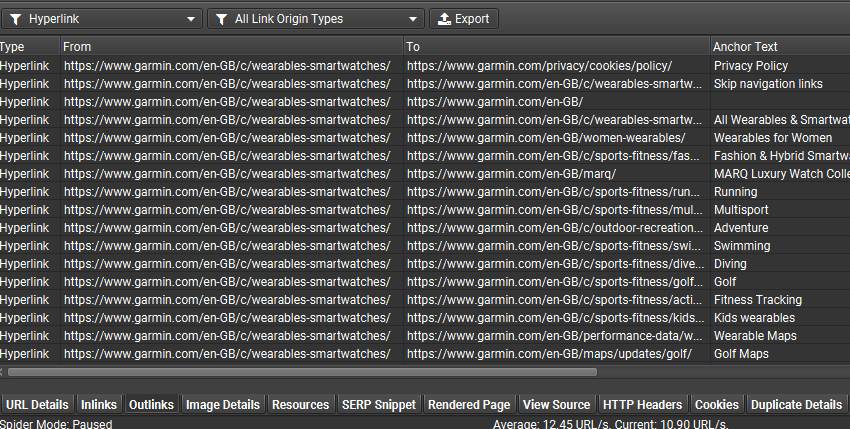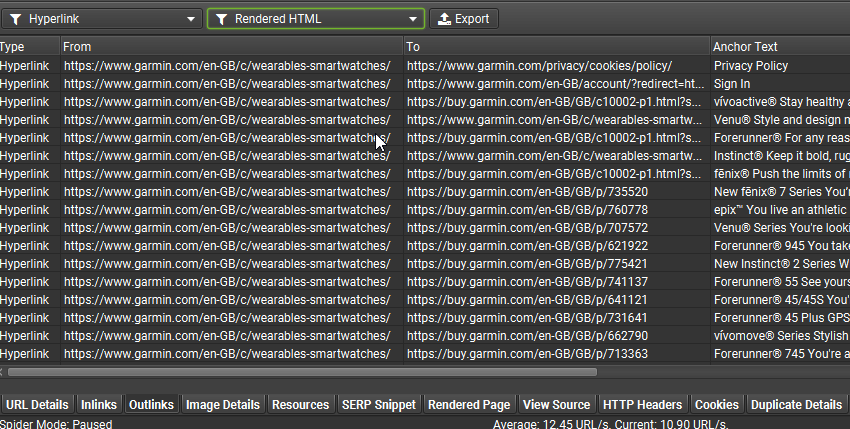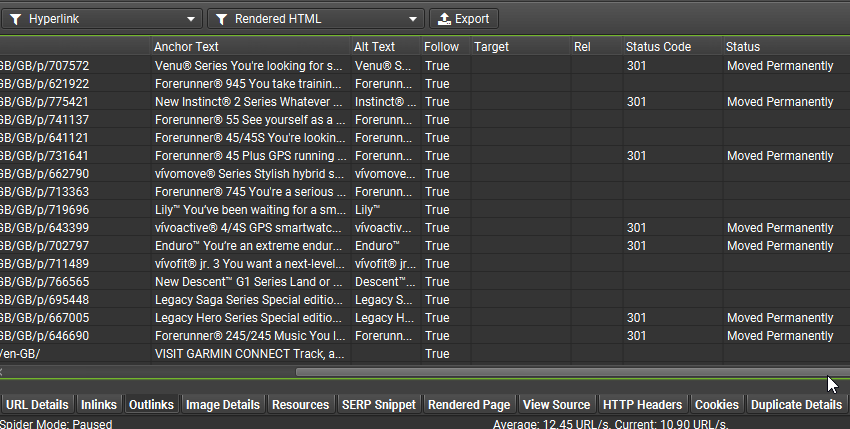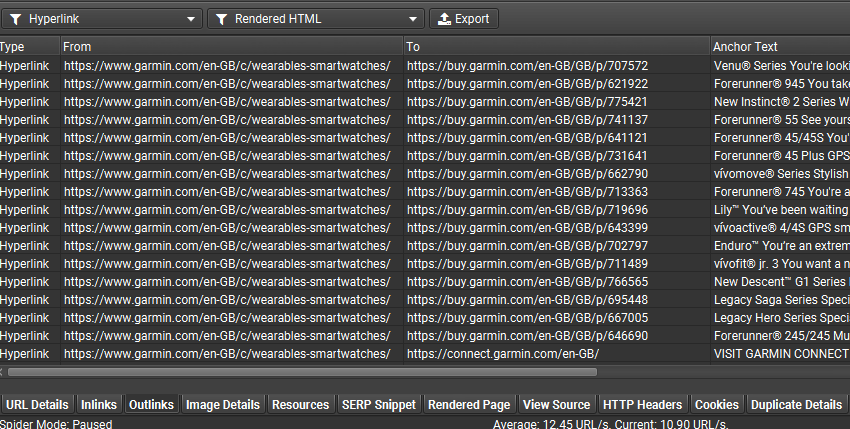
在 JavaScript 渲染模式下,SEO Spider 将爬取原始 HTML 和呈现的 HTML,以识别仅在客户端可用的内容或链接的页面,并报告其他依赖项和潜在问题。
请阅读我们的“如何爬取 JavaScript 网站”教程。
不可爬取的分页
如果您无法在网站上找到所有新闻文章、博客文章或产品,是否正在爬取分页页面?如果不是,为什么不呢?现在是分析其设置的时候了。
检查主博客或新闻页面,然后在浏览器中单击分页,以查看它们是否具有唯一的 URL。
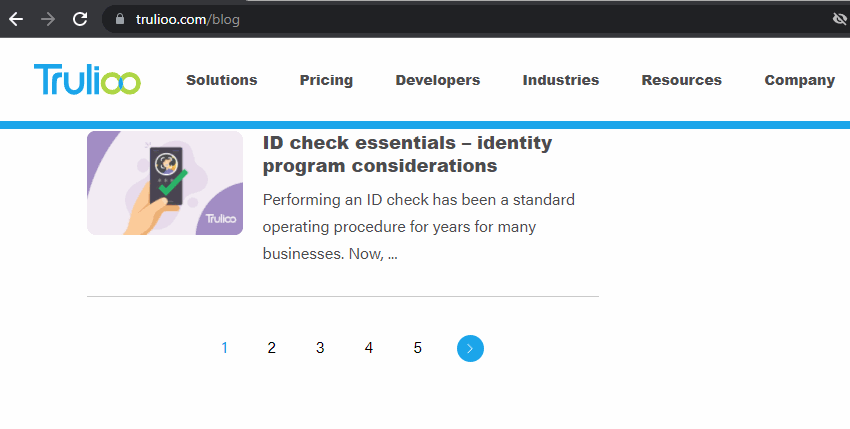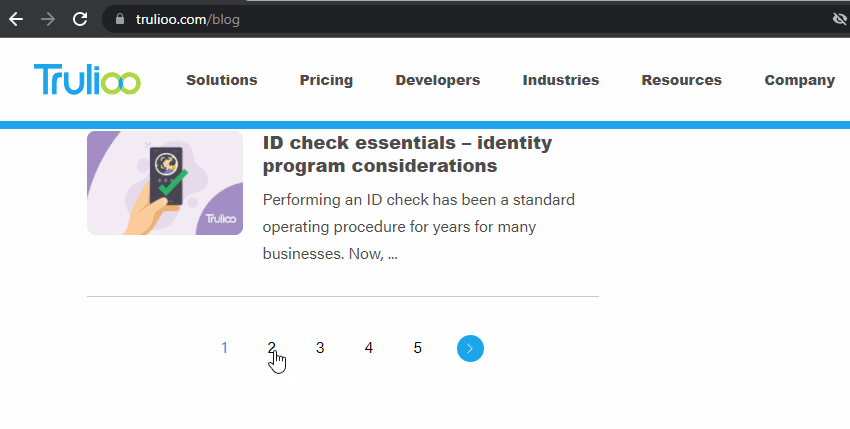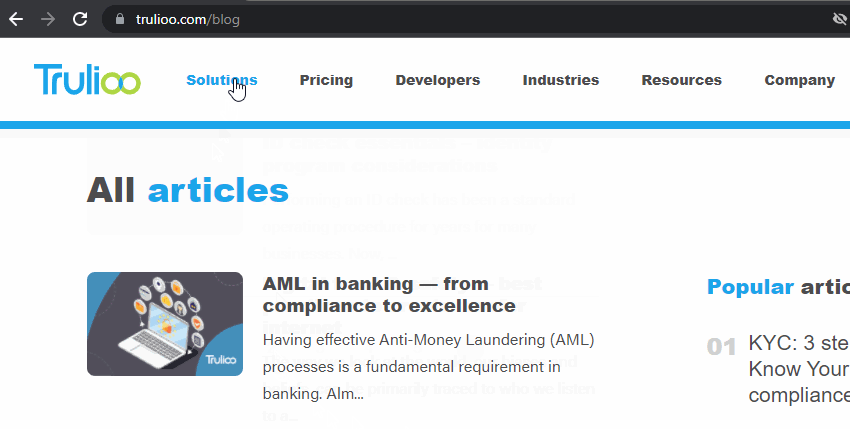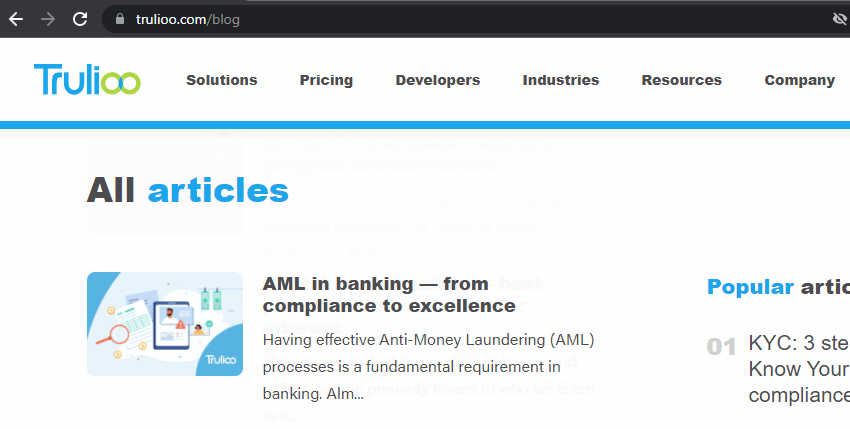
一些分页只是使用 JavaScript 来刷新页面并将其他博客文章或文章加载到页面上,这不会被 SEO Spider 或 Google 看到。
分析原始 HTML 和呈现的 HTML,以查看是否存在指向分页 URL 的任何链接,或者它们是否是使用 JavaScript 而没有带有 href 属性的 <a> 标签的按钮。
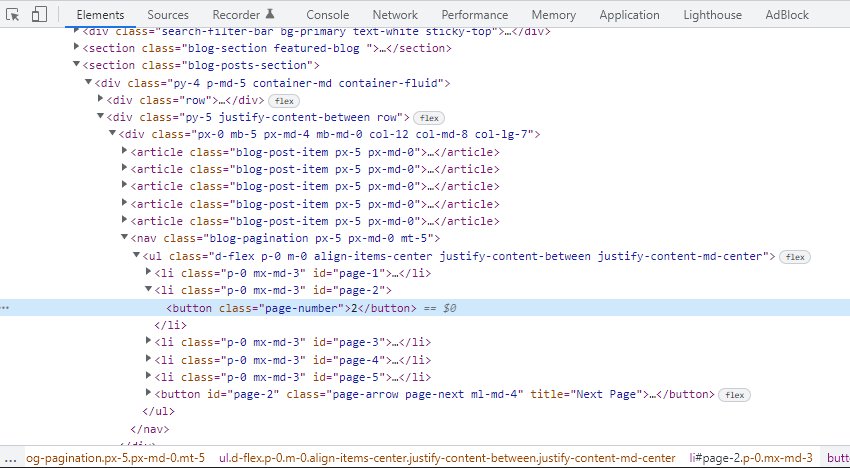
分页错误不仅限于博客和新闻文章,我们还经常在产品中看到这种情况。按钮用于将更多产品加载到同一页面上。
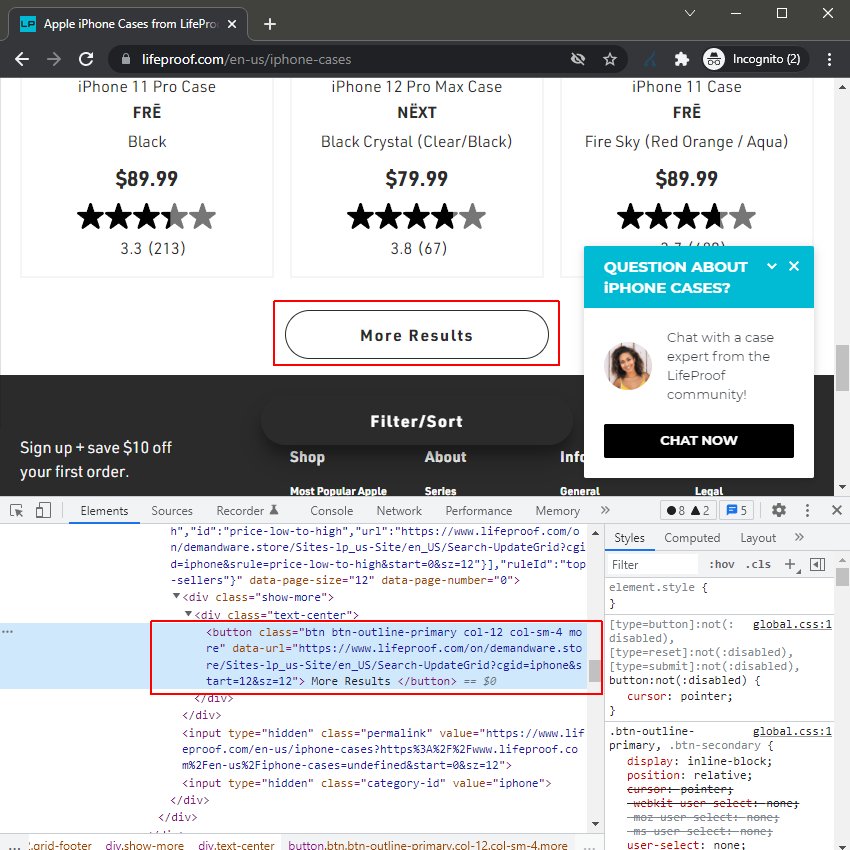
在这种情况下,它们不使用可爬取的链接类型,如果单独访问 URL,则它是一个仅加载主要正文内容的搜索结果页面。
分页的基本原则是——
- 确保分页页面具有唯一的 URL,例如 /blog/2/,并避免使用片段。
- 使用带有 href 属性的
<a>标签链接到分页页面 - 为了帮助 Google 了解页面之间的关系,请包含从每个页面到下一页的链接
分页页面应包含供用户使用的唯一分页内容,然后可以由搜索引擎爬取和索引。
Google 提供了关于 电子商务分页最佳实践 的优秀指南。
不可爬取的链接类型
Google 和 SEO Spider 只会跟踪在 HTML 中使用带有可解析 URL 的正确 <a> 标签的链接。
<a href="https://example.com" </a>
因此,分析原始 HTML 和呈现的 HTML,并验证链接是否已正确编码。我们看到了很多种类和错误,例如带有 ahref 的 div 或 span 标�签。
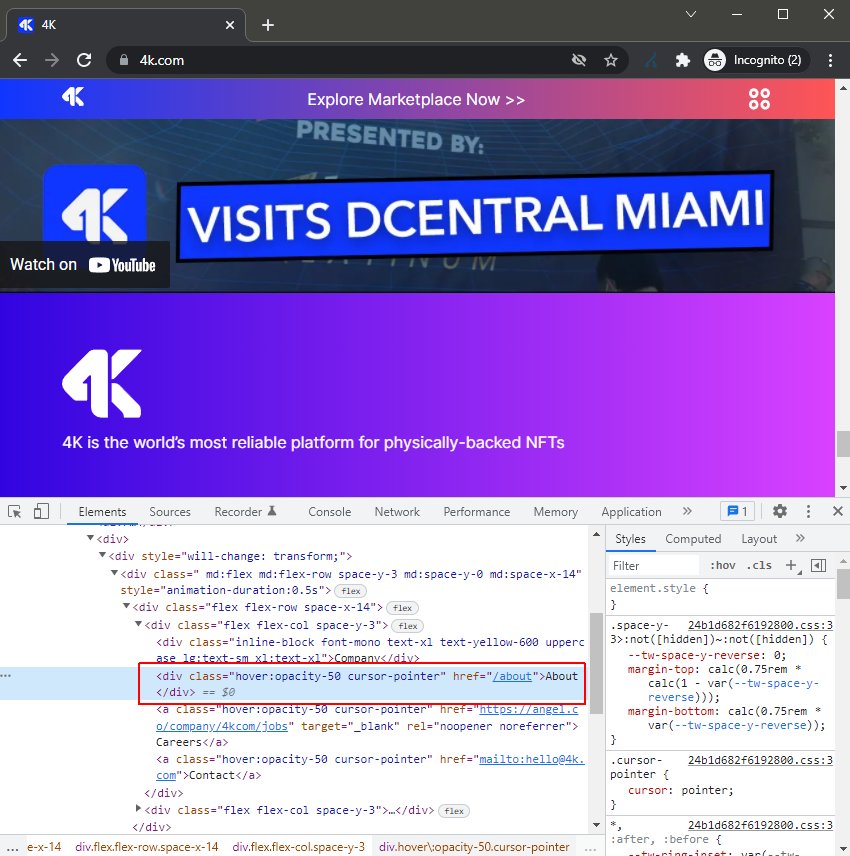
Google 和 SEO Spider 不会跟踪其他格式,例如以下——
<a routerLink=”some/path”><span href=”https://example.com”><a onclick=”goto(‘https://example.com’)”>javascript:goTo(‘products’)javascript:window.location.href=’/products’<span data-link=”https://example.com”>#
请参阅 Google 自己关于 使链接可爬取 的指南,了解他们的搜索引擎。
搜索表单
SEO Spider 不会像用户一样与页面内容交互,也不会使用搜索表单来运行搜索和查找内容。如果网站上的内容只能通过运行搜索来访问,那么将无法找到这些内容。
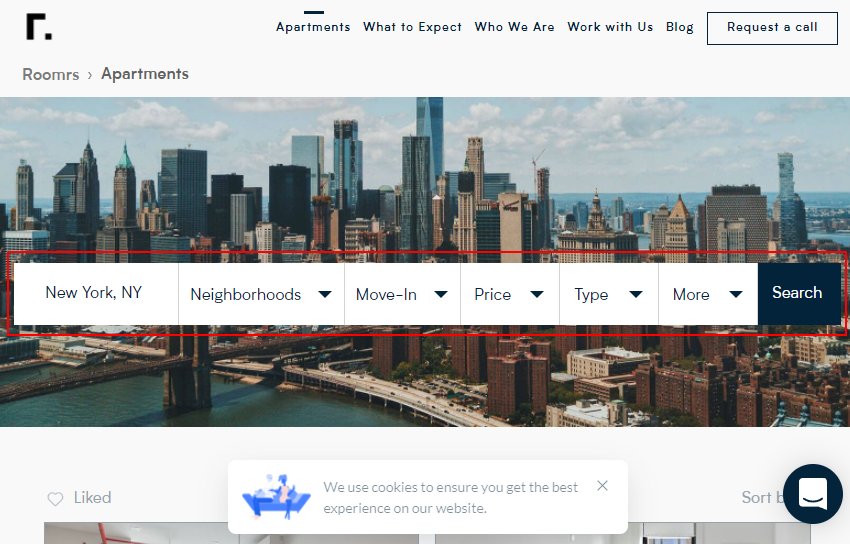
必须存在可抓取的链接路径,才能访问需要索引的任何内容。确保任何重要的内容都通过替代用户路径进行内部链接。
在上面的示例中,属性只能通过搜索访问,并且可以通过使用由其他菜单链接的位置页面在内部链接。
配置
SEO Spider 的配置在抓取内容方面起着重要作用。
通常,在抓取开始时,通过“File > Config > Clear Default Config”清除配置会很有用,以排除任何先前的调整影响其在抓取期间发现内容的能力。
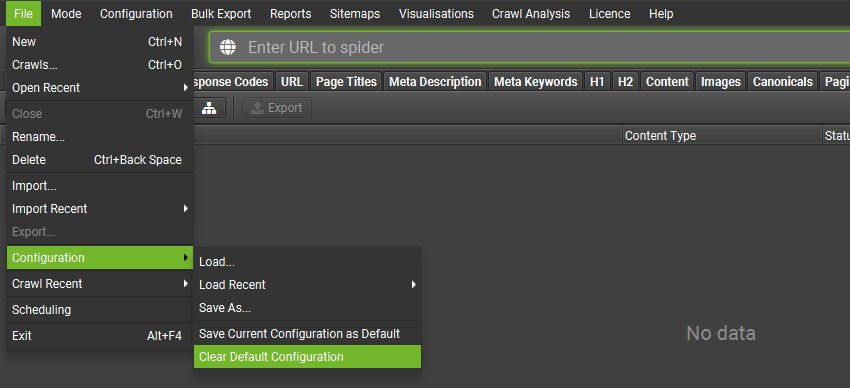
如果以上方法没有帮助,请同时查看以下内容:
- 如果网站使用 JavaScript,您正在JavaScript 渲染模式下进行抓取。
- 链接或链接页面没有“nofollow”属性或指令,阻止 SEO Spider 跟踪它们。默认情况下,SEO Spider 遵循“nofollow”指令,除非选中“follow internal nofollow“配置。
- 预期的页面与您的起始页面位于同一子域上。默认情况下,指向不同子域的链接被视为外部链接,除非选中“Crawl all subdomains”选项。
- 如果预期的页面位于与抓取起始点不同的子文件夹中,则选中“Crawl outside start folder”选项。
- 链接页面未被 Robots.txt 阻止。默认情况下,会遵循 robots.txt,因此除非选中“Ignore robots.txt”选项,否则将看不到被阻止页面上的任何链接。如果网站使用 JavaScript 并且渲染配置设置为“JavaScript”,请确保 JS 和 CSS 未被 robots.txt 阻止。
- 您没有设置限制抓取的 Include 或 Exclude 功能。
- 确保类别页面(或类似页面)在抓取期间没有暂时无法访问,从而导致连接超时、服务器错误等,从而阻止发现链接的页面。
- 默认情况下,SEO Spider 不会抓取网站的 XML Sitemap 以发现新的 URL。但是,您可以选择在配置中“Crawl Linked XML Sitemaps”。
总结
了解如何调试页面在抓取中缺失的原因将有助于您更好地了解搜索引擎在抓取、索引和对网站进行自然搜索排名时可能遇到的潜在问题。
了解爬虫如何通过跟踪链接来发现其他页面,将有助于您在站点架构和内部链接方面做出更好的决策。
查看我们的 Screaming Frog SEO Spider 用户指南、常见问题解答 和 教程,获取更多建议和技巧。
如果您对缺失页面有任何疑问,请通过 support 与我们的团队联系,并提供有关问题的详细信息,包括缺失的页面以及链接到该页面的源页面。