SEO Spider 中的 Robots.txt 测试
查看被 robots.txt 阻止的 URL、disallow 行,并使用自定义 robots.txt 彻底且大规模地检查和验证网站的 robots.txt。
如何使用 SEO Spider 测试 Robots.txt
robots.txt 文件用于向机器人发出指令,告知它们可以在网站上抓取哪些 URL。所有主要的搜索引擎机器人都符合 robots 排除标准,并且在从网站获取任何其他 URL 之前,都会读取并遵守 robots.txt 文件的指令。
可以设置命令以根据其用户代理(例如“Googlebot”)应用于特定机器人,并且 robots.txt 中最常用的指令是“disallow”,它告诉机器人不要访问 URL 路径。

您可以在浏览器中查看网站的 robots.txt,只需将 /robots.txt 添加到子域的末尾(例如 www.screamingfrog.co.uk/robots.txt)。
虽然 robots.txt 文件通常很容易解释,但当存在大量行、用户代理、指令和数千个页面时,可能难以识别哪些 URL 被阻止,以及哪些 URL 允许被抓取。显然,错误阻止 URL 的后果可能会对搜索结果中的可见性产生巨大影响。
这就是像 Screaming Frog SEO Spider 软件这样的 robots.txt 测试工具及其自定义 robots.txt 功能可以帮助彻底且大规模地检查和验证网站的 robots.txt 的地方。
首先,您需要下载 SEO Spider,它以精简版形式免费提供,可抓取多达 500 个 URL。更高级的自定义 robots.txt 功能需要许可证。
您可以按照以下步骤测试已上线的网站的 robots.txt。如果您想测试尚未上线的 robots.txt 指令或单个机器人命令的语法,请阅读我们指南的第 3 节中有关自定义 robots.txt 功能的更多信息。
1) 抓取 URL 或网站
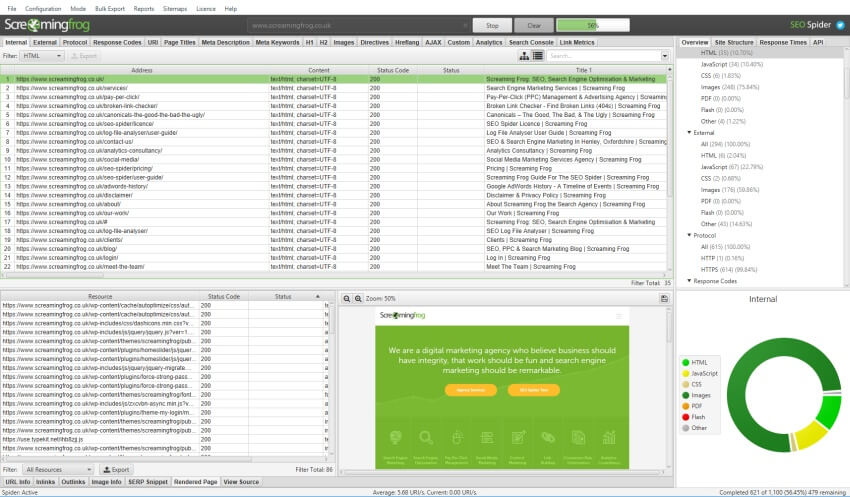
打开 SEO Spider,在“输入要抓取的 URL”框中键入或复制您要抓取的网站,然后点击“开始”。
如果您想测试多个 URL 或 XML 站点地图,您可以简单地在列表模式(在顶级导航栏中的“模式 > 列表”下)中上传它们。
2) 查看“��响应代码”选项卡和“被 Robots.txt 阻止”过滤器
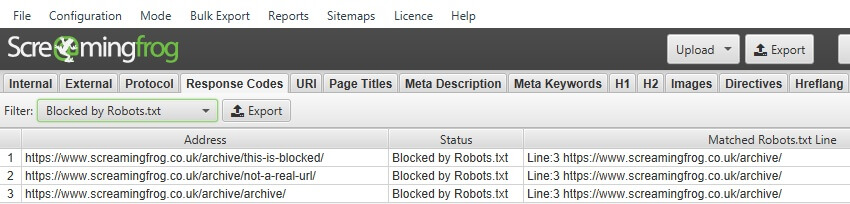
被禁止的 URL 将在“被 Robots.txt 阻止”过滤器下显示为“状态”为“被 Robots.txt 阻止”。

“被 Robots.txt 阻止”过滤器还显示“匹配的 Robots.txt 行”列,该列提供 robots.txt 条目的行号和禁止路径,该条目排除了抓取中的每个 URL。
可以通过点击“入站链接”选项卡来查看链接到 robots.txt 中禁止的 URL 的源页面,该选项卡会填充下部窗口窗格。
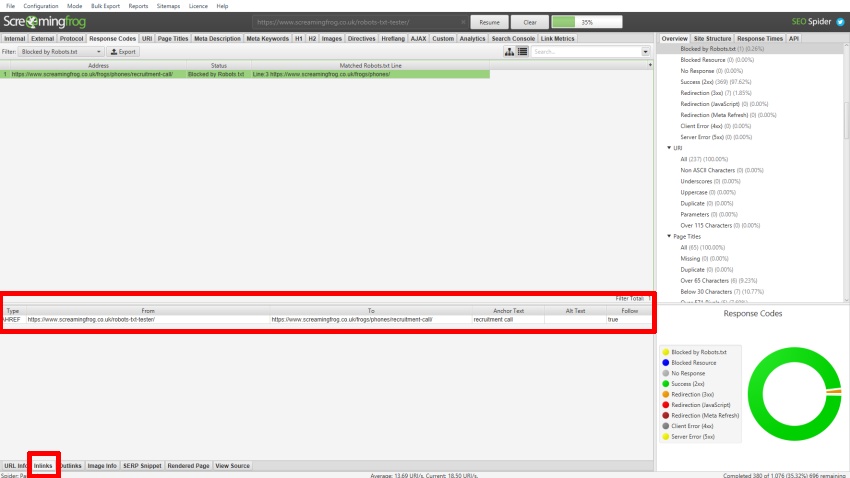
以下是下部窗口窗格的更详细视图,其中详细说明了“入站链接”数据 -
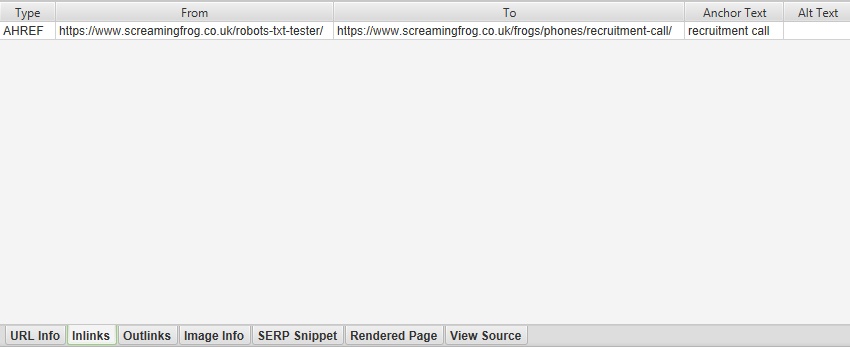
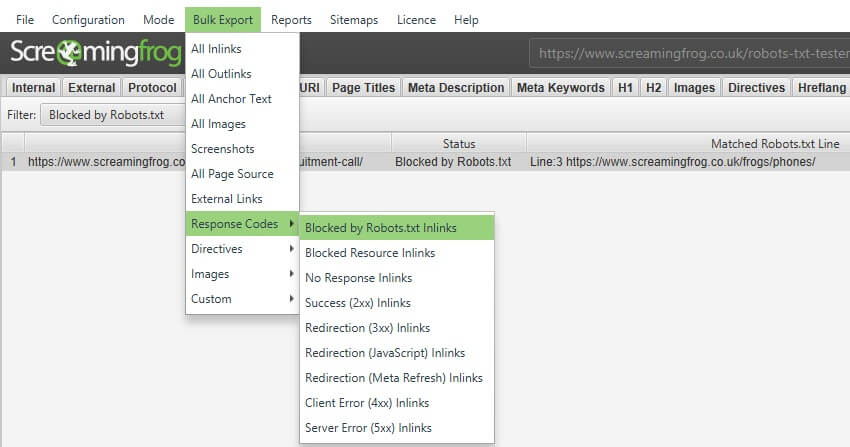
它们也可以通过“批量导出 > 响应代码 > 被 Robots.txt 阻止的入站链接”报告批量导出。
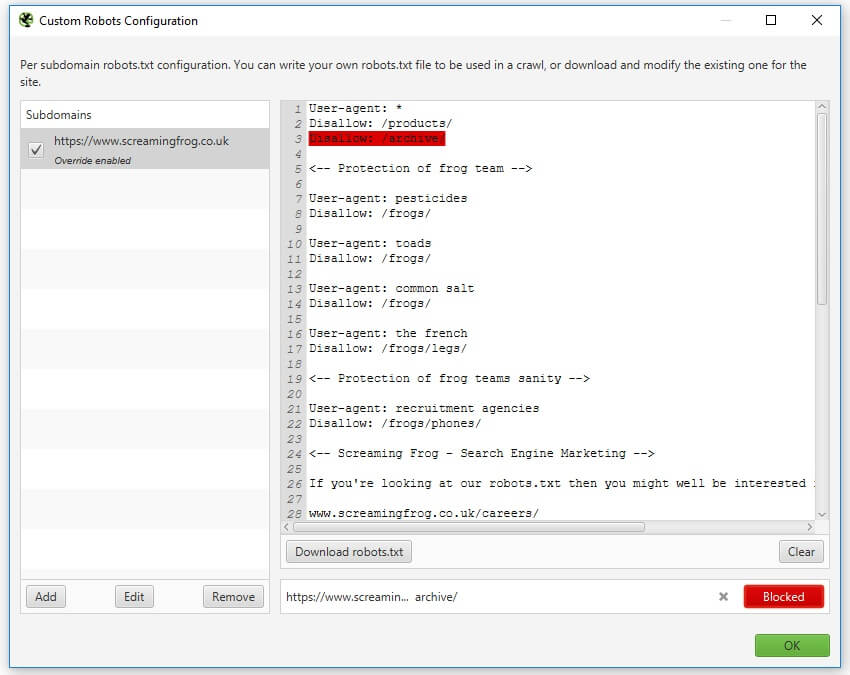
3) 使用��自定义 Robots.txt 进行测试
拥有许可证后,您还可以使用“配置 > robots.txt > 自定义”下的自定义 robots.txt 功能下载、编辑和测试网站的 robots.txt。
该功能允许您在子域级别添加多个 robots.txt,在 SEO Spider 中测试指令,并立即查看被阻止或允许的 URL。
您还可以执行抓取并根据更新后的自定义 robots.txt 过滤被阻止的 URL(“响应代码 > 被 robots.txt 阻止”),并查看匹配的 robots.txt 指令行。
自定义 robots.txt 使用配置中选择的用户代理,可以对其进行调整以测试和验证任何搜索机器人。
请注意 - 您在 SEO Spider 中对 robots.txt 所做的更改不会影响您上传到服务器的实时 robots.txt。但是,当您对测试感到满意时,您可以将内容复制到实时环境中。
SEO Spider 如何遵守 Robots.txt
Screaming Frog SEO Spider 以与 Google 相同的方式遵守 robots.txt。它将检查子域的 robots.txt,并遵循专门针对“Screaming Frog SEO Spider”用户代理的指令(允许/禁止),如果不是 Googlebot,则遵循所有机器人的指令。
在 robots.txt 中禁止的 URL 仍将显示并在用户界面中“索引”,状态为“被 Robots.txt 阻止”,它们只是不会被抓取,因此看不到页面的内容和出站链接。可以在 robots.txt 设置中关闭在用户界面中显示被 robots.txt 阻止的内部或外部链接。
重要的是要记住,如果内部或外部链接到在 robots.txt 中阻止的 URL,则它们仍然可以在搜索引擎中被索引。robots.txt 仅阻止搜索引擎查看页面的内容。“noindex”meta 标签(或 X-Robots-Tag)是从索引中删除内容的更好选择。
该工具还支持文件值的 URL 匹配(通配符 * / $),就像 Googlebot 一样。
常见的 Robots.txt 示例
“User-agent”命令旁边的星号(User-agent: *)表示指令适用于所有机器人,而特定的 User-agent 机器人也可以用于特定命令(例如 User-agent: Googlebot)。
如果命令同时用于所有用户代理和特定用户代理,则“所有”命令将被特定用户代理机器人忽略,并且仅遵守其自己的指令。如果您希望遵守全局指令,则还必须在特定 User-agent 部分下包含这些行。
以下是一些 robots.txt 中使用的常见指令示例。
阻止所有机器人访问所有 URL
User-agent: * Disallow: /
阻止所有机器人访问文件夹
User-agent: * Disallow: /folder/
阻止所有机器人访问 URL
User-agent: * Disallow: /a-specific-url.html
阻止 Googlebot 访问所有 URL
User-agent: Googlebot Disallow: /
阻止和允许命令一起使用
User-agent: Googlebot Disallow: / Allow: /crawl-this/
如果您有冲突的指令(即,允许和禁止访问同一文件路径),则当匹配的允许指令在命令中包含相等或更多的字符时,匹配的允许指令会胜过匹配的禁止指令。
Robots.txt URL 通配符匹配
Google 和 Bing 允许在 robots.txt 中使用通配符。例如,阻止所有抓取工具访问包含问号 (?) 的所有 URL。
User-agent: * Disallow: /*?
您可以使用美元 ($) 字符来匹配 URL 的结尾。例如,阻止所有抓取工具访问 .html 文件扩展名。
User-agent: * Disallow: /*.html$
您可以在 Google 的 robots.txt 规范 指南中阅读有关基于路径值的 URL 匹配的更多信息。
更多支持
如果您对如何在 Screaming Frog SEO Spider 中使用 robots.txt 测试器有任何疑问,请与我们的支持团队联系。