SEO Spider 常规
安装
可以通过点击适用于您操作系统的下载按钮来下载 Screaming Frog SEO Spider,然后运行安装程序。
SEO Spider 适用于 Windows、Mac 和 Ubuntu Linux。SEO Spider 不适用于 Windows XP。
最低配置是具有至少 4GB 可用 RAM 的 64 位操作系统。
SEO Spider 能够抓取数百万个 URL,但需要正确的硬件、内存和存储。它能够将抓取数据保存在 RAM 中,或者以数据库形式保存到磁盘中。
对于低于 20 万个 URL 的抓取,通常 8GB 的 RAM 应该足够。但是,为了能够抓取超过 100 万个 URL,我们推荐的硬件是 SSD 和 16GB 的 RAM(或更高)。
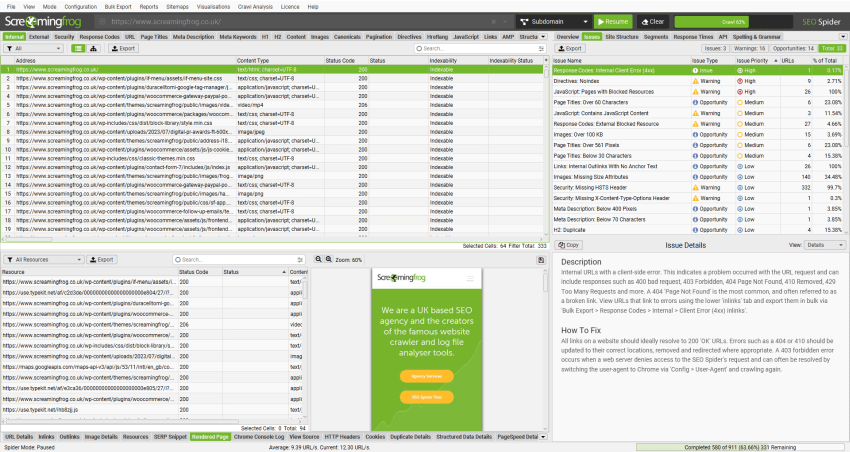
如果您��是 SEO Spider 的新手,请阅读我们的入门指南。
在 Windows 上安装
这些说明是使用 Windows 10 编写的,适用于所有最新版本的 Windows。
下载最新版本的 SEO Spider。下载的文件将被命名为 ScreamingFrogSEOSpider-VERSION.exe。该文件很可能会下载到您的“下载”目录,可以通过文件资源管理器轻松访问。当 Windows 执行安全扫描时,下载可能会在 100% 完成时暂停。
安装
下载的文件是一个可执行文件,必须运行才能安装 SEO Spider。转到文件资源管理器中的“下载”文件夹,双击下载的文件,您将看到以下屏幕。
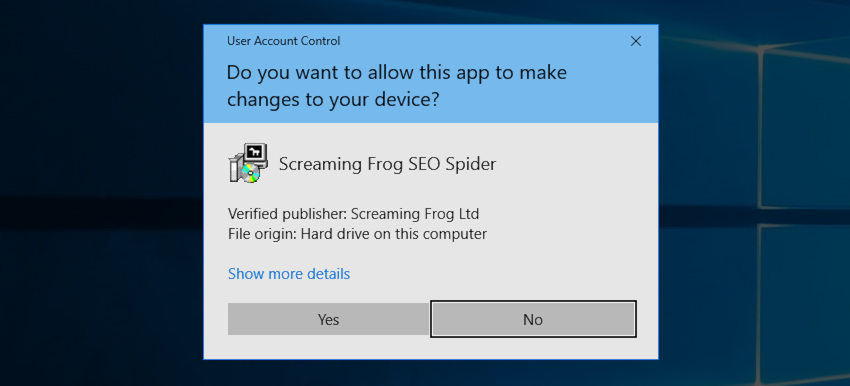
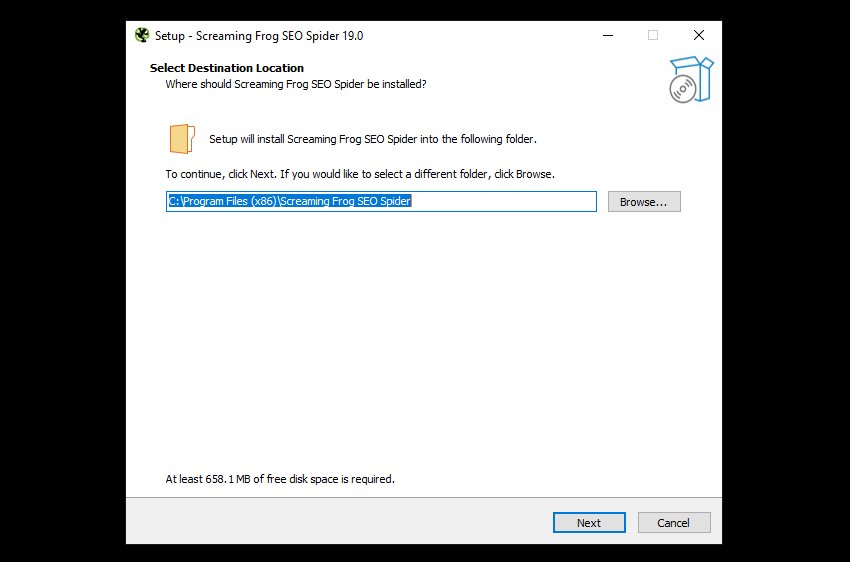
单击“是”,然后,除非您想安装到默认位置以外的任何位置,否则在下面的屏幕上选择“下一步”。
然后,系统会询问您是否需要桌面快捷方式,默认情况下已选中该快捷方式。再次单击“下一步”。
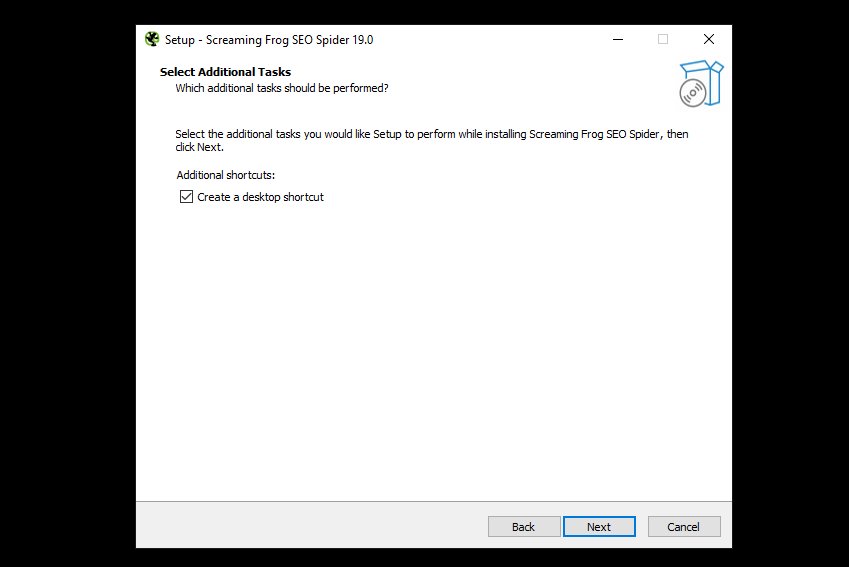
现在单击“安装”以开始安装。
安装过程将开始,将 SEO Spider 所需的文件复制到您的计算机,完成后,您将看到此屏幕。
单击“完成”以启动 SEO Spider。
命令行安装
您还可以通过命令行以静默方式安装,如下所示。
ScreamingFrogSEOSpider-VERSION.exe /VERYSILENT
默认情况下,这会将 SEO Spider 安装到:
C:\Program Files (x86)\Screaming Frog SEO Spider
您可以使用以下命令选择其他位置:
ScreamingFrogSEOSpider-VERSION.exe /VERYSILENT /DIR=C:\My Folder
故障排除
- “Error opening file for writing”(写入文件时出错)– 重新启动计算机并重试安装。
卸载
单击屏幕左下角的“开始”图标,然后键入“添加”以在�控制面板中找到“添加或删除程序”。
单击搜索框,然后输入“SEO”以在应用程序列表中找到 Screaming Frog SEO Spider。现在单击右侧的三个点,然后从下拉菜单中选择“卸载”。
在卸载过程中,系统会询问您是否要删除所有抓取、设置和许可证信息。
通过命令行卸载
您可以按如下方式执行 SEO Spider 的静默卸载:
"C:\Program Files (x86)\Screaming Frog SEO Spider\unins000.exe" /SUPPRESSMSGBOXES /VERYSILENT
运行 SEO Spider
SEO Spider 可以通过两种方式运行。
GUI
单击屏幕左下角的“开始”图标,键入“SEO Spider”以找到它,然后单击它以启动。
命令行
如果您想通过命令行运行,请参阅我们的用户指南。
在 macOS 上安装
这些说明是使用 macOS 11 Big Sur 编写的,适用于所有最新版本的 macOS。
下载最新版本的 SEO Spider。下载的文件将被命名为 ScreamingFrogSEOSpider-19.0-aarch64.dmg、ScreamingFrogSEOSpider-19.0-x86_64.dmg 或类似名称,具体取决于版本和机器架构。
如果您不确定要下载哪个版本,请参阅我们的常见问题解答 我的 Mac 需要哪个版本的 SEO Spider?。
该文件很可能会下载到您的“下载”目录,可以通过 Finder 轻松访问。
安装
下载的文件是一个磁盘映像,其中包含 Screaming Frog SEO Spider 应用程序。转到 Finder 中的“下载”文件夹,双击下载的文件,您将看到以下屏幕。

单击左侧的 Screaming Frog SEO Spider 应用程序图标,然后将其拖到右侧的“应用程序”文件夹中。这会将 Screaming Frog SEO Spider 应用程序复制到您的“应用程序”文件夹,这是 macOS 上大多数应用程序所在的位置。
现在,单击左上角的 x 关闭此窗口。转到 Finder,查看左侧的“设备”部分,找到 ScreamingFrogSEOSpider,然后单击其旁边的弹出图标。

卸载
Apple 有一个关于使用 Finder 卸载应用程序 的优秀指南。
从 Dock 打开 Finder,然后单击左侧的“应用程序”。
接下来,找到“Screaming Frog SEO Spider”,然后右键单击并“移到废纸篓”。
或者,将应用程序拖到废纸篓。将应用程序移到废纸篓后,要删除该应用程序,请选择“Finder > 清倒废纸篓”。
运行 SEO Spider
SEO Spider 可以通过两种方式运行。
GUI
使用 Finder 转到您的“应用程序”文件夹,找到 Screaming Frog SEO Spider 图标,然后双击它以启动。
命令行
如果您想通过命令行运行,请参阅我们的用户指南。
故障排除
如果在打开 .dmg 时收到类似这样的消息,请重新启动您的 Mac 并重试。
在 Ubuntu 上安装
这些说明适用于在 Ubuntu 18.04.1 上安装。
下载最新版本的 SEO Spider。下载的文件将被称为类似于 screamingfrogseospider_16.7_all.deb 的名称,并且很可能位于您主目录中的“下载”文件夹中。
安装
您可以通过两种方式之一安装 SEO Spider。
GUI
– 双击 .deb 文件。
– 选择“安装”并输入您的密码。
– SEO Spider 需要运行 ttf-mscorefonts-install,因此在弹出时接受此许可证。
– 等待安装完成。
命令行
打开一个终端并输入以下命令。
sudo apt-get install ~/Downloads/screamingfrogseospider_15.2_all.deb
您需要输入您的密码,然后在询问您是否要继续时输入 Y,并接受 ttf-mscorefonts-install 安装的 EULA。
故障排除
E: Unable to locate package screamingfrogseospider_15.2_all.deb
请确保您正在输入 .deb 的绝对路径以按照示例进行安装。
Failed to fetch http://archive.ubuntu.com/ubuntu/pool/main/u/somepackage.deb 404 Not Found [IP: 91.189.88.149 80]
请运行以下命令并重试。
sudo apt-get update
运行 SEO Spider
无论 SEO Spider 是如何安装的,您都可以通过两种方式之一运行它。
GUI
单击左下角的“应用程序”图标,键入“seo spider”,然后在应用程序图标出现时单击它。
命令行
在终端中输入以下命令:
screamingfrogseospider
有关更多命令行选项,请参阅我们的用户指南。
在 Fedora 上安装
这些说明适用于在 Fedora Linux 35 上安装。
下载最新版本的 SEO Spider。下载的文件将被称为类似于 screamingfrogseospider-17.0-1.x86_64.rpm 的名称,并且很可能位于您主目录中的“下载”文件夹中。
安装
打开一个终端并输入以下命令。
sudo rpm -i ~/Downloads/screamingfrogseospider-17.0-1.x86_64.rpm
运行 SEO Spider
SEO Spider 已安装,您可以通过两种方式之一运行它。
GUI
单击左上角的“活动”图标,键入“seo spider”,然后在应用程序图标出现时单击它。
命令行
在终端中输入以下命令:
screamingfrogseospider
有关更多命令行选项,请参阅我们的用户指南。
抓取
Screaming Frog SEO Spider 可以免费下载和使用,每次最多可以抓取 500 个 URL。每年只需 199 英镑,您就可以购买许可证,这将取消 500 个 URL 的抓取限制。
许可证还提供对配置、保存和打开抓取以及高级功能(例如 – JavaScript 渲染、自定义搜索、自定义提取、Google Analytics 集成、Google Search Console 集成、PageSpeed Insights 集成、计划等等!)的访问权限。
请参阅我们的定价页面上免费与付费功能的比较。
如果您是该软件的新用户,我们建议阅读我们的 SEO Spider 入门指南。
抓取网站(子域名)
在常规抓取模式下,SEO Spider 将抓取您输入的子域名,并将遇到的所有其他子域名默认视为外部链接(这些链接显示在“外部”选项卡下)。
例如,通过在顶部的“输入要抓取的 URL”框中输入 https://www.screamingfrog.co.uk 并单击“开始”,将抓取 Screaming Frog www 子域名。

可以将顶部过滤器从“子域名”调整为抓取“所有子域名”。
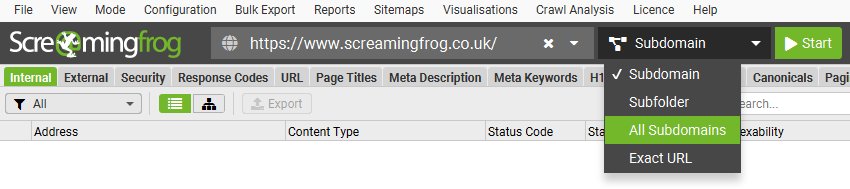
这意味着它可能会抓取其他子域名,例如 us.screamingfrog.co.uk 或 support.screamingfrog.co.uk(如果它们存在并且是内部链接)。如果您从根目录(例如 https://screamingfrog.co.uk)开始抓取,则 SEO Spider 默认也会抓取所有子域名。
SEO Spider 最常见的用途之一是查找网站上的错误,例如断开的链接、重定向和服务器错误。请阅读我们关于如何查找断开的链接的指南,其中解释了如何查看 404 等错误的来源,并将来源数据批量导出到电子表格。
为了更好地控制您的抓取,请使用您网站的 URL 结构,方法是抓取子文件夹、SEO Spider 的配置选项(例如仅抓取 HTML(图像、CSS、JS 等))、排除功能、自定义 robots.txt、包含功能 或更改 SEO Spider 的模式并上传要抓取的 URL 列表。
抓取子文件夹
要抓取子文件夹,请输入您要抓取的子文件夹,然后从顶部切换器中选择“子文件夹”。

通过直接将其输入到 SEO Spider 中,它将仅抓取 /blog/ 子文件夹中包含的所有 URL。
如果子文件夹的末尾没有尾部斜杠,例如“/blog”而不是“/blog/”,则 SEO Spider 将无法将其识别为子文件夹并在其中抓取。如果子文件夹的尾部斜杠版本重定向到非尾部斜杠版本,则同样适用。
要抓取此子文件夹,您需要使用包含功能并输入该子文件夹的正则表达式(在本例中为 .*blog.*)。
如果您有更复杂的设置(如子域名和子文件夹),您可以同时指定两者。例如 – http://de.example.com/uk/ 以抓取 .de 子域名和 UK 子文件夹等。
请查看我们关于抓取子域名和子文件夹的视频指南。
抓取 URL 列表
除了通过输入 URL 并点击“开始”来抓取网站之外,您还可以切换到列表模式,然后粘贴或上传要抓取的特定 URL 列表。

这对于站点迁移(例如,在审核 URL 和重定向时)特别有用。 我们建议阅读我们的指南“如何在站点迁移中审核重定向”,以获得最佳方法。
如果您希望以与上传相同的顺序导出列表模式下的数据,请使用用户界面顶部“上传”和“开始”按钮旁边的“导出”按钮。

导出中的数据将与原始上传中的顺序相同,并包含所有完全相同的 URL,包括重复项或执行的任何修复。
请查看我们的“如何使用列表模式”指南和视频,了解有关列表模式下更高级的抓取。
抓取更大的网站
SEO Spider 可以抓取的 URL 数量取决于使用的存储模式,以及可用的内存和 SEO Spider 中的内存分配。
如果您希望执行特别大的抓取,我们建议使用数据库存储模式并增加 SEO Spider 中的内存分配。
使用数据库存储意味着抓取数据将保存到磁盘,而不是仅保存在 RAM 中。 这使 SEO Spider 可以抓取更多 URL,抓取会自动存储并可以更快地打开在“文件 > 抓取”菜单下。
这可以在“文件 > 设置 > 存储模式”下配置,然后选择“数据库存储”。
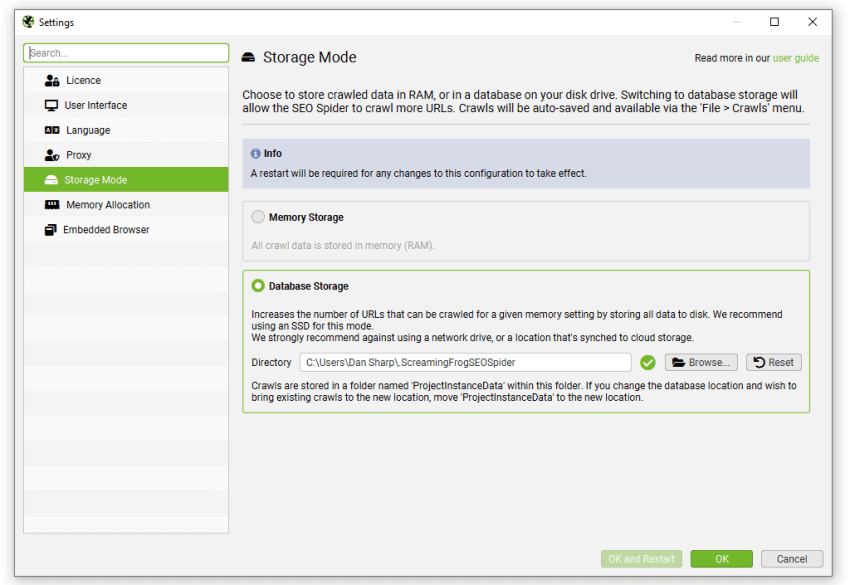
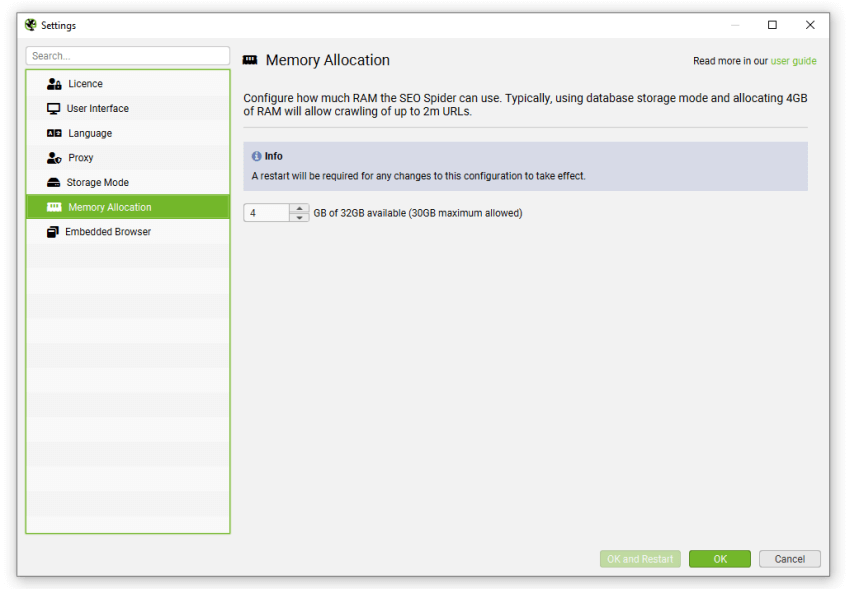
虽然 SEO Spider 会将所有数据保存到磁盘,但您仍然可以增加 RAM 内存分配,以使 SEO Spider 能够抓取更多 URL。 我们建议对于任何最多 200 万个 URL 的抓取,将其设置为 4gb。 这可以在“文件 > 设置 > 内存分配”下配置。
如果您收到“您正在耗尽此��抓取的内存”警告,则可以保存抓取并切换到数据库存储模式或增加 RAM 分配在内存存储模式下,然后打开并恢复抓取。
对于非常大的抓取,请阅读我们的如何抓取大型网站指南,其中提供了有关最佳设置和配置的详细信息,以使其尽可能易于管理和高效。
可用选项包括 -
- 如上所述,按子域或子文件夹抓取。
- 通过使用包含功能缩小抓取范围,或通过使用 排除或自定义 robots.txt 功能排除您不需要抓取的区域。
- 考虑通过抓取的总 URL 数、深度和查询字符串参数的数量来限制抓取。
- 考虑仅抓取内部 HTML,方法是在 SEO Spider 的配置中取消选中图像、CSS、JavaScript、SWF 和外部链接。
这些都应有助于节省内存并将抓取重点放在您需要的重要区域。
保存、打开、导出和导入抓取
可以使用 许可证在 SEO Spider 中保存和打开抓取。 保存和打开抓取的工作方式略有不同,具体取决于您配置的 SEO Spider 存储模式。
观看我们的视频或阅读下面的指南。
在数据库存储模式下保存和打开
在默认的数据库存储模式下,抓取会在抓取期间自动“保存”并提交到数据库中。
当您清除抓取、键入新的 URL ��或关闭 SEO Spider 时,抓取将自动存储。 如果您不小心关闭了机器、遇到崩溃或断电,抓取仍应安全存储。
要在数据库存储模式下打开抓取,请单击主菜单中的“文件 > 抓取”。
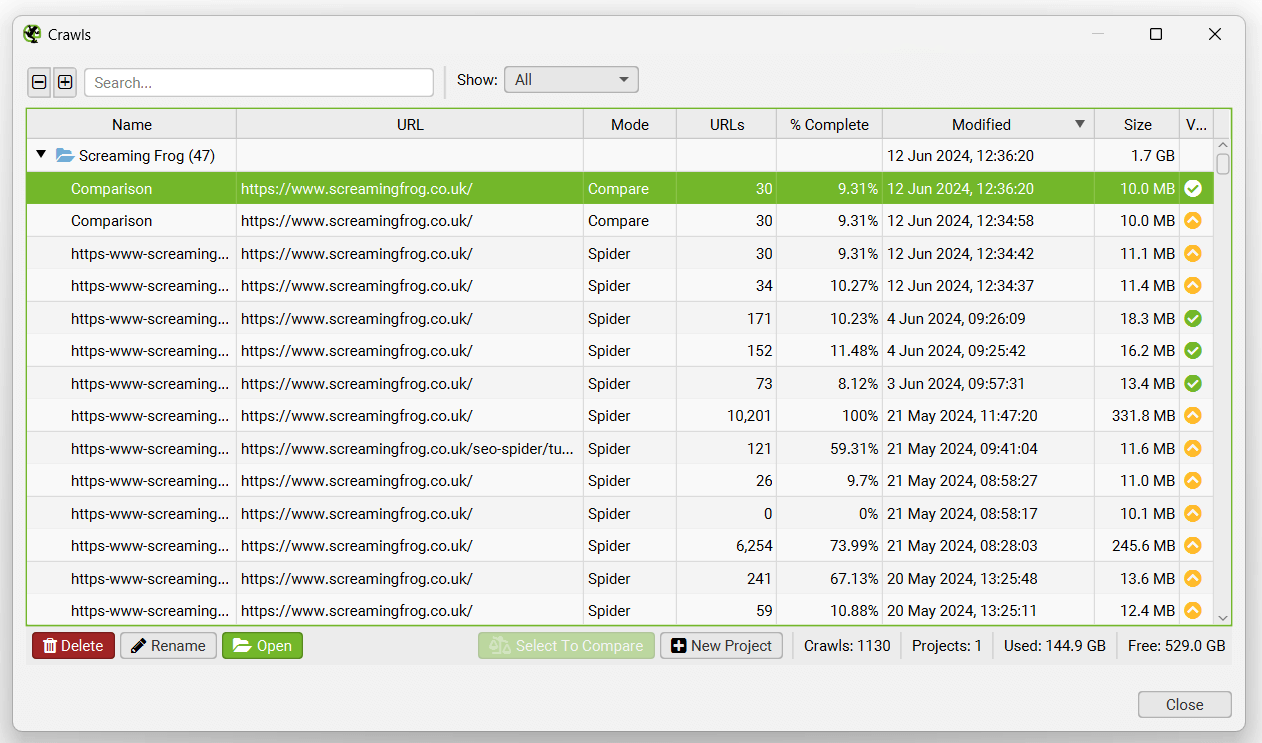
“抓取”窗口显示自动存储的抓取的概述,您可以在其中批量打开、重命名、组织到项目文件夹中、复制、导出或删除它们。
您可以导出抓取,以便其他用户可以在“文件 > 导出”下打开它。
在“另存为”对话框屏幕和“另存为类型”中,有两种选项可以在数据库存储模式下导出抓取。
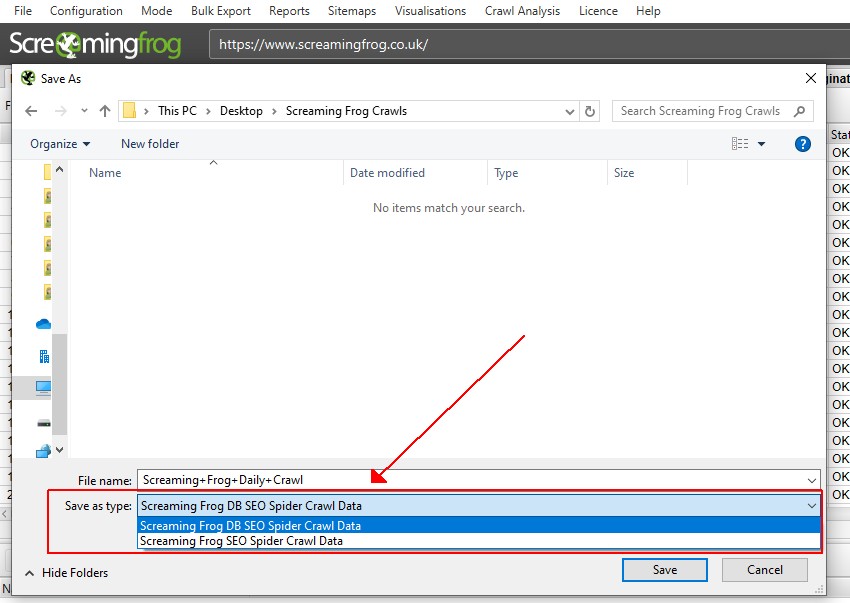
您可以导出数据库文件(.dbseospider 文件),该文件可以导入到数据库存储中的 SEO Spider 中。 这是推荐的默认选项,因为它速度更快。
或者,抓取也可以导出为 .seospider 文件,该文件可以使用内存或数据库存储模式导入到 SEO Spider 中。
在数据库存储模式下,.seospider 文件将被转换并提交到数据库,这将比打开 .dbseospider 文件花费更长的时间。 但是,一旦它进入数据库,就可以通过“文件 > 抓取”菜单访问,并允许更快地打开。
要在数据库存储模式下导入 .dbseospider 文件,请单击“文件 > 导入”。 .dbseospider 文件无法在内存存储模式下打开。
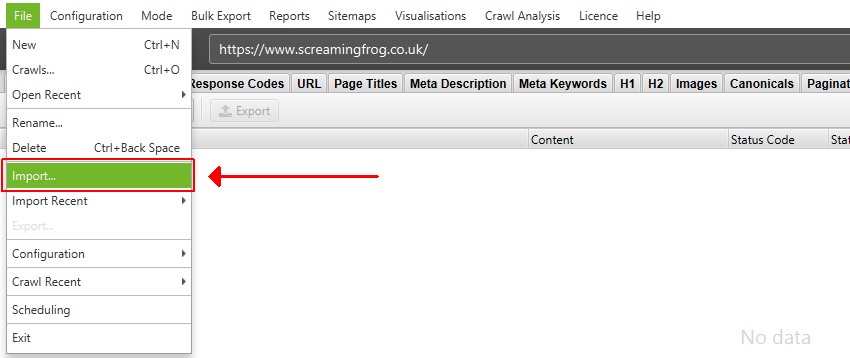
要在数据库存储模式下导入 .seospider 文件,请单击“文件 > 导入”,然后将“文件类型”从“Screaming Frog DB SEO Spider 抓取数据”切换为“Screaming Frog SEO Spider 抓取数据”,然后单击相关文件。
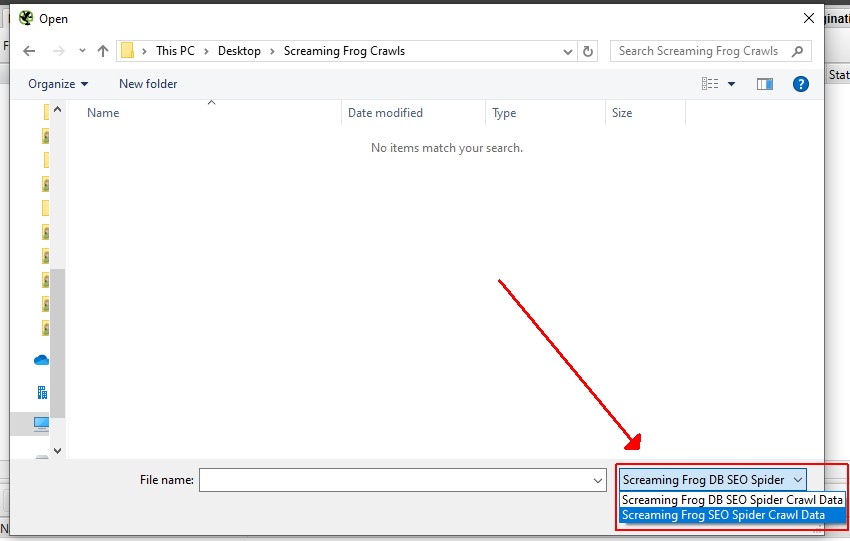
如上所述,.seospider 文件最初需要更长的时间才能导入,但在转换为数据库后,可以在“文件 > 抓取”菜单下使用。
在内存存储模式下保存和打开
内存存储是较旧的存储模式,以前是 SEO Spider 的默认模式。 在内存存储模式下,抓取需要保存为特定于 SEO Spider 的 .seospider 文件类型。
您可以通过暂停 SEO Spider 来保存部分抓取,或者通过选择“文件 > 保存”来在抓取结束时保存。
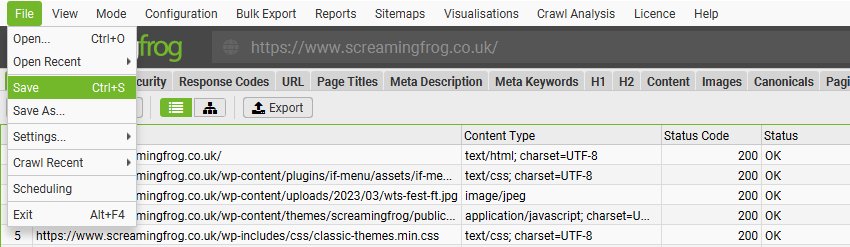
要打开抓取,只需双击相关的 .seospider 文件,选择“文件 > 打开”并导航到该文件,或者在“文件 > 打开最近”下选择您最近的抓取之一。 如果抓取已暂停,您可以恢复抓取。
请注�意,保存和打开抓取可能需要几分钟或更长时间,具体取决于抓取的大小和数据量。 只有 .seospider 抓取文件可以在内存存储模式下打开,而不是下一节中讨论的数据库文件 .dbseospider 文件。
如果您计划执行大型抓取,我们建议考虑数据库存储模式,因为打开抓取的速度要快得多。
配置
在该工具的许可版本中,您可以保存默认抓取配置,并保存配置配置文件,这些配置文件可以在需要时加载。
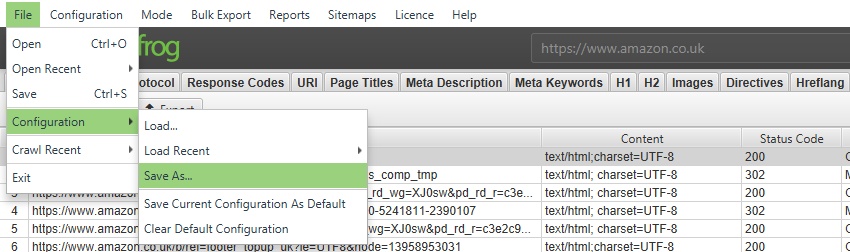
要将当前配置保存为默认配置,请选择“配置 > 配置文件 > 将当前配置另存为默认配置”。
要保存配置配置文件以便将来能够加载,请单击“配置 > 配置文件 > 另存为”并调整文件名(最好是描述性的!)。
要加载配置配置文件,请单击“配置 > 配置文件 > 加载”并选择您的配置配置文件,或单击“配置 > 配置文件 > 加载最近”以从最近的列表中选择。
要重置回原始 SEO Spider 默认配置,请选择“配置 > 配置文件 > 清除默认配置”。
请查看我们的自定义配置视频指南。
计划
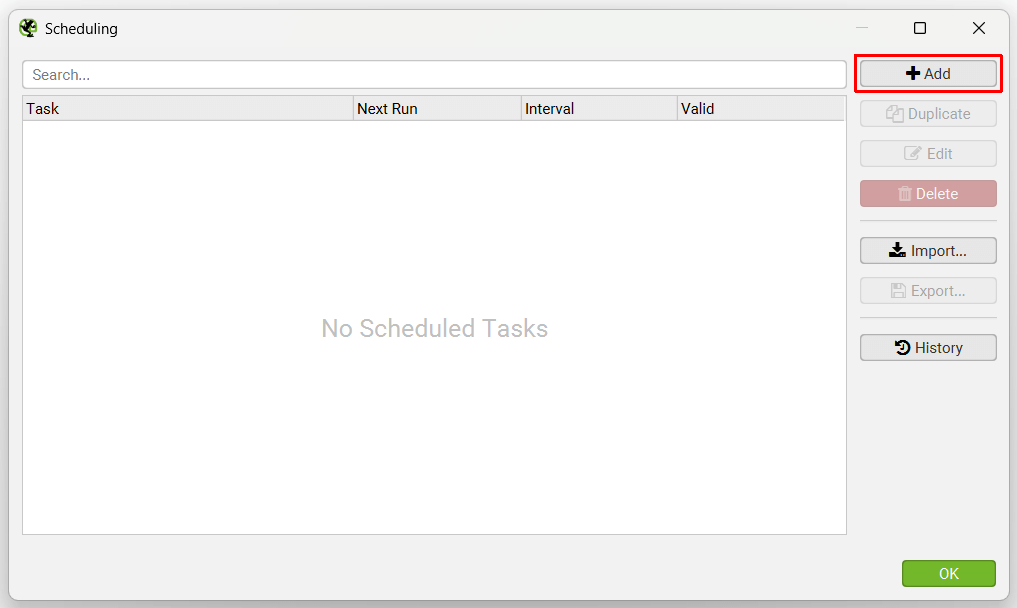
您可以在 SEO Spider 中安排抓取自动运行,作为一次性运行或按选定的时间间隔运行。 此功能可以在应用程序中的“文件 > 计划”下找到。
单击“添加”以设置计划的抓取。
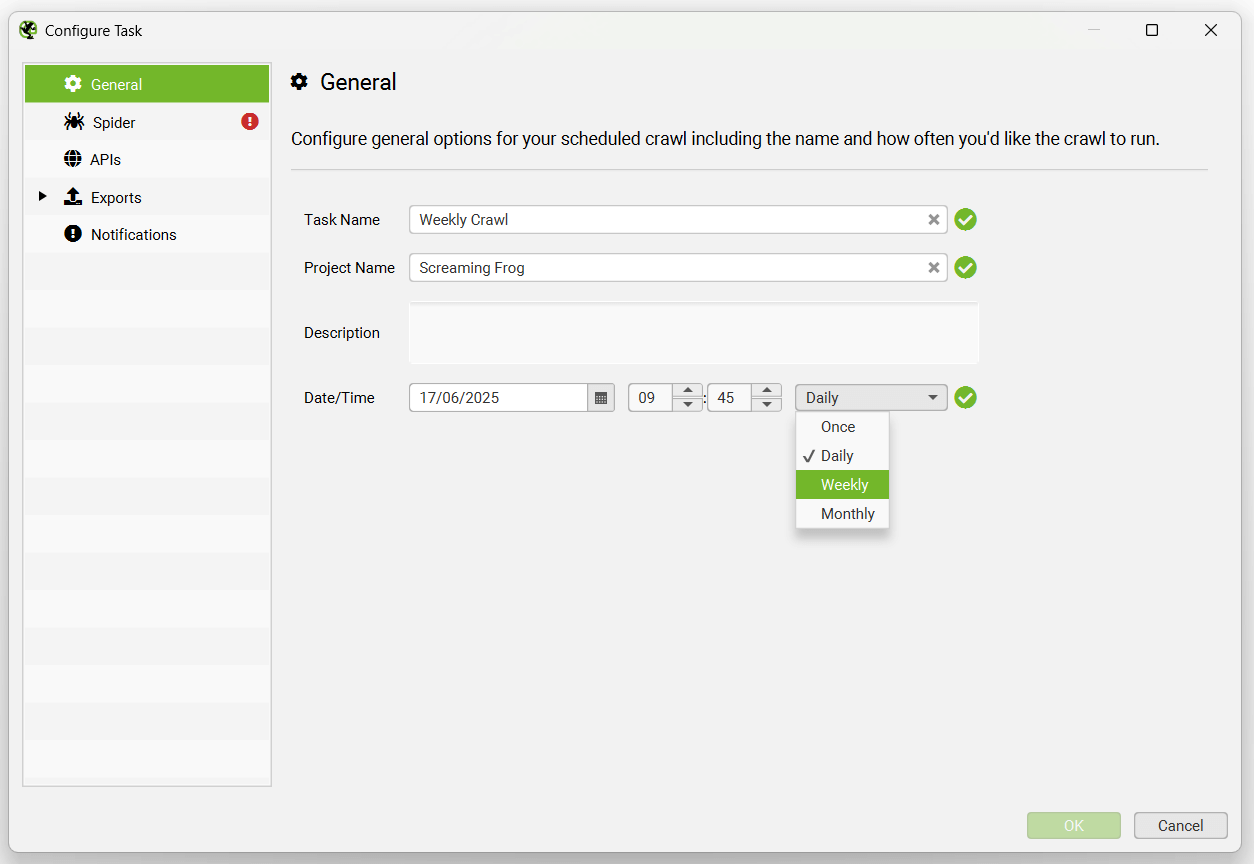
选择任务名称、应保存到的项目、日期和计划抓取的时间间隔。
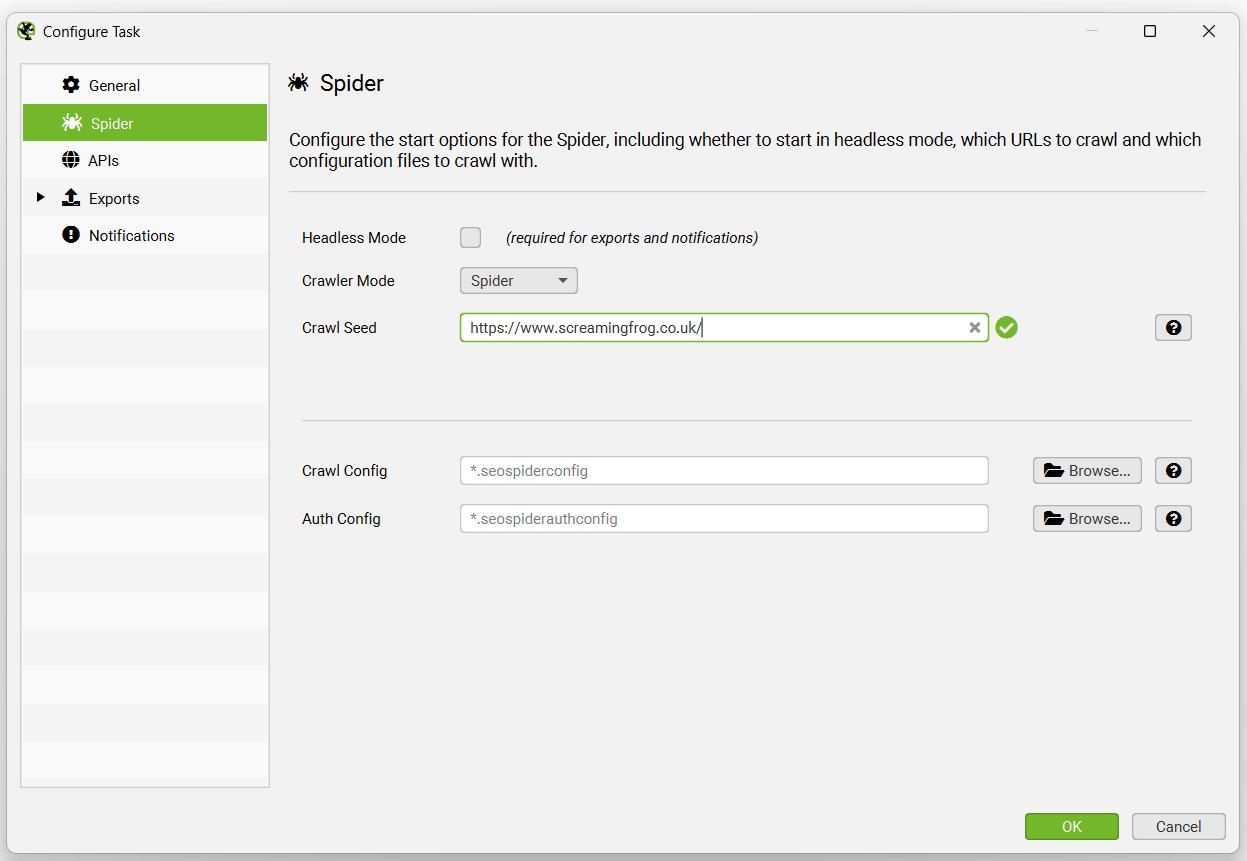
您可以预先选择模式(spider 或列表)、要抓取的网站地址、已保存的配置和计划抓取的身份验证配置。
API 选项卡允许您选择要连接到哪些 API 以进行计划的抓取,包括(Google Analytics、Search Console、PageSpeed Insights、Majestic、Ahrefs、Moz)。
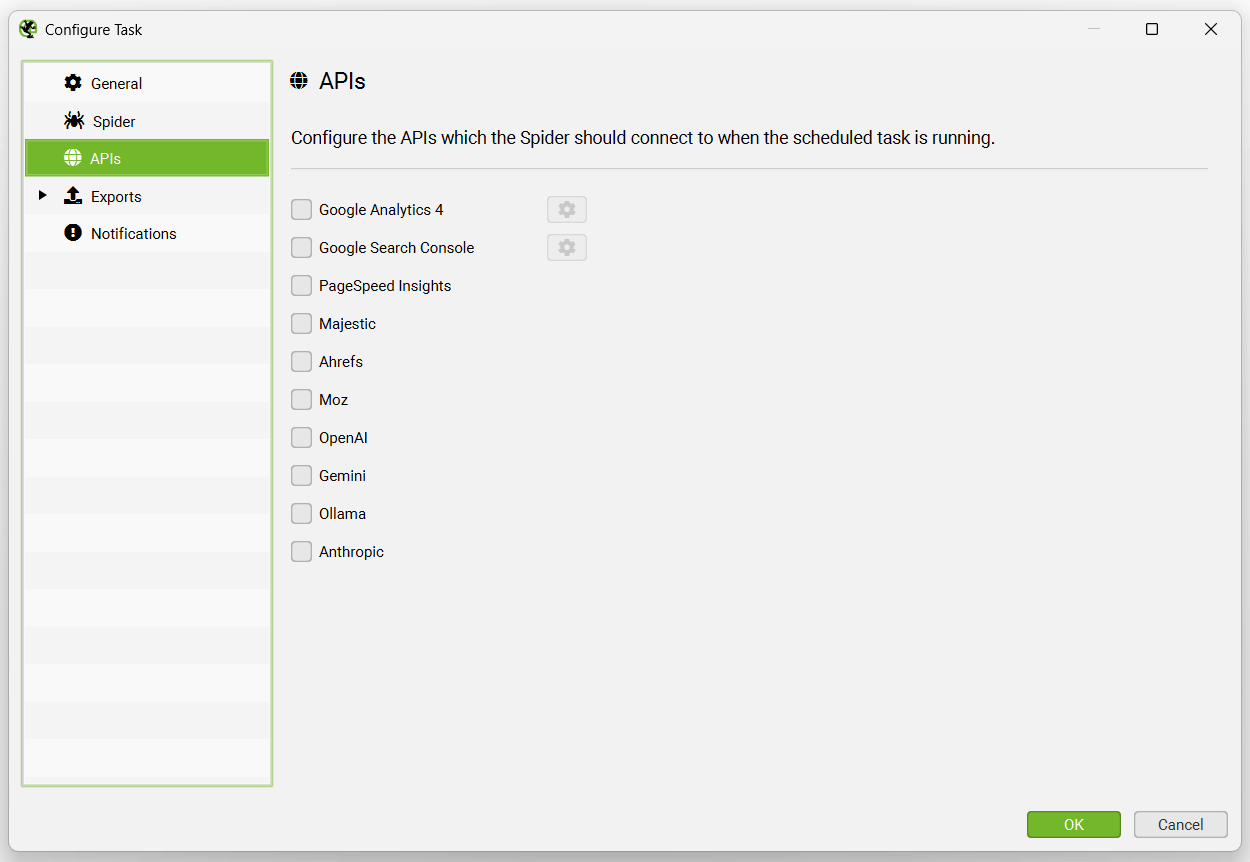
导出选项卡有多个子选项卡,包括输出设置、电子表格、本地文件、Looker Studio、预设和通知。
这些选项卡的顶部都会显示一条警告,即需要为导出配置“无头模式”。
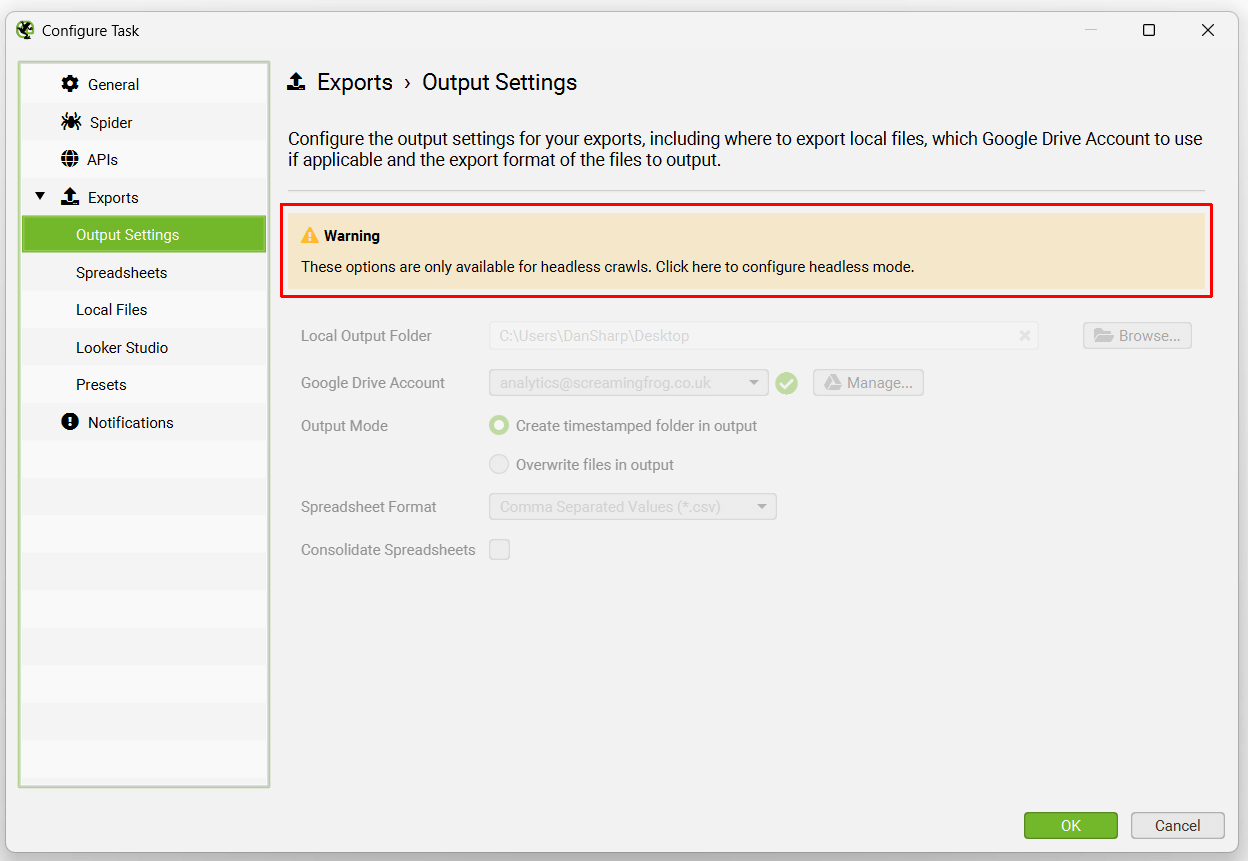
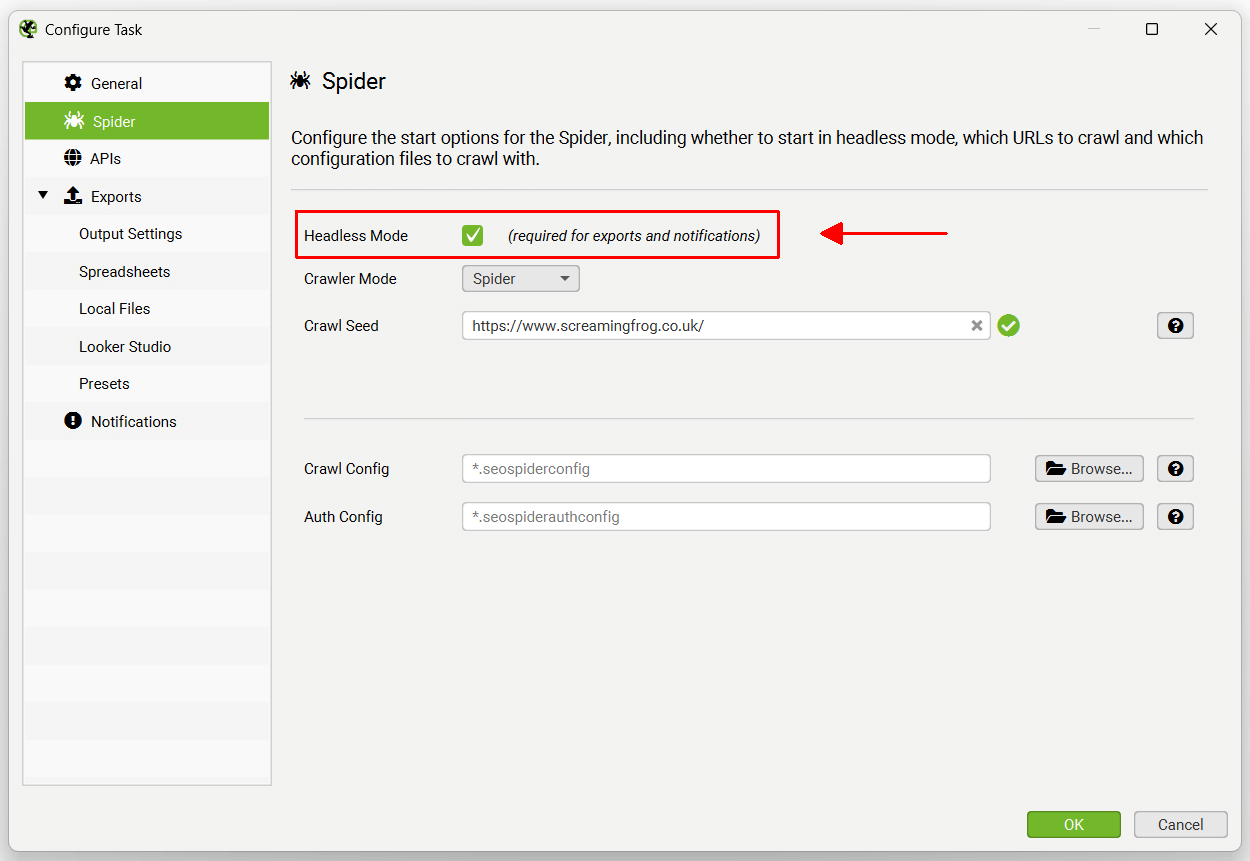
这仅仅意味着当 SEO Spider 运行计划的抓取时,UI 将不可见。 这是为了避免用户在计划的抓取执行操作时单击按钮,这可能会造成混淆并导致错误。
可以在“Spider”选项卡下启用无头模式。
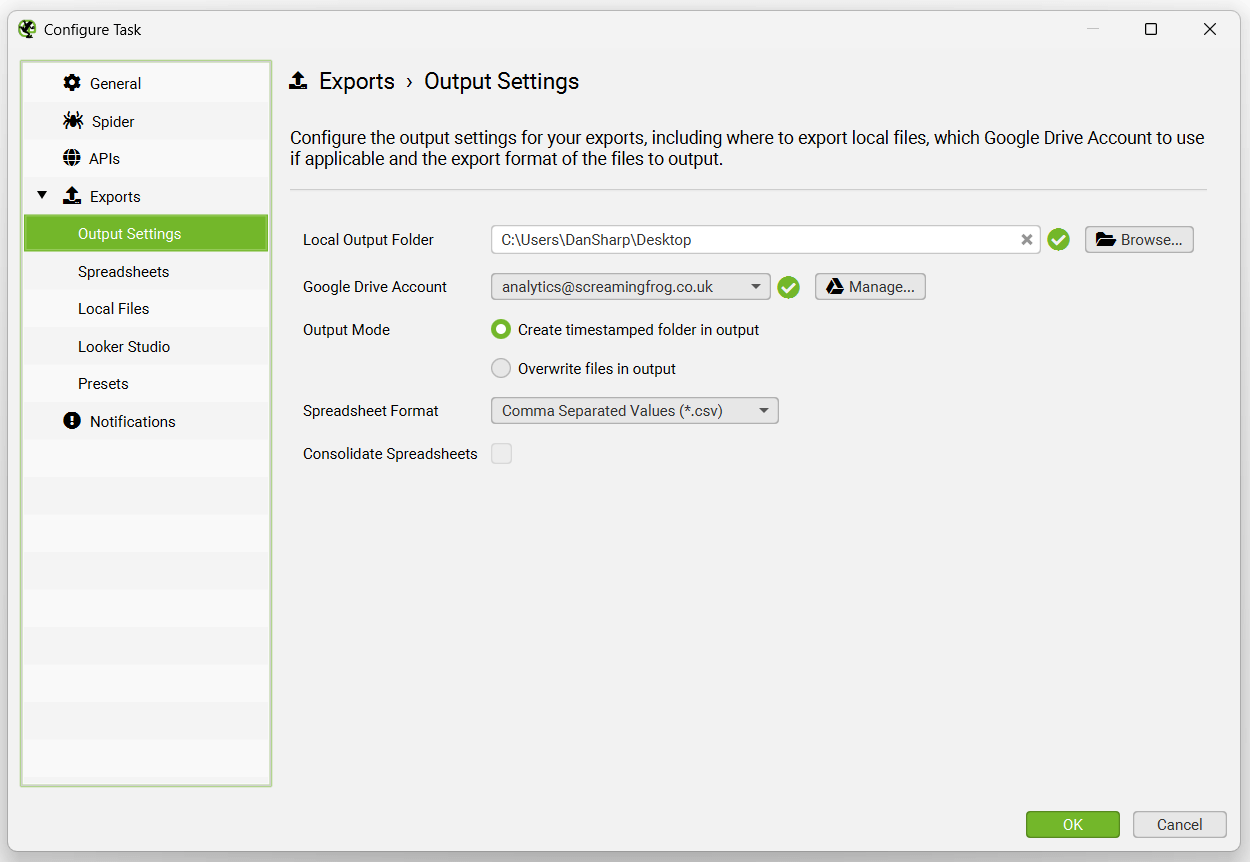
然后可以选择导出选项。
输出设置允许用户选择应如何导出文件 - 本地输出文件夹、Google Drive 帐户、带时间戳的文件夹或覆盖、电子表格格式(CSV、Excel 或 Google Sheets),以及将导出合并到单个电子表格中的选项卡中的选项。
电子表格选项卡允�许您选择任何选项卡和过滤器、批量导出和要导出的报告。
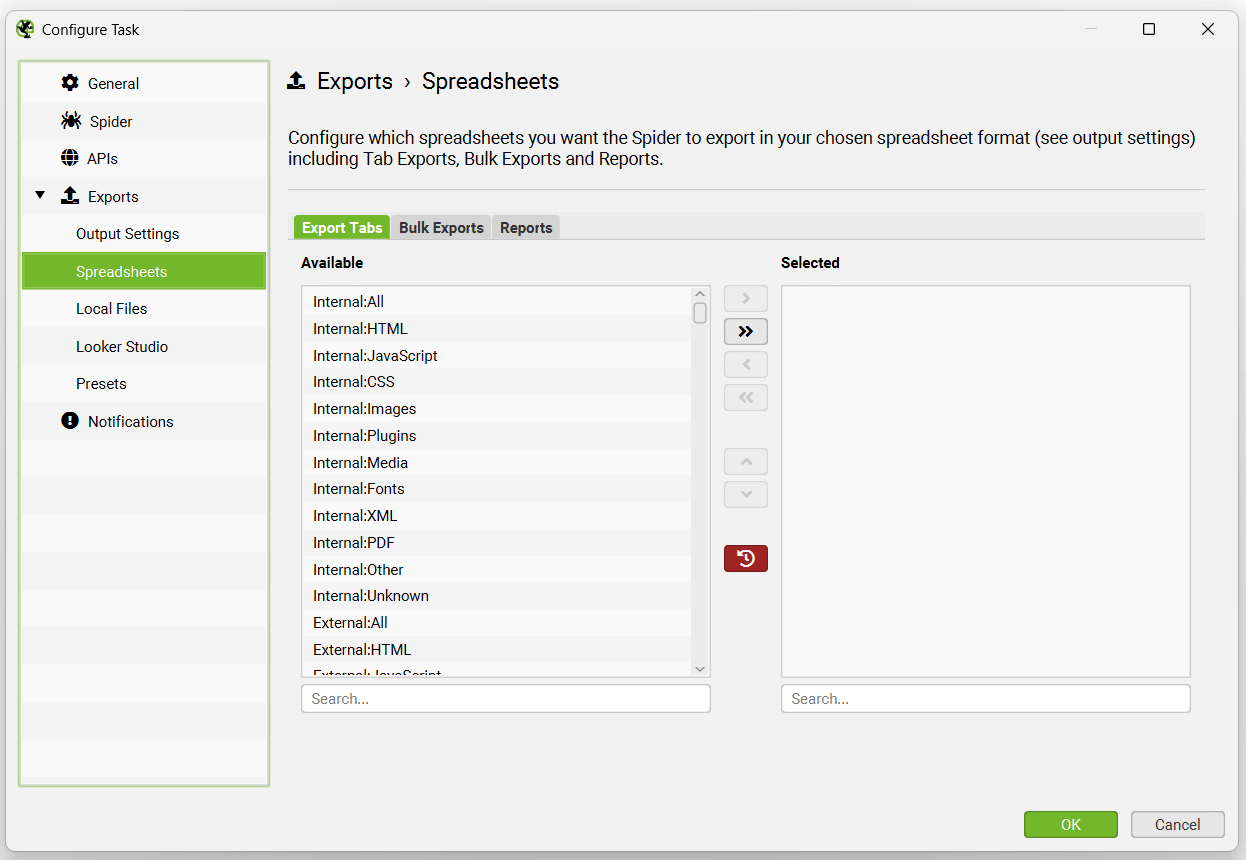
本地文件选项包括保存抓取(抓取在数据库存储模式下自动保存,因此通常不需要),创建 XML 站点地图或图像站点地图。
Looker Studio 选项卡允许用户将时序报告导出到可以连接到 Looker Studio 的 Google Sheets。
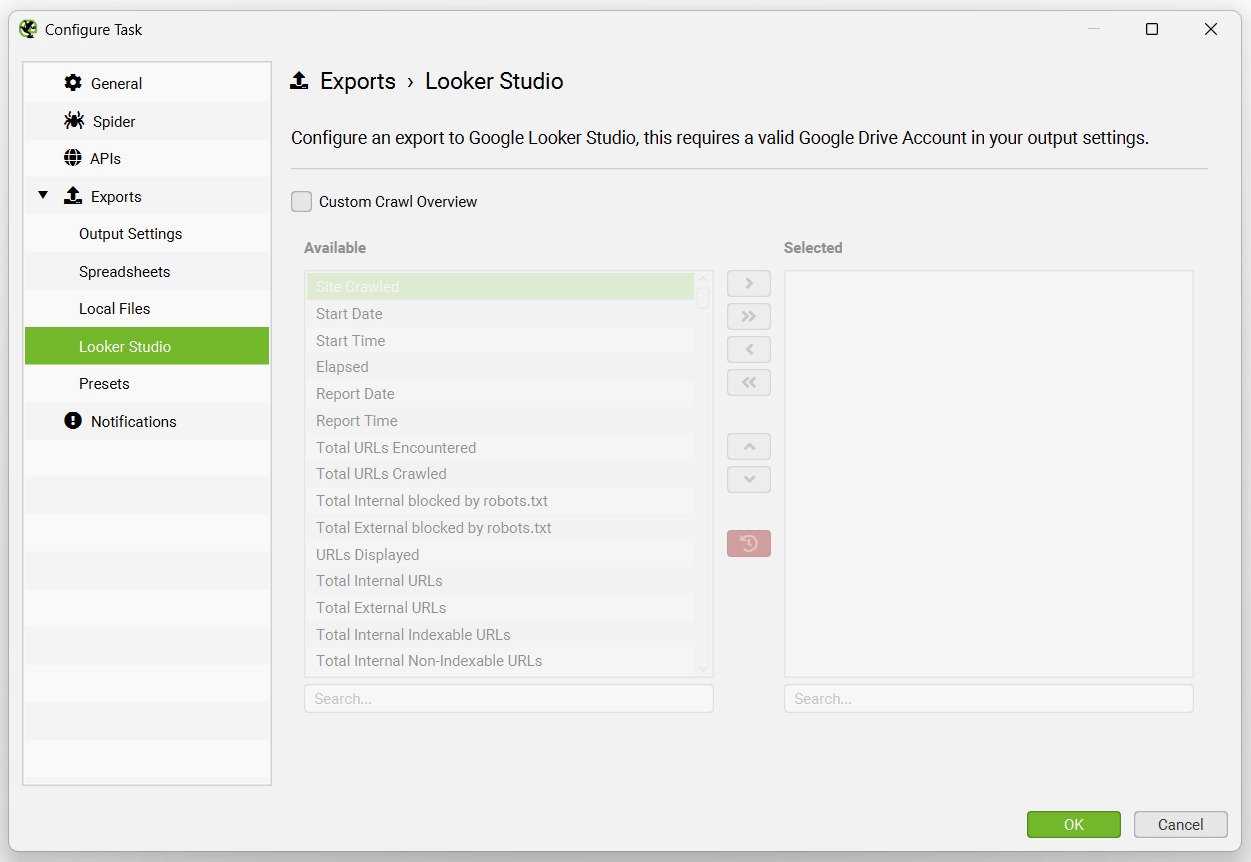
此功能专门设计用于允许用户选择抓取概览数据,并将其作为单个摘要行导出到 Google Sheets。它将自动将新的计划导出附加到同一工作表中的新行,形成时间序列。
请阅读我们的教程“如何在 Looker Studio 中自动化抓取报告”,以进行设置。
“预设”选项卡允许您设置多个报告的导出,作为一个预设,以便在计划的抓取中使用,从而提高效率。
“通知”选项允许在抓取完��成后发送电子邮件通知。请注意,目前这不会同时发送导出。
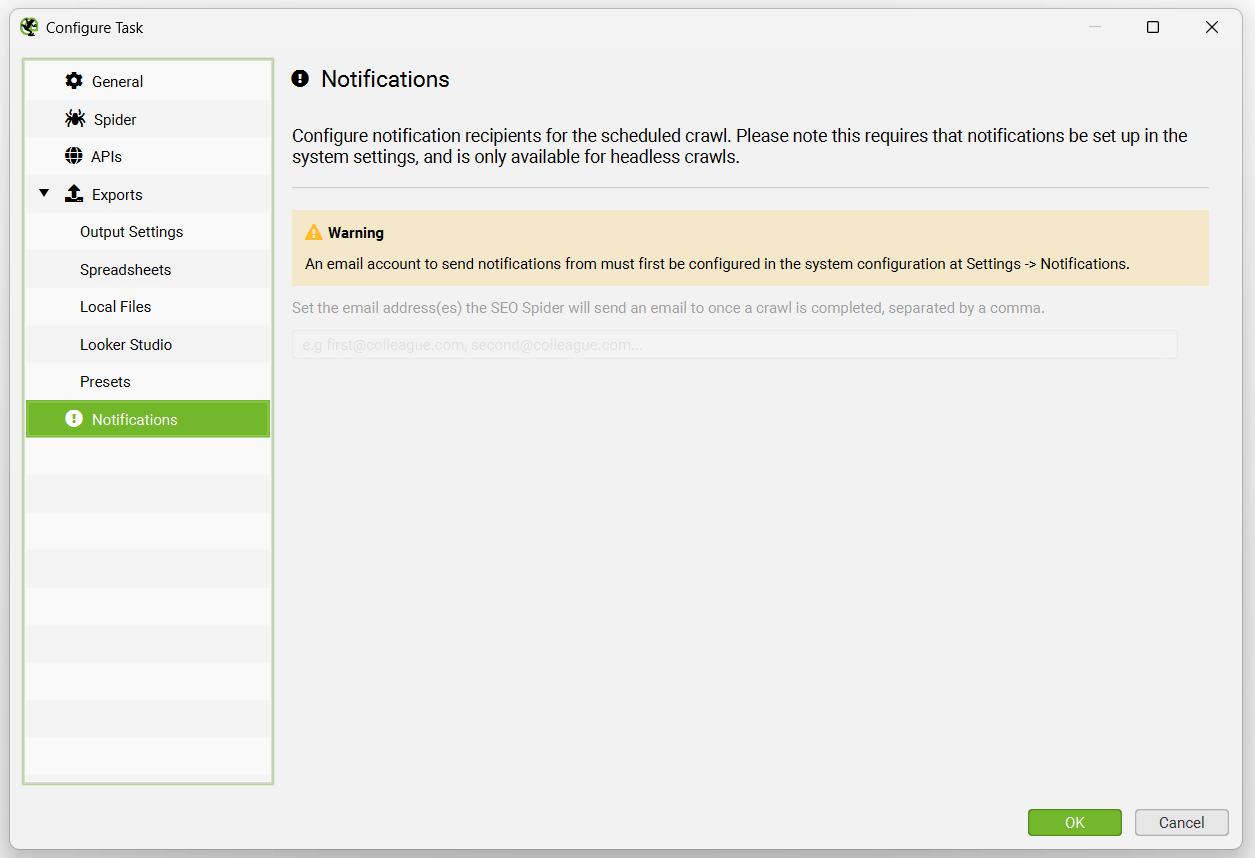
计划和 Google Sheets
在选择导出时,您可以选择通过将“格式”切换为 gsheet,自动将任何选项卡、过滤器、导出或报告导出到 Google Sheets。这将在您的 Google Drive 帐户中的“Screaming Frog SEO Spider”文件夹中保存一个 Google Sheet。
在计划中使用的“项目名称”和“抓取名称”将用作导出的文件夹。因此,例如,“Screaming Frog”项目名称和“每周抓取”名称将位于 Google Drive 中,如下所示。
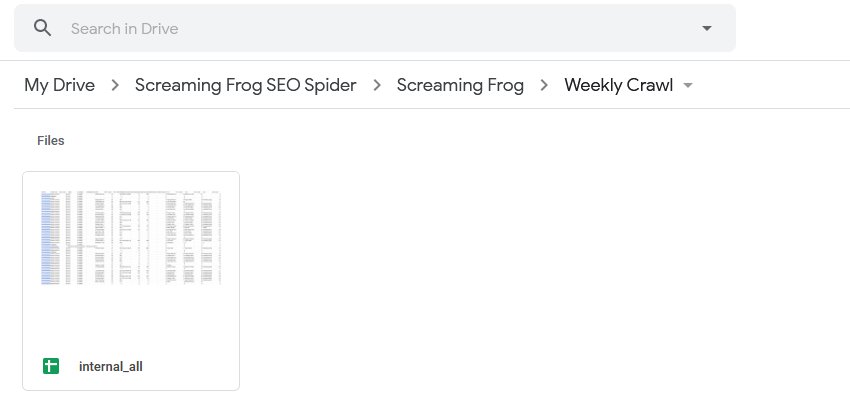
您还可以选择覆盖现有文件(如果存在),或者使用“输出设置”下的“输出模式”选项在 Google Drive 中创建一个带时间戳的文件夹。
计划提示
使用计划时,需要记住以下几点。
- 如果您使用的是数据库存储模式,则无需在计划中“保存”抓取,因为它们会自动存储在 SEO Spider 数据库中。在执行计划的抓取后,可以通过应用程序中的“文件 > 抓取”菜单打开抓取。请参阅我们的保存、打开、导出和导入抓取指南。
- 对于计划的抓取,将启动 SEO Spider 的新实例。因此,如果抓取发生重叠,SEO Spider 的多个实例将同时运行,而不是延迟到先前的抓取完成后。因此,我们建议适当考虑您的系统资源和抓取时间。
- 当计划导出数据时,SEO Spider 将在无头模式下运行(意味着没有界面)。这是为了避免任何用户交互或应用程序在您面前启动并单击选项,这会有点奇怪。
- 此计划是在用户界面中进行的,如果您更喜欢使用命令行来操作 SEO Spider,请参阅我们的命令行界面指南。
- 如果您在使用计划的抓取时遇到任何问题,第一步是查看“文件 > 计划”,并确保抓取设置为“有效”。如果无效,请单击选项卡以查找问题并更正任何突出显示的问题。如果计划的抓取有效,请单击“文件 > 计划 > 历史记录”,并检查抓取是否具有“结束”日期和时间,或者“错误”列下是否报告任何错误。
导出
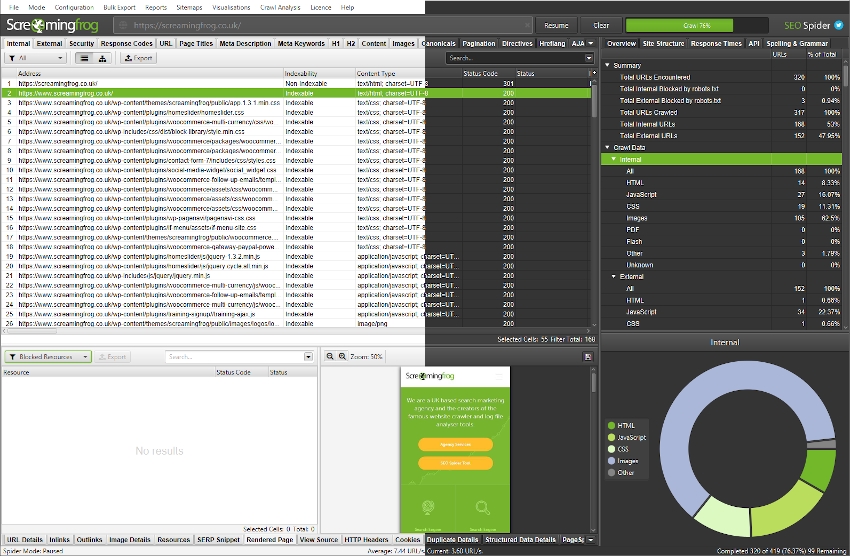
您可以导出抓取中的所有数据,包括批量导出内链和外链数据。以下概述了三种主要的导出数据方法。
导出选项卡和过滤器(顶部窗口数��据)
只需单击左上角的“导出”按钮,即可从顶部窗口选项卡和过滤器导出数据。

顶部窗口部分中的导出功能与顶部窗口中的当前视野一起使用。因此,如果您正在使用过滤器并单击“导出”,它将仅导出包含在过滤选项中的数据。
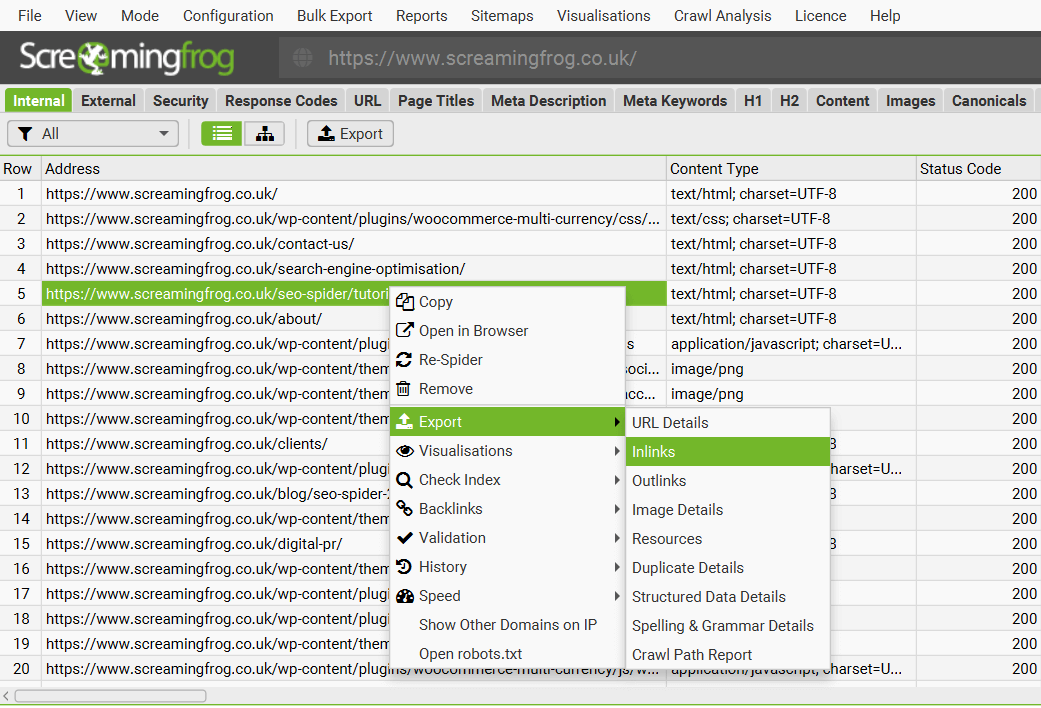
导出下部窗口数据
要导出下部窗口数据,只需在顶部窗口中右键单击要从中导出数据的 URL,然后单击其中一个选项。
可以通过这种方式导出以下下部窗口选项卡中的详细信息:
- URL 详细信息
- 内链
- 外链
- 图像详细信息
- 资源
- 重复详细信息
- 结构化数据详细信息
- 拼写和语法详细信息
- 抓取路径报告
也可以从下部窗口选项卡中的“导出”按钮导出此数据:
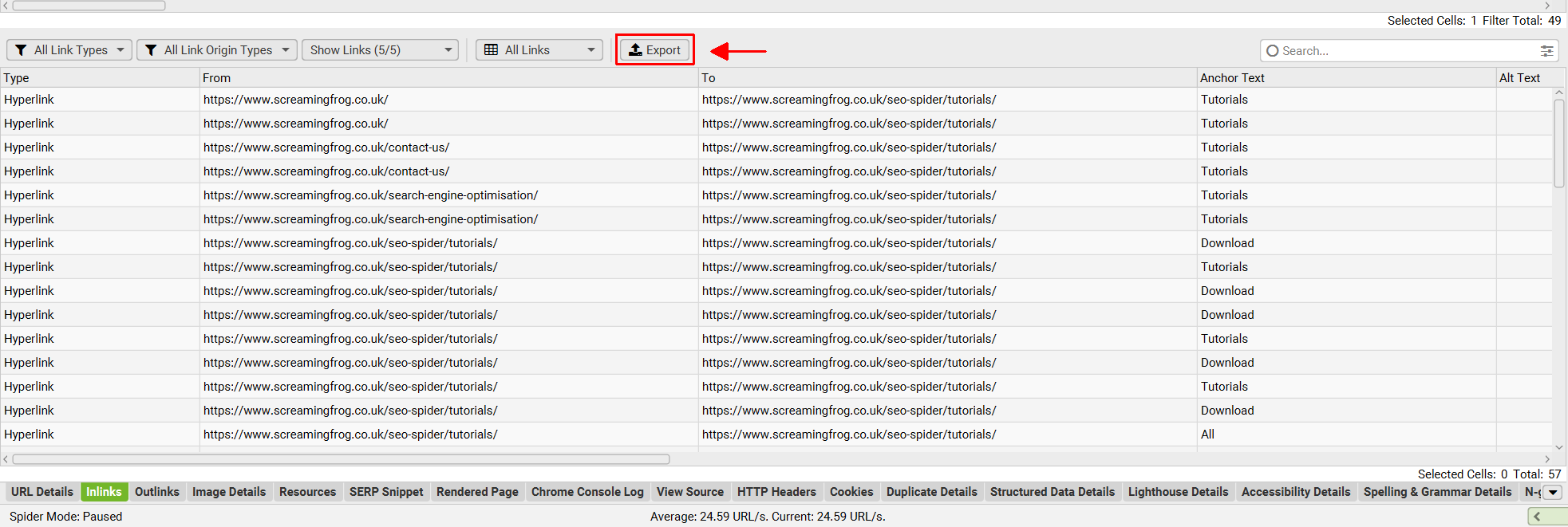
您还可以多选 URL(通过按住键盘上的 control 或 shift 键)并批量导出这些 URL 的数据。��例如,您可以批量导出特定感兴趣的 URL 的“内链”,并以相同的方式将其一起导出。
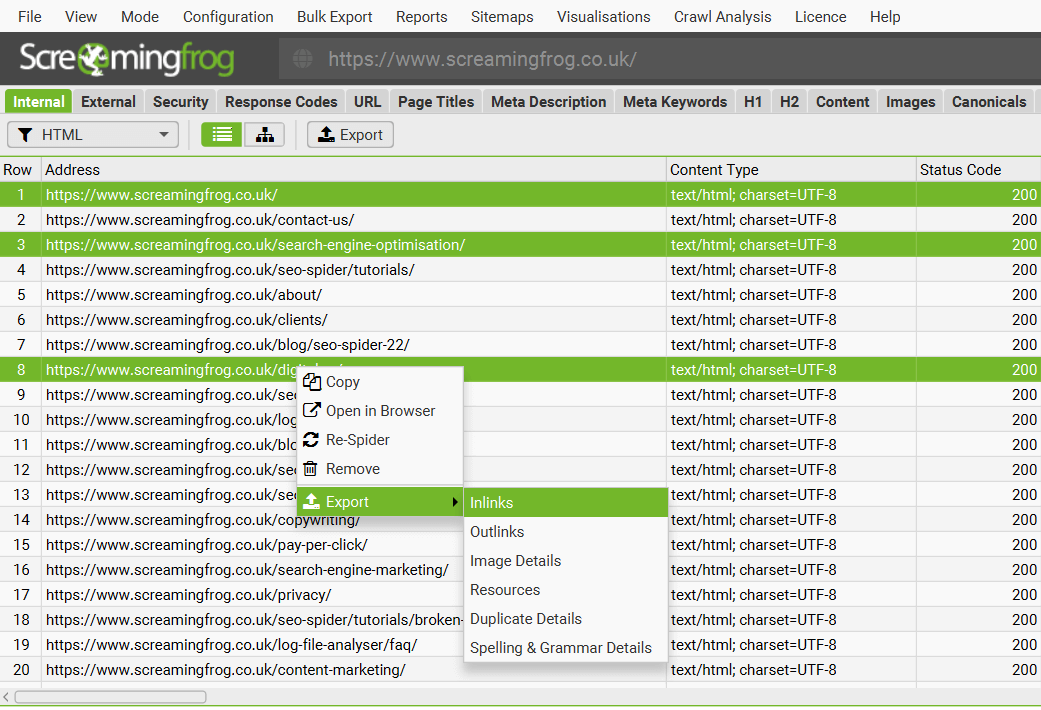
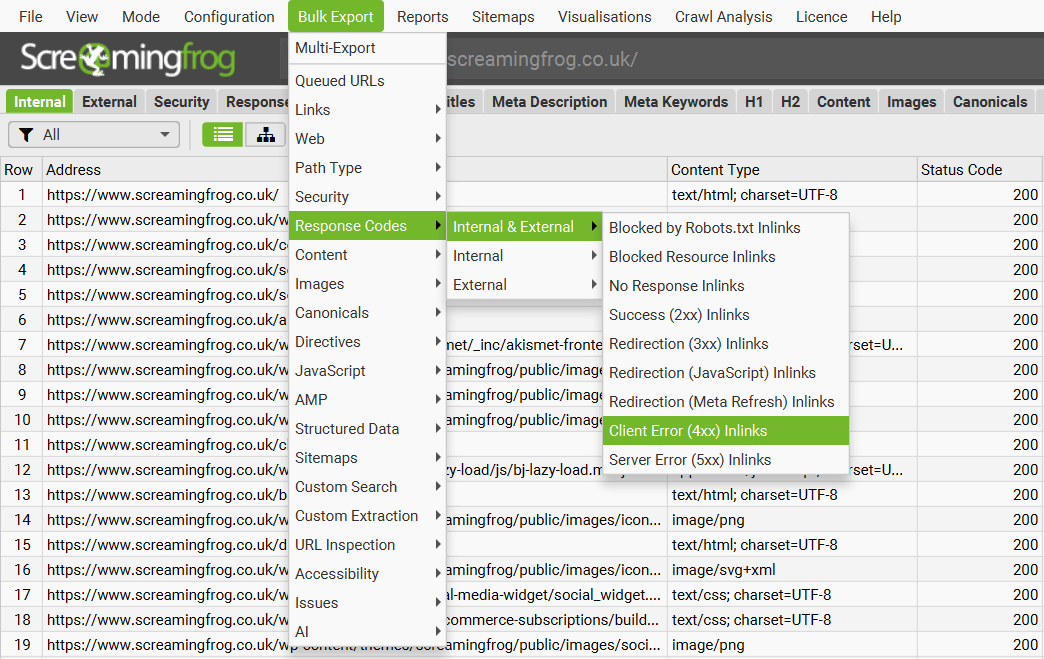
批量导出
“批量导出”位于顶级菜单下,允许批量导出所有数据。您可以通过“所有内链”选项导出在抓取中找到的链接的所有实例,或者导出具有特定状态代码(例如 2XX、3XX、4XX 或 5XX 响应)的 URL 的所有内链。
例如,选择“客户端错误 4XX 内链”选项将导出所有错误页面(例如 404 错误页面)的所有内链。您还可以导出所有图像 alt 文本、所有缺少 alt 文本的图像以及整个站点的所有锚文本。
查看我们的导出视频指南。
批量导出选项
以下导出选项在“批量导出”顶级菜单下可用。
- 排队的 URL: 这些是已发现的、在队列中等待抓取的所有 URL。这大致与 GUI 右下角的“剩余”URL 数量匹配。
- 链接 > 所有内链: 指向 SEO Spider 在抓取站点时遇到的每个 URL 的链接。这包含指向“响应代码”选项卡的“全部”过滤器中所有 URL 的每个链接(不仅是 ahref,还包括图像、规范、hreflang、rel next/prev 等)。
- 链接 > 所有外链: SEO Spider 在抓取期间遇到的所有链接。这将包含“响应代码”选项卡的“全部”过滤器中每个 URL 中包含的每个链接。
- 链接 > 所有锚文本: 指向“响应代码”选项卡中“全部”过滤器中 URL 的所有 ahref 链接。
- 链接 > 外部链接: 指向“外部”选项卡的“全部”过滤器下找到的 URL 的所有链接。
- 链接 > 带有 NoFollow 的内部外链: 使用带有 NoFollow 的内部外链的页面,如“链接”选项卡下所示。
- 链接 > 没有锚文本的内部外链: 具有没有锚文本的内部外链的页面,如“链接”选项卡下所示。
- 链接 > 内部外链中非描述性锚文本: 具有内部外链中非描述性锚文本的页面,如“链接”选项卡下所示。
- 链接 > 指向页面的 Follow 和 Nofollow 内部内链: 具有指向页面的 Follow 和 Nofollow 内部内链�的页面,如“链接”选项卡下所示。
- 链接 > 仅内部 Nofollow 内链: 具有仅 Nofollow 内链的页面,如“链接”选项卡下所示。
- 链接 > 指向 Localhost 的外链: 包含引用 Localhost 的链接的页面,如“链接”选项卡下所示。
- Web > 屏幕截图: 在“渲染页面”下部窗口选项卡中看到的所有屏幕截图的导出,在使用 JavaScript 渲染模式时存储。
- Web > 存档网站: 使用存档网站功能时存储的所有网站文件的导出。
- Web > 所有页面源代码: 抓取页面的静态 HTML 源代码或渲染的 HTML。渲染的 HTML 仅在 JavaScript 渲染模式下可用。
- Web > 所有页面文本: 从每个具有 200 响应的内部 HTML 页面导出页面文本,作为单独的 .txt 文件。
- Web > 所有 HTTP 标头: 所有 URL 及其对应的 HTTP 响应标头。必须启用“HTTP 标头”,才能通过“配置 > Spider > 提取”进行提取,以便填充此项。
- Web > 所有 Cookies: 所有 URL 以及在抓取中发出的每个 cookie。必须启用“Cookies”,才能通过“配置 > Spider > 提取”进行提取,以便填充此项。还需要配置 JavaScript 渲染模式,以获得使用 JavaScript 或像素图像标签加载到页面上的 cookie 的准确视图。
- 路径类型: 这将导出特定的路径类型链接及其链接的源页面。路径类型可以包括绝对路径、协议相对路径、根相对路径和路径相对路径链接。
- 安全性: 指向“安全性”选项卡的相应过滤器中的 URL 的所有链接。例如,指向站点上包含“不安全跨域链接”的所有页面的链接。
- 响应代码: 指向“响应代码”选项卡的相应过滤器中的 URL 的所有链接。例如,指向站点上以 404 错误响应的 URL 的所有源链接。
- 内容: 指向“内容”选项卡的相应过滤器中的 URL 的所有链接。例如,近似重复项及其在所选相似度阈值之上的所有相应近似重复 URL。
- 图像: 指向“图像”选项卡的相应过滤器中的图像 URL 的所有引用。例如,指向缺少 alt 文本的图像的所有引用。
- 规范: 指向“规范”选项卡的相应过滤器中的 URL 的所有链接。例如,指向缺少规范 URL 的链接。
- 指令: 指向“指令”选项卡的相应过滤器中的 URL 的所有链接。例如,指向站点上包含 meta robots 'noindex' 标签的所有页面的链接。
- AMP: 指向“AMP”选项卡的相应过滤器中的 URL 的所有链接。例如,具有非 200 响应的 amphtml 链接的页面。
- 结构化数据: 指向“结构化数据”选项卡的相应过滤器中的 URL 的所有链接。例如,指向具有验证错误的 URL 的链接。RDF Web 数据格式是一系列三元组(主语、谓语、宾语)语句。这就是批量报告的结构方式。JSON-LD 的分层格式不适合电子表格格式;而三元组语句则适合。
- 站点地图: 指向“站点地图”选项卡的相应过滤器中的图像 URL 的所有引用。例如,包含不可索引 URL 的所有 XML 站点地图。
- 自定义搜索: 指向“自定义搜索”选项卡的相应过滤器中的 URL 的所有链接。例如,指向站点上与自定义搜索匹配的所有页面的链接。
- 自定义提取: 指向“自定义提取”选项卡的相应过滤器中的 URL 的所有链接。例如,指向具有在自定义提取中设置的特定数据提取的页面的链接。
- URL 检查: 这包括通过 Search Console 中的 URL 检查 API 集成的精细“富媒体搜索结果”、“引用页面”和“站点地图”数据。“富媒体搜索结果”批量导出包含富媒体搜索结果类型、有效性、严重性和问题类型��。“引用页面”包括每个检查的 URL 最多 5 个可用的引用页面。“站点地图”包括检查的 URL,以及发现它的站点地图 URL。
- 可访问性: WCAG 级别的所有违规或违规。导出包括在“可访问性详细信息”选项卡中看到的详细可访问性问题,例如所有 URL 的问题、准则、影响和页面上的位置。
- 问题: 在“问题”选项卡中发现的所有问题(包括它们的“内链”变体)作为文件夹中的单独电子表格(作为 CSV、Excel 和 Sheets)。
- AI: 使用 OpenAI 和 Gemini 中能够生成它们的 AI 模型导出图像或文本到语音音频文件。
多重导出
“批量导出”菜单下的“多重导出”选项允许您选择任何选项卡、批量导出或报告,只需单击一下即可导出。
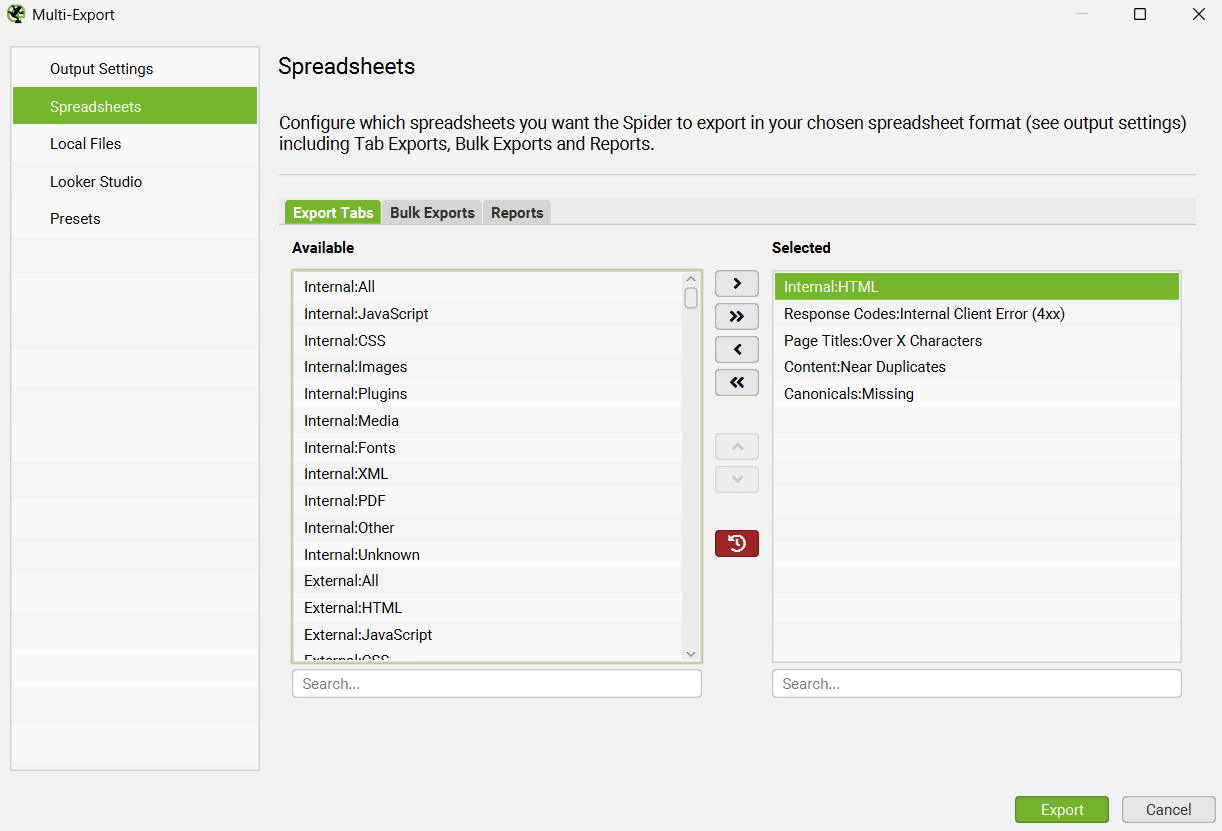
如果有一组常用的报告用于抓取,或者某些网站有特定的导出,则可以将它们保存为预设,并在 UI 中手动或在计划和 CLI 中根据需要使用它们。
此功能还使您可以从手动抓取运行 Looker Studio 导出,而不是仅从计划中运行。
导出格式
当您选择导出时,可以选择要将其保存为的文件“类��型”。这些包括 CSV、Excel 97-2004 工作簿、Excel 工作簿和 Google Sheets。
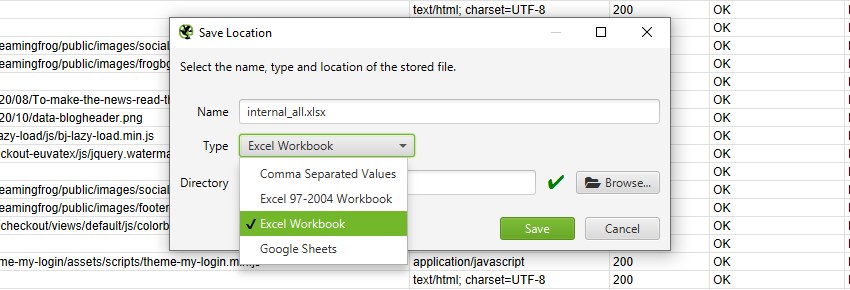
要导出为 CSV、Excel 97-2004 工作簿或 Excel 工作簿,您可以选择类型并简单地单击“保存”。
要首次导出到 Google Sheets,您需要将“类型”选择为 Google Sheets,然后单击“管理”。
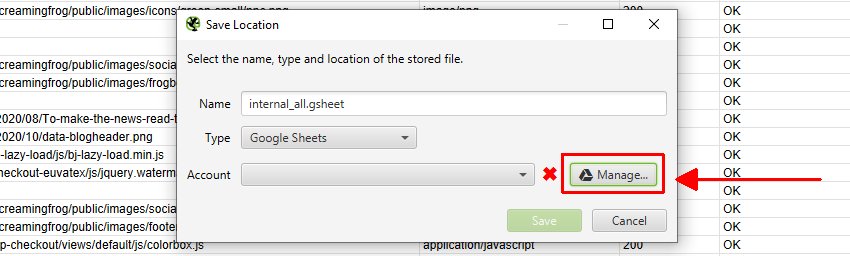
然后,在下一个窗口中单击“添加”以添加您想要导出的 Google 帐户。
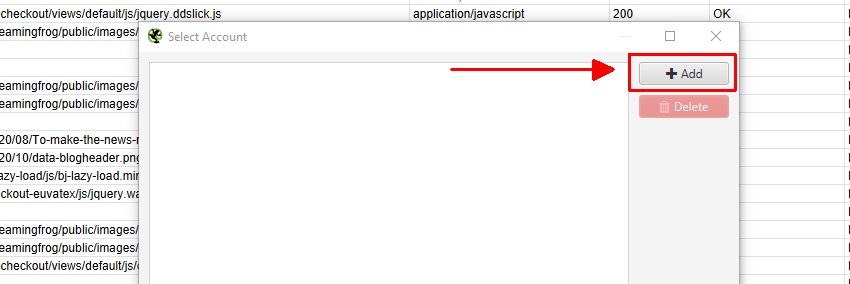
这将打开您的浏览器,您可以在其中选择并登录您的 Google 帐户。您需要单击“允许”两次,然后确认您的选择以“允许”SEO Spider 将数据导出到您的 Google Drive 帐户。
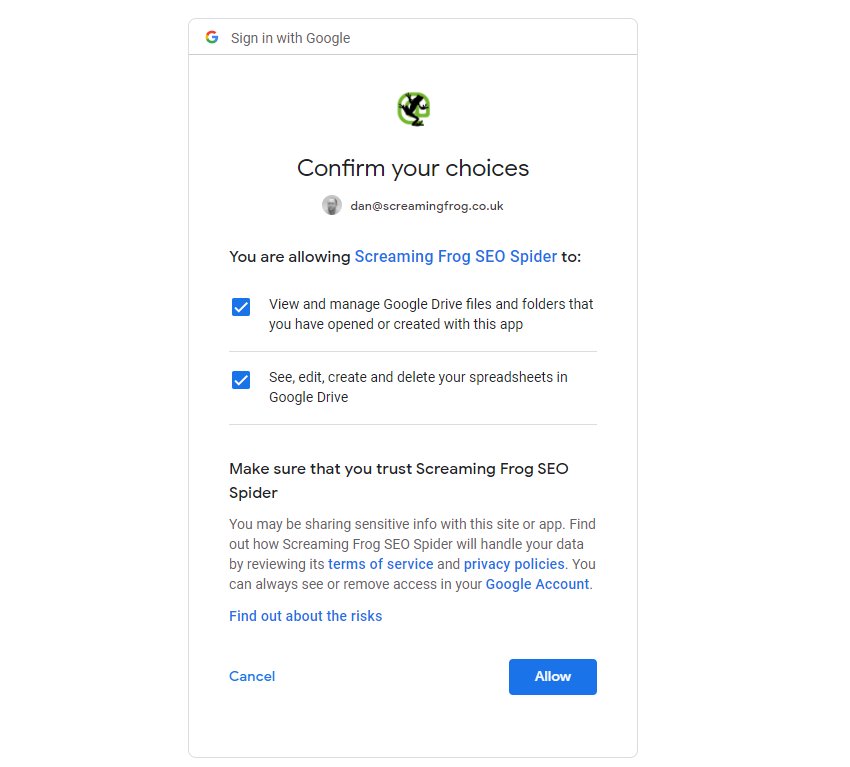
一旦您允许了它,您可以单击“确定”,您的帐户电子邮件现在将显示在“帐户”下,您现在可以选择“保存”。
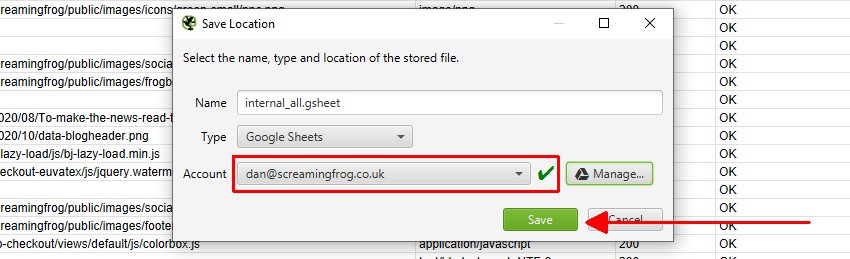
当您保存时,导出的内容将在 Google Sheets 中可用。
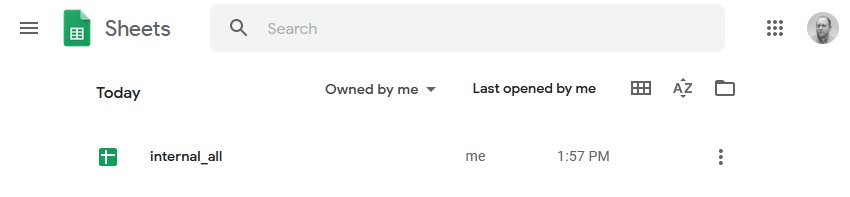
SEO Spider 还将在您的 Google Drive 帐户 中自动创建一个“Screaming Frog SEO Spider”文件夹,其中包含导出的内容。
请注意,Google Sheets 不是为大规模数据构建的,并且有 500 万个单元格的限制。默认情况下,SEO Spider 通常在“内部”选项卡中有大约 55 列,因此在截断之前能够导出大约 9 万行(55 x 90,000 = 4,950,000 个单元格)。
如果您需要导出更多行,请减少导出中的列数,或使用为该大小构建的不同导出格式。我们已经开始编写到多个工作表,但目前不应以这种方式使用 Google Sheets。
Google Sheets 导出也已集成到计划和命令行中。这意味着您可以安排抓取,它会自动将任何选项卡、过滤器、导出或报告导出到 Google Drive 中的工作表。
在计划中使用的“项目名称”和“抓取名称”将用作导出到 Google Drive 的文件夹。因此,例如,“Screaming Frog”项目名称和“每周抓取”名称将位于 Google Drive 中,如下所示。
您还可以选择覆盖现有文件(如果存在),或在 Google Drive ��中创建一个带时间戳的文件夹。
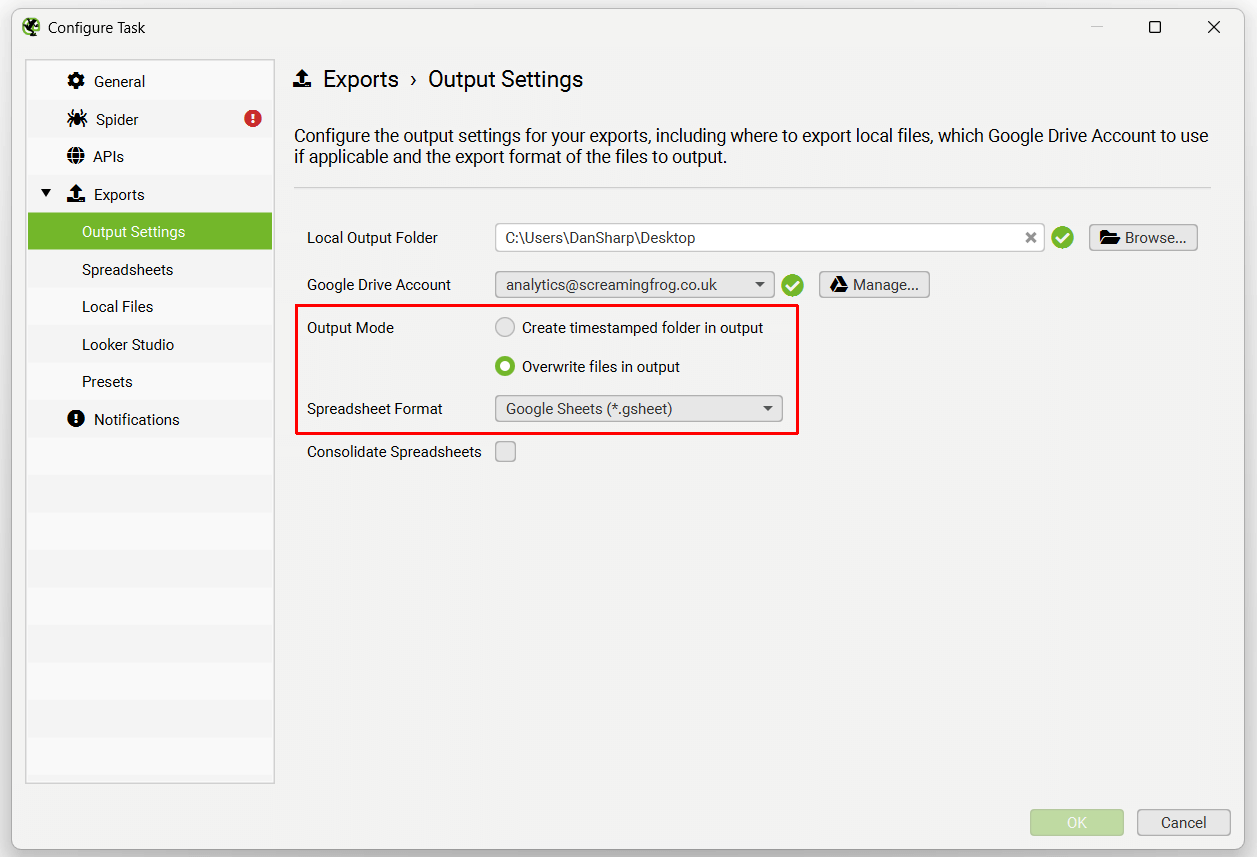
如果您希望导出到 Google Sheets 以连接到 Google Looker Studio,请使用“Looker Studio”选项卡和自定义概览导出。
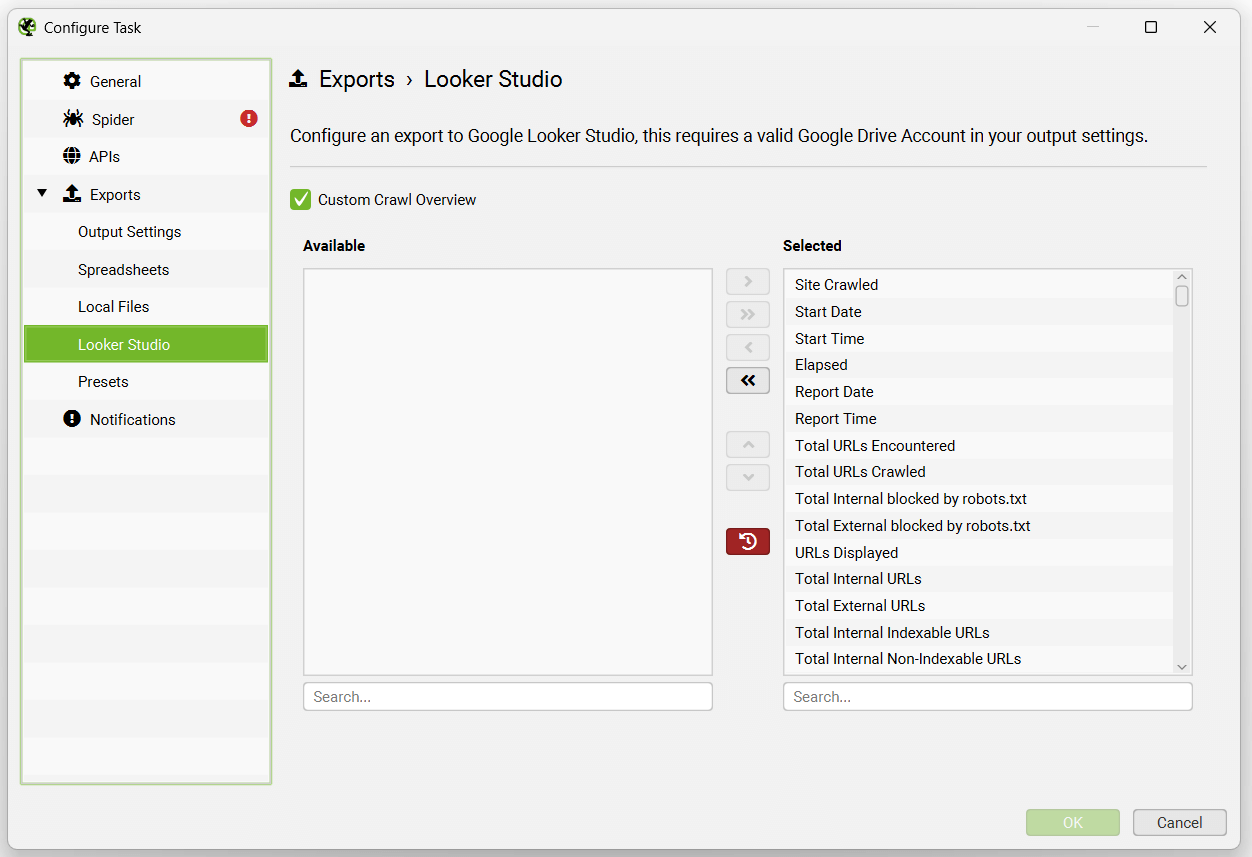
这是专门构建的,允许用户选择抓取概览数据,并将其作为单个摘要行导出到 Google Sheets。它会自动将新的计划导出附加到同一工作表中的新行,形成一个时间序列。请阅读我们的教程“如何在 Data Studio 中自动化抓取报告”,以进行设置。
如果您使用的是数据库存储模式,则无需在计划中“保存”抓取,因为它们会自动存储在 SEO Spider 数据库中。
Robots.txt
Screaming Frog SEO Spider 符合 robots.txt 协议。它以与 Google 相同的方式遵守 robots.txt。
它将检查子域的 robots.txt,并遵循专门针对 Screaming Frog SEO Spider 用户代理(如果不是 Googlebot,则为所有机器人)的指令(允许/禁止)。它目前将默认遵循 Googlebot 的任何指令。因此,如果某些页面或站点区域被禁止 Googlebot 访问,SEO Spider 也不会抓取它们。该工具还支持文件值的 URL 匹配(通配符 * / $),就像 Googlebot 一样。
您可以选择忽略 robots.txt(它甚至不会下载它),在软件的付费(许可)版本中,通过选择“配置 > robots.txt > 忽略 robots.txt”。
您还可以在“响应代码”选项卡和“被 Robots.txt 阻止”过滤器下查看被 robots.txt 阻止的 URL。这还将显示针对每个被阻止的 URL 的禁止的匹配 robots.txt 行。
最后,还有一个自定义 robots.txt配置,允许您在“配置 > robots.txt”的“自定义机器人”部分下下载、编辑和测试站点的 robots.txt。请阅读我们关于使用 Screaming Frog SEO Spider 作为 robots.txt 测试器 的用户指南。
关于 robots.txt,需要记住以下几点:
- SEO Spider 仅遵循一组用户代理指令,如 robots.txt 协议中所述。因此,如果您有任何指令,优先级是 Screaming Frog SEO Spider UA。如果没有,SEO Spider 将遵循 Googlebot UA 的命令,或者最后是“ALL”或全局指令。
- 重申以上内容,如果您为 Screaming Frog SEO Spider 或 Googlebot 指定指令,则 ALL(或“全局”)机器人命令将被忽略。如果您希望遵守全局指令,则必须将这些行包��含在 SEO Spider 或 Googlebot 的特定 UA 部分下。
- 如果您有冲突的指令(即,允许和禁止访问同一文件路径),则如果匹配的允许指令包含的命令中的字符相等或更多,则匹配的允许指令胜过匹配的禁止指令。
- 如果 robots 用户代理留空,SEO Spider 将仅遵守 * 的规则(如果存在)。
User agent
SEO Spider 遵守 robots.txt 协议。它的用户代理是“Screaming Frog SEO Spider”,因此如果您希望阻止它,可以在 robots.txt 中包含以下内容:
User-agent: Screaming Frog SEO Spider
Disallow: /
或者,如果您希望专门为 SEO Spider 排除站点的某些区域,只需使用我们用户代理的常用 robots.txt 语法即可。请注意 - 有一个选项可以“忽略 robots.txt”,这完全由用户负责。
内存
总结:如果您遇到内存警告或尝试执行大型抓取,我们建议使用具有 SSD 和数据库存储模式的计算机。对于最多 200 万个 URL 的抓取,请将内存分配调整为 4GB。
概述
Screaming Frog SEO Spider 使用可配置的混合存储引擎,这使其能够抓取数百万个 URL。但是,它确实需要推荐的硬件和正确的配置。
SEO Spider 中的两个主要配置是:
- 存储模式 - SEO Spider 中有两种存储模式,数据库存储模式和内存存储模式。
- 内存分配 - 您可以调整 SEO Spider 能够使用的最大内存,这使其能够抓取更多 URL。
默认情况下,SEO Spider 将以数据库存储模式启动,仅分配 2GB 的 RAM。它将使用您的硬盘来存储和处理数据。
这允许 SEO Spider 抓取比内存存储模式更多的 URL,还可以自动保存抓取,并允许更快地打开已保存的抓取。一些旧版用户可能仍在使用较旧的内存存储模式。
请继续阅读以获取更多详细信息。
数据库存储模式
可以将 SEO Spider 配置为将抓取数据保存到磁盘,这使其能够抓取数百万个 URL。抓取也会在数据库存储模式下自动保存,并通过“文件 > 抓取”菜单更快地打开。
我们建议将数据库存储模式作为所有具有固态硬盘 (SSD) 的用户的默认存储配置,因为硬盘驱动器在写入和读取数据时要慢得多。
这是默认模式,但一些旧版用户可能正在使用较旧的内存存储模式。可以通过选择数据库存储模式(在 Windows 或 Linux 上的“文件 > 设置 > 存储模式”下,以及在 macOS 上的“Screaming Frog SEO Spider > 设置 > 存储模式”下)来配置它。
作为粗略的指导,在数据库存储模式下分配 SSD 和 4gb 的 RAM 应允许 SEO Spider 抓取大约 200 万个 URL。
我们建议将此配置作为大多数用户日常使用的默认设置。可以通过在 Windows 或 Linux 上选择“文件 > 设置 > 内存分配”,以及在 macOS 上选择“Screaming Frog SEO Spider > 设置 > 内存分配”来在工具中分配内存
内存存储模式
内存存储模式将抓取数据存储在 RAM 中,而不是存储到磁盘。建议在没有 SSD 或磁盘空间不足的旧机器上使用此模式。
在内存存储模式下,没有可以抓取的页面的固定数量,这取决于站点的复杂性和用户的机器规格。SEO Spider 为 64 位机器设置了 2gb 的最大内存,这使其能够抓取站点的大约 10k-100k 个 URL。
您可以增加 SEO Spider 的内存分配,并仅使用 RAM 抓取数十万个 URL。如果增加了内存分配,具有 8gb RAM 的 64 位机器通常允许您抓取数十万个 URL。
高内存使用率
如果您达到设置的内存限制,您将收到“高内存使用率”警告消息 -
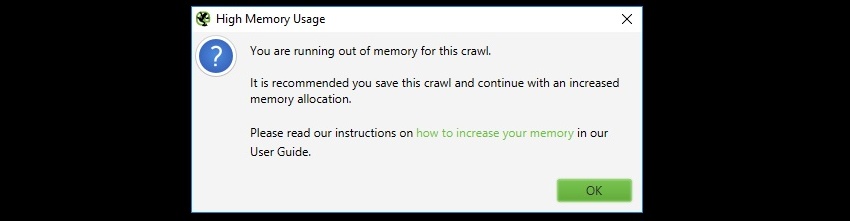
或者,如果您在大型抓取中遇到抓取或应用程序速度减慢的情况,这可能是由于达到了内存分配。
这会警告您 SEO Spider 已达到当前内存分配,并且为了能够抓取更多 URL,有两个选项。
- 切换到数据库存储模式 - 如果您尚未在使用数据库存储模式,那么这是我们推荐的第一步。数据库存储模式将所有抓取数据保存到磁盘,并允许您以相同的内存分配抓取更多 URL。
- 增加内存分配 - 仅当您无法移动到数据库存储模式,或者如果您已在数据库存储模式下达到内存分配时,我们才建议增加内存分配。这会增加可以保存在 RAM 中的数据量,从而允许您抓取更多 URL。
这些选项也可以组合使用以提高性能。
切换到数据库存储
如上所述,旧版用户可以切换到数据库存储模式以增加可以抓取的 URL 数量。
我们建议为此存储模式使用 SSD,并且可以通过 Windows 或 Linux 上的“文件 > 设置 > 存储模式”,以及 macOS 上的“Screaming Frog SEO Spider > 设置 > 存储模式”在应用程序中快速配置它。
我们建议将其作为具有 SSD 的用户的默认存储,并用于大规模抓取。数据库存储模式允许为给定的内存设置抓取更多 URL,对于具有 SSD 的设置,其抓取速度接近 RAM 存储。
默认抓取限制为 500 万个 URL,但这不是硬性限制 - SEO Spider 能够抓取更多(使用正确的设置)。对于低于 200 万个 URL 的抓取,我们建议数据库存储并仅分配 4gb 的 RAM。
我们不建议在数据库存储模式下使用常规硬盘驱动器 (HDD),因为硬盘驱动器的写入和读取速度太慢,并且会成为抓取中的瓶颈。
要从内存存储模式导入抓取,请阅读我们关于保存、打开、导出和导入抓取的指南。
增加内存分配
您可以通过在 Windows 或 Linux 上选择“文件 > 设置 > 内存分配”,以及在 macOS 上选择“Screaming Frog SEO Spider > 设置 > 内存分配”来在应用程序中设置内存分配。
这将允许 SEO Spider 抓取更多 URL,即使在数据库存储模式下也是如此。
SEO Spider 将传达您系统上安装的物理内存,并允许您快速配置它。我们建议为您的系统至少允许 2-4gb 的可用 RAM。例如,如果您有 8gb 的 RAM,我们建议最多分配 4-6gb 的 RAM。
对于最多 200 万个 URL 的抓取,我们建议分配 4GB 的 RAM。
请记住重新启动应用程序以使更改生效。您可以通过此处的指南验证您的设置是否已生效。
要打开已保存的抓取,请阅读我们关于保存、打开、导出和导入抓取的指南。
检查内存分配
更新内存设置后,您可以通过转到“帮助 > 调试”并查看“内存”行来验证更改是否已生效。
SEO Spider 默认分配 2gb 的 RAM,因此该行将如下所示:
内存:物理内存=16.0GB,已用=170MB,可用=85MB,总计=256MB,最大=2048MB,使用率8%
最大值通常会略小于分配的量。分配 4GB 看起来会是这样:
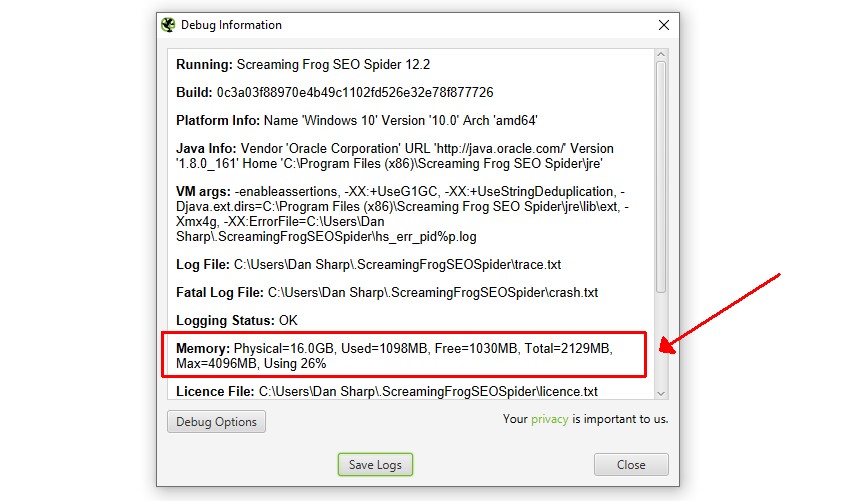
在这种情况下,“Max=4096MB”表示已正确分配 4GB 的 RAM。
请注意,此处显示的数据并不完全准确,因为 VM 开销因操作系统和 Java 版本而异。
故障排除
- 检查 C:\Program Files (x86)\Screaming Frog SEO Spider\ScreamingFrogSEOSpider.l4j.ini 中是否有多余的 -Xmx 行。
- 如果更改内存设置对此输出没有影响,请检查是否设置了 _JAVA_OPTS 环境变量。
Cookies
Google 在无状态的情况下抓取网络,不使用 cookies,但在页面加载期间会接受它们。有些网站只有在接受 cookies 的情况下才能查看,如果禁用接受 cookies 则会失败。
默认情况下,SEO Spider 将仅为“会话”接受 cookies。这意味着它们在页面加载时被接受�,然后被清除,并且不会像 Googlebot 那样用于其他请求。
Cookie 存储可以在“配置 > 爬取 > 高级”下进行调整,从默认的“仅会话”调整为“持久”或“不存储”。
XML 站点地图创建
Screaming Frog SEO Spider 允许您创建 XML 站点地图或特定的图片 XML 站点地图,位于顶部导航栏的“站点地图”下。

“XML 站点地图”功能允许您创建一个 XML 站点地图,其中包含爬取中发现的所有 HTML 200 响应页面,以及 PDF 和图片。“图片站点地图”与“XML 站点地图”选项和包含“图片”略有不同。此选项包括所有具有 200 响应的图片,并且仅包括包含图片的页面。
如果您有超过 49,999 个 URL,SEO Spider 将自动创建其他站点地图文件,并创建一个引用站点地图位置的站点地图索引文件。SEO Spider 符合 sitemaps.org 协议中概述的标准。
阅读我们关于如何使用 SEO Spider 作为 XML 站点地图生成器的详细教程,或继续阅读以下关于每个 XML 站点地图配置选项的快速概述。
调整要包��含的页面
默认情况下,只有来自爬取的具有“200”响应的 HTML 页面才会包含在站点地图中,因此不包括 3XX、4XX 或 5XX 响应。默认情况下,不包含“noindex”、“规范化”(规范 URL 与页面的 URL 不同)、分页(带有 rel=“prev”的 URL)或 PDF 的页面,但可以在 XML 站点地图“页面”配置中进行调整。
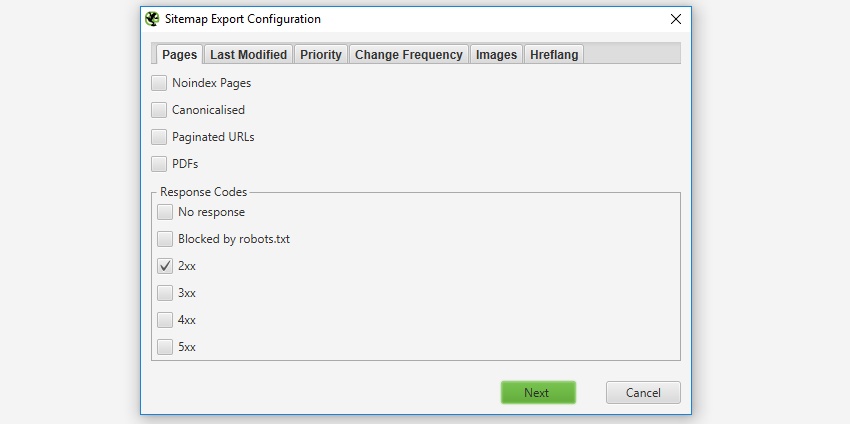
如果您爬取了不想包含在 XML 站点地图导出中的 URL,只需在用户界面中突出显示它们,右键单击并在创建 XML 站点地图之前“删除”它们。或者,您可以将“内部”选项卡导出到 Excel,过滤并删除任何不需要的 URL,然后在 列表模式下重新上传该文件,然后再导出站点地图。或者,只需在爬取之前通过 排除 功能或 robots.txt 阻止它们。
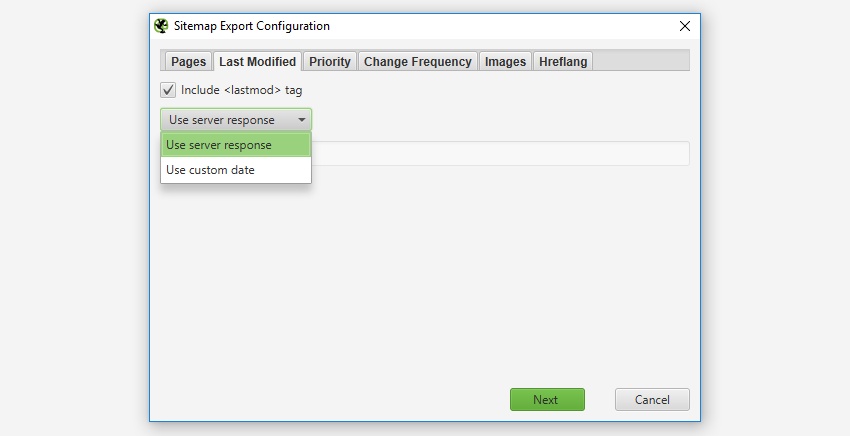
上次修改时间
在 XML 站点地图中是否包含“lastmod”属性是可选的,因此在 SEO Spider 中也是可选的。此配置允许您使用服务器响应或所有 URL 的自定义日期。
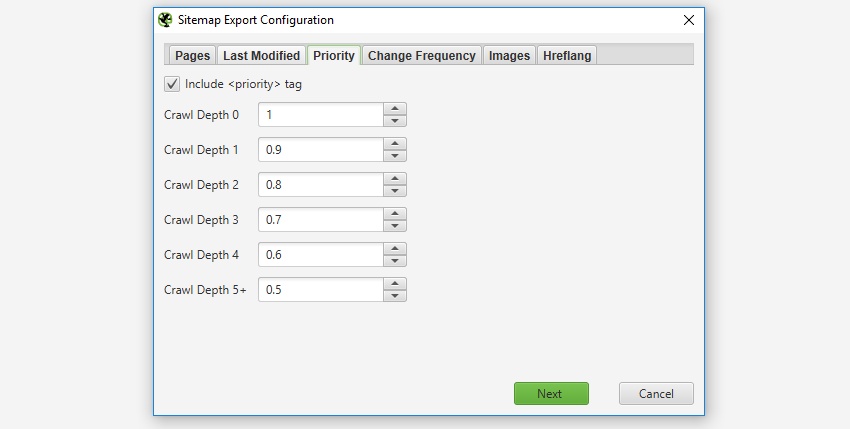
优先级
“优先级”是一个可选属性,可以包含在 XML 站点地图中。如果您不想设置 URL 的优先级,可以“取消选中”“包含优先级标签”框。
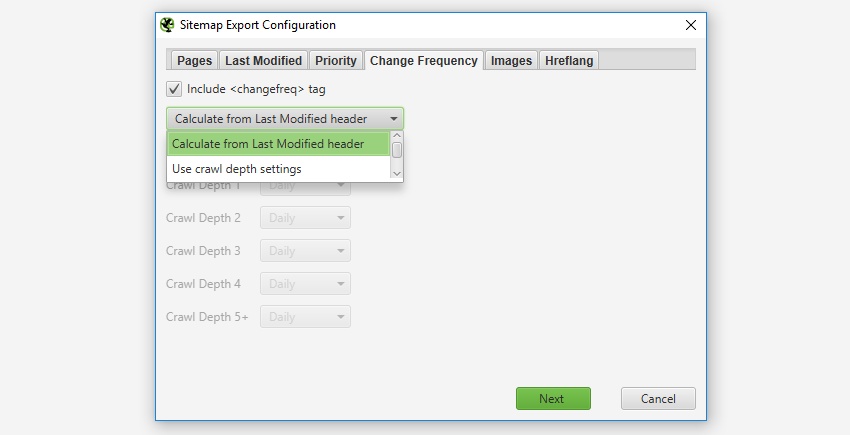
更改频率
是否包含“changefreq”属性是可选的,SEO Spider 允许您根据 URL 的“上次修改标头”或“级别”(深度)来配置这些属性。“从上次修改标头计算”选项意味着如果页面在过去 24 小时内已更改,则将其设置为“每天”,否则将其设置为“每月”。
图片
在 XML 站点地图中是否包含图片完全是可选的。如果选中“包含图片”选项,则默认情况下将包含“内部”选项卡(和“图片”下)下的所有图片。如下面的屏幕截图所示,您还可以选择包含位于 CDN 上并 显示在“外部”选项卡下的图片。
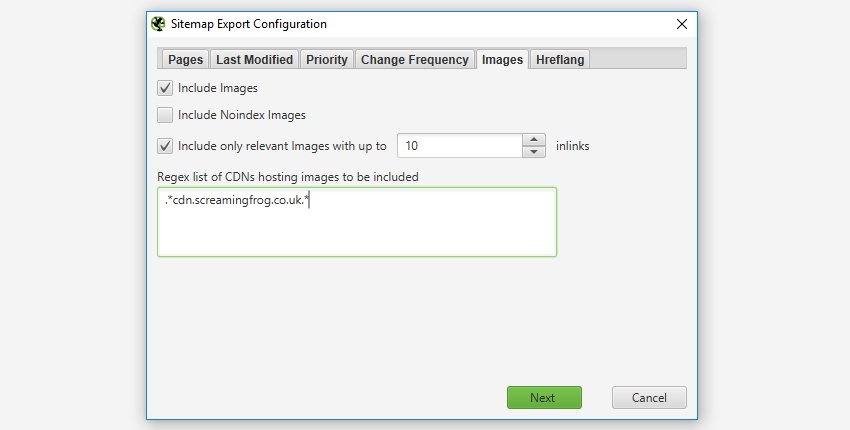
通常,像徽标或社交个人资料图标之类的图片不包含在图片站点地图中,因此您还可以选择仅包含具有一定数量的源属性引用的图片,以帮助排除这些图片。通常,像徽标之类的图片会链接到整个站点,而例如产品页面上的图片可能只会链接一次或两次。“图片”选项卡中有一个 IMG 内部链接列,显示图片被引用的次数,以帮助确定可能适合包含的“内部链接”的数量。
可视化
SEO Spider 的顶级菜单中有三种主要类型的可视化:爬取可视化、目录树可视化和 词云。
爬取可视化对于查看内部链接很有用,而目录树可视化对于理解 URL 结构和组织更有用。词云允许您可视化某个词在链接到特定页面或在特定页面的文本中使用了多少。
通过“可视化”顶级菜单,可以使用力导向图、3D 力导向图和树形图版本的爬取和目录树可视化。
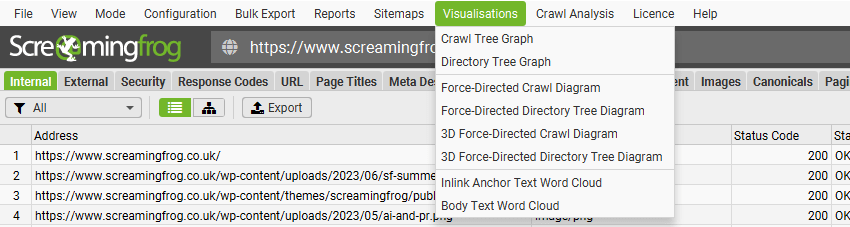
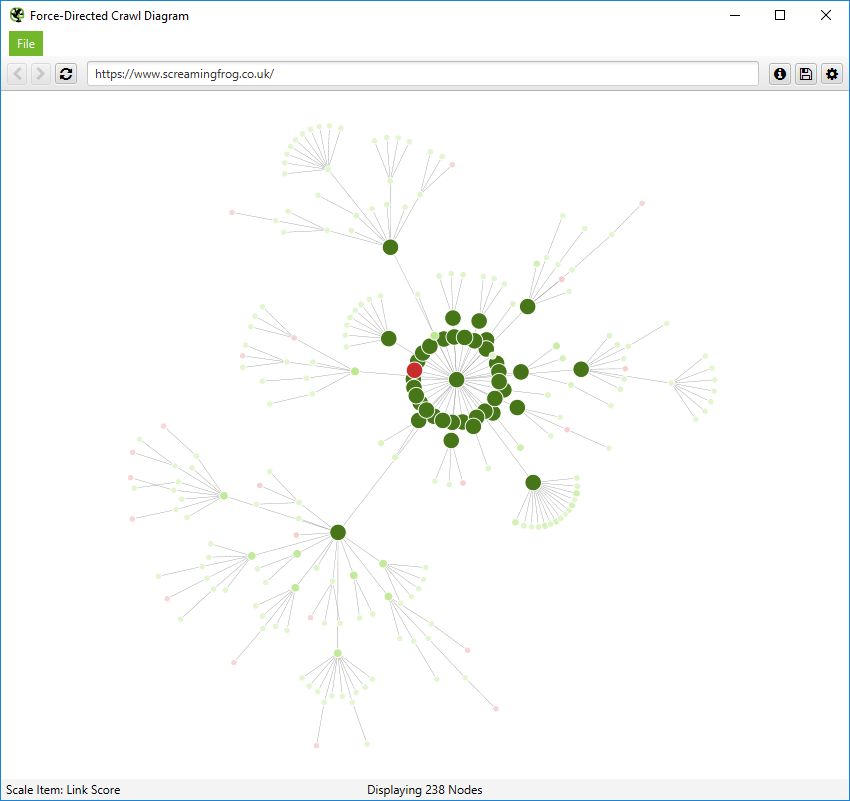
爬取可视化
爬取可视化包括“力导向爬取图”、“3D 力导向爬取图”和“爬取树形图”。
这些爬取可视化对于分析内部链接很有用,因为它们提供了 SEO Spider 如何通过指向页面的第一个链接来爬取站点的视图。如果存在指向页面的多个最短路径(即,从两个爬取深度相同的 URL 链接到某个 URL),则使用第一个爬取的 URL(通常是源中的第一个)。
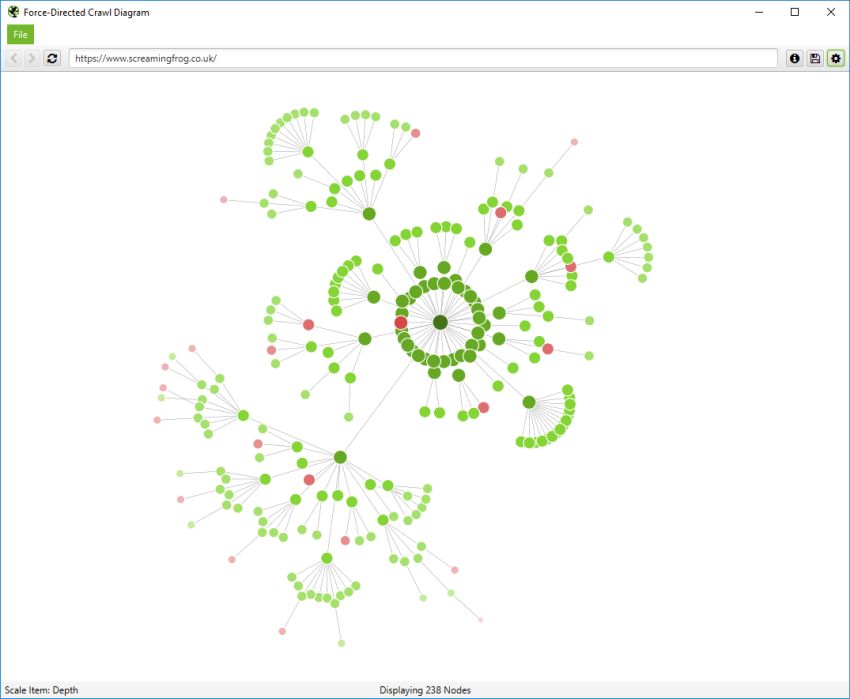
如果您单击可视化右上角的“i”符号,它会解释每种颜色代表什么。
可索引页面由绿色节点表示,中间最暗、最大的圆圈是起始 URL(主页),围绕它的是下一个深度级别,并且随着爬取深度的增加,它们会越来越远、越来越小、越来越亮(就像热图一样)。
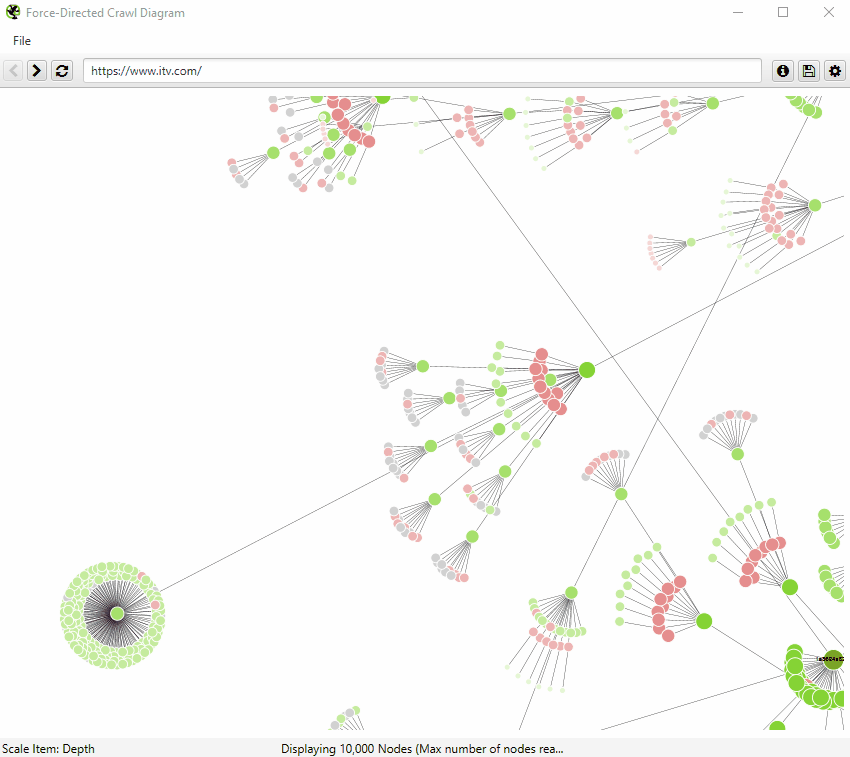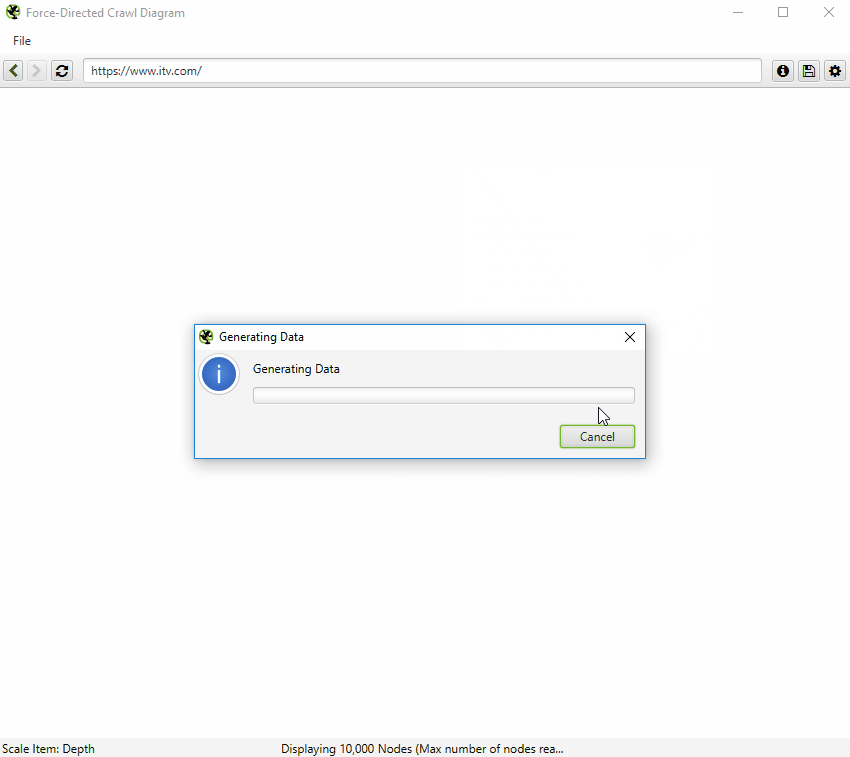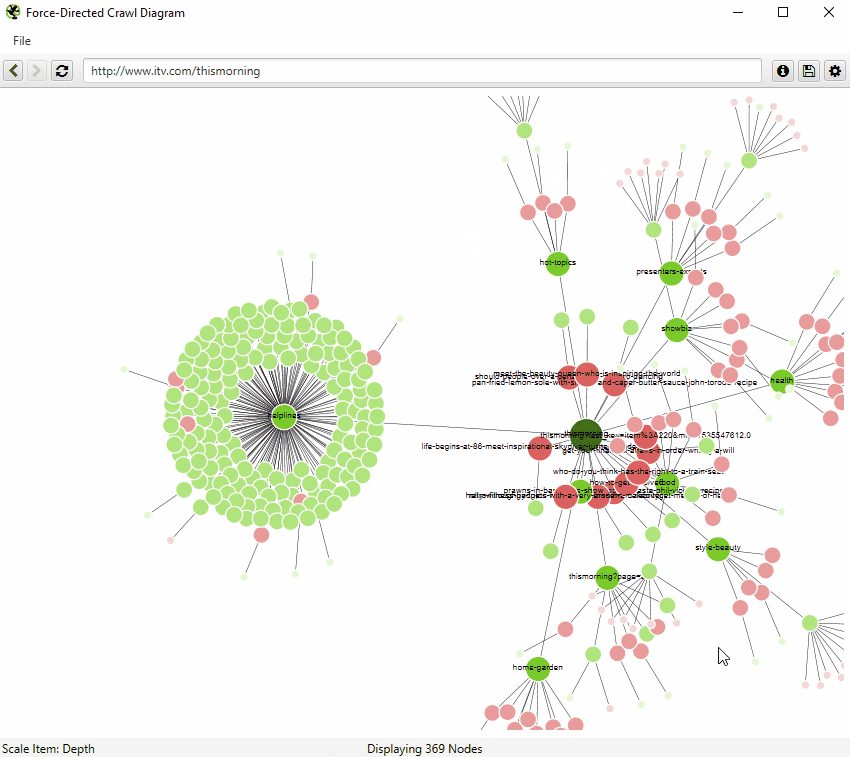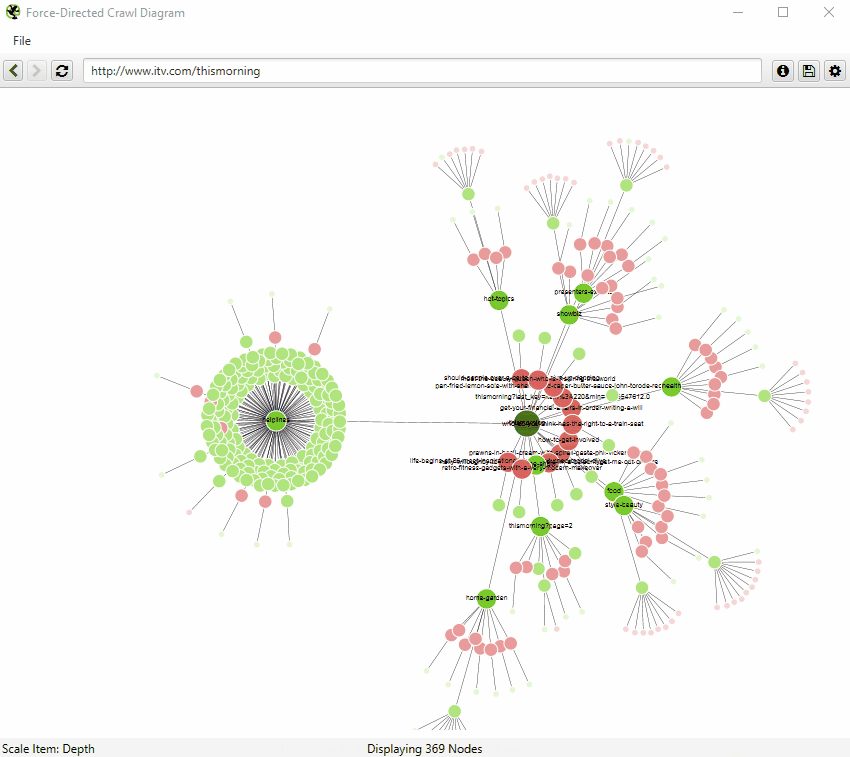
淡红色突出显示了不可索引的 URL,这使得很容易发现网站的问题区域。不可索引页面有其有效的原因,但可视化它们的比例和位置可以帮助快速识别需要进一步调查的感兴趣区域。
可视化一次最多显示 10k 个 URL,因为它们非常占用内存。但是,您可以从任何 URL 查看,以从该点查看。
您还可以右键单击并“聚焦”以扩展站点的特定区域,以显示该部分中的更多 URL(一次最多 10k 个 URL)。您可以使用浏览器作为导航,直接键入 URL,然后向前和向后移动。
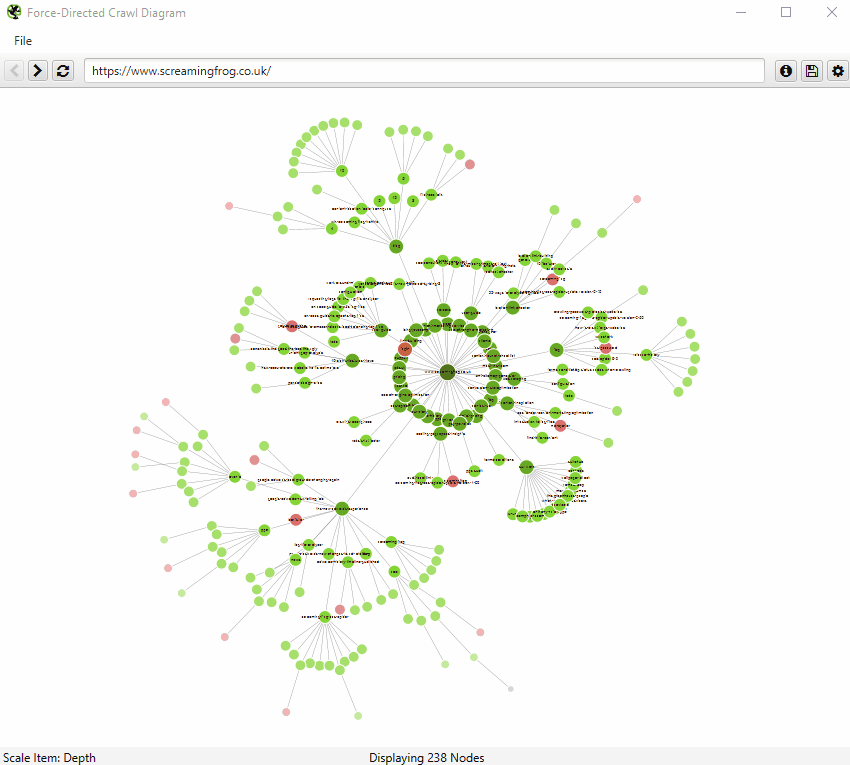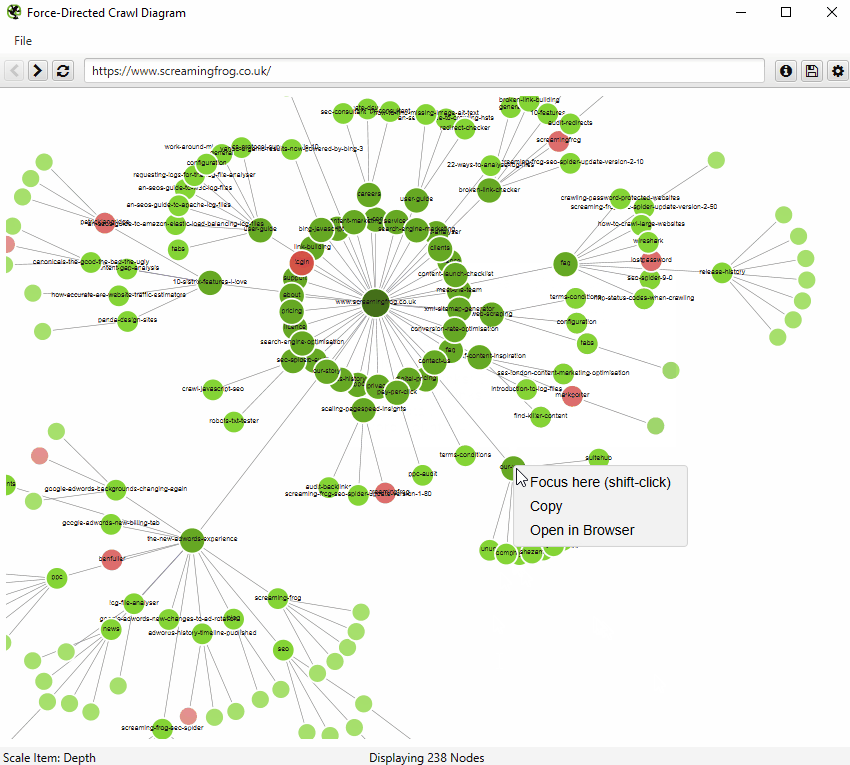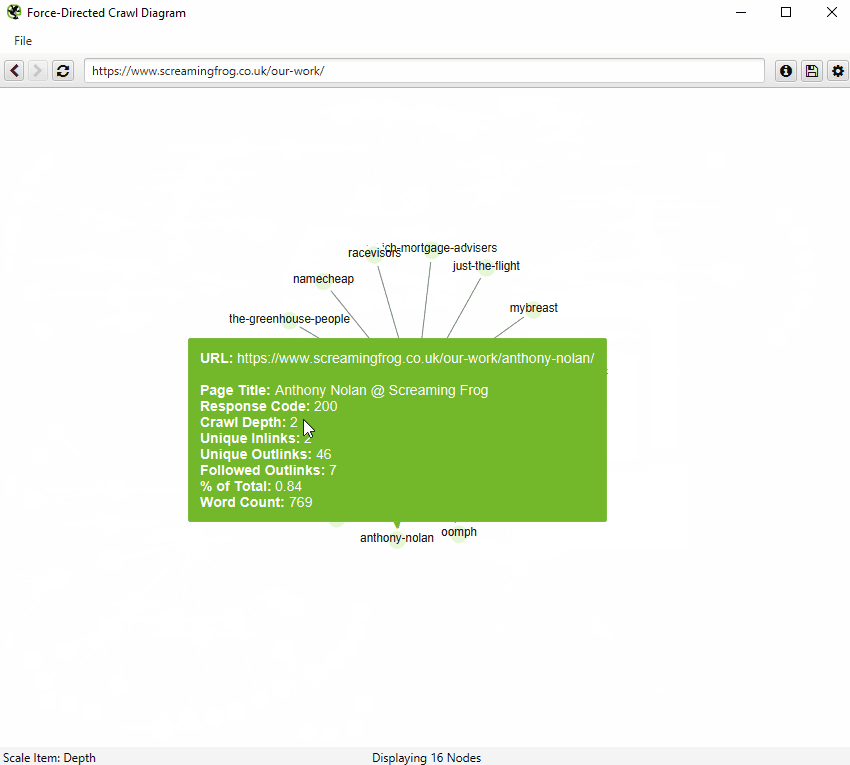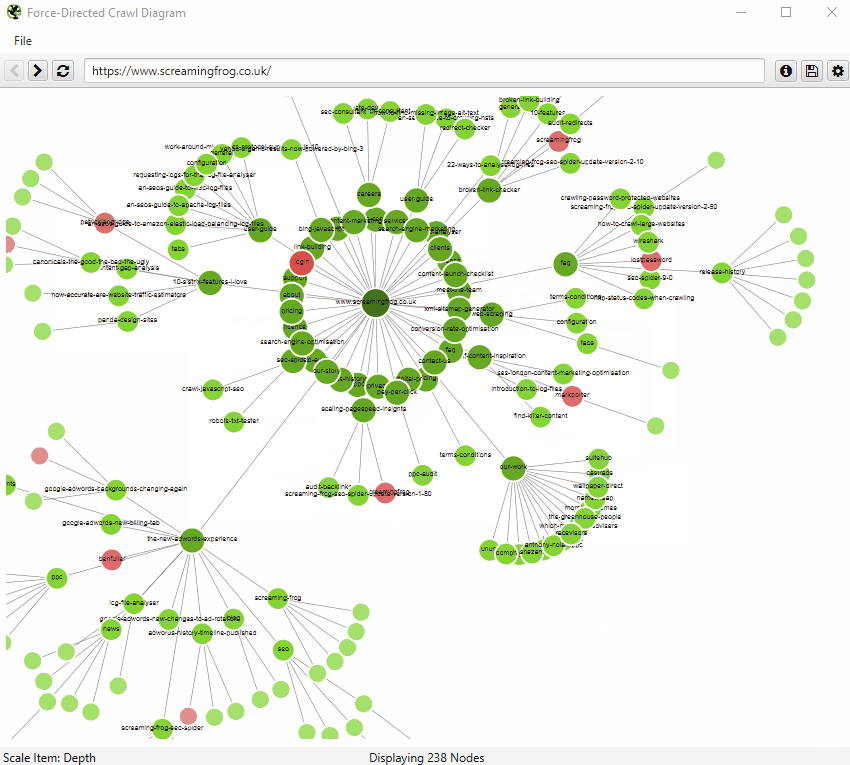
您还可以直接在浏览器中键入 URL,或右键单击爬取中的任何 URL,并从该点打开可视化,作为可视化 URL 资源管理器。
当可视化达到 10k URL 限制时,它会通过将节点着色为灰色来告知��您特定节点是否具有被截断的子节点(由于大小限制)。然后,您可以右键单击并“浏览”以查看子节点。这样,就可以可视化爬取中的每个 URL。
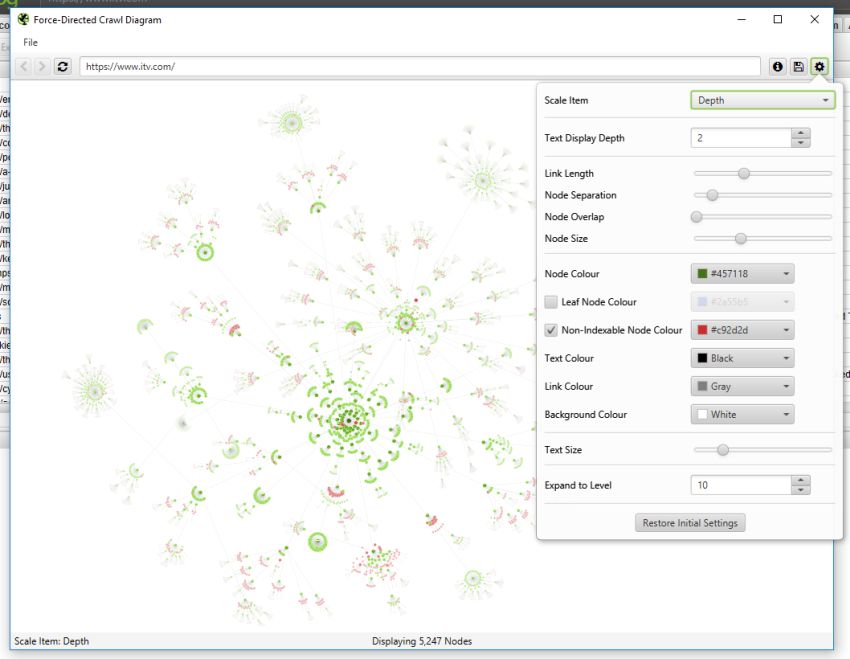
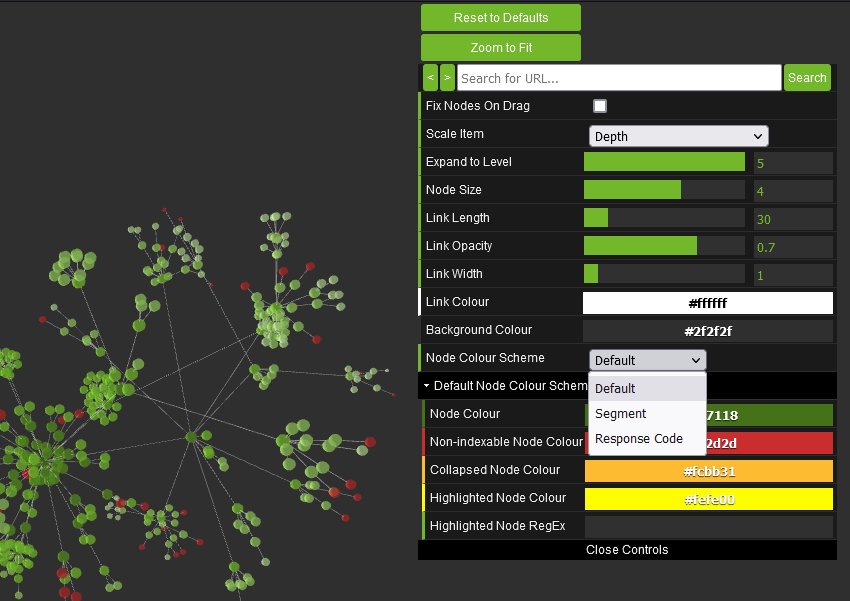
您还可以配置节点的大小、重叠、分离、颜色、链接长度以及何时显示文本。
因此,您可以生成如下所示的彩色可视化。

您还可以按其他指标缩放可视化,以提供更深入的了解,例如唯一内部链接、字数、GA 会话、GSC 点击、链接得分、Moz 页面权限等。
节点的大小和颜色将根据这些指标进行缩放,这有助于可视化许多不同的内容以及内部链接,例如站点中可能包含单薄内容的区域。
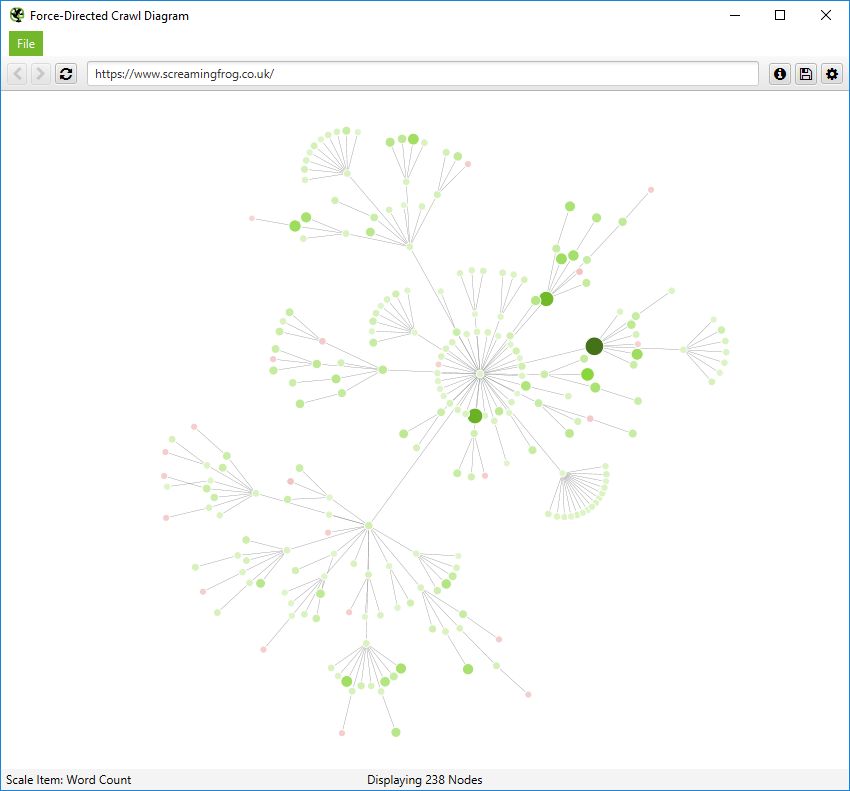
或按链接得分的最高值。
3D 力导向爬取图将在您的默认浏览器中打开,而不是在我们内置的浏览器中打开。
此图最多可以缩放到 100k 个 URL。右键单击功能不可用,但如果需要,仍然可以使用内置浏览器 URL 栏进行导��航。
鼠标左键将旋转,滚轮将缩放,鼠标右键将在 3D 可视化中平移。右侧的配置允许您调整图表或搜索特定 URL,其方式与 2D 图表类似。
您可以调整节点颜色以基于响应代码或分段。
您还可以在更简单的爬取树形图中查看内部链接,该图可以配置为从左到右或从上到下显示。
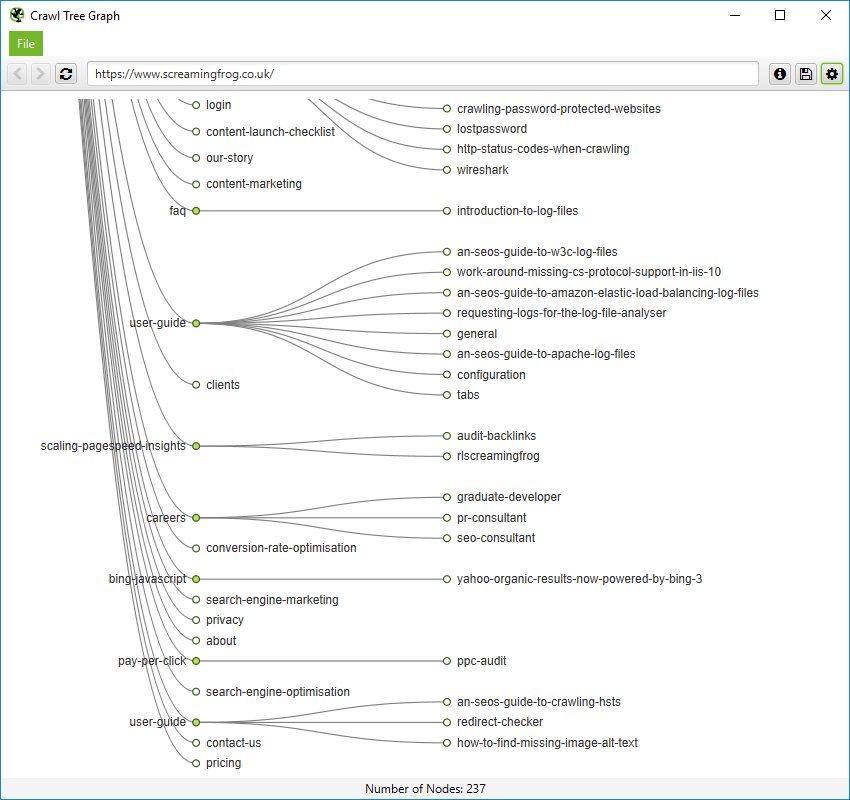
您可以右键单击并“聚焦”站点的特定区域。您还可以展开或折叠到特定的爬取深度,并调整级别和节点间距。
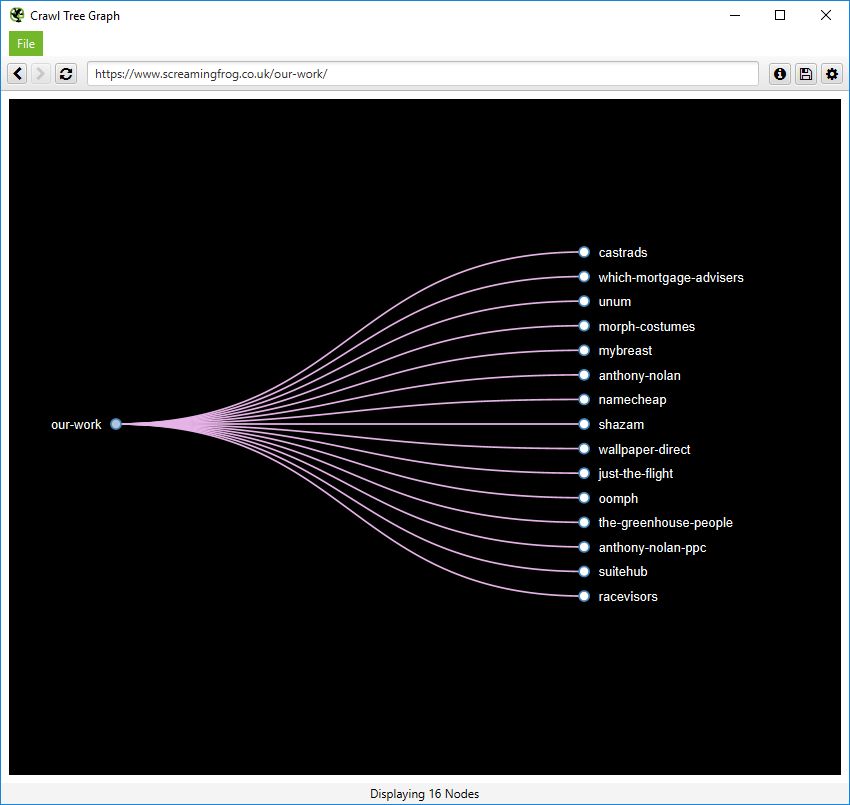
与力导向图一样,所有颜色也可以调整。
目录树可视化
目录树可视化包括“力导向目录树图”、“3D 力导向目录树图”和“目录树图”。
与爬取可视化的内部链接相反,“目录树”视图有助于了解站点的 URL 架构及其 组织方式。这很有用,因为这些分组通常共享相同的页面模板和 SEO 问题。
力导向目录树图是 SEO Spider 独有的(您可以看到它�与我们站点的爬取图非常不同),并且更容易可视化潜在的问题。
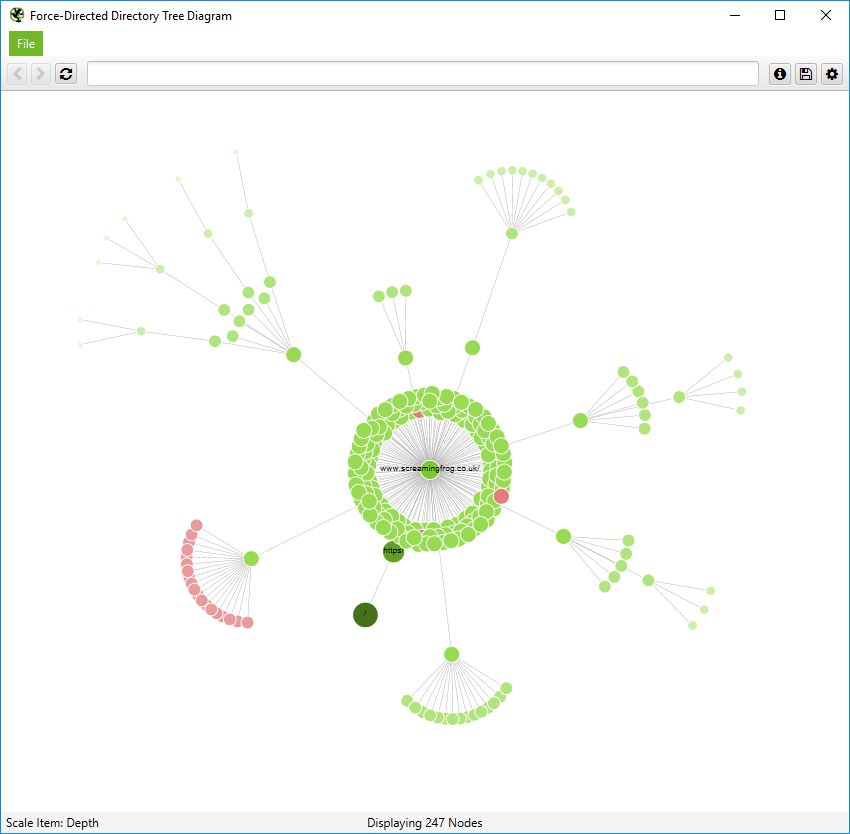
请注意,不可索引的红色节点是如何组织在一起的,因为它们具有相同的模板,而在爬取图中,它们分布在各处。此视图通常使查看模式更容易。
也可以在 3D 力导向目录树图中查看此内容。
或者,也可以使用简单的目录树图格式。这些图是交互式的,这是我们网站某个部分的放大、自上而下的视图。

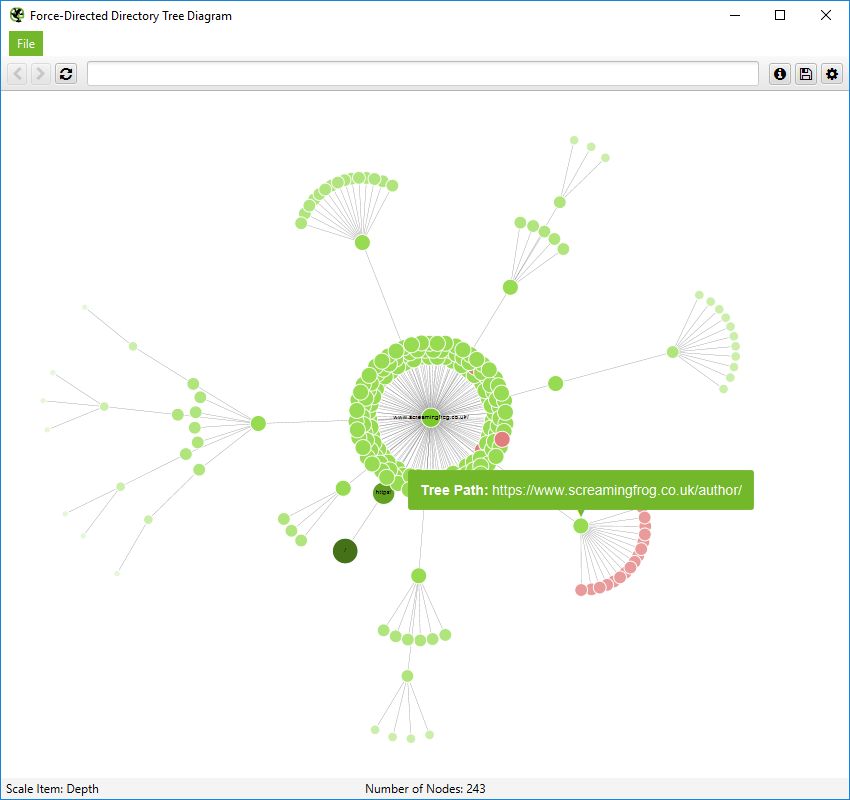
重要的是要记住,在此目录树视图中,节点并不总是代表 URL。它们可能仅仅代表一个路径,该路径不存在作为 URL。一个例子是 Screaming Frog 网站的子文件夹 /author/。它包含子文件夹 (/author/name/) 中的 URL,这些 URL 存在,但 /author/ 路径本身不存在。
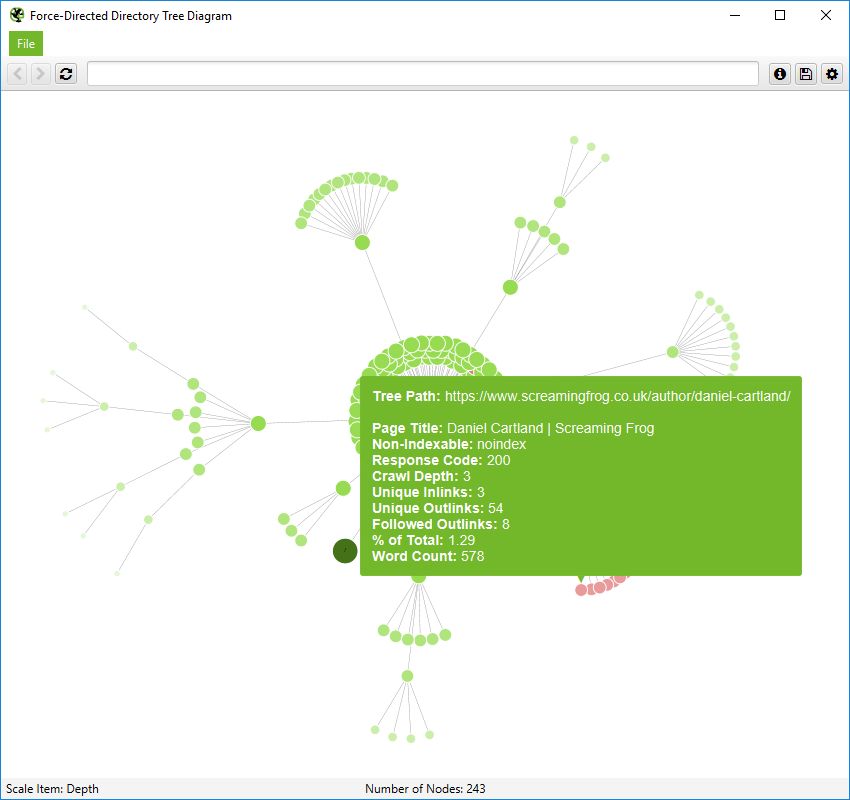
但是,在目录树视图中,仍然会显示此内容以启用分组。但是,当您将鼠标悬停在其上时,只会显示“路径” -
URL 将包含更多信息,如下所示 -
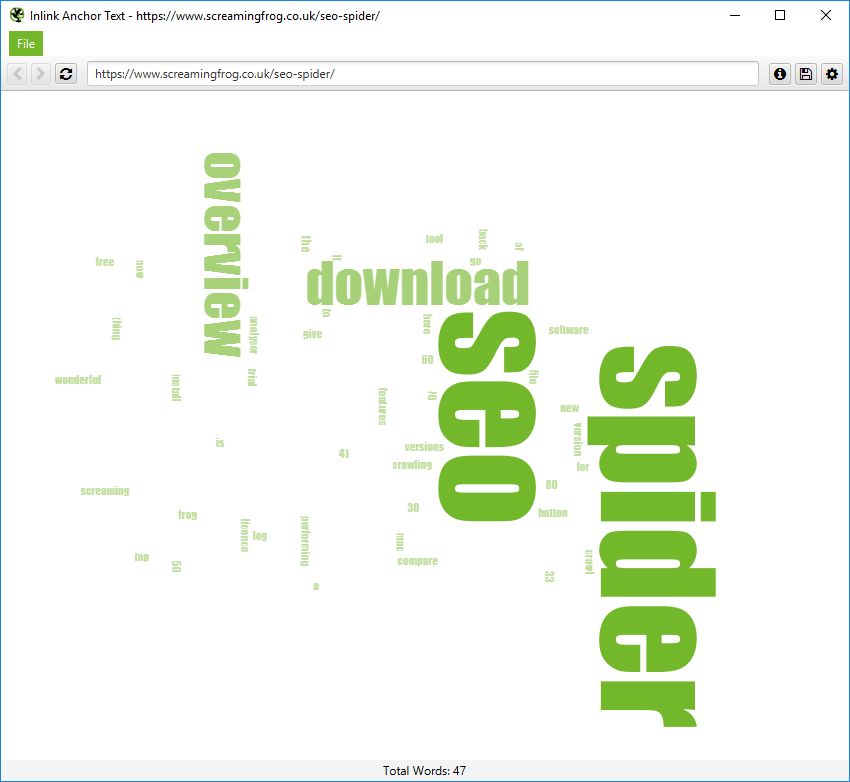
内部链接锚文本和正文文本词云
顶部导航中的选项将显示输入为爬取起点的 URL 的词云。要查看任何页面 URL 的这些词云,请右键单击主窗口中的 URL,然后转到“可视化”。
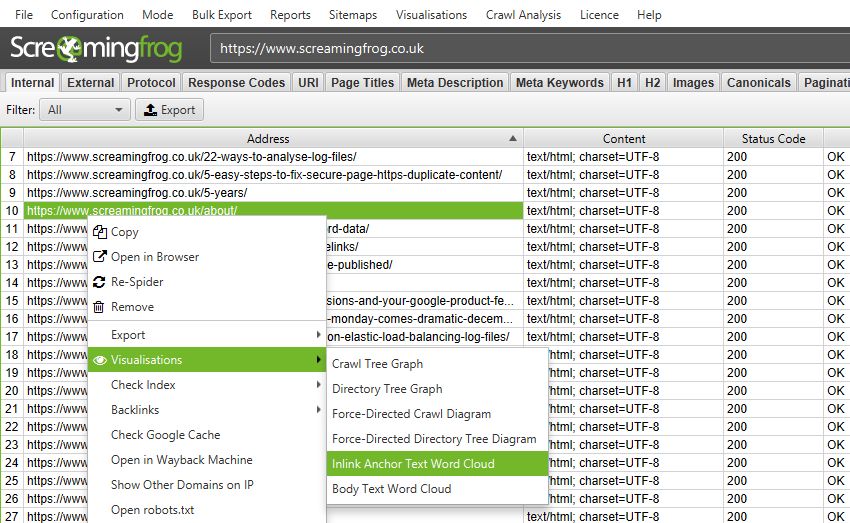
“内部链接锚文本词云”包括指向给定 URL 的所有内部锚文本以及指向页面的超链接图像的图像 alt 文本。
“正文文本词云”包含页面 HTML 正文中的所有文本。要查看此可视化效果,必须启用“存储 HTML”配置。
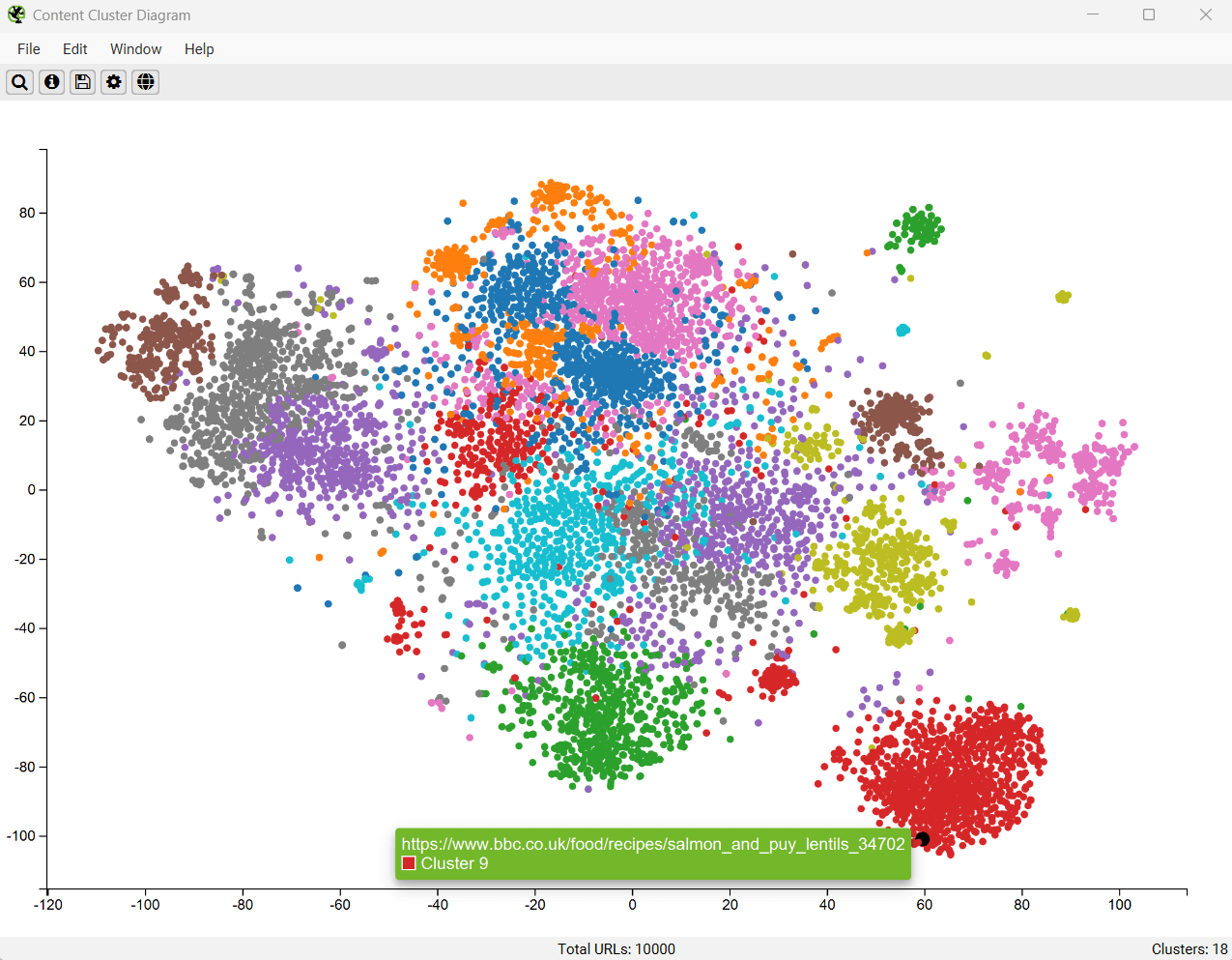
内容聚类图
内容聚类图是对抓取中的 URL 进行二维可视化,这些 URL 通过嵌入数据进行绘制和聚类。请阅读“如何识别语义相似的页面和异常值”以进行设置。
它可以用于识别网站内容中的模式和关系,其中语义相似的内容被聚类在一起。
该图一次最多可以显示 10,000 个页面。节点越靠近,它们在语义上就越相似。
上面的示例图突出了动物网站的语义关系。
老虎种群紧密地聚集在一起,最近的邻居是老虎和狮子之间的狮虎兽杂交种,然后是其他大型猫科动物,如豹、美洲虎和猎豹,以此类推。
这些图可以可视化站点上内容集群的规模,或者识别语义相关的潜在主题集群,但这些集群可能与用户的集成度较低。
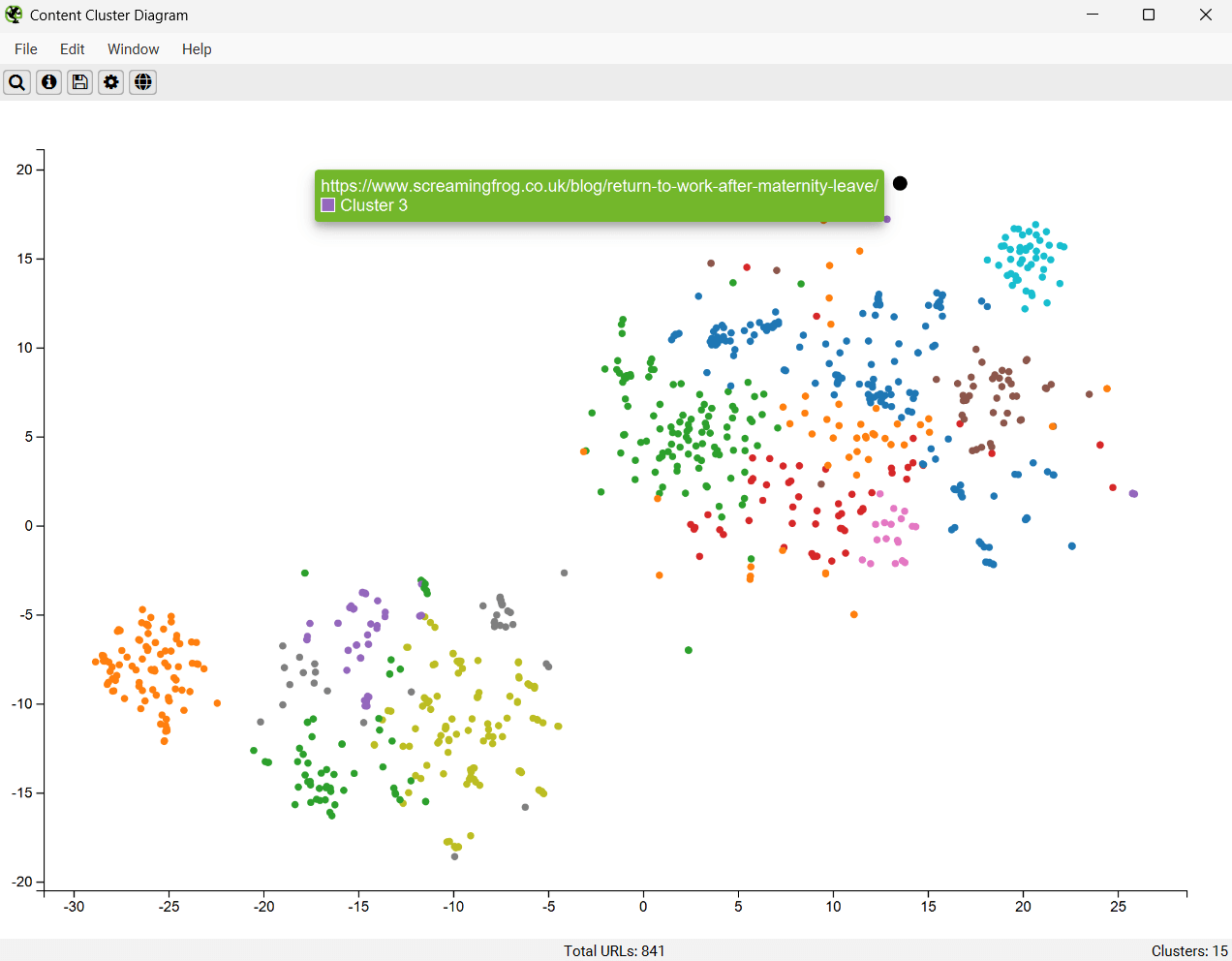
低相关性内容和异常值可以很容易地识别为图边缘上的孤立节点。
齿轮允许您调整采样、降维、集群数量和使用的配色方案。您也可以选择使用“segments”作为聚类节点配色方案。
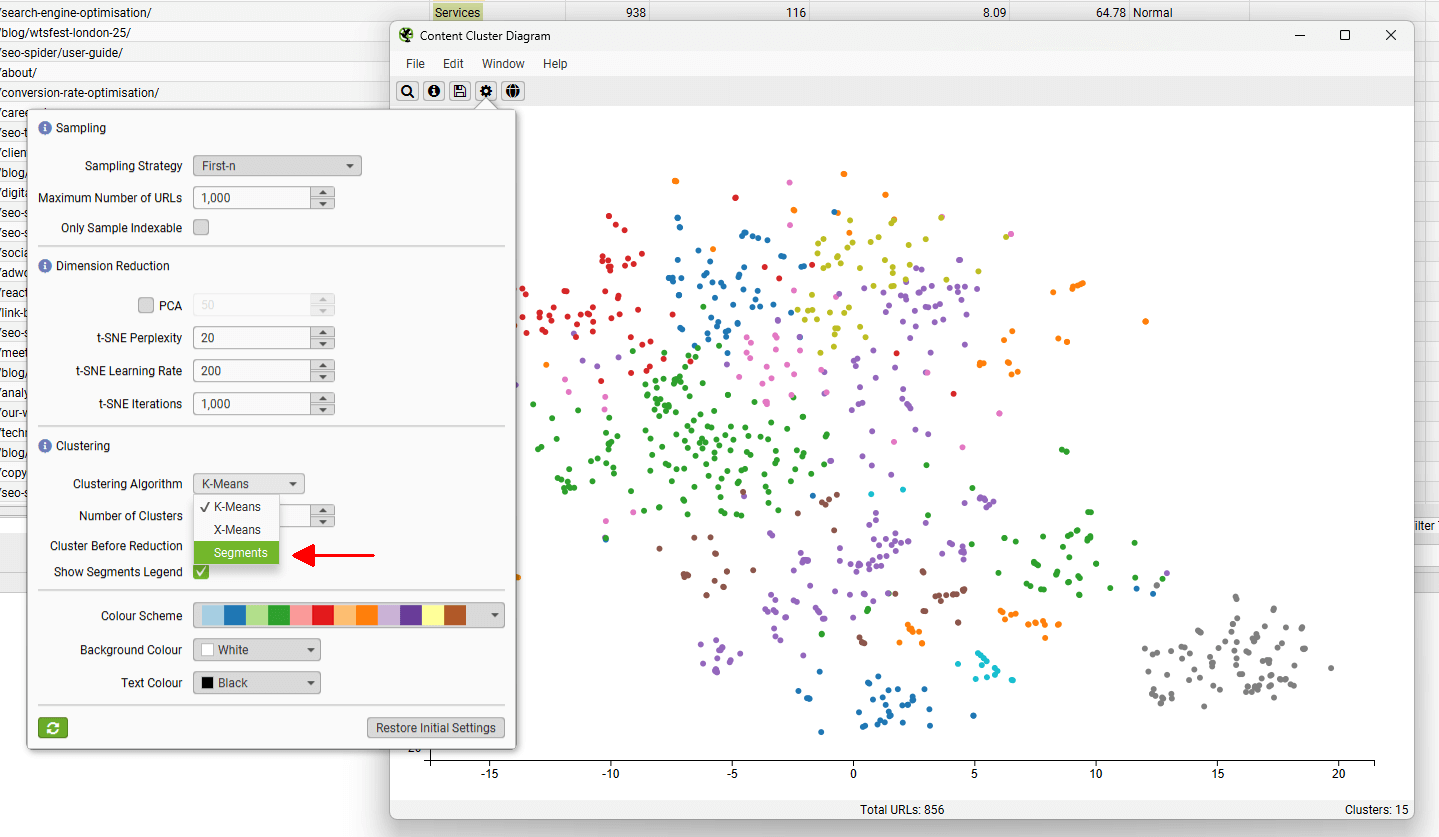
这有助于发现两个语义相似的页面位于不同的分段中,可以考虑相互进行内部链接。
在上面的例子中,涵盖相同主题的两个页面位于网站的不同部分 - 教程 和我们的 问题库,并且应该通过内部链接相互引用。
故障排除
- 当导出为 .svg 时,这将具有导出时的当前视口。没有信息丢失,但您需要使用支持 SVG 的应用程序来调整视图,例如 Adobe Illustrator 或 Inkscape。
报告
可以通过“reports”顶级导航访问各种报告。这些报告包括以下内容。
抓取概览报告
此报告提供抓取摘要,包括遇到的 URL 数量、被 robots.txt 阻止的 URL 数量、抓取的 URL 数量、内容类型、响应代码等数据。它提供了每个选项卡和相应过滤器中数字的顶级摘要。
“total URI description”提供有关每个单独行的“Total URI”列号的信息,以(尝试)避免任何混淆。
所有重定向、重定向链和重定向及规范链报告
这些报告详细说明了在网站上发现的重定向以及发现它们的源 URL。

“所有重定向”报告显示发现的所有��单个重定向和链,“重定向链”报告显示链中具有 2 个或更多重定向的重定向,“重定向和规范链”显示链中任何 2 个或更多重定向或规范。
“重定向链”和“重定向和规范链”报告绘制出重定向和规范链,沿途的跳数,并将识别源,以及是否存在循环。在 Spider 模式(Mode > Spider)下,这些报告将显示所有重定向,从单跳向上。它将在列中传达“重定向数量”和已识别的“链类型”,无论是 HTTP 重定向、JavaScript 重定向、规范等。它还会标记重定向循环。如果报告为空,则表示您没有可以缩短的循环或重定向链。
“重定向”、“重定向链”和“重定向和规范链”报告也可以在列表模式(Mode > List)中使用。它们将为列表中提供的每个 URL 显示一行。通过勾选“始终遵循重定向”和“始终遵循规范”选项,SEO Spider 将继续在列表模式下抓取重定向和规范,并忽略抓取深度,这意味着它将报告所有跳,直到最终目的地。请参阅我们关于在站点迁移中审计重定向的指南。
请注意 - 如果您仅执行部分抓取,或者某些 URL 通过 robots.txt 被阻止,您可能无法收到此报告中 URL 的所有响应代码。
规范报告
“规范链”和“不可索引规范”报告突出显示��了抓取中规范链接元素或 HTTP 规范实施的错误和问题。请阅读如何审计规范以获取我们的分步指南。
“规范链”报告突出显示了链中具有 2 个或更多规范的任何 URL。这是指 URL 具有指向不同位置的规范 URL(并且是“规范化的”),然后该 URL 具有指向另一个 URL 的规范 URL(规范链)。
“不可索引规范”报告突出显示了规范的错误和问题。特别是,此报告将显示任何没有响应、被 robots.txt 阻止、3XX 重定向、4XX 或 5XX 错误的规范(任何非 200“OK”响应)。
此报告还提供有关仅通过规范发现且未从站点链接到的任何 URL 的数据(当“true”时,在“unlinked”列中)。
分页报告
“非 200 分页 URL”和“未链接分页 URL”报告突出显示了 rel=”next” 和 rel=”prev” 属性的错误和问题,这些属性当然用于指示分页内容。请阅读如何审计 rel=”next” 和 rel=”prev” 分页属性以获取我们的分步指南。
“非 200 分页 URL”报告将显示任何没有响应、被 robots.txt 阻止、3XX 重定向、4XX 或 5XX 错误的 rel=”next” 和 rel=”prev” URL(任何非 200“OK”响应)。
“未链接分页 URL”报告提供有关仅通过 rel=”next” 和 rel=”prev” 属性发现且未从站点链接到的任何 URL 的数据(当“true”时,在“unlinked”列中)。
Hreflang 报告
Hreflang 报告与在网站上发现的 hreflang 的实施有关。请阅读如何审计 Hreflang以获取我们的分步指南。
有 7 个 hreflang 报告允许批量导出数据,其中包括以下内容 -
- 所有 Hreflang URL - 这是所有 URL 和 hreflang URL 的 1:1 报告,包括在抓取中发现的区域和语言值。
- 非 200 Hreflang URL - 此报告显示 hreflang 注释中任何非 200 响应的 URL(无响应、被 robots.txt 阻止、3XX、4XX 或 5XX 响应)。
- 未链接 Hreflang URL - 此报告显示未通过站点上的超链接链接到的任何 hreflang URL。
- 缺少确认链接 - 此报告显示缺少确认链接的页面,以及哪个页面未确认。
- 不一致的语言确认链接 - 此报告显示使用与同一页面不同的语言代码的确认页面。
- 非规范确认链接 - 此报告显示指向非规范 URL 的确认链接。
- Noindex 确认链接 - 此报告显示指向 noindex URL 的确认链接。
不安全内容报告
不安全内容报告将显示任何具有不安全元素的安全 (HTTPS) URL,例如内部 HTTP 链接、图像、JS、CSS、SWF 或 CDN 上的外部图像、社交配置文件等。当您将网站从不安全 (HTTP) 迁移到安全 (HTTPS) 时,很难拾取所有不安全元素,这可能会导致浏览器中出现警告 -
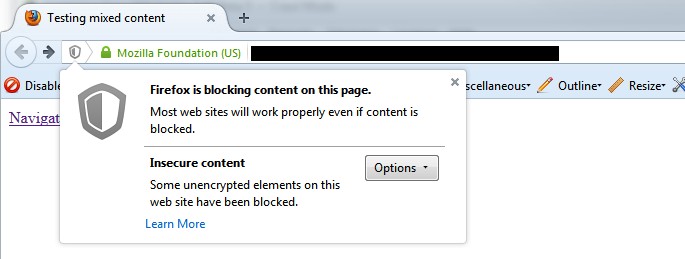
这是一个报告可能看起来如何的快速示例(在本例中为不安全图像) -

SERP 摘要报告
此报告允许您快速导出 URL、页面标题和元描述,以及它们各自的字符长度和像素宽度。
此报告也可以用作模板,以重新上传回 SEO Spider 中的“SERP”模式。
孤立页面报告
孤立页面报告提供从 Google Analytics API、Google Search Console(搜索分析 API)和 XML 站点地图收集的 URL 列表,这些 URL 与在抓取中发现的 URL 不匹配。
除非您已连接到 Google Analytics、Search Console 或配置为抓取 XML 站点地图 并在抓取期间提取数据,否则此报告将为空白。
您也可以直接在 SEO Spider 中查看孤立页面 URL,但这确实需要正确的配置。我们建议阅读我们关于如何查找孤立页面的指南。
孤立页面报告的“source”列准确显示了发现 URL 的来源,但与抓取中的 URL 不匹配。这些包括 -
- GA - 该 URL 是通过 Google Analytics API 发现的。
- GSC - 该 URL 是在 Google Search Console 中通过搜索分析 API 发现的。
- Sitemap - 该 URL 是通过 XML 站点地图发现的。
- GA & GSC & Sitemap - 该 URL 是在 Google Analytics、Google Search Console 和 XML 站点地图中发现的。
此报告可以包括 Google Analytics 为您在 Google Analytics 配置中选择的查询返回的任何 URL。因此,这可以包括登录区域或购物车 URL,因此对于 SEO 而言,最有用的数据通常是通过查询 着陆页路径维度和“自然流量”细分返回的。这可以帮助识别 -
- 孤立页面 - 这些是在网站上没有内部链接,但确实存在的页面。这些可能只是旧页面、在旧�站点迁移中遗漏的页面或仅在外部找到的页面(通过外部链接或引用站点)。此报告允许您浏览列表并查看哪些是相关的,并可能通过列表模式上传。
- 错误 - 该报告可以包括 404 错误,有时还包括 URL 中的引用网站(您将需要这些的“所有流量”细分)。这对于追查网站以更正外部链接,或者只是将错误的 URL 301 重定向到正确的页面非常有用!此报告还可以包括可能被规范化或被 robots.txt 阻止,但实际上仍在索引并传递一些流量的 URL。
- GA 或 GSC URL 匹配问题 - 如果数据与抓取中的 URL 不匹配,您可以检查通过 GA 或 GSC API 返回了哪些 URL。这可能会突出显示特定 Google Analytics 视图的任何问题,例如 URL 上的过滤器,例如“扩展 URL”黑客等。为了使 SEO Spider 返回与抓取中的 URL 相关的数据,URL 需要匹配。因此,更改为“原始”GA 视图(未经任何修改)可能会有所帮助。
结构化数据报告
“验证错误和警告摘要”报告将结构化数据聚合到发现的唯一验证错误和警告(而不是报告每个实例),并显示受每个问题影响的 URL 数量,以及具有特定问题的示例 URL。可以在下面看到示例报告。
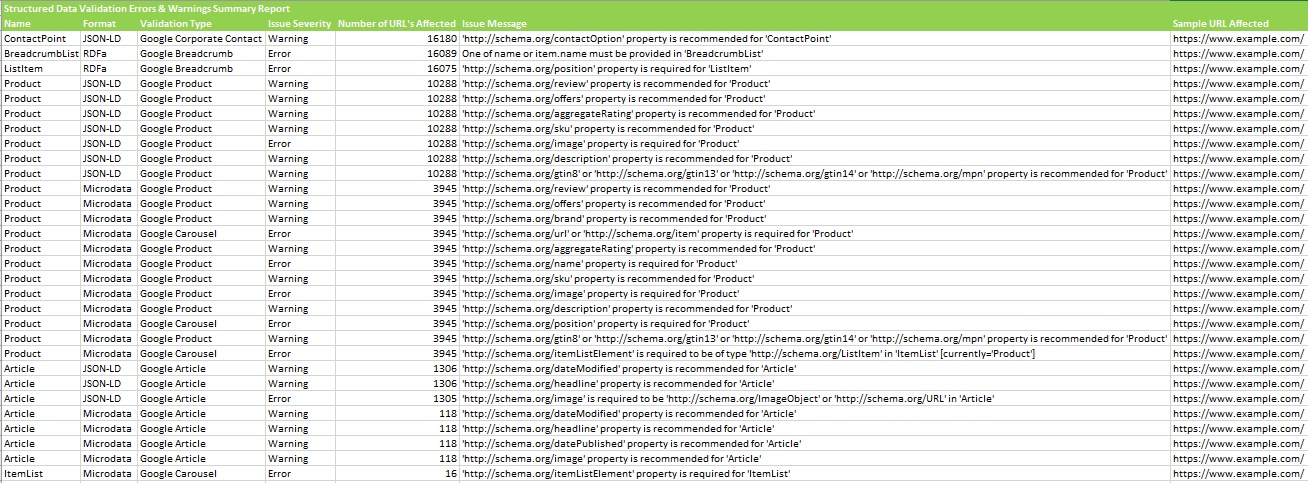
“验证错误和警告”报告显示 URL 级别的每个结构化数据验证错误和警告,包括 URL、属性名称(Organization 等)、格式(JSON-LD 等)、问题严重性(错误或警告)、验证类型(Google Product 等)和问题消息(/review 属性是必需的等)。
“Google 富媒体搜索结果功能摘要”报告按抓取中检测到的 Google 富媒体搜索结果功能进行聚合,并显示具有每个功能的 URL 数量。
“Google 富媒体搜索结果功能”报告将每个 URL 与每个可用功能进行映射,并显示每个 URL 检测到的功能。
PageSpeed 报告
PageSpeed 报告与 PageSpeed 选项卡中概述的过滤器相关,该选项卡涵盖了每个过滤器的含义。这些报告提供了一种导出页面及其具有速度机会或诊断的特定资源的方法。
它们需要设置并连接 PageSpeed Insights 集成。
“PageSpeed 优化建议汇总”报告总结了整个站点中发现的所有独特的优化建议、其影响的 URL 数量,以及平均和总体的潜在大小和毫秒节省量,以帮助大规模地确定优先级。
“CSS 覆盖率汇总”报告突出显示了每次抓取中每个 CSS 文件有多少未使用,以及通过删除站点上加载的未使用代码可以实现的潜在节省。
“JavaScript 覆盖率汇总”报告突出显示了每次抓取中每个 JS 文件有多少未使用,以及通过删除站点上加载的未使用代码可以实现的潜在节省。
HTTP 标头汇总报告
此报告显示了在抓取期间发现的所有 HTTP 响应标头的聚合视图。它显示了每个唯一的 HTTP 响应标头以及使用该标头响应的唯一 URL 的数量。
必须启用“HTTP 标头”,才能通过“配置 > Spider > 提取”进行提取,以便填充此报告。
更详细的 URL 和标头信息可以在下方的“HTTP 标头”选项卡中查看,也可以通过“批量导出 > Web > 所有 HTTP 标头”导出。
或者,可以在“内部”选项卡中查询 HTTP 标头,它们会附加在单独的唯一列中。
Cookie 汇总报告
此报告显示了在抓取期间发现的唯一 Cookie 的聚合视图,考虑了它们的名称、域、过期时间、安全性和 HttpOnly 值。还将显示每个唯一 Cookie 发布到的 URL 数量。Cookie 值本身在此聚合中被忽略(因为它们是唯一的!)。
必须启用“Cookies”,才能通过“配置 > Spider > 提取”进行提取,以便填充此报告。还需要配置 JavaScript 渲染 模式,以获得使用 JavaScript 或像素图像标签加载到页面上的 Cookie 的准确视图。
此聚合报告对于 GDPR 非常有帮助。更详细的 URL 和在其上找到的 Cookie 信息可以在下方的“Cookies”选项卡中查看,也可以通过“批量导出 > Web > 所有 Cookies”导出。
抓取路径报告
此报告不在顶部菜单的“报告”下拉列表中,而是在顶部窗口窗格中右键单击 URL,然后选择“导出”选项时可用。例如 -
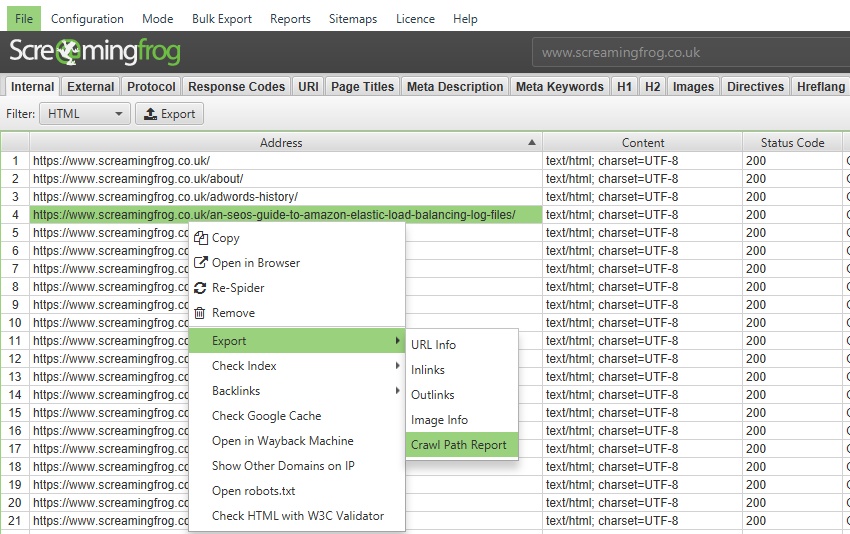
此报告显示了 SEO Spider 抓取以发现 URL 的最短路径,这对于深层页面非常有用,而不是查看大量 URL 的“反向链接”来发现原始源 URL(例如,由日历引起的无限 URL)。
抓取路径报告应从下往上阅读。“来源”列底部的第一个 URL 是抓取的第一个 URL(级别为“0”)。“目标”显示接下来抓取了哪些 URL,这些 URL 构成了下一级别(1)的以下“来源”URL,依此类推,向上。
报告最顶部的最终“目标”URL 将是抓取路径报告的 URL。
命令行界面设置
如果您在不允许您运行用户界面的平台上运行,则需要在通过命令行运行 SEO Spider 之前按照本指南中的说明进行操作。
如果您可以运行用户界面,请在通过命令行运行之前执行此操作。这将允许您接受最终用户许可协议 (EULA)、输入您的许可证密钥并选择存储模式。
当用户界面不可用于执行初始运行时,您必须�编辑一些配置文件。这些文件的位置因平台而异:
Windows
C:\Users\USERNAME\.ScreamingFrogSEOSpider\
macOS:
~/.ScreamingFrogSEOSpider/
Ubuntu:
~/.ScreamingFrogSEOSpider/
从现在开始,我们将此称为 .ScreamingFrogSEOSpider 目录。
输入您的许可证密钥
在您的 .ScreamingFrogSEOSpider 目录中创建一个名为 licence.txt 的文件。在第一行输入(复制并粘贴以避免拼写错误)您的许可证用户名,在第二行输入您的许可证密钥,然后保存该文件。
接受 EULA
在您的 .ScreamingFrogSEOSpider 目录中创建或编辑文件 spider.config。找到并编辑或添加以下行:
eula.accepted=15
保存文件并退出。请注意,数字值可能需要调整为更高版本。
选择存储模式
默认存储模式是内存。如果您乐于使用内存存储,则无需进行任何更改。要更改为数据库存储模式,请编辑您的 .ScreamingFrogSEOSpider 目录中的文件 spider.config。添加或编辑 storage.mode 属性为:
storage.mode=DB
默认路径是您的 .ScreamingFrogSEOSpider 目录中名为 db 的目录。如果您想更改此路径,请添加或编辑 storage.db_dir 属性。根据您�的操作系统,必须以不同的方式输入路径。
Windows:
storage.db_dir=C\:\\Users\\USERNAME\\dbfolder
macOS:
storage.db_dir=/Users/USERNAME/dbfolder
Ubuntu:
storage.db_dir=/home/USERNAME/dbdir
禁用嵌入式浏览器
embeddedBrowser.enable=false
内存分配
我们建议在 SEO Spider 界面中的“文件 > 设置 > 内存分配”下更改内存分配。然后在设置完成后通过 CLI 运行 SEO Spider。
但是,真正以无头模式(未连接显示器)运行的用户倾向于在基于 Linux 的操作系统上运行。因此,要在 Linux 操作系统上配置此设置,您需要在主目录(即“~/.screamingfrogseospider”)中修改或创建一个名为“.screamingfrogseospider”的文件。
相应地添加或修改以下行(显示了 8gb 配置):
-Xmx8g
连接到 API
要使用 API,我们建议在使用 CLI 之前使用用户界面设置和授权凭据。但是,当用户界面不可用时,可以通过复制在另一台机器上设置的所需文件夹或编辑 spider.config 文件(具体取决于 API)来使用 API。
对于 Google Analytics 和 Google Search Console,由于 OAuth,都需要使用用户界面进行连接和授权。因此,应使用能够使用 SEO Spider 界面的另一台机器来设置这些。授权后,可以将凭据复制到用户界面不可用的机器上。
请导航到相应的本地 Screaming Frog SEO Spider 用户文件夹 -
Windows
C:\Users\USERNAME\.ScreamingFrogSEOSpider\
macOS:
~/.ScreamingFrogSEOSpider/
Ubuntu:
~/.ScreamingFrogSEOSpider/
并复制“analytics”和“search_console”文件夹。
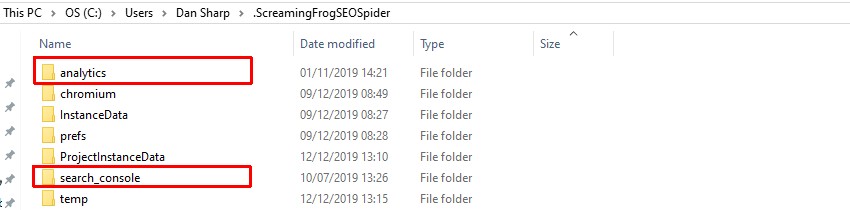
然后将它们粘贴到没有用户界面的机器上的 Screaming Frog SEO Spider 用户文件夹中。然后可以使用以下命令像往常一样使用 CLI 使用 API。
在抓取期间使用 Google Analytics API。
--use-google-analytics "google account" "account" "property" "view" "segment"
在抓取期间使用 Google Search Console API。
--use-google-search-console "google account" "website"
对于 PSI、Ahrefs、Majestic 和 Moz,它们都需要编辑 spider.config 文件并使用其各自的 API 密钥进行更新。spider.config 文件可以在如上所示的 Screaming Frog SEO Spider 用户文件夹中找到。
要使用每个 API,只需粘贴相关的 API 行,并将“APIKEY”替换为每个提供商提供的 API 密钥。
PSI.secretkey=APIKEY
ahrefs.authkey=APIKEY
majestic.authkey=APIKEY
moz.secretkey=APIKEY
然后可以使用以下命令像往常一样使用 CLI 使用 API。
在抓取期间使用 PageSpeed Insights API。
--use-pagespeed
在抓取期间使用 Ahrefs API。
--use-ahrefs
在抓取期间使用 Majestic API。
--use-majestic
在抓取期间使用 Mozscape API。
--use-mozscape
导出到 Google Drive
要在 CLI 中使用 Google Drive 导出,机器将需要适当的凭据,类似于任何其他 API。
这些凭据可以通过用户界面授权,也可以通过从另一台机器复制“google_drive”文件夹(如上所述)来授权。
配置抓取
如果某个功能或配置选项不可用作特定的命令行选项(如排除或 JavaScript 渲染),您将需要使用用户界面设置您希望的确切配置,并保存配置文件。
然后,您可以在使用 CLI 时提供该配置文件以使用这些功能。
当用户界面不可用时,我们建议首先在可用的机器上设置配置文件,传输保存的 .seospiderconfig 文件,然后通过命令行提供它。supercool-config.seospiderconfig 的命令行如下 -
--config "C:\Users\Your Name\Desktop\supercool-config.seospiderconfig"
命令行界面
您可以通过命令行完全操作 SEO Spider。
这包括启动、完整配置、保存和导出几乎所有数据和报告。SEO Spider 也可以使用 CLI 以无头模式运行。
本指南概述了如何为支持的三个操作系统使用命令行以及可用的参数。
Windows
打开命令提示符(“开始”按钮,然后键入“cmd”或在程序和文件中搜索“Windows 命令提示符”)。通过输入以下内容进入 SEO Spider 目录(64 位):
cd "C:\Program Files (x86)\Screaming Frog SEO Spider"
或者对于 32 位:
cd "C:\Program Files\Screaming Frog SEO Spider"
在 Windows 上,有一个单独的 SEO Spider 版本,称为 ScreamingFrogSEOSpiderCli.exe(而不是通常的 ScreamingFrogSEOSpider.exe)。可以从 Windows 命令行运行它,其行为类似于典型的控制台应用程序。您可以键入 -
ScreamingFrogSEOSpiderCli.exe --help
查看所有参数并查看 CL 中的所有日志记录。您也可以键入
–-help export-tabs, –-help bulk-export, –-help save-report, or –-help export-custom-summary
查看每个导出类型可用的完整参数列表。
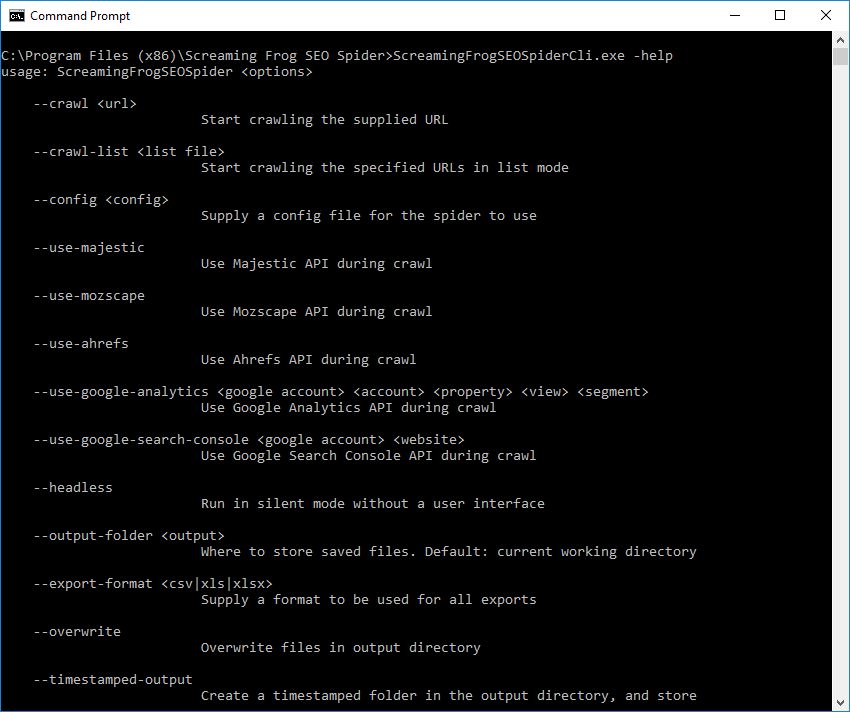
自动启动抓取:
ScreamingFrogSEOSpiderCli.exe --crawl https://www.example.com
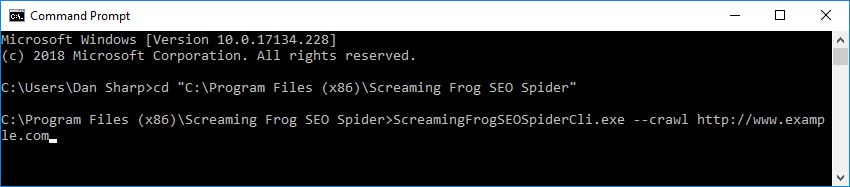
然后,只需用空格附加其他参数即可。
例如,以下命令意味着 SEO Spider 以无头模式运行、保存抓取、输出到您的桌面并导出内部和响应代码选项卡以及客户端错误过滤器。
ScreamingFrogSEOSpiderCli.exe --crawl https://www.example.com --headless --save-crawl --output-folder "C:\Users\Your Name\Desktop" --export-tabs “Internal:All,Response Codes:Client Error (4xx)”
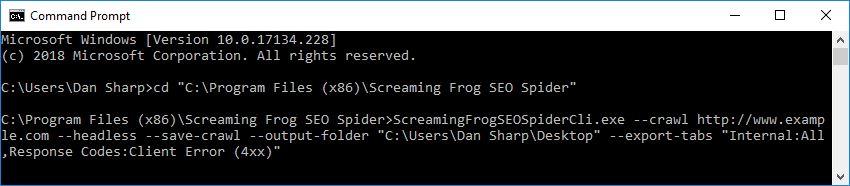
加载已保存的抓取:
ScreamingFrogSEOSpiderCli.exe --headless --load-crawl "C:\Users\Your Name\Desktop\crawl.dbseospider"
抓取必须是 .seospider 或 dbseospider 文件的绝对路径。
单独加载抓取没有用,因此需要其他参数来导出数据,例如以下命令将“内部”选项卡导出到桌面。
ScreamingFrogSEOSpiderCli.exe --headless --load-crawl "C:\Users\Your Name\Desktop\crawl.dbseospider" --output-folder "C:\Users\Your Name\Desktop\" --export-tabs “Internal:All”

请参阅 命令行选项 的完整列表,这些选项可用作 SEO Spider 的参数。
macOS
打开终端,可以在“应用程序”文件夹的“实用工具”文件夹中找到,也可以直接使用 Spotlight 并键入:“终端”。
有两种方法可以从命令行启动 SEO Spider。您可以使用 open 命令或 ScreamingFrogSEOSpiderLauncher 脚本。open 命令立即返回,允许您之后关闭终端。ScreamingFrogSEOSpiderLauncher 将日志记录到终端,直到 SEO Spider 退出,关闭终端会终止 SEO Spider。
要使用 open 命令启动 UI:
open "/Applications/Screaming Frog SEO Spider.app"
要使用 ScreamingFrogSEOSpiderLauncher 脚本启动 UI:
/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher
要查看可用命令行选项的完整列表:
/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher --help
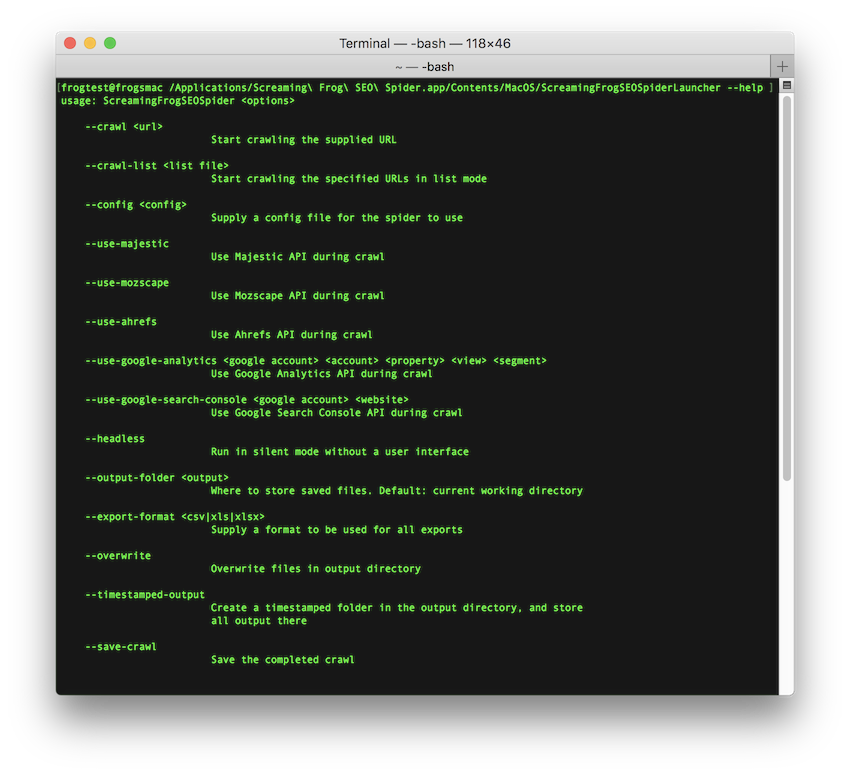
以下示例显示了启动 SEO Spider 的两种方法。
要打开已保存的抓取文件:
open "/Applications/Screaming Frog SEO Spider.app" --args /tmp/crawl.seospider
/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher /tmp/crawl.seospider
要加载已保存的抓取文件并将“内部”选项卡导出到桌面。
open "/Applications/Screaming Frog SEO Spider.app" --args --headless --load-crawl "C:\Users\Your Name\Desktop\crawl.dbseospider" --output-folder "C:\Users\Your Name\Desktop\" --export-tabs “Internal:All”
/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher --headless --load-crawl "/Users/Your Name/Desktop/crawl.dbseospider" --output-folder "/Users/Your Name/Desktop" --export-tabs "Internal:All"
要启动 UI 并立即开始抓取:
open "/Applications/Screaming Frog SEO Spider.app" --args --crawl https://www.example.com/
/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher --crawl https://www.example.com/
要以 Headless 模式启动,立即开始抓取,并将抓取结果以及 Internal->All 和 Response Codes->Client Error (4xx) 过滤器保存:
open "/Applications/Screaming Frog SEO Spider.app" --args --crawl https://www.example.com --headless --save-crawl --output-folder /tmp/cli --export-tabs "Internal:All,Response Codes:Client Error (4xx)"
/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher --crawl https://www.example.com --headless --save-crawl --output-folder /tmp/cli --export-tabs "Internal:All,Response Codes:Client Error (4xx)"
请参阅命令行选项的完整列表,这些选项可用作 SEO Spider 的参数。
Linux
此 screamingfrogseospider 二进制文件在安装期间放置在您的路径中。要运行此程序,请打开终端并按照以下示例操作。
要正常启动:
screamingfrogseospider
要打开已保存的抓取文件:
screamingfrogseospider /tmp/crawl.seospider
要查看可用命令行选项的完整列表:
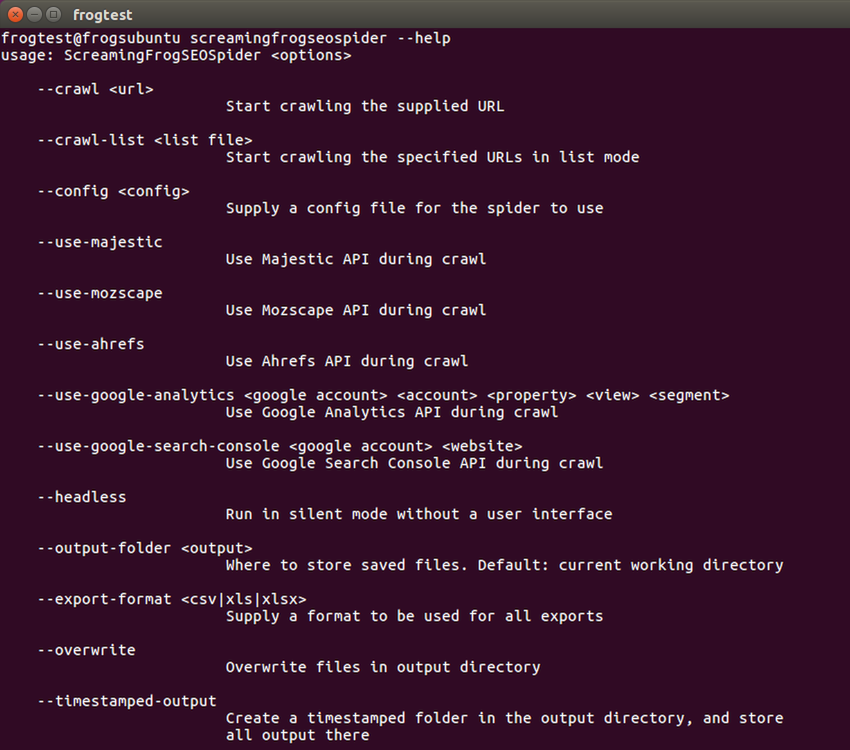
screamingfrogseospider --help
要启动 UI 并立即开始抓取:
screamingfrogseospider --crawl https://www.example.com/
要以 Headless 模式启动,立即开始抓取,并将抓取结果以及 Internal->All 和 Response Codes->Client Error (4xx) 过滤器保存:
screamingfrogseospider --crawl https://www.example.com --headless --save-crawl --output-folder /tmp/cli --export-tabs "Internal:All,Response Codes:Client Error (4xx)"
要加载已保存的抓取文件并将“Internal”选项卡导出到桌面:
screamingfrogseospider --headless --load-crawl ~/Desktop/crawl.seospider --output-folder ~/Desktop/ --export-tabs "Internal:All"
为了在 Linux 中以 Headless 模式运行时利用 JavaScript 渲染,需要一个显示器。您可以使用虚拟帧缓冲区来模拟连接了显示器。请参阅此处的完整详细信息。
请参阅下面的命令行选项的完整列表。
命令行选项
请参阅命令行选项的完整列表,这些选项可用作 SEO Spider 的参数,方法是在应用程序中使用 –-help,以及下面的列表。
提供 '–-help export-tabs'、'–-help bulk-export'、'–-help save-report' 或 '–-help export-custom-summary' 以查看每种导出类型可用的参数的完整列表。
开始抓取提供的 URL。
--crawl https://www.example.com
开始以列表模式抓取指定的 URL。
--crawl-list "list file"
加载已保存的 .seospider 或 .dbseospider 抓取文件。示例:–load-crawl “C:\Users\Your Name\Desktop\crawl.dbseospider”。
--load-crawl "crawl file"
加载数据库抓取。抓取 ID 在“文件 > 抓取”中可用,并使用右键单击“复制数据库 ID”。示例:–load-crawl “65a6a6a5-f1b5-4c8e-99ab-00b906e306c7”。
--load-crawl "database crawl ID"
或者,可以在 CLI 中查看数据库抓取 ID。
--list-crawls
提供已保存的配置文件供 SEO Spider 使用。示例:–config “C:\Users\Your Name\Desktop\supercool-config.seospiderconfig”。
--config "config"
提供已保存的身份验证配置文件供 SEO Spider 使用。示例:–auth-config “C:\Users\Your Name\Desktop\supercool-auth-config.seospiderauthconfig”。
--auth-config "authconfig"
在没有用户界面的静默模式下运行。
--headless
保存已完成的抓取。
--save-crawl
存储已保存的文件。默认值:当前工作目录。示例:–output-folder “C:\Users\Your Name\Desktop”。
--output-folder "output"
覆盖输出目录中的文件。
--overwrite
设置项目名称,用于在数据库存储模式下存储抓取结果,以及用于 Google Drive 中的文件夹名称。默认情况下,导出将存储在“Screaming Frog SEO Spider”Google Drive 目录中,但使用此参数意味着它们将存储在“Screaming Frog SEO Spider > 项目名称”中。示例:–project-name “Awesome Project”。
--project-name "Name"
设置任务名称,用于数据库存储模式下的抓取名称。这也将用作 Google Drive 的文件夹,它是项目文件夹的子文件夹。例如,当提供项目名称时,“Screaming Frog SEO Spider > 项目名称 > 任务名称”。示例:–task-name “Awesome Task”
--task-name "Name"
在输出目录中创建一个带时间戳的文件夹,并将所有输出存储在那里。这还将在 Google Drive 中创建一个带时间戳的目录。
--timestamped-output
提供要导出的选项卡和过滤器的逗号分隔列表。您需要指定选项卡和过滤器名称,并用冒号分隔。选项卡名称与它们在用户界面上显示的名称相同,但通过配置->Spider->首选项配置的选项卡除外,其中使用 X。例如:Meta Description:Over X Characters。示例:–export-tabs “Internal:All”。
--export-tabs "tab:filter,..."
提供要执行的批量导出的逗号分隔列表。导出名称与 UI 中“批量导出”菜单中的名称��相同。要访问子菜单中的导出,请使用“子菜单名称:导出名称”。示例:–bulk-export “Response Codes:Internal & External:Client Error (4xx) Inlinks”。
--bulk-export "submenu:export,..."
提供要保存的报告的逗号分隔列表。报告名称与 UI 中“报告”菜单中的名称相同。要访问子菜单中的报告,请使用“子菜单名称:报告名称”。示例:–save-report “Redirects:All Redirects”。
--save-report "submenu:report,..."
为自动 Data Studio 抓取报告提供“导出到 Data Studio”自定义抓取概览报告的项目的逗号分隔列表。
可以使用“–help export-custom-summary”在 CLI 中查看自定义抓取概览的可配置报告项目,并且它们与调度 UI 中(英语)的名称相同。这需要您也使用您的 Google Drive 帐户。示例:–export-custom-summary “Site Crawled,Date,Time” –google-drive-account “[email protected]”。
--export-custom-summary "item 1,item 2,item 3..."
从已完成的抓取创建站点地图。
--create-sitemap
从已完成的抓取创建图像站点地图。
--create-images-sitemap
提供用于所有导出的格式。对于 Google Sheet,您还需要提供您的 Google Drive 帐户。示例:–export-format csv。
--export-format csv xls xlsx gsheet
使用 Google Drive 帐户进行 Google Sheets 导出。示例:–google-drive-account “[email protected]”。
--google-drive-account "google account"
在抓取期间使用 Google Universal Analytics API。请记住如下所示的引号。示例:–use-google-analytics “[email protected]” “Screaming Frog” “https://www.screamingfrog.co.uk/” “All Web Site Data” “Organic Traffic”。
--use-google-analytics "google account" "account" "property" "view" "segment"
在抓取期间使用 Google Analytics 4 API。请记住如下所示的引号。示例:–use-google-analytics-4 “[email protected]” “Screaming Frog” “Screaming Frog – GA4” “All Data Streams”。
--use-google-analytics-4 "google account" "account" "property" "data stream"
在抓取期间使用 Google Search Console API。示例:–use-google-search-console “[email protected]” “https://www.screamingfrog.co.uk/”
--use-google-search-console "google account" "website"
在抓取期间使用 PageSpeed Insights API。
--use-pagespeed
在抓取期间使用 Majestic API。
--use-majestic
在抓取期间使用 Mozscape API。
--use-mozscape
在抓取期间使用 Ahrefs API。
--use-ahrefs
查看此选项列表。
--help
使用已保存的配置
如果某个功能或配置选项无法作为上面概述的特定命令行选项使用(例如排除或 JavaScript 渲染),您将需要使用用户界面来设置您希望的确切配置,并保存配置文件。
然后,您可以在使用 CLI 时提供已保存的配置文件以利用这些功能。
故障排除
- 如果 Headless 抓取无法导出任何结果,请确保 –output-folder 存在并且为空,或者您正在使用 –timestamped-output 选项。
- 在引用参数时,不要在引号前以 \ 结尾,因为它将被转义。
用户界面
主题
文件 > 设置 > 用户界面 (Windows, Linux)
Screaming Frog SEO Spider > 设置 > 用户界面 (macOS)
SEO Spider 有两个主题,浅色模式和深色模式。可以在以下位置修改:
选项卡
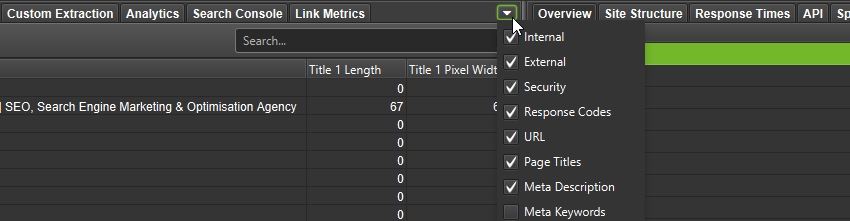
可以通过使用鼠标将选项卡拖放到新位置来重新排序选项卡。这适用于下部窗口中的选项卡以及主窗口中的选项卡。

可以通过右键单击任何选项卡并选择“关闭”来隐藏这些选项卡,“关闭其他”将隐藏除所选选项卡之外的所有选项卡,“全部关闭”将隐藏所有选项卡。

选项卡可见性可以从选项卡右侧的 ⌄ 菜单进行管理。
可以通过“视图 > 重置选项卡”将选项卡重置为其默认可见性和位置。

列
可以通过将列拖放到所需位置来重新定位列。
可以使用主窗口中列行右侧的 + 菜单隐藏这些列。
可以通过“视图 > 重置所有表的列”将列重置为其默认可见性和位置。

调整窗格大小
可以通过选择右侧和下部窗口之间的窗格并将它们拖动到首选大小来调整它们的大小。
专注模式
视图 > 专注模式
“专注模式”会自动隐藏未使用的选项卡,以帮助减少混乱。

默认情况下,无论配置如何,所有选项卡都会显示在 UI 中。
但是,当启用“专注模式”时,只会保留基于配置所需的选项卡。因此,如果未启用其各自的配置,则诸如“结构化数据”、“站点地图”或“自定义提取”之类的选项卡将被隐藏。
这减少了主窗口选项卡和下部详细信息选项卡的数量。
如果为隐藏的选项卡启用了配置,则该选项卡将自动再次显示。
搜索功能
界面右上角的搜索框允许您搜索所有可见列。它默认为“地址”列的常规文本搜索,但允许您切换到正则表达式,从各种预定义的过滤器中进行选择(包括“不匹配正则表达式”),组合规则(和/或)并选择列。
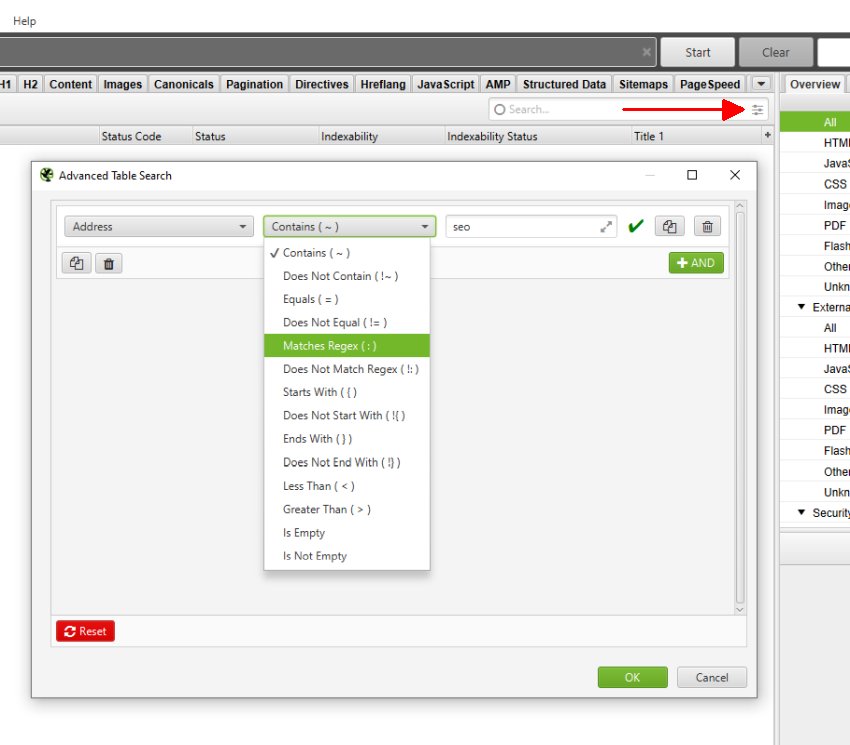
输入搜索内容后,按 Enter 键,只会显示包含匹配单元格的行。
如果您想使此搜索不区分大小写,您可以单击搜索查询框右侧的箭头并启用“区分大小写”:
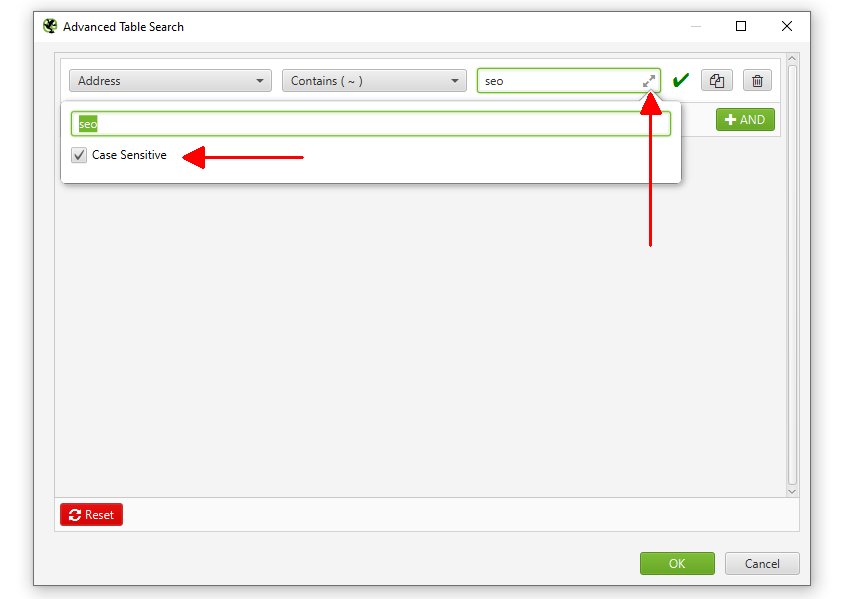
搜索栏显示搜索和过滤系统使用的语法,因此高级用户可以构建常用搜索和过滤器,而无需单击按钮来运行搜索。

只需将语法粘贴或直接写入搜索框即可运行搜索。
要搜索重复或重复的单词,您可以使用区分大小写的捕获组:
(keyword)(.*\1+)
在包含表格数据的大多数下部窗口选项卡中,可以找到具有相同功能和功能的其他搜索框。
“查看源代码”选项卡中还有一个搜索功能,可以搜索任何存储的 HTML。
自动更新
默认情况下,SEO Spider 将自动检查更新。您可以通过菜单项帮助->调试->自动检查更新来启用/禁用此行为。
要在没有 UI 的情况下执行此操作,您可以更新位于以下位置的 spider.config 文件:
Windows
C:\Users\USERNAME\.ScreamingFrogSEOSpider\
macOS:
~/.ScreamingFrogSEOSpider/
Ubuntu:
~/.ScreamingFrogSEOSpider/
并添加/修改以下行:
updatechecker.enabled=false