SEO Spider 配置
Spider 抓取标签页
图片
配置 > Spider > 抓取 > 图片
您可以选择独立存储和抓取图片。
取消勾选“存储”配置将意味着 img 元素中的图片文件将不会被存储,并且不会出现在 SEO Spider 中。
<img src="image.jpg">
取消勾选“抓取”配置将意味着 img 元素中的图片文件将不会被抓取以检查其响应代码。
通过任何其他方式链接的图片仍然会被存储和抓取,例如,使用锚标记。
排除 或 自定义 robots.txt 可用于锚标记中链接的图片。
请阅读我们的指南 如何查找缺失的图片 Alt 文本和属性。
媒体
配置 > Spider > 抓取 > 媒体
您可以选择独立存储和抓取媒体文件。启用两者将意味着 <video> 和 <audio> 元素中的文件将被抓取。
例如:
<video width="320" height="240" controls>
<source src="movie.mp4" type="video/mp4">
</video>
取消勾选“存储”配置将意味着 video 和 audio 元素中的文件将不会被存储,并且不会出现在 SEO Spider 中。
取消勾选“抓取”配置将意味着 video 和 audio 元素中的文件将不会被抓取以检查其响应代码。
CSS
配置 > Spider > 抓取 > CSS
这允许您独立存储和抓取 CSS 文件。
取消勾选“存储”配置将意味着 CSS 文件将不会被存储,并且不会出现在 SEO Spider 中。
取消�勾选“抓取”配置将意味着样式表将不会被抓取以检查其响应代码。
JavaScript
配置 > Spider > 抓取 > JavaScript
您可以选择独立存储和抓取 JavaScript 文件。
取消勾选“存储”配置将意味着 JavaScript 文件将不会被存储,并且不会出现在 SEO Spider 中。
取消勾选“抓取”配置将意味着 JavaScript 文件将不会被抓取以检查其响应代码。
SWF
配置 > Spider > 抓取 > SWF
您可以选择独立存储和抓取 SWF (Adobe Flash File format) 文件。
取消勾选“存储”配置将意味着 SWF 文件将不会被存储,并且不会出现在 SEO Spider 中。
取消勾选“抓取”配置将意味着 SWF 文件将不会被抓取以检查其响应代码。
内部超链接
配置 > Spider > 抓取 > 内部超链接
默认情况下,SEO Spider 将在抓取中抓取和存储内部超链接。
内部定义为与在 SEO Spider 中输入的子域相同的 URL。 超链接是包含在 HTML 锚标记中的 URL。
通过禁用“抓取”,锚标记中包含的与起始 URL 位于同一子域上的 URL 将不会被跟踪和抓取。
禁用“存储”和“抓取”在 列表模式 中非常有用,当删除 抓取深度 时。 它允许 SEO Spider 抓取上传的 URL 和任何其他资源或页面链接,但不再抓取内部链接。
例如,您可以在列表模式下提供 URL 列表,并且仅抓取它们和 hreflang 链接。 或者您可以提供桌面 URL 列表并仅审核其 AMP 版本。 您可以上传 URL 列表,并且仅审核它们上的图像或外部链接等。
外部链接
配置 > Spider > 抓取 > 外部链接
您可以选择独立存储和抓取外部链接。 外部链接是在抓取过程中遇到的来自与启动抓取的域(或具有默认配置的子域)不同的域的 URL。
取消勾选“存储”配置将意味着任何外部链接将不会被存储,并且不会出现在 SEO Spider 中。
取消勾选“抓取”配置将意味着外部链接将不会被抓取以检查其响应代码。
请注意,这可以包括图像、CSS、JS、hreflang 属性和 canonicals(如果它们是外部的)。
Canonicals
配置 > Spider > 抓取 > Canonicals
默认情况下,SEO Spider 将存储和抓取 canonicals(在 canonical 链接元素或 HTTP 标头中),并使用其中包含的链接进行发现。
取消勾选“存储”配置将意味着 canonicals 将不会被存储,并且不会出现在 SEO Spider 中。
取消勾选“抓取”配置将意味着在 canonicals 中发现的 URL 将不会被��抓取。 如果仅选择“存储”,那么它们将继续在界面中报告,但它们不会用于发现。
请阅读我们的指南 如何审核 Canonicals。
分页 (rel next/prev)
配置 > Spider > 抓取 > 分页 (Rel Next/Prev)
默认情况下,SEO Spider 不会抓取 rel=”next” 和 rel=”prev” 属性,也不会使用其中包含的链接进行发现。
取消勾选“存储”配置将意味着 rel=”next” 和 rel=”prev” 属性将不会被存储,并且不会出现在 SEO Spider 中。
取消勾选“抓取”配置将意味着在 rel=”next” 和 rel=”prev” 中发现的 URL 将不会被抓取。
请阅读我们的指南 如何审核 rel=”next” 和 rel=”prev” 分页属性。
Hreflang
配置 > Spider > 抓取 > Hreflang
默认情况下,SEO Spider 将提取 hreflang 属性,并在 hreflang 标签页 中显示 hreflang 语言和区域代码以及 URL。
但是,除非勾选“抓取 hreflang”,否则 hreflang 属性中找到的 URL 将不会被抓取并用于发现。 启用此设置后,将从列表模式下上传的 XML 站点地图中提取 hreflang URL。
取消勾选“存储”配置将意味着 hreflang 属性将不会被存储,并且不会出现在 SEO Spider 中。
取消勾选“抓取”配置将意味着在 hreflang 中发现的 URL 将不会被抓取。
请阅读我们的指南 如何审核 Hreflang。
AMP
配置 > Spider > 抓取 > AMP
默认情况下,SEO Spider 不会提取 rel=”amphtml” 链接标签中包含的 AMP URL 的详细信息,这些信息随后将出现在 AMP 标签页 下。
取消勾选“存储”配置将意味着 rel=”amphtml” 链接标签中包含的 URL 将不会被存储,并且不会出现在 SEO Spider 中。
取消勾选“抓取”配置将意味着 rel=”amphtml” 链接标签中包含的 URL 将不会被抓取。
我们建议在审核 AMP 时启用这两个配置选项。 请阅读我们的指南 如何审核和验证加速移动页面 (AMP)。
Meta refresh
配置 > Spider > 抓取 > Meta Refresh
默认情况下,SEO Spider 将存储和抓取 meta refresh 中包含的 URL。
<meta http-equiv="refresh" content="4; URL='www.screamingfrog.co.uk/meta-refresh-url'"/>
取消勾选“存储”配置将意味着 meta refresh 详细信息将不会被存储,并且不会出现在 SEO Spider 中。
取消勾选“抓取”配置将意味着在 meta refresh 中发现的 URL 将不会被抓取。
iframes
配置 > Spider > 抓取 > iframes
默认情况下,SEO Spider 将存储和抓取 iframes 中包含的 URL。
<iframe src="https://www.screamingfrog.co.uk/iframe/"/>
取消勾选“存储”配置将意味着 iframe 详细信息将不会被存储,并且不会出现在 SEO Spider 中。
取消勾选“抓取”配置将意味着在 iframe 中发现的 URL 将不会被抓取。
移动设备备选方案
配置 > Spider > 抓取 > 移动设备备选方案
默认情况下,SEO Spider 不会抓取或存储 rel=”alternate” 链接元素中包含的 URL。
<link rel="alternate" media="only screen and (max-width: 640px)" href="http://m.example.com/">
取消勾选“存储”配置将意味着移动设备备选方案详细信息将不会被存储,并且不会出现在 SEO Spider 中。
取消勾选“抓取”配置将意味着在移动设备备选方案链接元素中发现的 URL 将不会被抓取。
检查起始文件夹外的链接
配置 > Spider > 抓取 > 检查起始文件夹外的链接
如果您不想抓取从您开始的子文件夹之外的链接,请取消选中此框。 此选项使您能够从起始子文件夹中进行抓取,但仍然可以抓取这些 URL 链接到的位于起始文件夹之外的链接。
抓取起始文件夹外的内容
配置 > Spider > 抓取 > 抓取起始文件夹外的内容
默认情况下,SEO Spider 将仅从您从中抓取的子文件夹(或子目录)向前抓取。 但是,如果您希望从特定的子文件夹开始抓取,但抓取整个网站,请使用此选项。
抓取所有子域
配置 > Spider > 抓取 > 抓取所有子域
默认情况下,SEO Spider 将仅抓取您从中抓取的子域,并将遇到的所有其他子域视为外部站点。 这些将仅被抓取到单个级别,并显示在 外部标签页 下。
例如,如果输入 https://www.screamingfrog.co.uk 作为起始 URL,那么在抓取中发现的其他子域(例如 https://cdn.screamingfrog.co.uk 或 https://images.screamingfrog.co.uk)将被视为“外部”,以及其他域(例如 www.google.co.uk 等)。
要抓取根域的所有子域(例如 https://cdn.screamingfrog.co.uk 或 https://images.screamingfrog.co.uk),则应启用此配置。
CDN 配置选项可用于将外部 URL 视为内部 URL。
请注意 - 如果从根目录开始抓取,并且未在一开始指定子域(例如,从 https://screamingfrog.co.uk 开始抓取),那么默认情况下将抓取所有子域。 这类似于 Google 搜索中 site: 查询的行为。
跟踪内部或外部“nofollow”
配置 > Spider > 抓取 > 跟踪内部/外部“Nofollow”
默认情况下,SEO Spider 不会抓取具有“nofollow”、“sponsored”和“ugc”属性的内部或外部链接,也不会抓取来自具有 meta nofollow 标签的页面以及 X-Robots-Tag HTTP 标头中具有 nofollow 的链接。
如果您希望 SEO Spider ��抓取这些链接,只需启用此配置选项。
抓取链接的 XML 站点地图
配置 > Spider > 抓取 > 抓取链接的 XML 站点地图
默认情况下,SEO Spider 不会抓取 XML 站点地图(在常规“Spider”模式下)。 要抓取 XML 站点地图并在 站点地图标签页 中填充过滤器,应启用此配置。
启用“抓取链接的 XML 站点地图”配置后,您可以选择“通过 robots.txt 自动发现 XML 站点地图”,或者通过勾选“抓取这些站点地图”并将其粘贴到出现的字段中来提供 XML 站点地图列表。
请注意 - 抓取完成后,需要执行“抓取分析”才能填充站点地图过滤器。 请阅读我们的指南“如何审核 XML 站点地图”。
Spider 提取标签页
页面详情
配置 > Spider > 提取 > 页面详情
以下页面元素可配置为存储在 SEO Spider 中。
- 页面标题
- Meta 描述
- Meta 关键词
- H1
- H2
- 可索引性(& 可索引性状态)
- 字数统计
- 可读性
- 文本代码比率
- 哈希值
- 页面大小
- 表单
- 可访问性 - 此功能还需要通过“配置 > Spider > 渲染”进行 JavaScript 渲染。 这将启用开源 AXE 可访问性规则集,用于在 可访问性标签页 和过滤器中看到的自动化可访问性验证。
禁用提取上述任何选项将意味着它们不会出现在 SEO Spider 界面中的相应标签页、列或过滤器中。
如果禁用某些过滤器和报告,显然将不再起作用。 例如,如果禁用“哈希值”,那么“URL > 重复”过滤器将不再填充,因为这使用哈希值作为完全重复 URL 的算法检查。
通过不存储每个元素的数据,可以节省少量内存。
URL 详情
配置 > Spider > 提取 > URL 详情
以下 URL 详情可配置为存储在 SEO Spider 中。
- 响应时间 – 下载 URL 所需的时间,以秒为单位。更多详细信息请参见我们的 FAQ。
- Last-Modified – 从服务器 HTTP 响应中的 Last-Modified 标头读取。如果服务器未提供此标头,则该值将为空。
- HTTP 标头 – 这将存储完整的 HTTP 请求和响应标头,可以在下方的“HTTP 标头”选项卡中查看。完整的响应标头也包含在“内部”选项卡中,以便可以与抓取数据一起查询。它们可以通过“批量导出 > Web > 所有 HTTP 标头”进行批量导出,并且可以通过“报告 > HTTP 标头 > HTTP 标头摘要”导出聚合报告。
- Cookies – 这将存储在抓取期间找到的 cookies,位于下方的“Cookies”选项卡中。需要使用 JavaScript 渲染 模式才能准确查看使用 JavaScript 或像素图像标签加载到页面上的 cookies。Cookies 可以通过“批量导出 > Web > 所有 Cookies”进行批量导出,并且可以通过“报告 > Cookies > Cookie 摘要”导出聚合报告。请注意,当您选择存储 cookies 时,SEO Spider 对 Google Analytics 跟踪标签执行的自动排除将被禁用,以提供所有已颁发 cookies 的准确视图。这意味着它会影响您的分析报告,除非您选择使用 排除 配置(“配置 > 排除”)排除任何跟踪脚本的触发,或者过滤掉类似于 排除 PSI 的“Screaming Frog SEO Spider”用户代理。
禁用上述任何提取选项意味着它们不会出现在 SEO Spider 界面的相应选项卡和列中。
通过不存储每个元素的数据,可以节省少量内存。
指令
配置 > Spider > 提取 > 指令
以下指令可以配置为存储在 SEO Spider 中。
- Meta Robots
- X-Robots-Tag
禁用上述任何提取选项意味着它们不会出现在 SEO Spider 界面的相应选项卡、列或过滤器中。
通过不存储数据,可以节省少量内存。
结构化数据
配置 > Spider > 提取 > 结构化数据
结构化数据完全可以配置为存储在 SEO Spider 中。请参阅我们关于 如何测试和验证结构化数据 的详细指南,或者继续阅读以下内容以了解有关配置选项的更多信息。
默认情况下,SEO Spider 不会提取和报告结构化数据。需要启用以下配置选项,不同的结构化数据格式才能出现在“结构化数据”选项卡中。
- JSON-LD – 此配置选项使 SEO Spider 能够提取 JSON-LD 结构化数据,并使其出现在“结构化数据”选项卡下。
- Microdata – 此配置选项使 SEO Spider 能够提取 Microdata 结构化数据,并使其出现在“结构化数据”选项卡下。
- RDFa – 此配置选项使 SEO Spider 能够提取 RDFa 结构化数据,并使其出现在“结构化数据”选项卡下。
您还可以选择根据 Schema.org 和 Google 富媒体搜索结果功能 验证结构化数据。
Schema.org 验证
只有在启用了一种或多种结构化数据格式以进行提取时,此�配置选项才可用。
如果启用,则 SEO Spider 将根据 Schema.org 规范验证结构化数据。它会检查类型和属性是否存在,并会显示遇到的任何问题的“错误”。
例如,它会检查属性是否存在 http://schema.org/author,或者类型是否存在 http://schema.org/Book。它会根据其最新版本验证主要和待处理的 Schema 词汇表。结构化数据 选项卡和过滤器将显示验证错误的详细信息。
此外,此验证还会检查 Data-Vocabulary.org 的过期 schema 使用情况。
Google 富媒体搜索结果功能验证
只有在启用了一种或多种结构化数据格式以进行提取时,此配置选项才可用。
如果启用,则 SEO Spider 将根据 Google 富媒体搜索结果功能的要求,按照他们自己的文档验证结构化数据。所需属性的验证问题将被归类为错误,而围绕推荐属性的问题将被归类为警告,这与 Google 自己的结构化数据�测试工具的方式相同。
结构化数据 选项卡和过滤器将显示 Google 功能验证错误和警告的详细信息。
可以在我们的 如何测试和验证结构化数据 指南中查看 SEO Spider 能够验证的 Google 富媒体搜索结果功能的完整列表。
HTML
配置 > Spider > 提取 > 存储 HTML / 渲染的 HTML
存储 HTML
这允许您将 SEO Spider 抓取的每个 URL 的静态 HTML 保存到磁盘,并在“查看源文件”下部窗口窗格(在左侧,“原始 HTML”下)中查看它。它们可以通过“批量导出 > Web > 所有页面源文件”进行批量导出。
这使您能够查看 JavaScript 生效之前的原始 HTML,就像在浏览器中右键单击“查看源文件”一样。这非常适合调试或与渲染的 HTML 进行比较。
存储渲染的 HTML
这允许您将 SEO Spider 抓取的每个 URL 的渲染 HTML 保存到磁盘,并在“查看源文件”下部窗口窗格(在右侧,“渲染的 HTML”下)中查看它。它们可以通过“批量导出 > Web > 所有页面源文件”进行批量导出。
这使您能够像“检查元素”(在 Chrome 的 DevTools 中)一样查看 DOM,在 JavaScript 处理之后。
请注意,此选项仅在启用 JavaScript 渲染 时才有效。
PDF
配置 > Spider > 提取 > PDF
存储 PDF
这允许您在抓取期间将 PDF 保存到磁盘。它们可以通过“批量导出 > Web > 所有 PDF 文档”进行批量导出,或者仅内容可以通过“批量导出 > Web > 所有 PDF 内容”导出为 .txt 文件。
存储 PDF 时,可以在“渲染的页面”选项卡中查看 PDF,并且可以在“查看源文件”选项卡和“可见内容”过滤器中查看 PDF 的文本内容。
提取 PDF 属性
默认情况下,将提取 PDF 标题和关键字。这些将出现在 SEO Spider 的“内部”选项卡中的“标题”和“Meta 关键字”列中。
Google 会将 PDF 转换为 HTML,并将 PDF 标题用作标题元素,并将关键字用作 meta 关键字,尽管它不会在评分中使用 meta 关键字。
通过启用“提取 PDF 属性”,还将提取以下其他属性。
- 主题
- 作者
- 创建日期
- 修改日期
- 页数
- 字数
这些新列显示在“内部”选项卡中。
提取链接文本
启用此设置后,SEO Spider 将尝试查找与 PDF 中的链接关联的文本。禁用此设置后,这些列将为空白。
可以在与链接关联的下部“出站链接”(和“入站链接”)选项卡中查看锚文本。
根据 PDF 的格式,这可能不准确、缓慢且占用大量内存。
Spider 限制选项卡
限制抓取总数
配置 > Spider > 限制 > 限制抓取总数
该软件的免费版本具有 500 个 URL 的抓取限制。如果您拥有该工具的许可版本,则此限制将替换为 500 万个 URL,但您可以在此处包含任意数量的 URL,以便更好地控制要抓取的页面数量。
限制抓取深度
配置 > Spider > 限制 > 限制抓取深度
您可以选择 SEO Spider 抓取站点的深度(根据与您选择的起点的链接距离)。
限制每个抓取深度的 URL 数量
配置 > Spider > 限制 > 限制每个抓取深度的 URL 数量
控制在每个抓取深度抓取的 URL 数量。
限制最大文件夹深度
配置 > Spider > 限制 > 限制最大文件夹深度
控制 SEO Spider 将抓取的文件夹(或子目录)的数量。
Spider 将文件夹分类为 URL 路径的一部分,该路径位于域之后,并以尾部斜杠结尾:
- https://www.screamingfrog.co.uk/ – 文件夹深度 0
- https://www.screamingfrog.co.uk/seo-spider/ – 文件夹深度 1
- https://www.screamingfrog.co.uk/seo-spider/#download – 文件夹深度 1
- https://www.screamingfrog.co.uk/seo-spider/fake-page.html – 文件夹深度 1
- https://www.screamingfrog.co.uk/seo-spider/user-guide/ – 文件夹深度 2
限制查询字符串的数量
配置 > Spider > 限制 > 限制查询字符串的数量
从抓取中排除包含超过配置数量的查询字符串的任何 URL。例如,如果设置为“2”,则不会抓取 example.com/?query1&query2&query3。
要遵循的最大重定向数
配置 > Spider > 限制 > 要遵循的最大重定向数
此选项提供了控制 SEO Spider 将遵循的重定向数量的功能。
限制要抓取的最大 URL 长度
配置 > Spider > 限制 > 限制最大 URL 长度
控制 SEO Spider 将抓取的 URL 的长度。
由于数据库存储的限制,默认的最大 URL 长度为 2,000。
按 URL 路径限制
配置 > Spider > 限制 > 按 URL 路径限制
按 URL 路径控制抓取的 URL 数量。输入 URL 模式列表以及要抓取的每个模式的最大页面数。
Spider 渲染选项卡
渲染
配置 > Spider > 渲染
此配置允许您设置抓取的渲染模式:
- 仅文本: SEO Spider 将仅从原始 HTML 抓取和提取。它忽略 AJAX 抓取方案和客户端 JavaScript。
- 旧的 AJAX 抓取方案: 如果发现,SEO Spider 将遵守 Google 长期弃用的 AJAX 抓取方案。如果不存在,它将像默认的“仅文本”模式一样抓取原始 HTML。
- JavaScript: SEO Spider 将通过在其无头 Chrome 浏览器中渲染页面来执行客户端 JavaScript,并从渲染的 HTML 中抓取和提取内容和链接。与 Google 一样,它还将发现原始 HTML 中的任何链接。
请注意:为了尽可能地模拟 Googlebot,我们的渲染引擎使用 Chromium 项目。支持以下操作系统:
- Windows 10
- Windows 11
- Windows Server 2016
- Windows Server 2022
- Ubuntu 14.04+(仅限 64 位)
- macOS 11+
请注意:如果您运行的是受支持的操作系统,但仍然无法使用渲染,则可能是您在兼容模式下运行。
要检查这一点,请转到您的安装目录 (C:\Program Files (x86)\Screaming Frog SEO Spider\),右键单击 ScreamingFrogSEOSpider.exe,选择“属性”,然后选择“兼容性”选项卡,并检查您在“兼容模式”部分下没有任何勾选。
渲染的页面屏幕截图
配置 > Spider > 渲染 > JavaScript > 渲染的页面屏幕截图
选择 JavaScript 渲染 时,默认启用此配置,这意味着会捕获渲染页面的屏幕截图,可以在下部窗口窗格的“渲染的页面”选项卡中查看。
您可以从 Googlebot 桌面版、Googlebot 智能手机版和各种其他设备中选择各种窗口大小。
可以使用以下选项自定义这些窗口大小:
- 宽度和高度 – 用于设置自定义窗口大小。
- 缩放因子 – 增加用于屏幕截图的缩放比例。更好地模拟具有更高像素密度的设备。
- 移动设备 – Chrome 标志,指示屏幕用于移动设备。
- 启用触摸 – Chrome 标志,指示设备已启用触摸。
- 调整为内容大小 – 启用后,Spider 将调整浏览器窗口的大小,以尝试捕获屏幕截图中的完整页面长度(最多 8192 像素)。取消选中后,这将仅在指定分辨率的窗口中截取页面顶部的屏幕截图。
- 窗口调整大小时间 – 调整窗口大小后,截取页面屏幕截图的时间。
渲染的屏幕截图可以在“C:\Users\User Name\.ScreamingFrogSEOSpider\screenshots-XXXXXXXXXXXXXXX”文件夹中查看,并且可以通过“批量导出 > Web > 屏幕截图”顶级菜单导出,以节省导航、复制和粘贴的时间。
JavaScript 错误报告
配置 > Spider > 渲染 > JavaScript > JavaScript 错误报告
此设置启用 JavaScript 错误报告,以便在“JavaScript”选项卡中的相应过滤器下捕获和报告。
可以在下部“Chrome 控制台日志”选项卡中查看详细的 JavaScript 错误、警告和问题,并通过“批量导出 > JavaScript > 具有 JavaScript 问题的页面”进行批量导出。
扁平化 Shadow DOM
配置 > Spider > 渲染 > JavaScript > 扁平化 Shadow DOM
Google 能够扁平化和索引 Shadow DOM 内容,作为页面渲染 HTML 的一部分。默认情况下启用此配置,但可以禁用。
扁平化 iframes
配置 > Spider > 渲染 > JavaScript > 扁平化 iframes
如果条件允许,Google 会将 iframe 内联到父页面的渲染 HTML 中的 div 中。这些条件包括设置高度、具有移动视口以及不进行 noindex。我们尝试模仿 Google 的行为。默认情况下启用此配置,但可以禁用。
存档网站
配置 > Spider > 渲染 > JavaScript > 存档网站
启用后,SEO Spider 将下载并存储在抓取期间找到的所有 HTML 和资源,并将文件保存在本地。
有两个选项 –
- 分层 URL 存档 – 网站将根据网站的目录文件路径在本地存储。这些文件未压缩。
- WARC – 用于存档网站的 Web ARChive 标准格式。WARC 文件格式可以在许多开源工具中查看,并且是压缩的。
存档的文件可以在 C:\Users\您的名字\.ScreamingFrogSEOSpider\ProjectInstanceData\\results_\siteArchive 文件夹中查看,并通过“批量导出 > Web > 存档网站”批量导出。
您可以通过右键单击并选择“在浏览器中打开存档页面”来在应用程序中查看存档的页面,以查看离线版本。
AJAX 超时
配置 > Spider > 渲染 > JavaScript > AJAX 超时
这是 SEO Spider 在认为页面已加载之前,应允许 JavaScript 执行的时间(以秒为单位)。此计时器在 Chromium 浏览器加载网页和任何引用的资源(例如 JS、CSS 和图像)后开始。
实际上,Google 比上面提到的 5 秒标记更灵活,他们会根据页面加载内容所需的时间进行调整,同时考虑网络活动和缓存等因素。但是,Google 显然不会永远等待,因此您希望被抓取和索引的内容需要快速可用,否则它将根本不会被看到。
5 秒规则对于用户和 Googlebot 来说都是一个合理的经验法则。
窗口大小
配置 > Spider > 渲染 > JavaScript > 窗口大小
这设置了 JavaScript 渲染 模式下的视口大小,该大小可以在 渲染页面屏幕截图 中看到,这些截图是在“渲染页面”选项卡中捕获的。
对于“Googlebot Mobile:智能手机”和“Googlebot Desktop”窗口大小,SEO Spider 模拟 Googlebot 的行为并调整页面大小 - 因此它非常长,可以捕获尽可能多的数据。Google 将拉伸页面,以加载和捕获任何其他内容。
SEO Spider 将以 411×731 像素加载移动设备页面,或以 1024×768 像素加载桌面设备页面,然后将长度调整到最大 8,192 像素。这是我们目前能够在内置 Chromium 浏览器中捕获的限制。Google 能够将大小调整到最大 12,140 像素的高度。
在极少数情况下,窗口大小会影响渲染的 HTML。例如,某些网站可能在较小的视口上没有某些元素,这会影响诸如字数统计和链接之类的结果。
对于其他设备窗口大小,所选的视口将用于渲染任何内容、链接和屏幕截图 - 而不会调整为更长的视口。
Spider 高级选项卡
Cookie 存储
配置 > Spider > 高级 > Cookie 存储
Google 在没有 cookie 的情况下以无状态方式抓取网络,但会在页面加载期间接受它们。某些网站只有在接受 cookie 时才能查看,并且在禁用接受 cookie 时会失败。
默认情况下,SEO Spider 将仅为“会话”接受 cookie。这意味着它们被接受用于页面加载,然后清除它们,并且不会以与 Googlebot 相同的方式用于其他请求。
您可以选择将 cookie 存储切换为“持久”,这将记住跨会话的 cookie,或者选择“不存储”,这意味着根本不会接受它们。
对于“持久”,cookie 按抓取存储并在爬网器线程之间共享。保存抓取时不会存储 cookie,因此从保存的 .seospider 文件恢复抓取将不会保留先前使用的 cookie。
Cookie 在新抓取开始时重置。
忽略问题的非索引 URL
配置 > Spider > 高级 > 忽略问题的非索引 URL
启用后,如果页面可索引,SEO Spider 将仅填充与问题相关的过滤器。这包括页面标题、Meta 描述、Meta 关键词、H1 和 H2 选项卡下的所有过滤器以及以下其他问题 -
- “内容少的页面”在“内容”选项卡中。
- “缺失”、“验证错误”和“验证警告”在“结构化数据”选项卡中。
- “孤立 URL”在“站点地图”选项卡中。
- “无 GA 数据”在“分析”选项卡中。
- “无搜索分析数据”在“搜索控制台”选项卡中。
- “具有高抓取深度的页面”在“链接”选项卡中。
例如,这意味着如果 URL 设置为“noindex”且因此不可索引,则不会被视为“重复”、“超过 X 个字符”或“低于 X 个字符”。
如果您正在抓取一个具有站点范围 noindex 的暂存网站,我们建议禁用此功能。
忽略重复过滤器的分页 URL
配置 > Spider > 高级 > 忽略重复过滤器的分页 URL
启用后,在序列中具有 rel="prev" 的 URL 将不会被视为页面标题、Meta 描述、Meta 关键词、H1 和 H2 选项卡下的“重复”过滤器。只有分页序列中的第一个 URL(具有 rel="next" 属性)才会被考虑。
这意味着分页 URL 不会被视为与系列中的第一页具有“重复”页面标题。这是正常且预期的行为,因此,此配置意味着这不会被标记为问题。
始终遵循重定向
配置 > Spider > 高级 > 始终遵循重定向
此功能允许 SEO Spider 遵循重定向,直到列表模式下的最终重定向目标 URL,而忽略抓取深度。这对于站点迁移特别有用,在站点迁移中,URL 可能会执行多次 3XX 重定向,然后才能到达其最终目的地。
要在站点迁移中查看重定向,我们建议使用“所有重定向”报告。
请参阅我们的“如何使用列表模式”指南,了解有关如何利用此配置的更多信息。
始终遵循 canonicals
配置 > Spider > 高级 > 始终遵循 Canonicals
此功能允许 SEO Spider 遵循 canonicals,直到列表模式下的最终重定向目标 URL,而忽略抓取深度。这对于站点迁移特别有用,在站点迁移中,canonicals 可能会被多次规范化,然后才能到达其最终目的地。
要查看 canonicals 链,我们建议启用此配置并使用“canonical 链”报告。
请参阅我们的“如何使用列表模式”指南,了解有关如何像“始终遵循重定向”一样利用此配置的更多信息。
尊重 noindex
配置 > Spider > 高级 > 尊重 Noindex
此选项意味着具有“noindex”的 URL 不会在 SEO Spider 中报告。这些 URL 仍将被抓取,并且它们的出站链接将被跟踪,但它们不会出现在工具中。
尊重 canonical
配置 > Spider > 高级 > 尊重 Canonical
此选项意味着已规范化为另一个 URL 的 URL 不会在 SEO Spider 中报告。这些 URL 仍将被抓取,并且它们的出站链接将被跟踪,但它们不会出现在工具中。
尊重 next/prev
配置 > Spider > 高级 > 尊重 Next/Prev
此选项意味着在序列中具有 rel="prev" 的 URL 不会在 SEO Spider 中报告。只有分页序列中的第一个 URL(具有 rel="next" 属性)才会被报告。
这些 URL 仍将被抓取,并且它们的出站链接将被跟踪,但它们不会出现在工具中。
尊重 HSTS 策略
配置 > Spider > 高级 > 尊重 HSTS 策略
HTTP 严格传输安全 (HSTS) 是一种标准,在 RFC 6797 中定义,Web 服务器可以通过该标准向客户端声明只能通过 HTTPS 访问它。
客户端(在本例中为 SEO Spider)然后将通过 HTTPS 发出所有未来的请求,即使在跟踪到 HTTP URL 的链接时也是如此。发生这种情况时,SEO Spider 将显示状态代码 307,状态为“HSTS 策略”,重定向类型为“HSTS 策略”。
您可以禁用此功能并查看重定向背后的“真实”状态代码(例如 301 永久重定向)。请在我们的“SEO 抓取 HSTS 和 307 重定向指南”文章中查看更多详细信息。
尊重自引用 Meta Refresh
配置 > Spider > 高级 > 尊重自引用 Meta Refresh
您可以禁用“尊重自引用 Meta Refresh”配置,以停止将自引用 meta refresh URL 视为“不可索引”。
站点出于各种原因具有自引用 meta refresh 是相当常见的,并且通常这不会影响页面的索引。但是,应该进一步调查,因为它正在重定向到自身,这就是它被标记为“不可索引”的原因。
从 img srcset 属性中提取图像
配置 > Spider > 高级 > 从 IMG SRCSET 属性中提取图像
如果启用,将从 <img> 标记的 srcset 属性中提取图像。在下面的示例中,这将是 image-1x.png 和 image-2x.png 以及 image-src.png。
<img src="image-src.png" srcset="image-1x.png 1x, image-2x.png 2x" alt="Retina 友好的图像" />
抓取片段标识符
配置 > Spider > 高级 > 抓取片段标识符
如果启用,SEO Spider 将抓取带有哈希片段的 URL,并将它们视为单独的唯一 URL。
https://www.screamingfrog.co.uk/#this-is-treated-as-a-separate-url/
默认情况下,SEO Spider 将忽略哈希值中的任何内容,例如搜索引擎。但是,当分析页面内跳转链��接和书签时,这可能很有用。
执行 HTML 验证
配置 > Spider > 高级 > 执行 HTML 验证
如果启用,SEO Spider 将检查可能导致抓取和索引问题的基本 HTML 错误。此配置将填充“验证”选项卡过滤器以及页面标题、Meta 描述、Canonicals 等选项卡中的各种“<head> 外部”过滤器。
绿色托管碳计算
配置 > Spider > 高级 > 绿色托管碳计算
此配置用于碳足迹计算和评级。如果您的网站托管在绿色能源上运行,请启用该配置。
您目前可以通过 Green Web Foundation 的 Green Web Check 手动检查此项。
假设页面是 HTML
配置 > Spider > 高级 > 假设页面是 HTML
启用后,任何没有内容类型的 URL 都将被假定为 HTML 并被抓取。
响应超时
配置 > Spider > 高级 > 响应超时(秒)
默认情况下,SEO Spider 将等待 20 秒以从 URL 获取任何类型的 HTTP 响应。您可以增加等待时间,以适应非常慢的网站。
5XX 响应重试
配置 > Spider > 高级 > 5XX 响应重试
此选项提供了自动重试 5XX 响应的功能。通常,这些响应可能是暂时的,因此重试 URL 可能会提供 2XX 响应。
Spider 首选项选项卡
页面标题和 Meta 描述宽度
配置 > Spider > 首选项 > 页面标题/Meta 描述宽度
此选项提供了控制 SEO Spider 过滤器中页面标题和 meta 描述选项卡中的字符和像素宽度限制的功能。
例如,更改页面标题宽度的最小像素宽度默认数字“200”,将更改“页面标题”选项卡中的“低于 200 像素”过滤器。这允许您根据自己的首选项设置自己的字符和像素宽度。
请注意 - 这不会更新此时的 SERP 片段预览,只会更新选项卡中的过滤器。
链接首选项
配置 > Spider > 首选项 > 链接
这些选项提供了控制何时触发“具有高外部出站链接的页面”、“具有高内部出站链接的页面”、“具有高抓取深度的页面”和“内部出站链接中非描述性锚文本”过滤器在“链接”选项卡下的功能。
例如,将“高内部出站链接”默认值从 1,000 更改为 2,000 将意味着页面需要 2,000 个或更多内部出站链接才能出现在“链接”选项卡中的此过滤器下。
其他字符首选项
配置 > Spider > 首选项 > 其他
这些选项提供了控制 URL、h1、h2、图像 alt 文本、最大图像大小和低内容页面过滤器在其各自选项卡中的字符长度的功能。
例如,如果将“最大图像大小千字节”从 100 调整为“200”,则只有超过 200kb 的图像才会出现在“图像 > 超过 X kb”选项卡和过滤器中。
其他配置选项
内容区域
配置 > 内容 > 区域
您可以指定用于字数统计、近似重复内容分析以及拼写和语法检查的内容区域。这可以帮助将分析重点放在页面的主要内容区域,从而避免已知的样板文本。
内容区域设置不会影响链接发现,它仅用于内容。
默认情况下,SEO Spider 将仅考虑网页的 body HTML 元素中包含�的文本。默认情况下,nav 和 footer HTML 元素都被排除在外,以帮助将内容区域的重点放在页面的主要内容上。
但是,并非所有网站都使用这些 HTML5 语义元素构建,有时进一步细化分析中使用的内容区域很有用。您可以添加 HTML 元素、类或 ID 的列表,以排除或包含用于内容的内容。
例如,Screaming Frog 网站在 nav 元素之外有一个移动菜单,默认情况下该菜单包含在内容分析中。在检查重复内容时,可以在下面显示的“重复详细信息”选项卡(以及“拼写和语法详细信息”选项卡)的内容预览中看到该移动菜单。
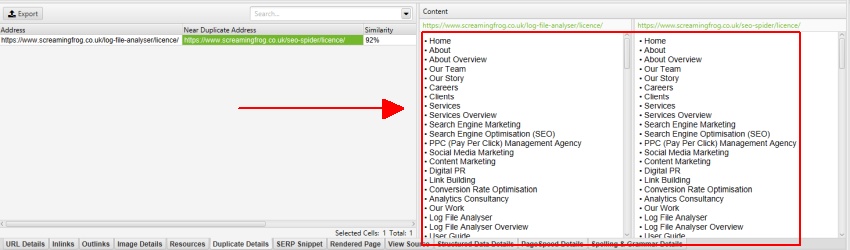
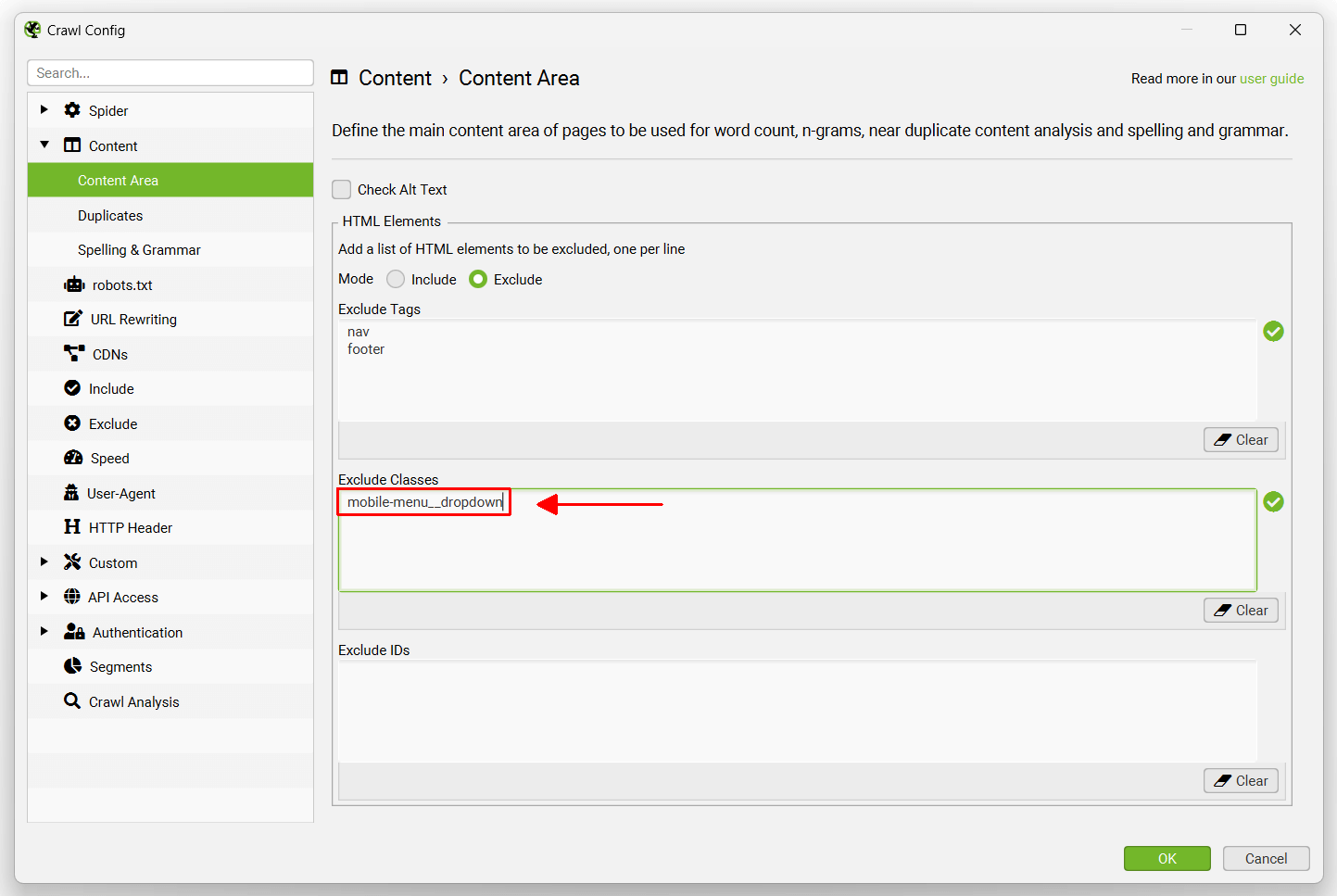
通过右键单击并查看我们网站的 HTML 源代码,我们可以看到此菜单具有“mobile-menu__dropdown”类。然后可以在“排除类”框中排除“mobile-menu__dropdown” -
然后,移动菜单将从近重复分析中移除,并且内容会显示在重复详情标签(以及拼写和语法和字数统计)中。
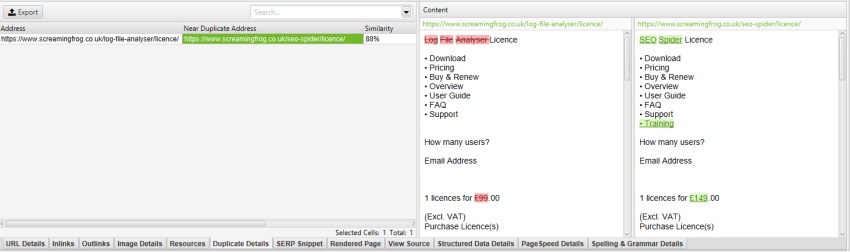
内容区域设置可以在抓取后进行调整,以进行近重复内容分析以及拼写和语法检查。近重复项将需要重新运行“抓取分析”,以更新结果,而拼写和语法检查则需要通过右侧的“Spelling & Grammar(拼写和语法)”标签或下方的“Spelling & Grammar Details(拼写和语法详情)”标签刷新其分析。
重复项
Configuration > Content > Duplicates(配置 > 内容 > 重复项)
SEO Spider 能够找到页面彼此完全相同的精确重复项,以及不同页面之间存在部分内容匹配的近重复项。这两者都可以在“Content(内容)”标签和相应的“Exact Duplicates(精确重复项)”和“Near Duplicates(近重复项)”过滤器中查看。
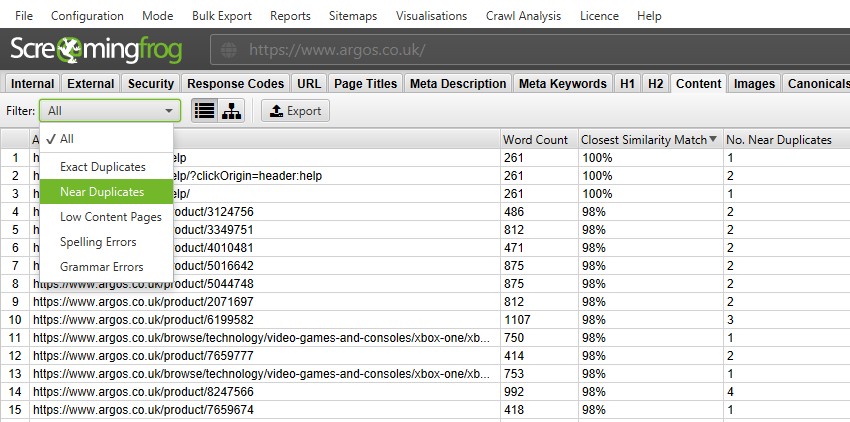
默认情况下会发现精确重复页面。要检查“近重复项”,必须启用配置,以便 SEO Spider 存储每个页面的内容。
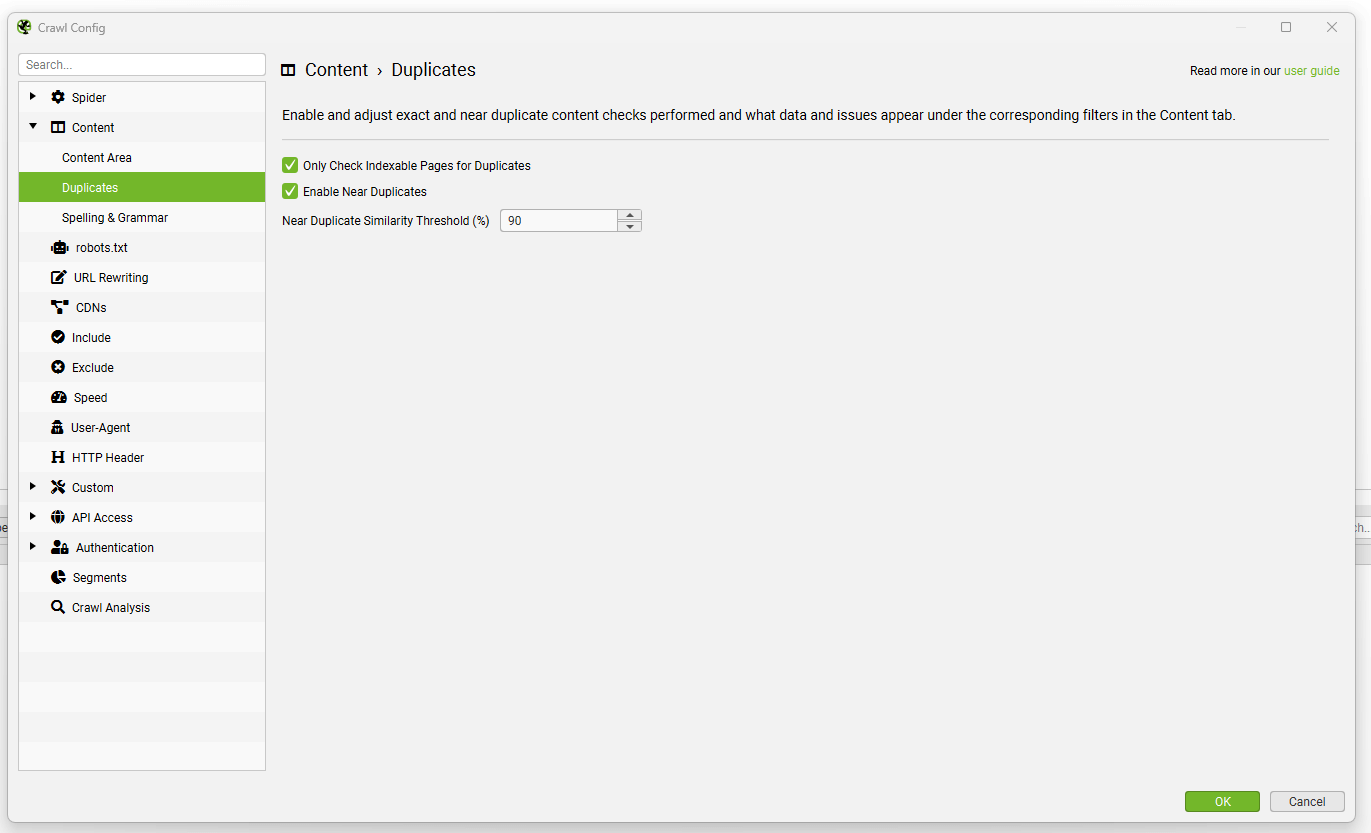
SEO Spider 将使用 minhash 算法识别相似度匹配度为 90% 的近重复项,可以调整该算法以查找相似度阈值较低的内容。
SEO Spider 还将仅检查“Indexable(可索引)”页面中的重复项(对于精确重复项和近重复项)。
这意味着,如果您有两个相同的 URL,但其中一个已规范化为另一个 URL(因此“不可索引”),则不会报告此情况,除非禁用此选项。
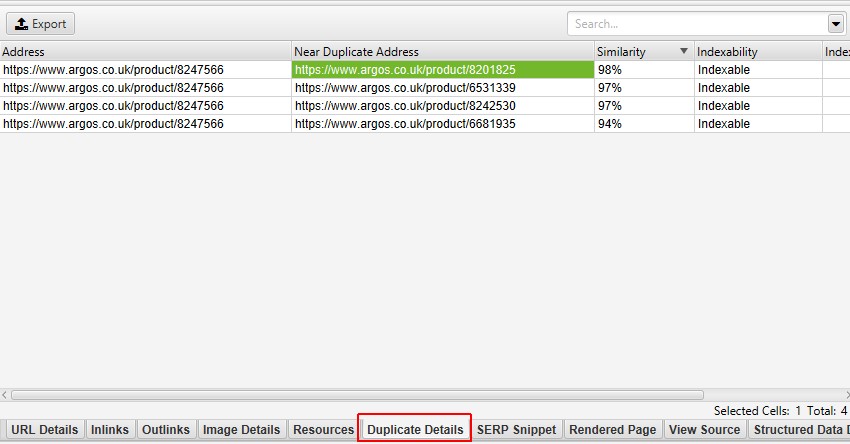
近重复项需要填充 抓取分析 后才能显示,并且可以在“Duplicate Details(重复详情)”下方的标签中查看有关重复项的更多详细信息。这将显示识别出的每个近重复 URL 及其相似度匹配度。
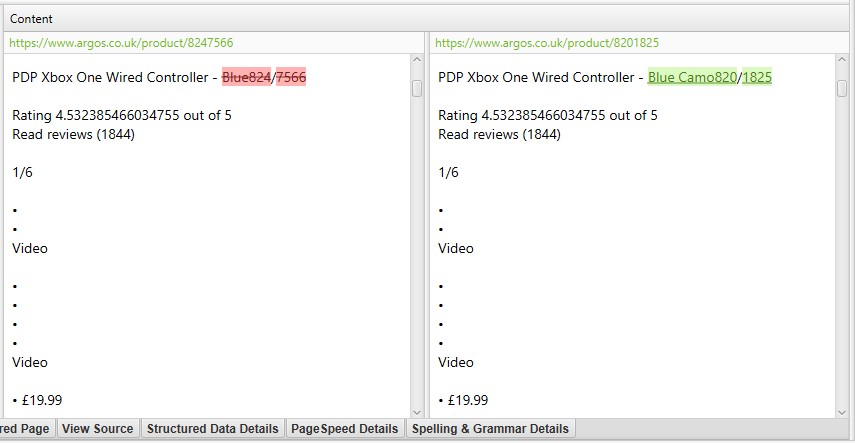
单击“Duplicate Details(重复详情)”标签中的“Near Duplicate Address(近重复地址)”也会显示页面之间发现的近重复内容,并突出显示差异。
用于近重复分析的内容区域可以通过“Configuration > Content > Area(配置 > 内容 > 区域)”进行调整。您可以添加 HTML 元素、类或 ID 的列表,以排除或包含用于内容的元素。
近重复内容阈值和分析中使用的内容区域都可以在抓取后进行更新,并且可以重新运行抓取分析以优化结果,而无需重新抓取。
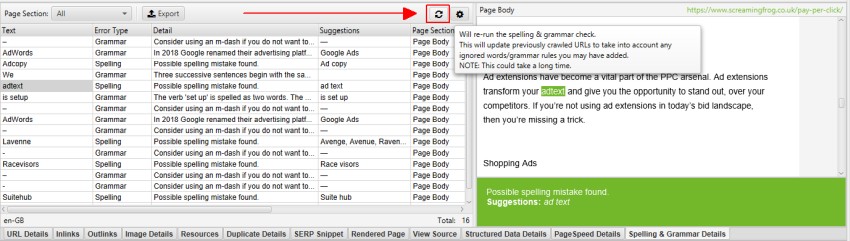
拼写和语法
Configuration > Content > Spelling & Grammar(配置 > 内容 > 拼写和语法)
SEO Spider 能够在抓取中对 HTML 页面执行拼写和语法检查。目前不��支持其他内容类型,但将来可能会支持。
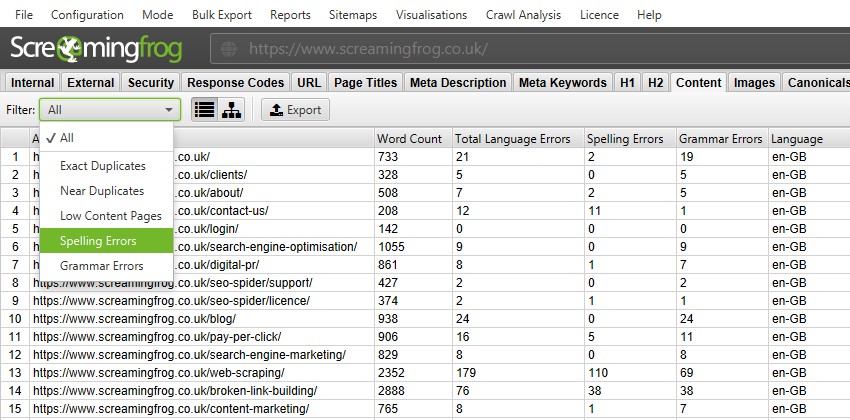
默认情况下,拼写和语法检查处于禁用状态,需要启用拼写和语法检查,才能在“Content(内容)”标签和相应的“Spelling Errors(拼写错误)”和“Grammar Errors(语法错误)”过滤器中显示拼写和语法错误。
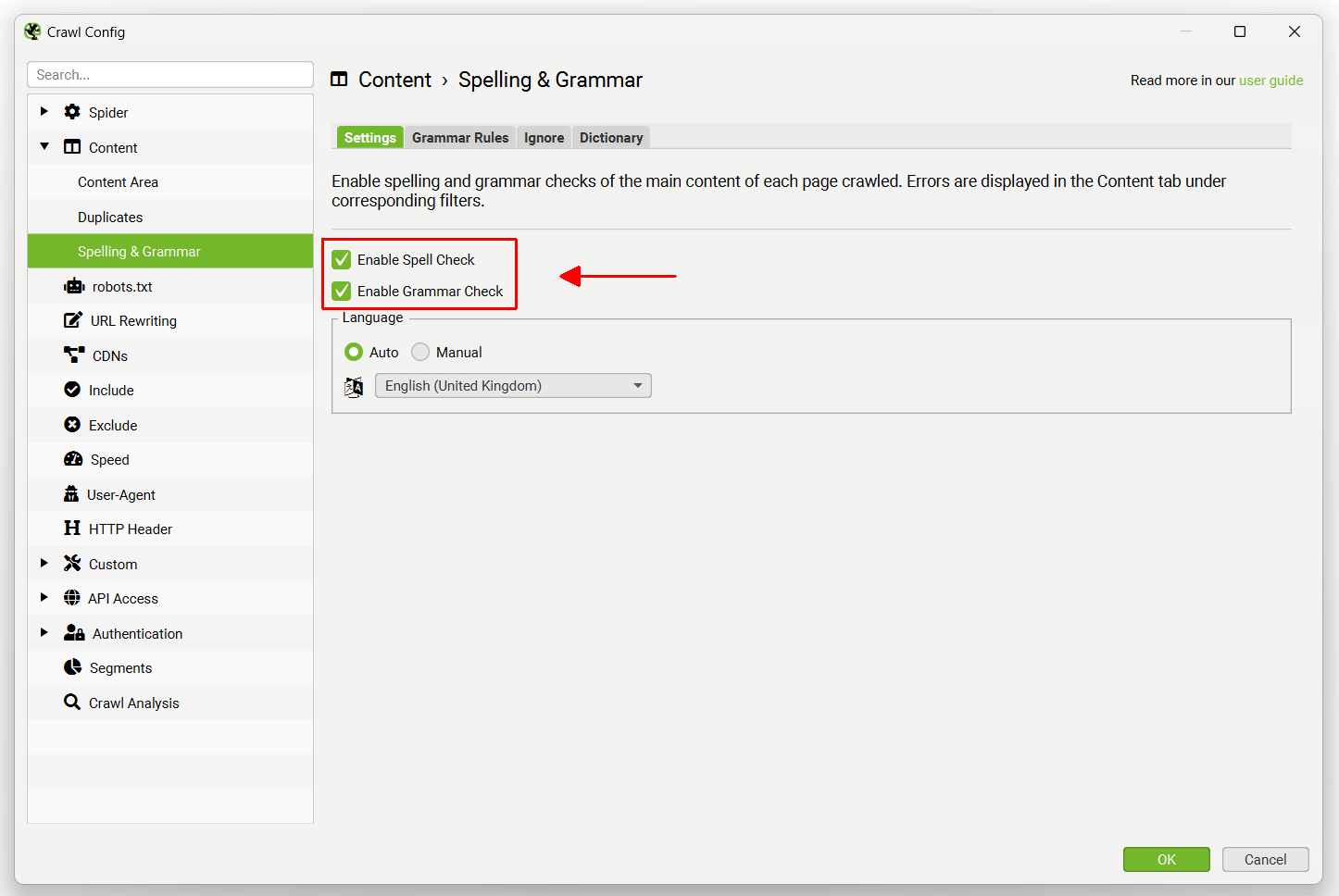
拼写和语法功能将自动识别页面上使用的语言(通过 HTML 语言属性),但也允许您在需要时在配置中手动选择语言。
它支持 39 种语言,其中包括:
- Arabic(阿拉伯语)
- Asturian(阿斯图里亚斯语)
- Belarusian(白俄罗斯语)
- Breton(布列塔尼语)
- Catalan(加泰罗尼亚语)
- Chinese(中文)
- Danish(丹麦语)
- Dutch(荷兰语)
- English(英语)(澳大利亚、加拿大、新西兰、南非、美国、英国)
- French(法语)
- Galician(加利西亚语)
- German(德语)(奥地利、德国、瑞士)
- Greek(希腊语)
- Italian(意大利语)
- Japanese(日语)
- Khmer(高棉语)
- Persian(波斯语)(阿富汗、伊朗)
- Polish(波兰语)
- Portuguese(葡萄牙语)(安哥拉、巴西、莫桑比克、葡萄牙)
- Romanian(罗马尼亚语)
- Russian(俄语)
- Slovak(斯洛伐克语)
- Solvenian(斯洛文尼亚语)
- Spanish(西班牙语)
- Swedish(瑞典语)
- Tagalog(塔加路族语)
- Tamil(泰米尔语)
- Ukranian(乌克兰语)
如果您希望看到支持拼写和语法的新语言,请参阅我们的常见问题解答。
下方的“Spelling & Grammar Details(拼写和语法详情)”标签显示错误、类型(拼写或语法)、详细信息,并提供更正问题的建议。详细信息标签的右侧还显示页面文本的可视化效果以及识别出的错误。
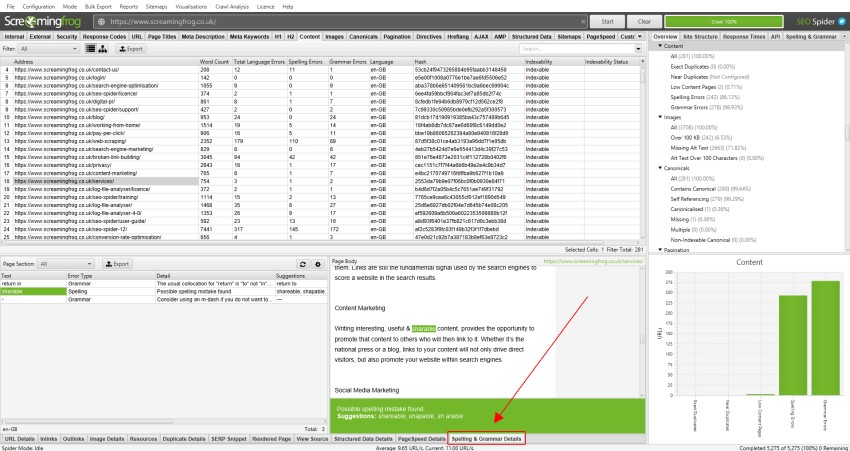
右侧窗格“Spelling & Grammar(拼写和语法)”标签显示发现的前 100 个唯一错误以及它影响的 URL 数量。这有助于查找模板中的错误,以及构建您的字典或忽略列表。您可以右键单击并选择“Ignore grammar rule(忽略语法规则)”、“Ignore All(全部忽略)”或“Add to Dictionary(添加到字典)”(如果适用)。
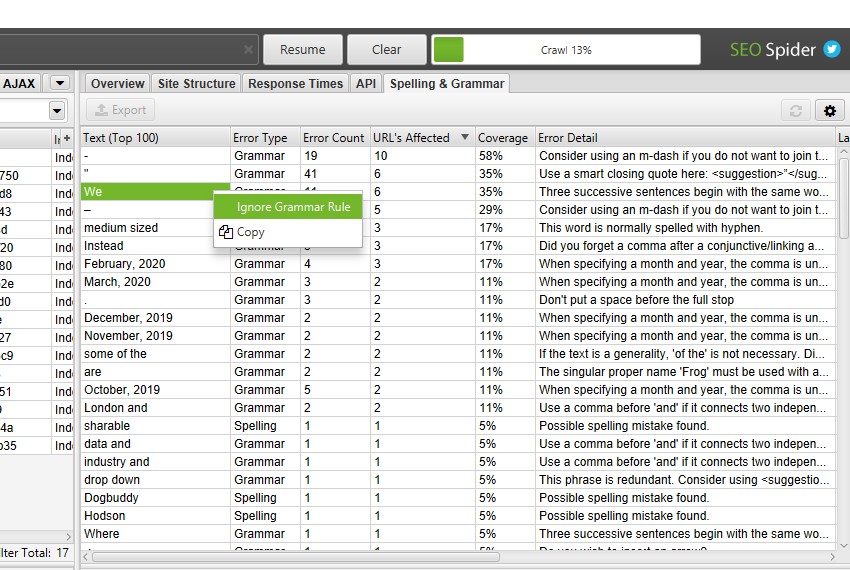
拼写和语法配置
“grammar rules(语法规则)”配置允许您启用和禁用使用的特定语法规则。您可以右键单击并“Ignore grammar rule(忽略语法规则)”在抓取期间识别出的特定语法问题。
“Ignore(忽略)��”配置允许您忽略抓取的单词列表。这仅适用于特定的抓取,不会在所有抓取中记住。您可以右键单击并“Ignore All(全部忽略)”在抓取期间发现的拼写错误。
“dictionary(字典)”允许您忽略每次执行抓取的单词列表。此列表存储在相关字典中,并记住每次执行的抓取。可以随时为每个字典添加和删除单词。您可以右键单击并“Add to Dictionary(添加到字典)”在抓取中识别出的拼写错误。
用于拼写和语法的内容区域可以通过“Configuration > Content > Area(配置 > 内容 > 区域)”进行调整。您可以添加 HTML 元素、类或 ID 的列表,以排除或包含用于分析的内容。
分析中使用的语法规则、忽略单词、字典和内容区域设置都可以在抓取后(或暂停时)进行更新,并且可以重新运行拼写和语法检查以优化结果,而无需重新抓取。
嵌入
Configuration > Content > Embeddings(配置 > 内容 > 嵌入)
SEO Spider 能够利用 AI 提供商生成的向量嵌入来识别语义相似的页面和低相关性内容,以及语义搜索和内容集群图可视化。
要启用此功能,首先导航到“Config > API Access > AI(配置 > API 访问 > AI)”,然后选择一个 AI 提供商来生成嵌入。从 OpenAI、Gemini 和 Ollama 中进行选择。确保您已按照上述指南设置帐户并拥有 API 密钥。
选择 AI 提供商后,导航到“Prompt Configuration(提示配置)”,选择“Add from Library(从库中添加)”,然后选择相关的嵌入预设。
以 Gemini 为例,这意味着选择“Extract Semantic Embeddings from Page(从页面提取语义嵌入)”,该预设将添加为提示。
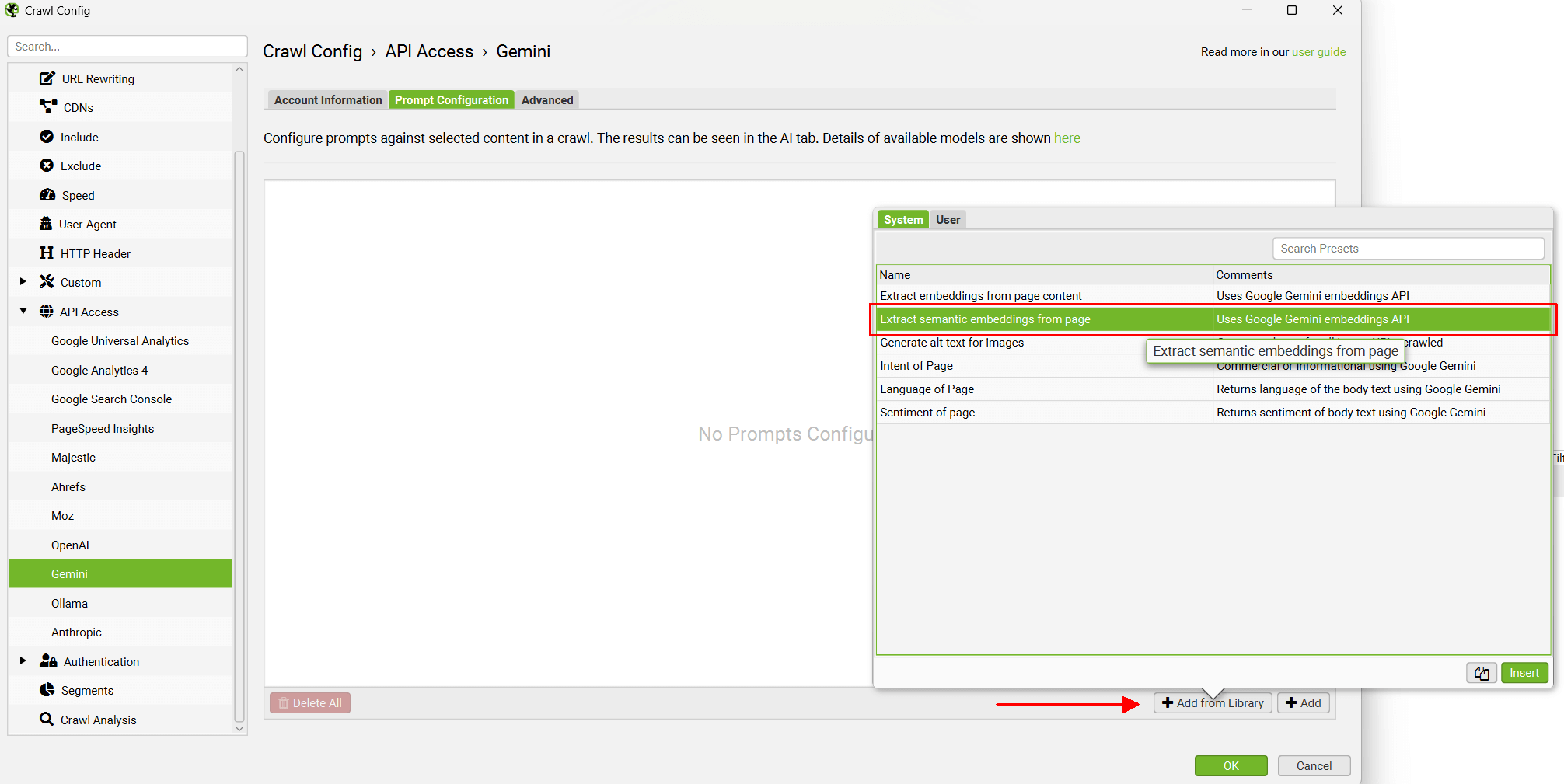
将显示提示,并显示一条错误消息,解释说还必须配置“Store HTML(存储 HTML)”。
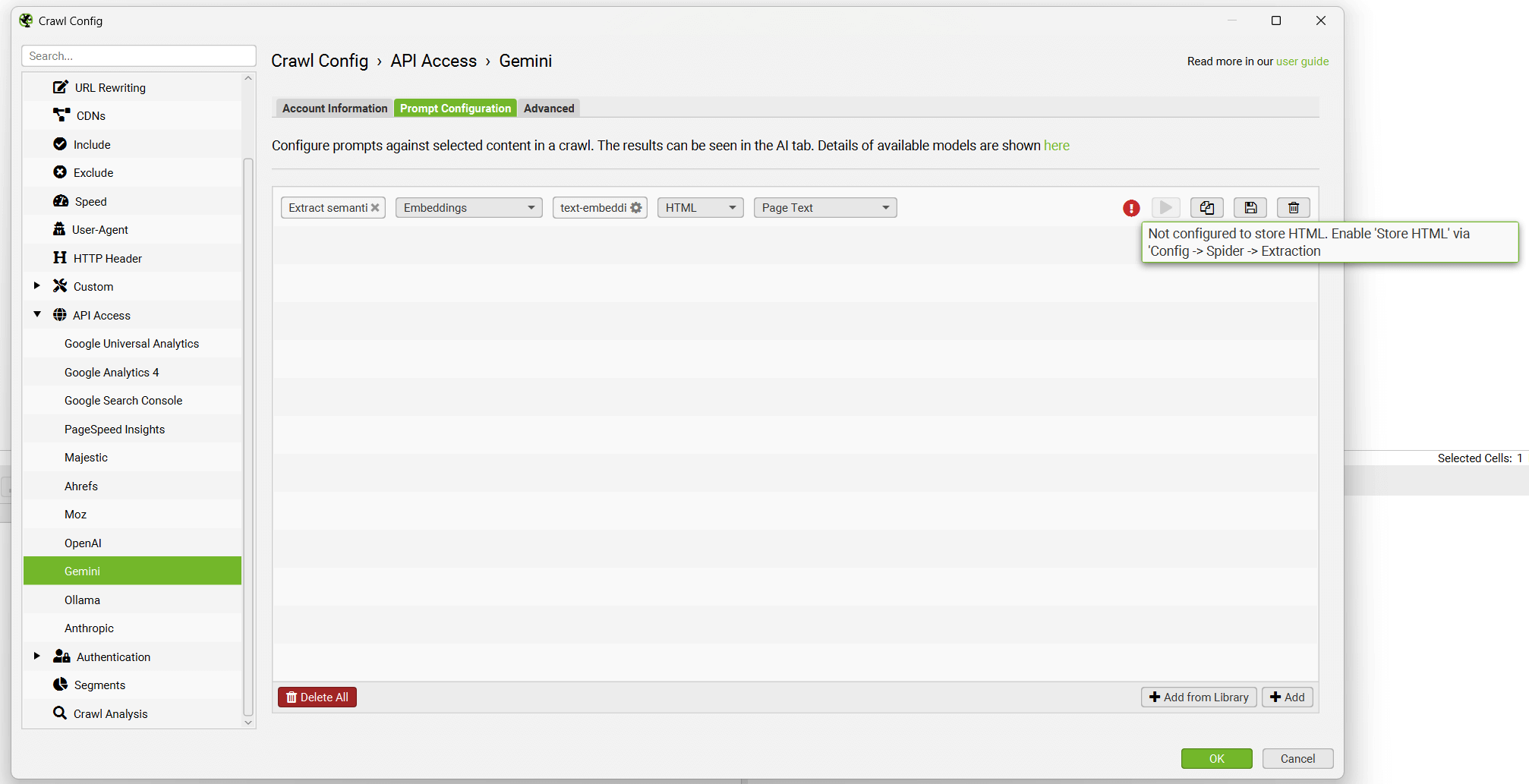
在配置 Store HTML 选项之前,请记住在“Account Information(帐户信息)”下“Connect(连接)”到 API。
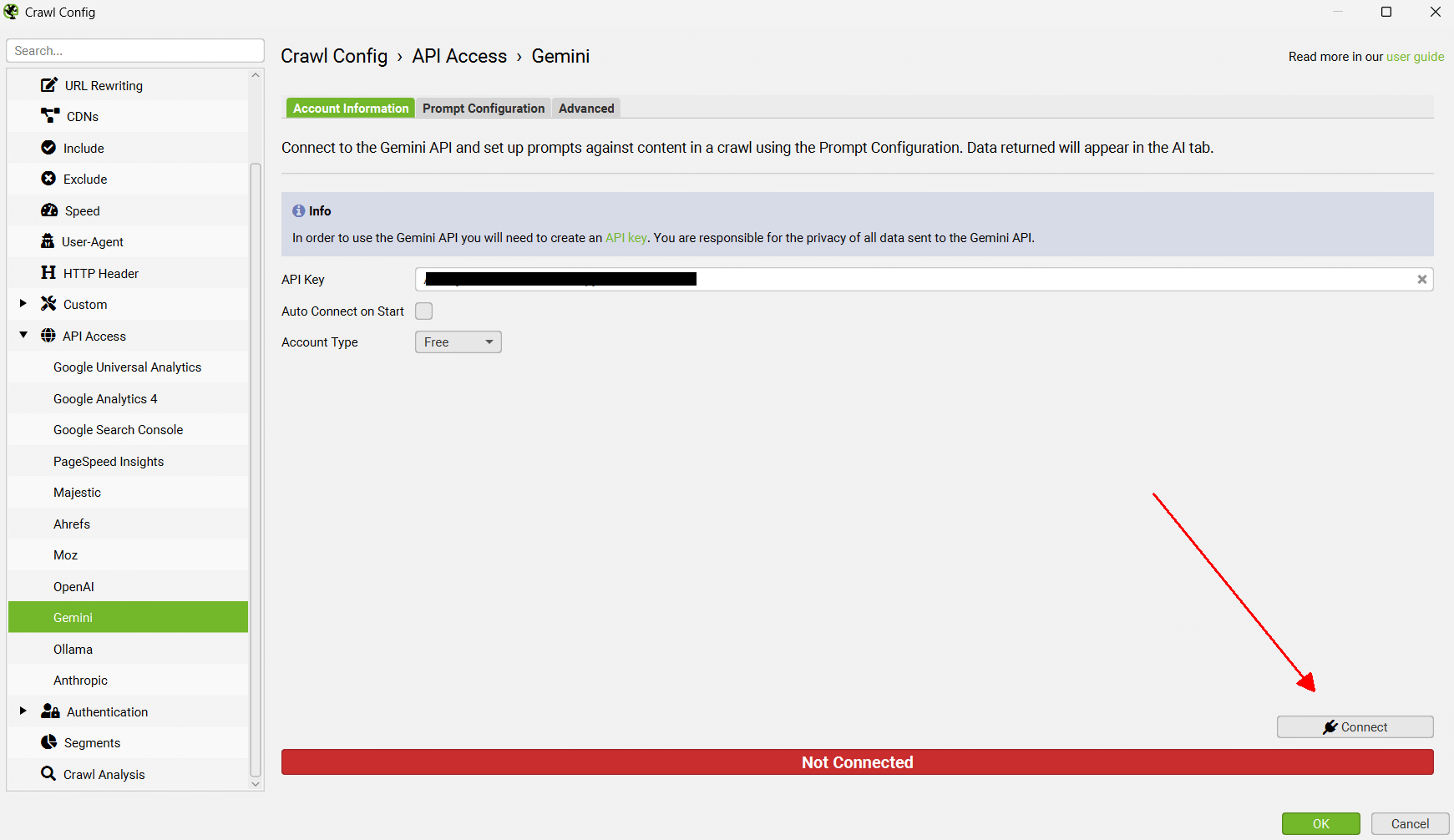
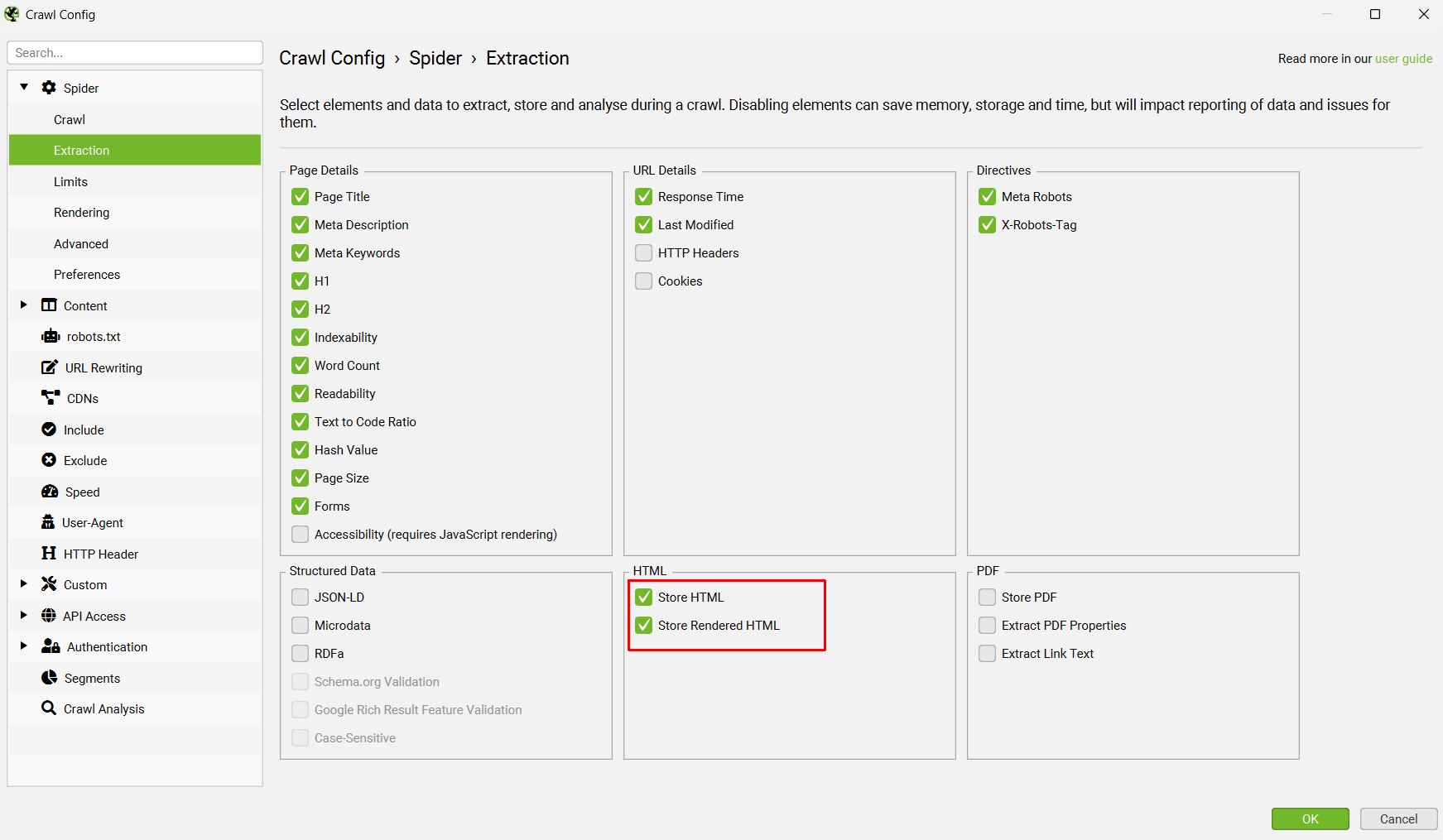
现在转到“Config > Spider > Extraction(配置 > Spider > 提取)”,然后启用“Store HTML(存储 HTML)”和“Store Rendered HTML(存储渲染的 HTML)”,以便存储页面文本以用于向量嵌入。
设置完成后,通过“Config > Content > Embeddings(配置 > 内容 > 嵌入)”重新访问 Embeddings 配置。
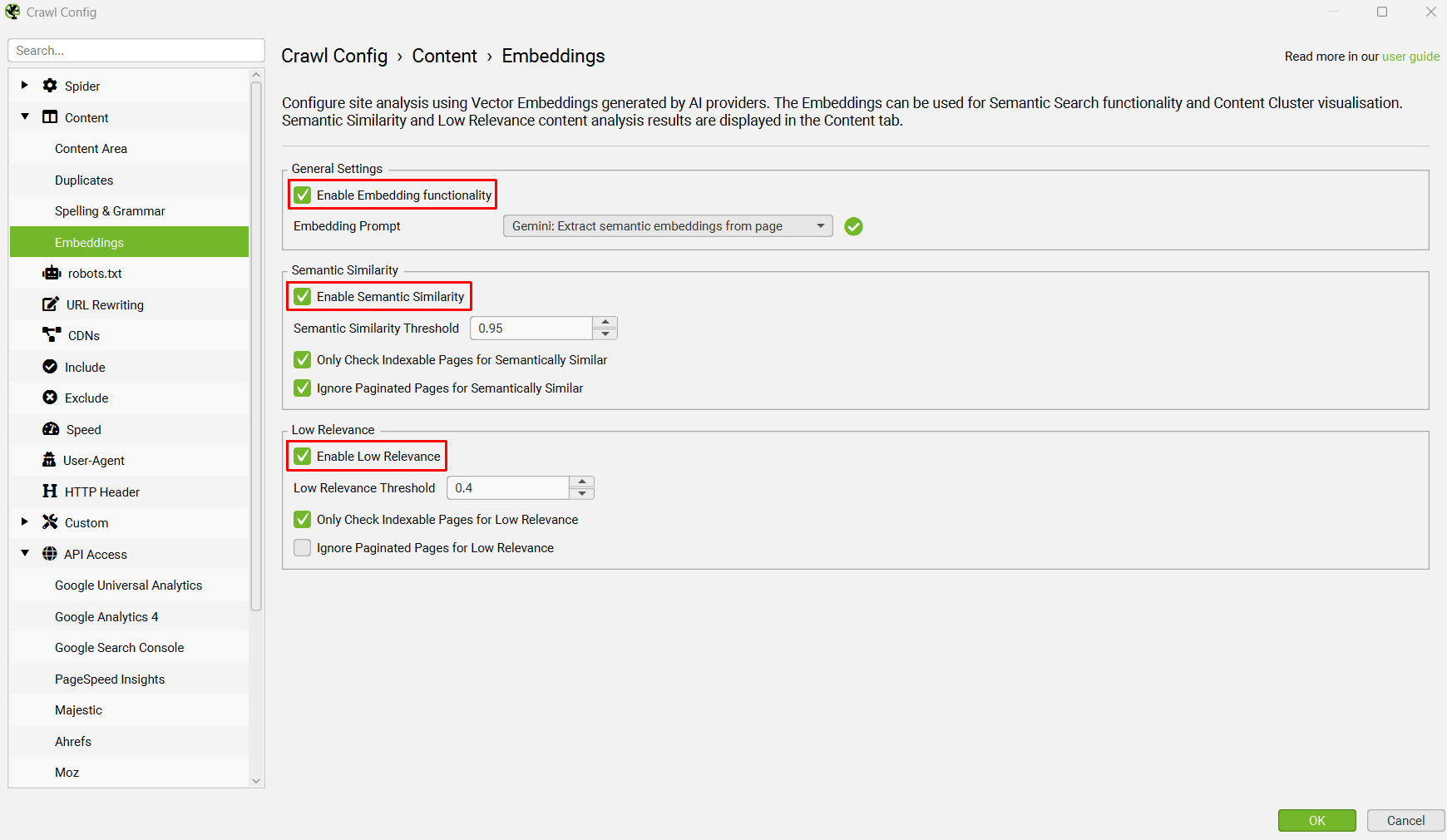
单击“Enable Embedding functionality(启用嵌入功能)”,设置的提示应自动显示在嵌入提示下拉列表中。启用“Semantic Similarity(语义相似性)”和“Low Relevance(低相关性)”以填充 Content 标签中的相关列和过滤器。
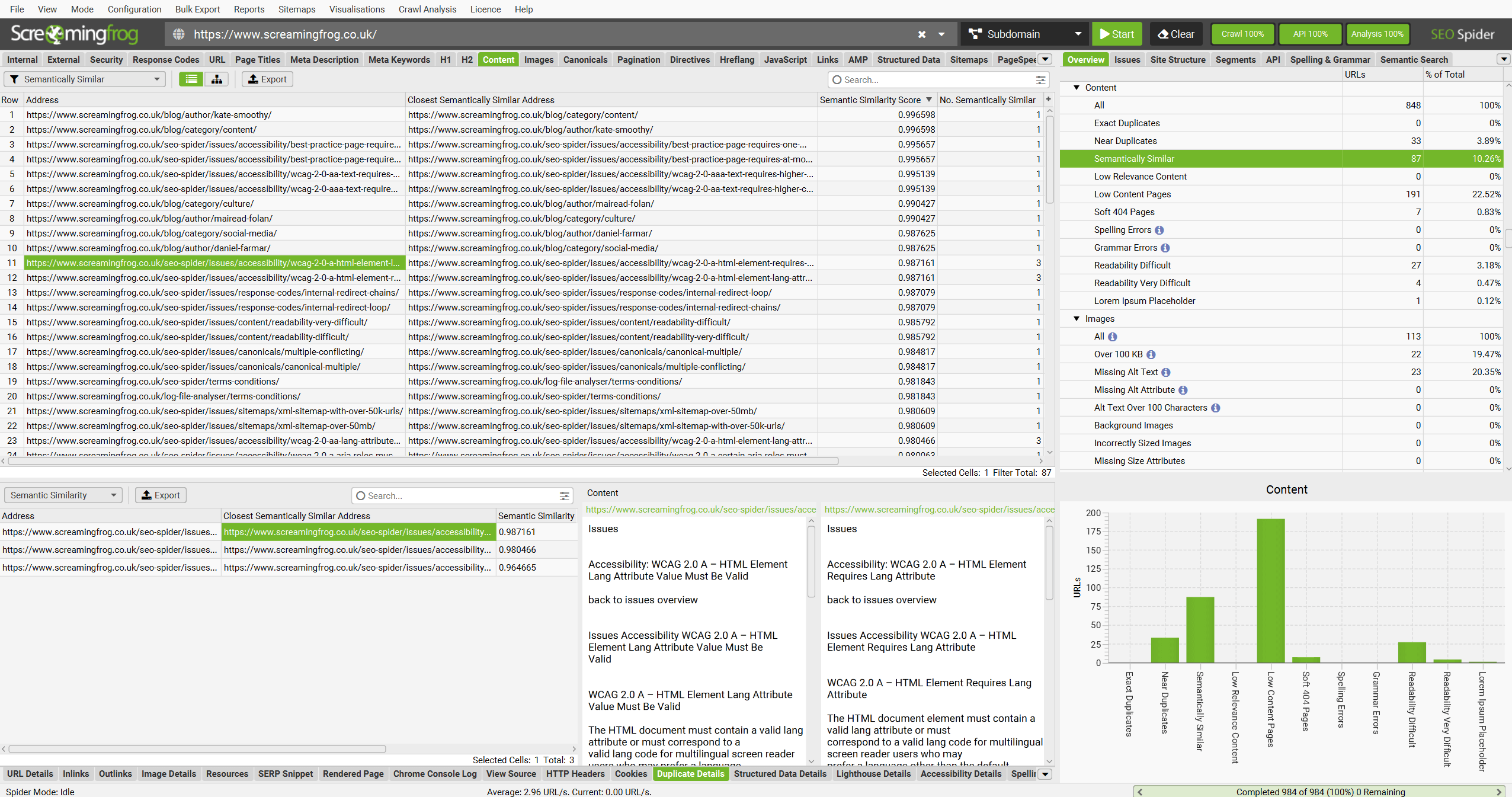
抓取完成后,运行抓取分析,然后“Semantically Similar(语义相似)”和“Low Relevance Content(低相关性内容)”过滤器将填充在 Content 标签中。
请参阅我们的教程如何识别语义相似的页面和异常值。
嵌入还将用于右侧的“Semantic Search(语义搜索)”和“Content Cluster Diagram(内容集群图)”。
Robots.txt
Configuration > Robots.txt(配置 > Robots.txt)
默认情况下,SEO Spider 将遵守 robots.txt 协议,并设置为“Respect robots.txt(遵守 robots.txt)”。这意味着,如果通过 robots.txt 禁止抓取站点,则 SEO Spider 将无法抓取该站点。
此设置可以调整为“Ignore robots.txt(忽略 robots.txt)”或“Ignore robots.xt but report status(忽略 robots.xt 但报告状态)”。
Ignore robots.txt(忽略 robots.txt)
“Ignore robots.txt(忽略 robots.txt)”选项允许您忽略此协议,这由用户自行负责。此选项实际上意味着 SEO Spider 甚至不会下载 robots.txt 文件。因此,这也意味着所有 robots 指令都将被完全忽略。
Ignore robots.xt but report status(忽略 robots.xt 但报告状态)
“Ignore robots.txt, but report status(忽略 robots.txt 但报告状态)”配置意味着网站的 robots.txt 已下载并在 SEO Spider 中报告。但是,其中的指令将被忽略。这允许您抓取网站,但仍然可以看到哪些页面应该被阻止抓取。
Show Internal URLs Blocked By Robots.txt(显示 Robots.txt 阻止的内部 URL)
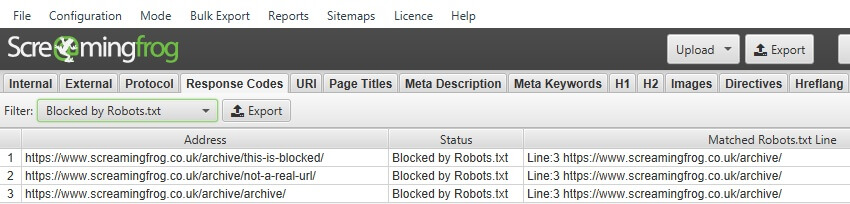
默认情况下,robots.txt 阻止的内部 URL 将显示在“Internal(内部)”标签中,状态代码为“0”,状态为“Blocked by Robots.txt(被 Robots.txt 阻止)”。要隐藏界面中的这些 URL,请取消选择此选项。如果选中“Ignore robots.txt(忽略 robots.txt)”,则此选项不可用。
您还可以在“Response Codes(响应代码)”标签和“Blocked by Robots.txt(被 Robots.txt 阻止)”过滤器下查看 robots.txt 阻止的内部 URL。这还将显示针对每个被阻止的 URL 的 disallow 的 robots.txt 指令(“matched robots.txt line(匹配的 robots.txt 行)”列)。
Show External URLs Blocked By Robots.txt(显示 Robots.txt 阻止的外部 URL)
默认情况下,robots.txt 阻止的外部 URL 已隐藏。要使用状态代码“0”和状态“Blocked by Robots.txt(被 Robots.txt 阻止)”在 External 标签中显示这些 URL,请选中此选项。如果选中“Ignore robots.txt(忽略 robots.txt)”,则此选项不可用。
您还可以在“Response Codes(响应代码)”标签和“Blocked by Robots.txt(被 Robots.txt 阻止)”过滤器下查看 robots.txt 阻止的外部 URL。这还将显示针对每个被阻止的 URL 的 disallow 的 robots.txt 指令(“matched robots.txt line column(匹配的 robots.txt 行列)”)。
自定义 Robots
您可以使用自定义 robots.txt 功能下载、编辑和测试站点的 robots.txt,该功能将覆盖站点上的实时版本以进行抓取。它不会更新站点上的实时 robots.txt。
此功能允许您在子域级别添加多个 robots.txt,测试 SEO Spider 中的指令,并查看被阻止或允许的 URL。自定义 robots.txt 使用配置中选择的 user-agent。
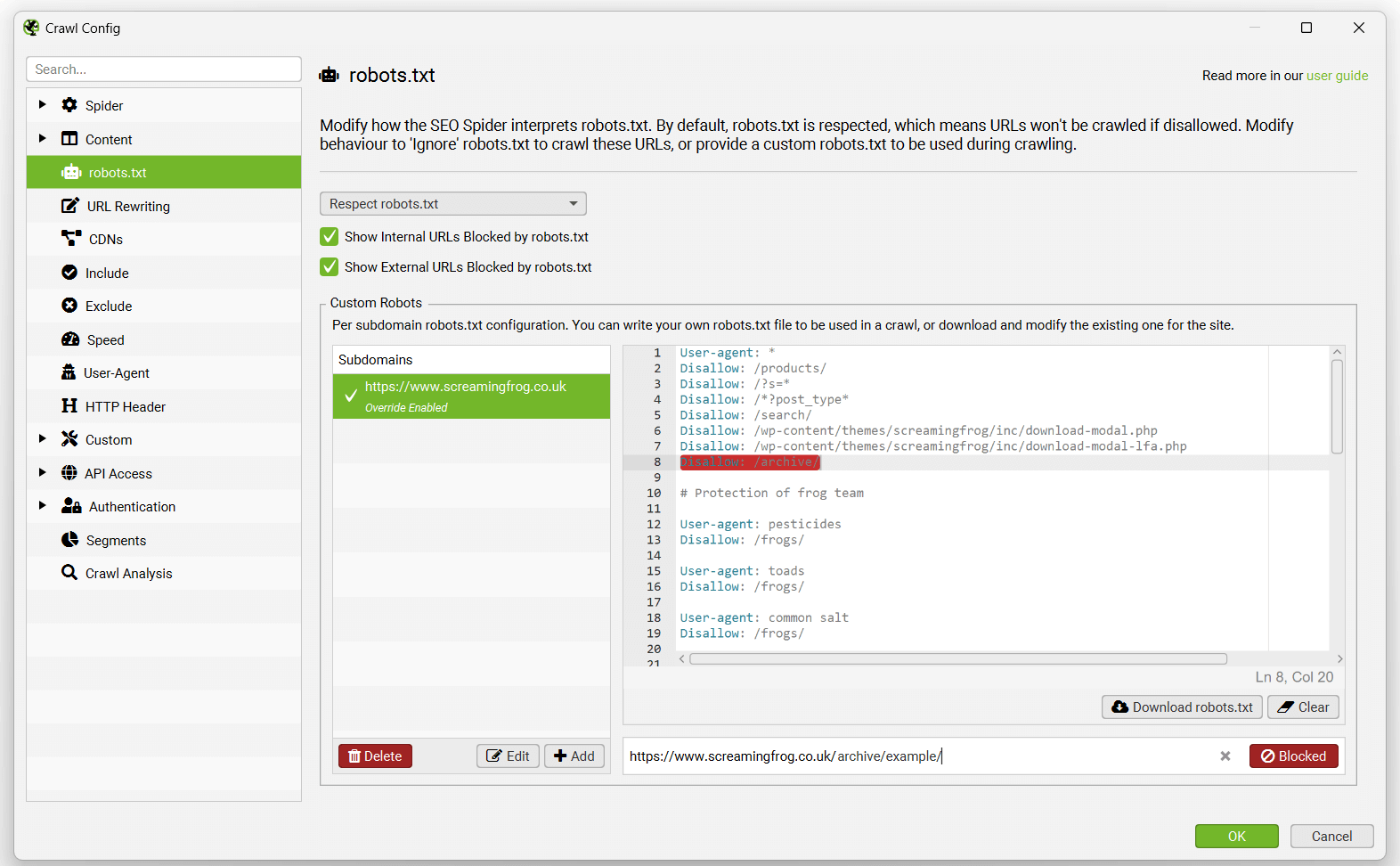
在抓取期间,您可以根据自定义 robots.txt(“Response Codes > Blocked by robots.txt(响应代码 > 被 robots.txt 阻止)”)过滤被阻止的 URL,并查看匹配的 robots.txt 指令行。
请阅读我们以 SEO Spider 作为 robots.txt 测试器的特色用户指南。
请注意 - 如上所述,您在 SEO Spider 中对 robots.txt 所做的更改不会影响您上传到服务器的实时 robots.txt。但是,您可以手动将这些更改复制并粘贴到实时版本中以更新您的实时指令。
URL 重写
Configuration > URL Rewriting(配置 > URL 重写)
URL 重写功能允许您动态重写 URL。对于大多数情况,‘remove parameters(删除参数)’和常见选项(在‘options(选项)’下)就足够了。但是,我们还提供高级 regex replace 功能,该功能提供进一步的控制。
URL 重写仅适用于在抓取网站过程中发现的 URL,而不适用于在“Spider(Spider)”模式下作为抓取开始输入的 URL,或作为“List(列表)”模式下的一组 URL 的一部分。
删除参数
此功能允许您自动删除 URL 中的参数。这对于具有会话 ID、Google Analytics 跟踪或您希望删除的大量参数的网站非常有用。例如 -
如果网站的 URL 中包含 session ID,使其看起来像这样 ‘example.com/?sid=random-string-of-characters’。要移除 session ID,你只需要在“移除参数”标签的“parameters”字段中添加 ‘sid’(不带引号)。
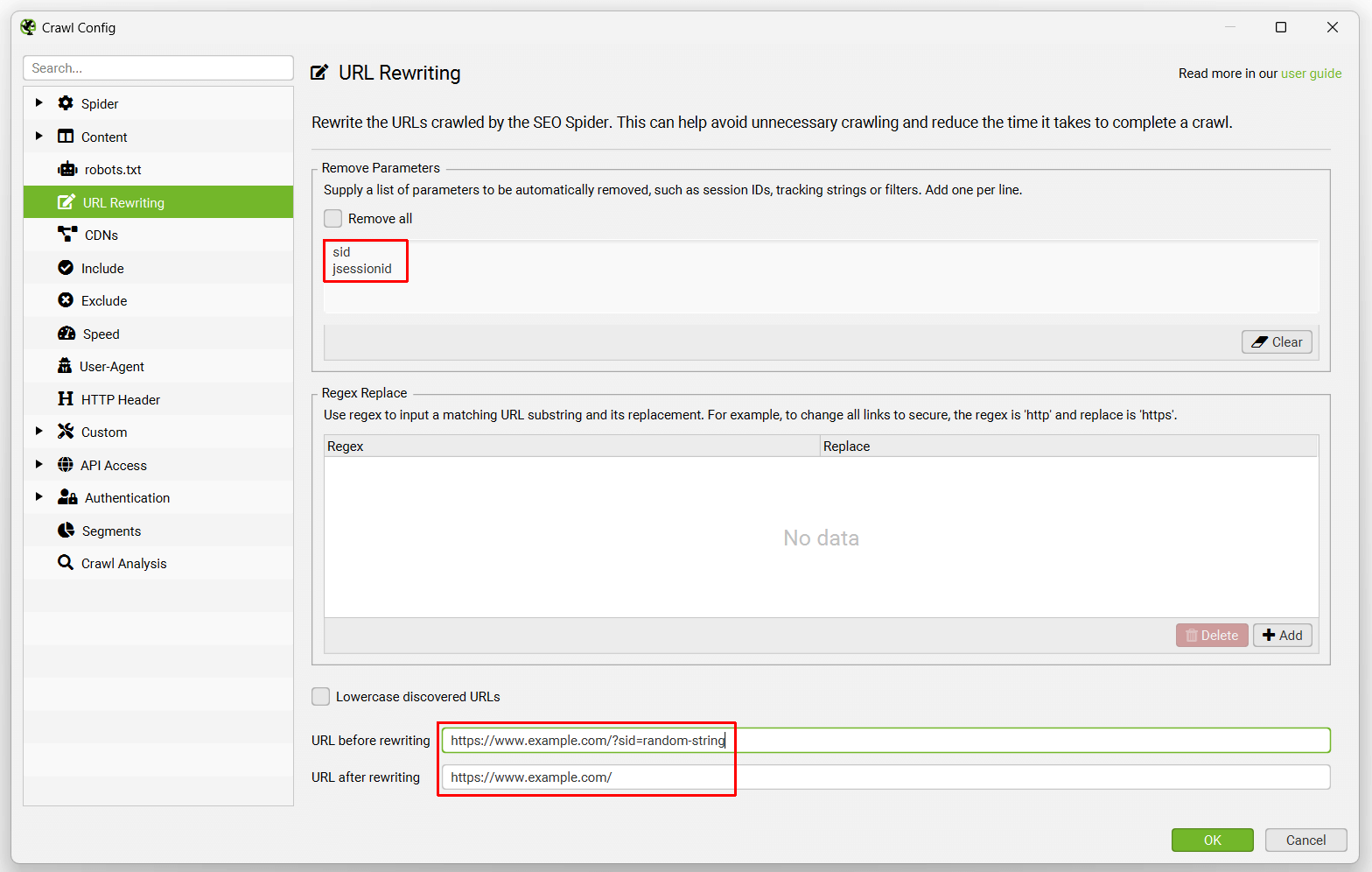
SEO Spider 将会自动从 URL 中移除 session ID。你可以在配置底部的 SEO Spider 中测试 URL 将如何被重写。
此功能也可用于移除 Google Analytics 跟踪参数。例如,你只需在“移除参数”下包含以下内容 –
utm_source
utm_medium
utm_campaign
这将从 URL 中移除标准跟踪参数。
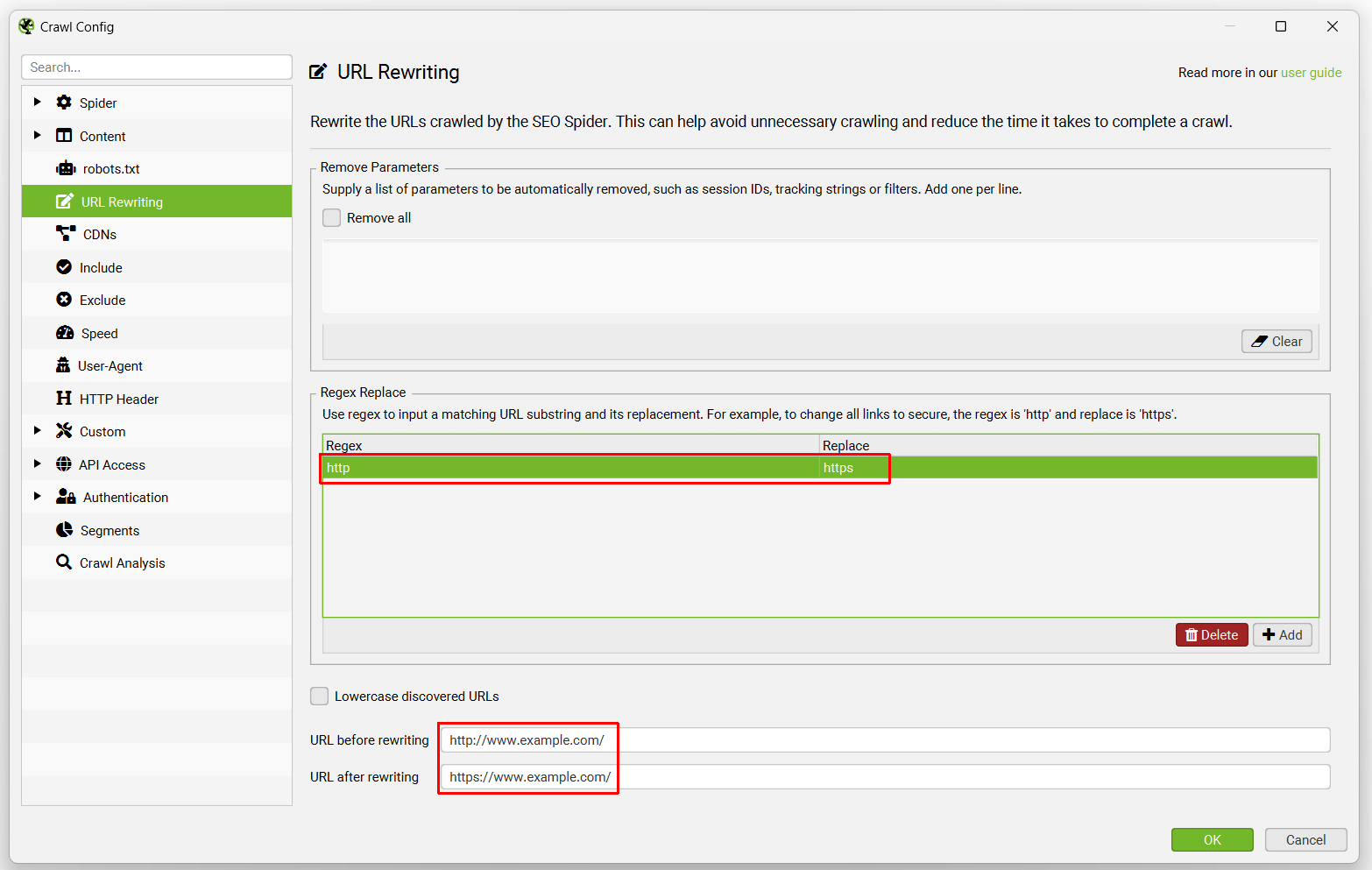
正则表达式替换
此高级功能针对在抓取或列表模式下找到的每个 URL 运行。它将 URL 中与正则表达式匹配的每个子字符串替换为给定的替换字符串。
示例:
- 将所有链接从 HTTP 更改为 HTTPS
Regex: http
Replace: https
- 将所有指向 example.com 的链接更改为 example.co.uk
Regex: .com
Replace: .co.uk
- 将所有包含 page=number 的链接更改为固定数字,例如
www.example.com/page.php?page=1
www.example.com/page.php?page=2
www.example.com/page.php?page=3
www.example.com/page.php?page=4
要使所有这些都转到 www.example.com/page.php?page=1
Regex: page=\d+
Replace: page=1
- 通过使用空的“Replace”从任何 URL 中删除 www. 域名。 如果你想删除查询字符串参数,请使用“移除参数”功能——正则表达式不是完成这项工作的正确工具!
Regex: www.
Replace:
- 移除所有参数
Regex: \?.*
Replace:
- 仅将 example.com 子域的链接从 HTTP 更改为 HTTPS
Regex: http://(.*example.com)
Replace: https://$1
- 在 JavaScript 渲染 模式下移除哈希值之后的所有内容
Regex: #.*
Replace:
- 向 URL 添加参数
Regex: $
Replace: ?parameter=value
这会将“?parameter=value”添加到遇到的任何 URL 的末尾
在网站已经有参数的情况下,这需要更复杂的表达式才能正确添加参数:
Regex: (.*?\?.*)
Replace: $1¶meter=value
Regex: (^((?!\?).)*$)
Replace: $1?parameter=value
这些必须按上述顺序输入,否则在将新参数添加到现有查询字符串时将不起作用。
选项
我们将在本节中包含常用选项。“将发现的 URL 转换为小写”选项正是这样做的,它将所有抓取的 URL 转换为小写,这对于 URL 中存在区分大小写问题的网站非常有用。
CDN
Configuration > CDNs
CDN 功能允许你输入 CDN 列表,以便在抓取期间将其视为“内部”。
你可以提供要被视为内部的域名列表。你还可以提供带有域名的子文件夹,以便将该子文件夹(及其中的内容)视为内部。
“内部”链接随后会包含在“内部”选项卡中,而不是“外部”选项卡中,并且会从中提取更多详细信息。
包含
Configuration > Include
此功能允许你使用部分正则表达式匹配来控制 SEO Spider 将抓取哪个 URL 路径。它通过仅抓取与正则表达式匹配的 URL 来缩小默认搜索范围,这对于较大的站点或 URL 结构不太直观的站点特别有用。匹配是在 URL 的编码版本上执行的。
你开始抓取的页面必须具有与此功能配合使用的正则表达式匹配的出站链接,否则它将不会继续抓取。如果起始页面没有与正则表达式匹配的 URL,SEO Spider 将不会抓取任何内容!
- 例如,如果你想从 https://www.screamingfrog.co.uk 抓取 URL 字符串中包含“search”的页面,你只需在“include”功能中包含正则表达式:search。这将找到 /search-engine-marketing/ 和 /search-engine-optimisation/ 页面,因为它们都包含“search”。
查看我们关于 include 功能的视频指南。
故障排除
- 匹配是在 URL 编码的地址上执行的,你可以在下部窗口窗格的 URL Info 选项卡或 Internal 选项卡中的相应列中查看它。
- 正则表达式必须匹配整个 URL,而不仅仅是部分 URL。
- 如果你遇到只抓取单个 URL 然后停止抓取的情况,请检查该页面的出站链接。如果你使用包含“/news/”的 include 抓取 http://www.example.com/ 并且只抓取 1 个 URL,那是因为 http://www.example.com/ 没有指向该站点新闻部分的任何链接。
排除
Configuration > Exclude
排除配置允许你使用部分正则表达式匹配从抓取中排除 URL。与排除项匹配的 URL 根本不会被抓取(它不仅仅是“隐藏”在界面中)。这意味着不匹配排除项的其他 URL,但只能从排除的页面访问,也不会在抓取中找到。
排除列表应用于在抓取期间发现的新 URL。此排除列表不适用于在抓取或列表模式下提供的初始 URL。
在抓取期间更改排除列表将影响新发现的 URL,并且它将追溯应用于待处理的 URL 列表,但不会更新已抓取的 URL。
匹配是在 URL 的编码版本上执行的。你可以通过在主窗口中选择 URL,然后在下部窗口窗格的详细信息选项卡中查看“URL 详细信息”选项卡,以及标记为“URL 编码地址”的第二行中的值来查看 URL 的编码版本。
以下是一些常见示例 –
- 要排除特定的 URL 或页面,语法为:
http://www.example.com/do-not-crawl-this-page.html
- 要排除子目录或文件夹,语法为:
http://www.example.com/do-not-crawl-this-folder/
- 要排除品牌之后的所有内容,其中有时可能在之前有其他文件夹:
http://www.example.com/.*/brand.*
- 如果你希望排除包含在各种不同目录中的带有特定参数(例如“?price”)的 URL,你可以简单地使用(注意 ? 是正则表达式中的特殊字符,必须使用反斜杠进行转义):
\?price
- 要排除带有问号“?”的任何内容(注意 ? 是正则表达式中的特殊字符,必须使用反斜杠进��行转义):
\?
- 如果你想排除所有以 jpg 结尾的文件,正则表达式将是:
jpg$
- 如果你想排除文件夹中包含 1 个或多个数字的所有 URL,例如“/1/”或“/999/”:
/\d+/$
- 如果你想排除所有以连字符后跟一个随机的 6 位数字结尾的 URL,例如“-402001”,正则表达式将是:
-[0-9]{6}$
- 如果你想排除任何包含“exclude”的 URL,正则表达式将是:
exclude
- 安全 (https) 页面将是:
https
- 排除 http://www.domain.com/ 上的所有页面将是:
http://www.domain.com/
- 如果你想排除一个 URL 并且它似乎不起作用,那可能是因为它包含特殊的正则表达式字符,例如 ?。与其尝试单独定位和转义这些字符,不如使用 \Q 开头和 \E 结尾来转义整行,如下所示:
\Qhttp://www.example.com/test.php?product=special\E
- 记住使用 URL 的编码版本。因此,如果你想排除任何带有管道符 | 的 URL,它将是:
%7C
- 如果你正在提取 cookie,这将删除 Google Analytics 跟踪标签的自动排除,你可以通过包含以下内容来阻止它们触发:
google-analytics.com
查看我们关于 exclude 功能的视频指南。
速度
Configuration > Speed
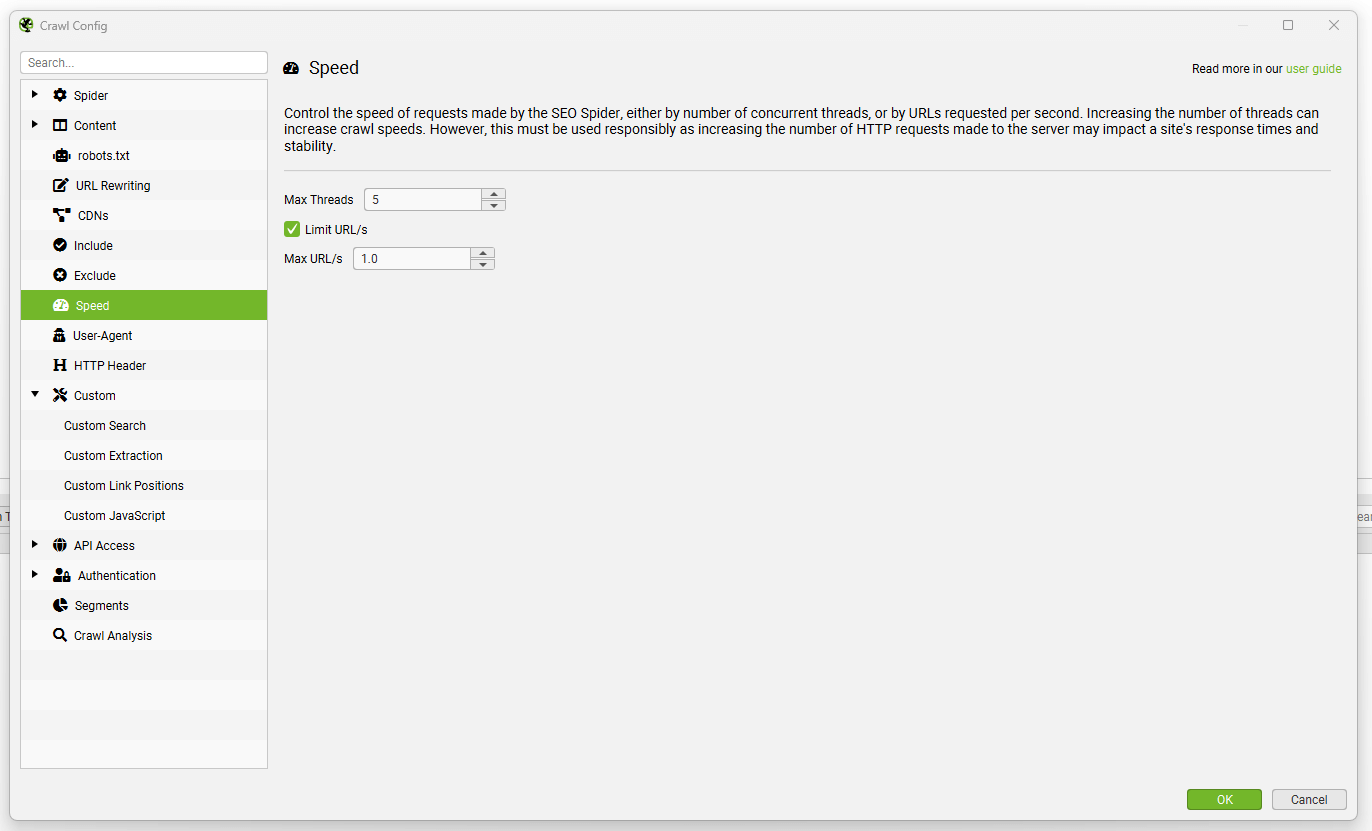
速度配置允许你通过并发线程数或每秒请求的 URL 数来控制 SEO Spider 的速度。
在降低速度时,始终更容易通过“最大 URI/秒”选项进行控制,该选项是每秒的最大 URL 请求数。例如,下面的屏幕截图表示以每秒 1 个 URL 的速度进行抓取 –
当你通过每秒 URL 数来限制速度时,可以简单地忽略“最大线程数”选项。
增加线程数可以显著提高 SEO Spider 的速度。默认情况下,SEO Spider 以 5 个线程进行抓取,以避免服务器过载。
请负责任地使用线程配置,因为将线程数设置得很高以提高抓取速度会增加对服务器发出的 HTTP 请求数,并可能影响站点的响应时间。在非常极端的情况下,你可能会使服务器过载并使其崩溃。
我们建议首先与网站管理员批准抓取速率和时间,监控响应时间,并在出现任何问题时调整默认速度。
用户代理
Configuration > User-Agent
用户代理配置允许你切换 SEO Spider 发出的 HTTP 请求的用户代理以及要遵循的 robots.txt 指令。默认情况下,SEO Spider 使用其自己的“Screaming Frog SEO Spider”用户代理字符串发出请求。
但是,它具有 Googlebot、Bingbot、各种浏览器等的内置预设�用户代理。这允许你在需要时快速切换它们。此功能还具有自定义用户代理设置,允许你指定自己的用户代理:
- HTTP Request User-Agent: 设置 HTTP 请求标头的用户代理字段。
- Robots User-Agent: 定义用于遵循 robots.txt 指令的用户代理。
有关 SEO Spider 如何处理 robots.txt 的详细信息,请参见此处。
HTTP 标头
Configuration > HTTP Header
HTTP 标头配置允许你在抓取期间提供完全自定义的标头请求。
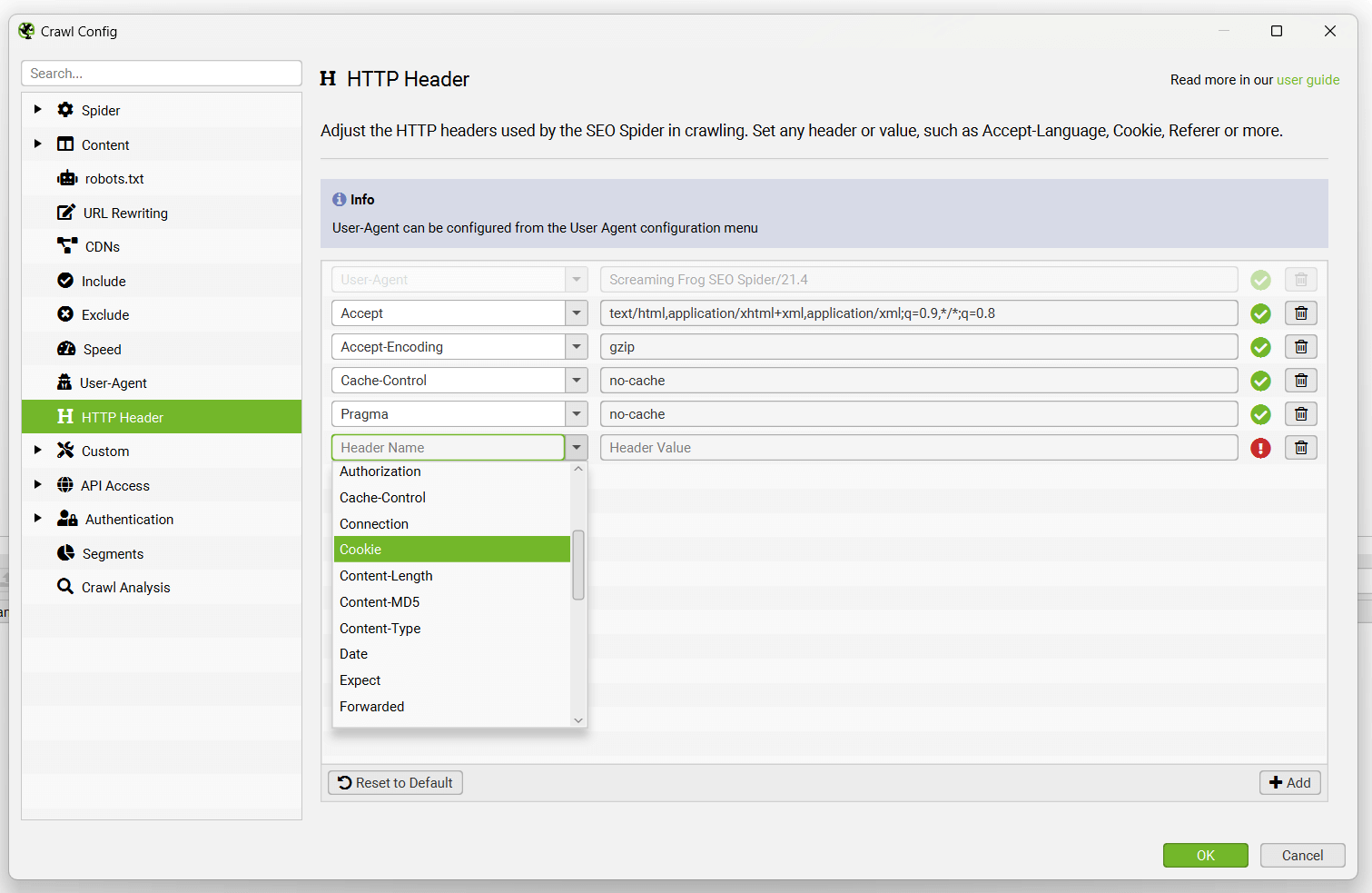
这意味着你可以设置从 accept-language、cookie、referer 到仅提供任何唯一标头名称的任何内容。例如,在某些情况下,你可能希望在 SEO Spider 的请求中提供 Accept-Language HTTP 标头,以抓取区域设置自适应内容。
User-agent 通过“Configuration > User-Agent”与其它标头分开配置。
自定义搜索
Configuration > Custom > Search
SEO Spider 允许你在网站的源代码中查找任何你想要的内容。自定义搜索功能将检查你抓取的每个页面的 HTML(页面文本或你选择搜索的特定元素)。
默认情况下,自定义搜索会检查网站的原始 HTML 源代码,这可能不是在浏览器中呈现的文本。你可以切换到 JavaScript 渲染模式 以搜索呈现的 HTML。
你可以在自定义搜索配置中配置多达 100 个搜索过滤器,这些过滤器允许你输入文本或正则表达式,并查找“包含”或“不包含”你选择的输入的页面。
这可以在“Config > Custom > Search”下找到。
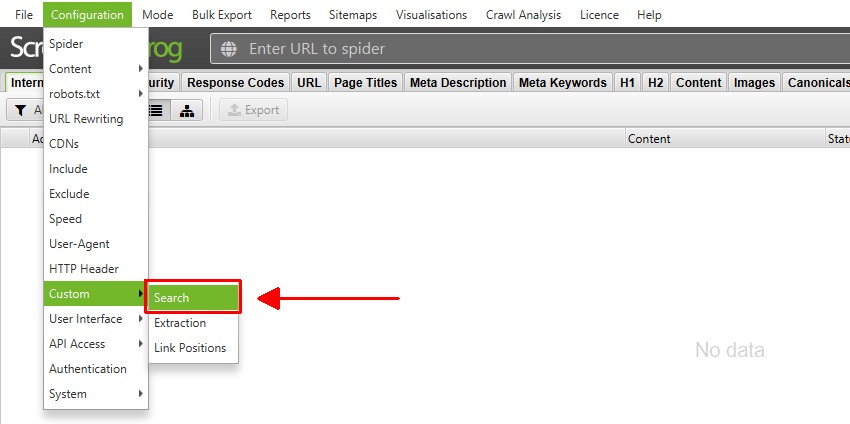
只需单击“添加”(在右下角)即可在配置中包含过滤器。
从左到右,你可以命名搜索过滤器,选择“包含”或“不包含”,选择“文本”或“正则表达式”,输入你的搜索查询 – 并选择执行搜索的位置(HTML、页面文本、元素或 XPath 等)。
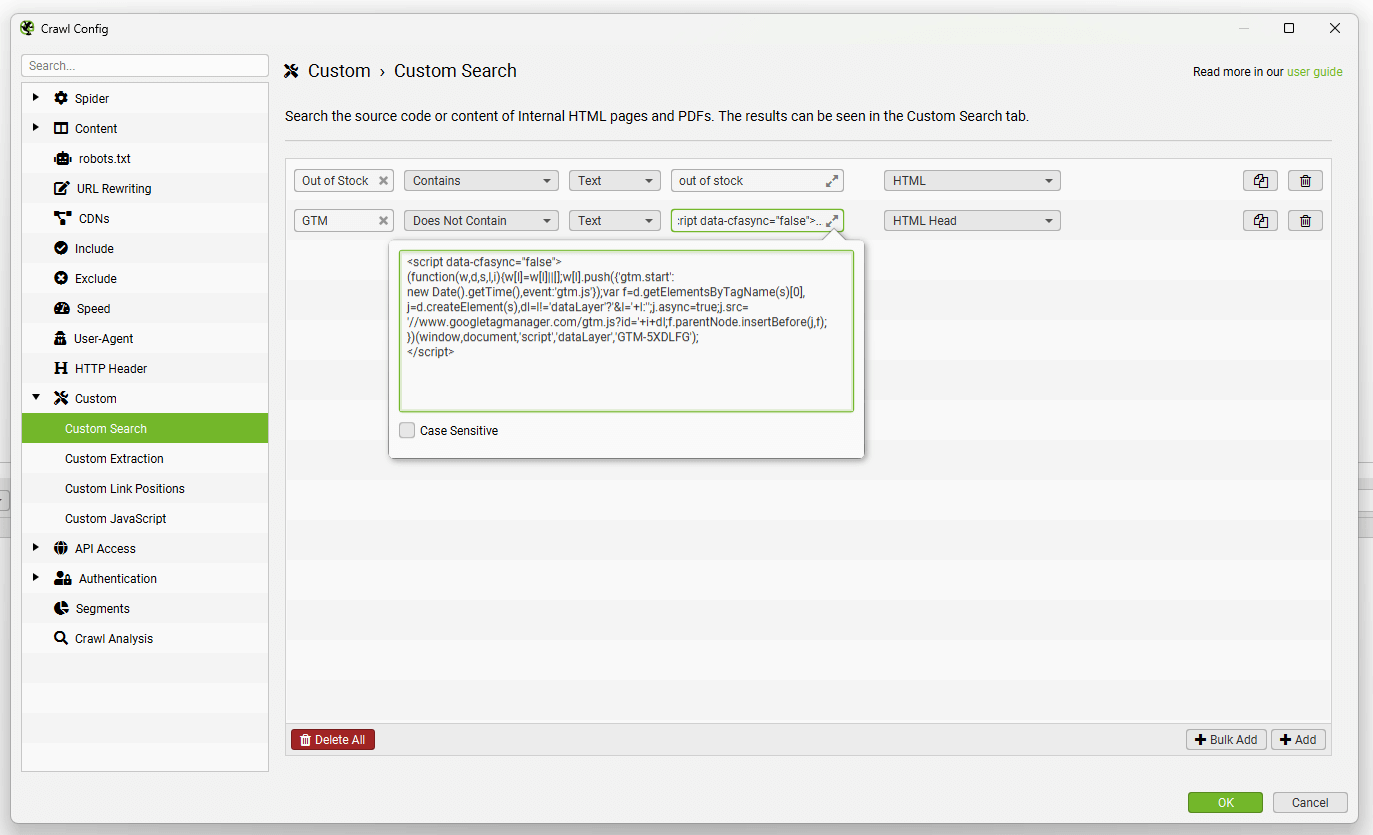
例如,你可能希望为“缺货”之类的页面选择“包含”,因为你希望找到任何包含此内容的页面。当搜索 Google Analytics 代码之类的内容时,选择“不包含”过滤器更有意义,以查找不包含该代码的页面(而不是仅列出所有包含该代码的页面!)。
可以在“自定义搜索”选项��卡中查看“包含”或“不包含”输入数据的页面。
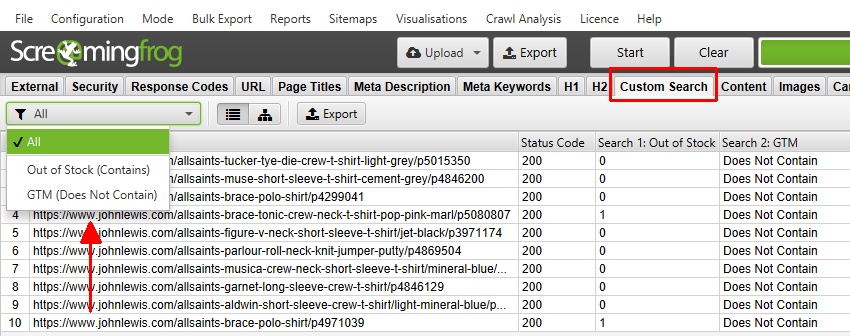
“包含”过滤器将显示搜索的出现次数,而“不包含”搜索将返回“包含”或“不包含”。
在此搜索中,有 2 个页面包含“缺货”文本,每个页面仅包含该词一次 – 而在 10 个页面中的任何一个页面上都未找到 GTM 代码。
SEO Spider 使用 Java 正则表达式库,如此处所述。要“抓取”或提取数据,请使用自定义提取功能。
你可以在自定义搜索中使用正则表达式来查找确切的单词。例如 –
\bexample\b
将匹配一个特定的单词(在本例中为“example”),因为 \b 匹配单词边界。
请参阅我们的教程“如何使用自定义搜索”,了解更高级的场景,例如区分大小写、查找确切和多个单词、组合搜索、在特定元素中搜索以及用于多行代码段。
自定义提取
Configuration > Custom > Extraction
自定义提取允许您从 URL 的 HTML 中收集任何数据。提取操作针对内部 HTML 页面返回的静态 HTML 执行,并返回 2XX 响应代码。您可以切换到 JavaScript 渲染 模式,以从渲染后的 HTML 中提取数据(对于任何仅存在于客户端的数据)。
SEO Spider 支持以下模式来执行数据提取:
- XPath:XPath 选择器,包括属性。
- CSS Path:CSS Path 和可选属性。
- Regex:用于更高级的用途,例如抓取 HTML 注释或内联 JavaScript。
当使用 XPath 或 CSS Path 收集 HTML 时,您可以选择要提取的内容:
- Extract HTML Element(提取 HTML 元素):所选元素及其内部 HTML 内容。
- Extract Inner HTML(提取内部 HTML):所选元素的内部 HTML 内容。如果所选元素包含其他 HTML 元素,它们将被包含在内。
- Extract Text(提取文本):所选元素的文本内容以及任何子元素的文本内容。
- Function Value(函数值):所提供函数的结果,例如 count(//h1) 用于查找页面上 h1 标签的数量。
要设置自定义提取,请单击“Config > Custom > Custom Extraction”(配置 > 自定义 > 自定义提取)。
只需单击“Add”(添加)即可开始设置提取器。
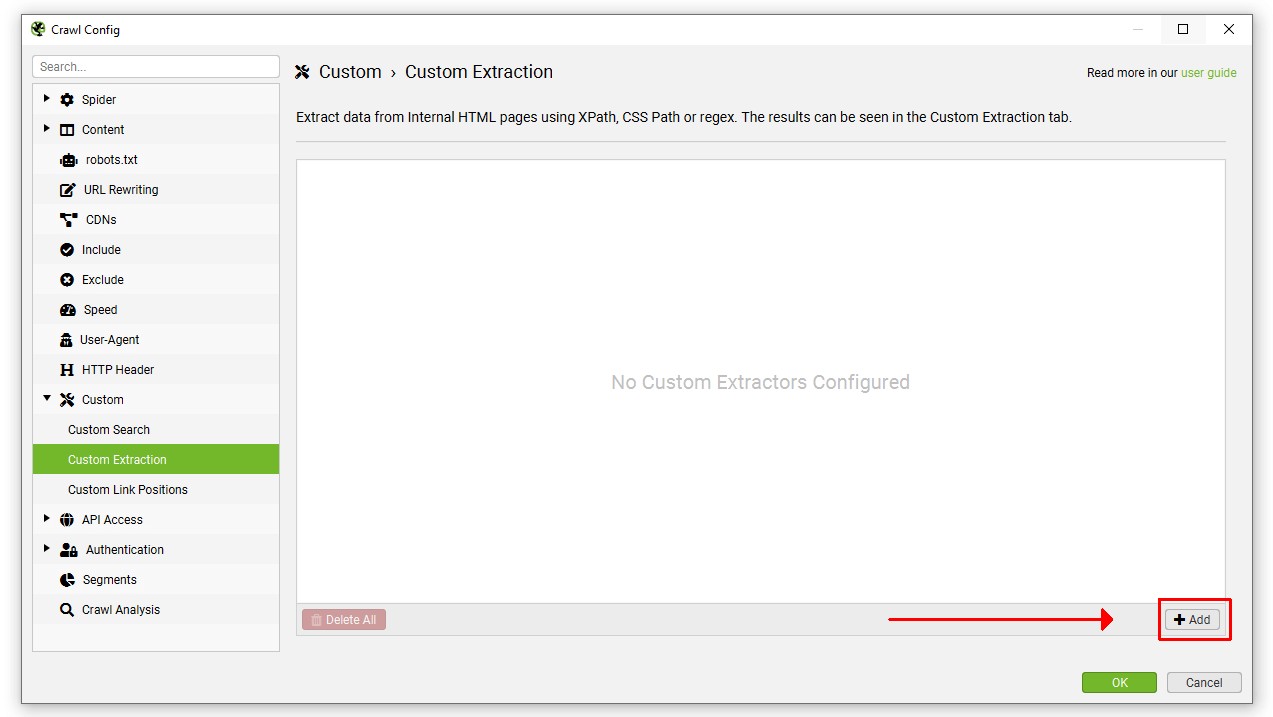
然后插入相关的表达式以抓取数据。最多可以配置 100 个独立的提取器来抓取网站数据,所有提取器总共最多可以进行 1,000 次提取。
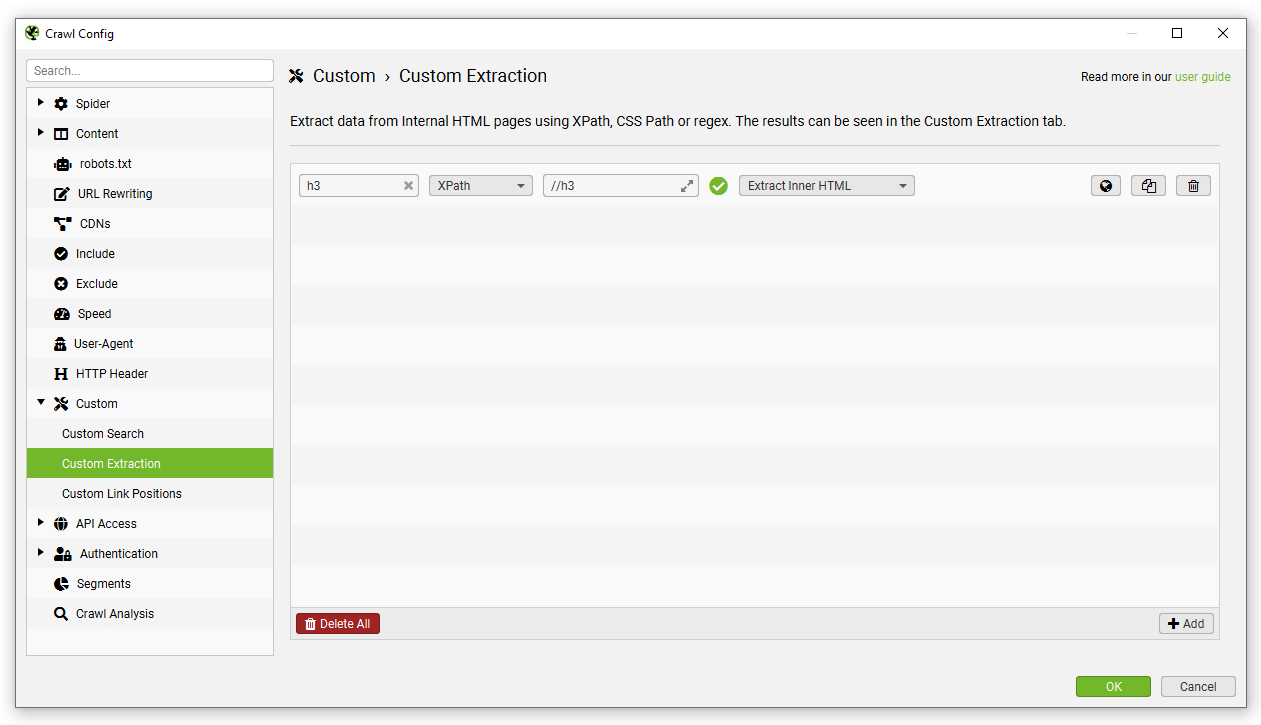
如果您不熟悉 XPath、CSSPath 和 regex,您可以使用可视化自定义提取功能,使用内置浏览器选择要抓取的元素。单击提取器旁边的“browser”(浏览器)图标。

在 URL 栏中输入您希望从中提取数据的 URL,然后选择您希望抓取的元素。
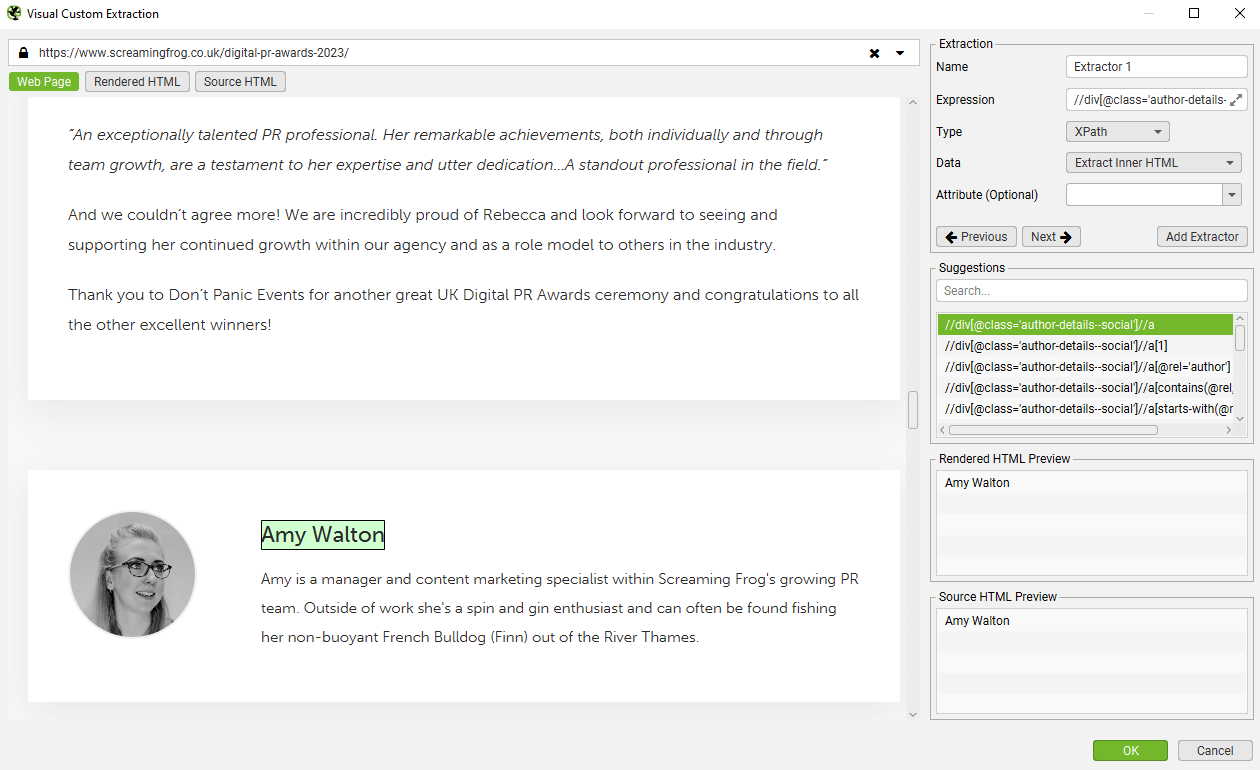
SEO Spider 将突出显示页面上的区域,并创建各种建议的表达式,以及基于原始或渲染后的 HTML 的提取预览。在本例中,是从博客文章中提取作者姓名。
提取的数据可以在 Custom Extraction(自定义提取)选项卡中查看。提取的数据也作为列包含在“Internal”(内部)选项卡中。
请阅读我们的 SEO Spider 网络抓取 指南,以获取有关如何使用自定义提取的完整教程。有关自定义提取表达式的示例,请参阅我们的 XPath 示例 和 Regex 示例。
Regex 故障排除
-
SEO Spider 在运行 regex 之前不会预处理 HTML。但请记住,您在浏览器中查看源代码时看到的 HTML 可能与 SEO Spider 看到的 HTML 不同。这可能是由于网站根据 User-Agent 或 Cookies 返回不同的内容,或者如果页面内容是使用 JavaScript 生成的,而您没有使用 JavaScript 渲染。
-
有关 SEO Spider 使用的 regex 引擎的更多详细信息,请参见此处。
-
regex 引擎配置为点字符匹配换行符。
-
正则表达式,取决于它们的编写方式以及它们所针对的 HTML,可能会很慢。这将影响爬网速度。
自定义链接位置
Configuration > Custom > Link Positions(配置 > 自定义 > 链接位置)
SEO Spider 对页面上的每个链接的位置进行分类,例如它是在导航栏、页面内容、侧边栏还是页脚中。
分类是通过使用每个链接的“链接路径”(作为 XPath)来查找已知的语义子字符串来执行的,并且可以在“inlinks”(入站链接)和“outlinks”(出站链接)选项卡中看到。
这可以帮助识别仅来自正文内容的页面的“入站链接”,例如,忽略主导航栏或页脚中的任何链接,以进行更好的内部链接分析。
如果您的网站使用语义 HTML5 元素(或命名良好的非语义元素,�例如 div id=”nav”),SEO Spider 将能够自动确定网页的不同部分以及其中的链接。
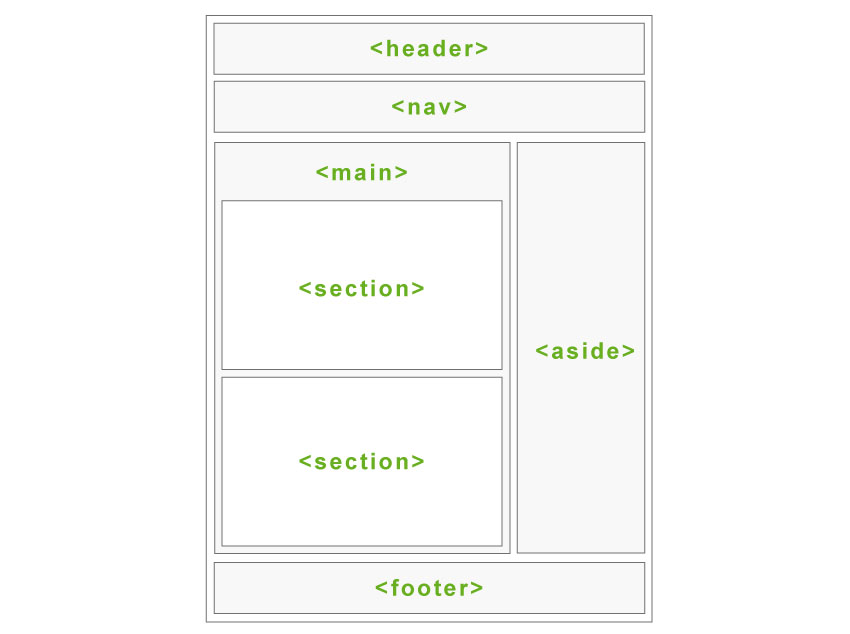
默认的链接位置设置使用以下搜索词来对链接进行分类。
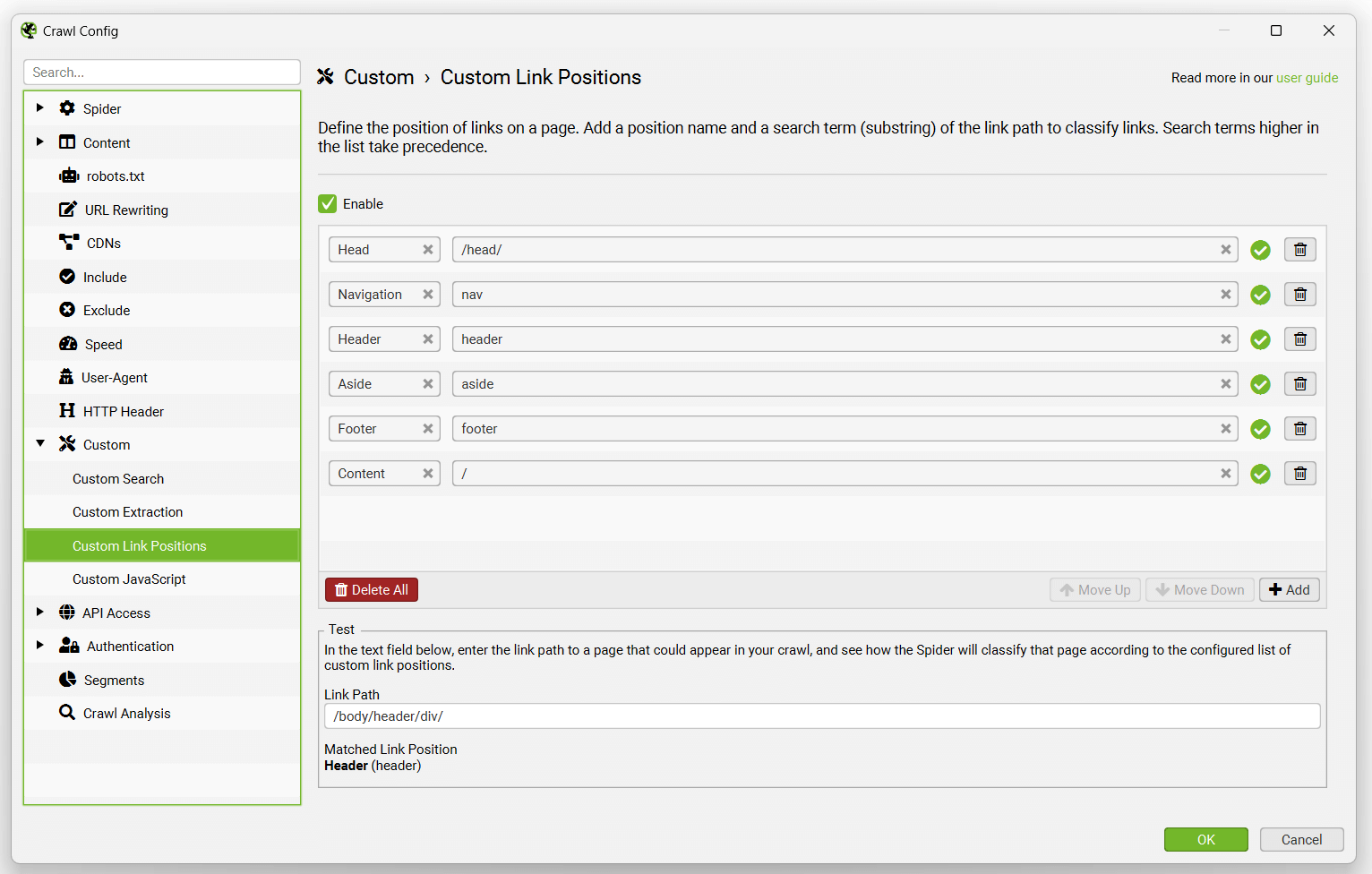
但是,并非每个网站都以这种方式构建,因此您可以根据每个网站的独特设置来配置链接位置分类。这允许您使用任何链接的链接路径的子字符串来对其进行分类。
例如,Screaming Frog 网站在 nav 元素之外具有移动菜单链接,这些链接被确定为“content”(内容)链接。这是不正确的,因为它们只是移动设备上的一个额外的全站导航。这是因为它们不在 nav 元素内,并且没有很好地命名,例如在它们的类名中没有“nav”。哎呀!
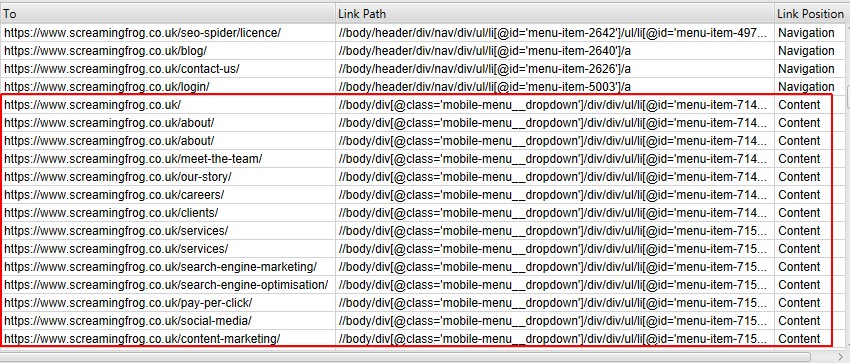
“mobile-menu__dropdown”类名(如上所示,在链接路径中)可用于使用“链接位置”功能定义其正确的链接位置。
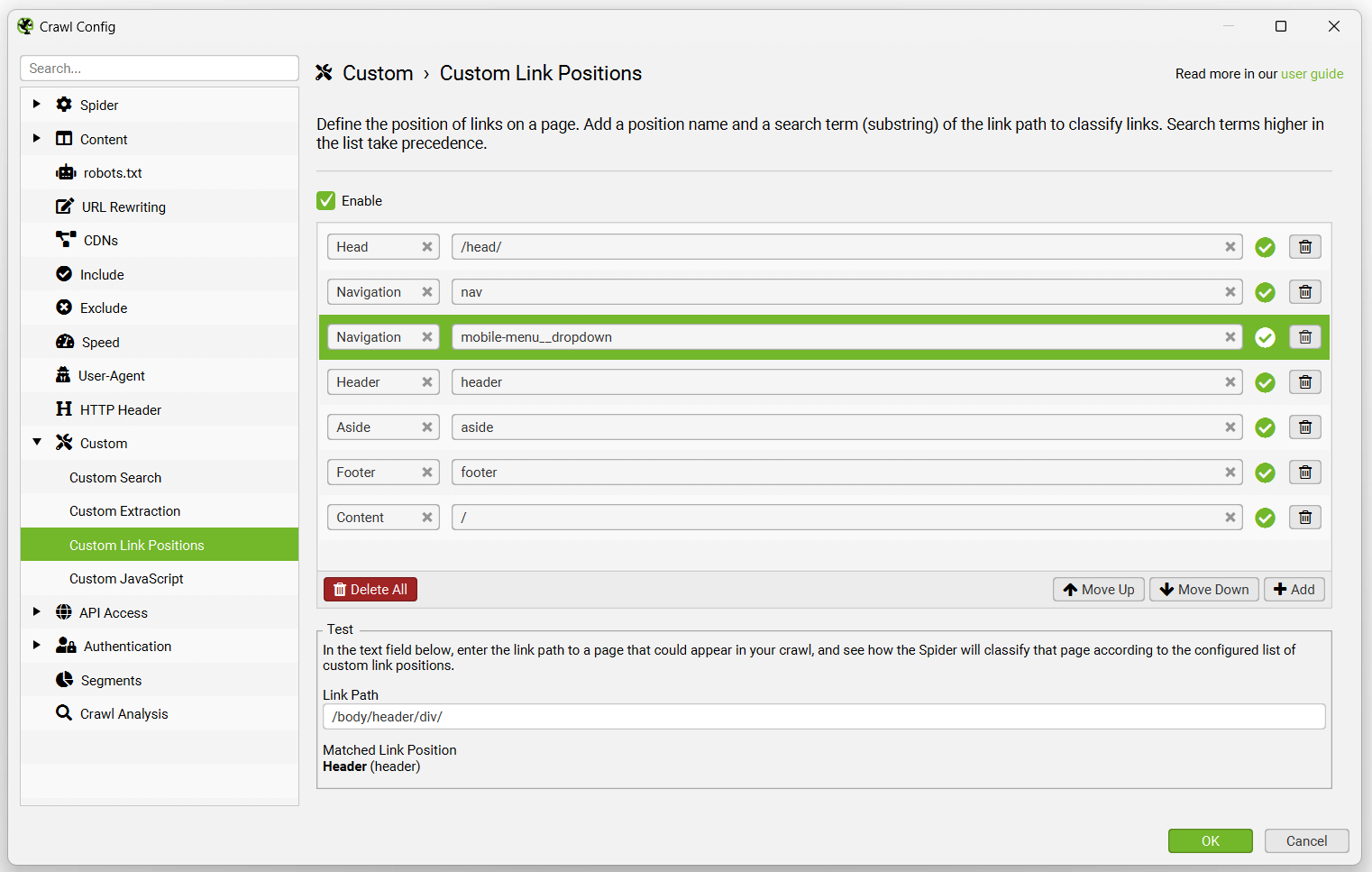
然后,这些链接将被正确地归类为全站导航链接。
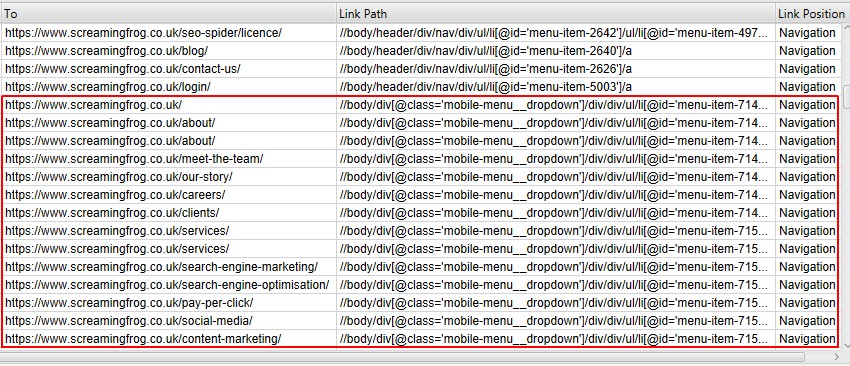
用于链接位置分类的搜索词或子字符串基于优先级顺��序。由于“Content”(内容)设置为“/”并且将匹配任何链接路径,因此它应始终位于配置的底部。
因此,在上面的示例中,添加了“mobile-menu__dropdown”类名,并使用“Move Up”(上移)按钮将其移动到“Content”(内容)上方以获得优先权。
您可以禁用“Link Positions”(链接位置)分类,这意味着不会存储每个链接的 XPath,也不会确定链接位置。这有助于节省内存并加快爬网速度。
自定义 JavaScript
Configuration > Custom > Custom JavaScript(配置 > 自定义 > 自定义 JavaScript)
隐私声明
- “Custom JavaScript Snippets”(自定义 JavaScript 代码段)可能涉及将数据发送到第三方服务或 API(即,使用 ChatGPT 的服务或 API)。您有责任保护所有此类数据的隐私。
- 在共享“Custom JavaScript Snippets”(自定义 JavaScript 代码段)之前,请确保删除 API 密钥或其他敏感数据。
简介
自定义 JavaScript 允许您在爬取的每个内部 200 OK URL 上运行 JavaScript 代码(PDF 除外)。
您可以从网页中提取各种有用的信息,这些信息可能在 SEO Spider 中不可用,还可以与 API(例如 OpenAI 的 ChatGPT、本地 LLM 或其他库)进行通信。您可以将 URL 内容保存到磁盘,并将内容写入磁盘上的文本文件。
要设置自定义 JavaScript 代码段,请单击“Config > Custom > JavaScript”(配置 > 自定义 > JavaScript)。然�后单击“Add”(添加)以开始设置新的代码段,或单击“Add from Library”(从库中添加)以选择现有的代码段。
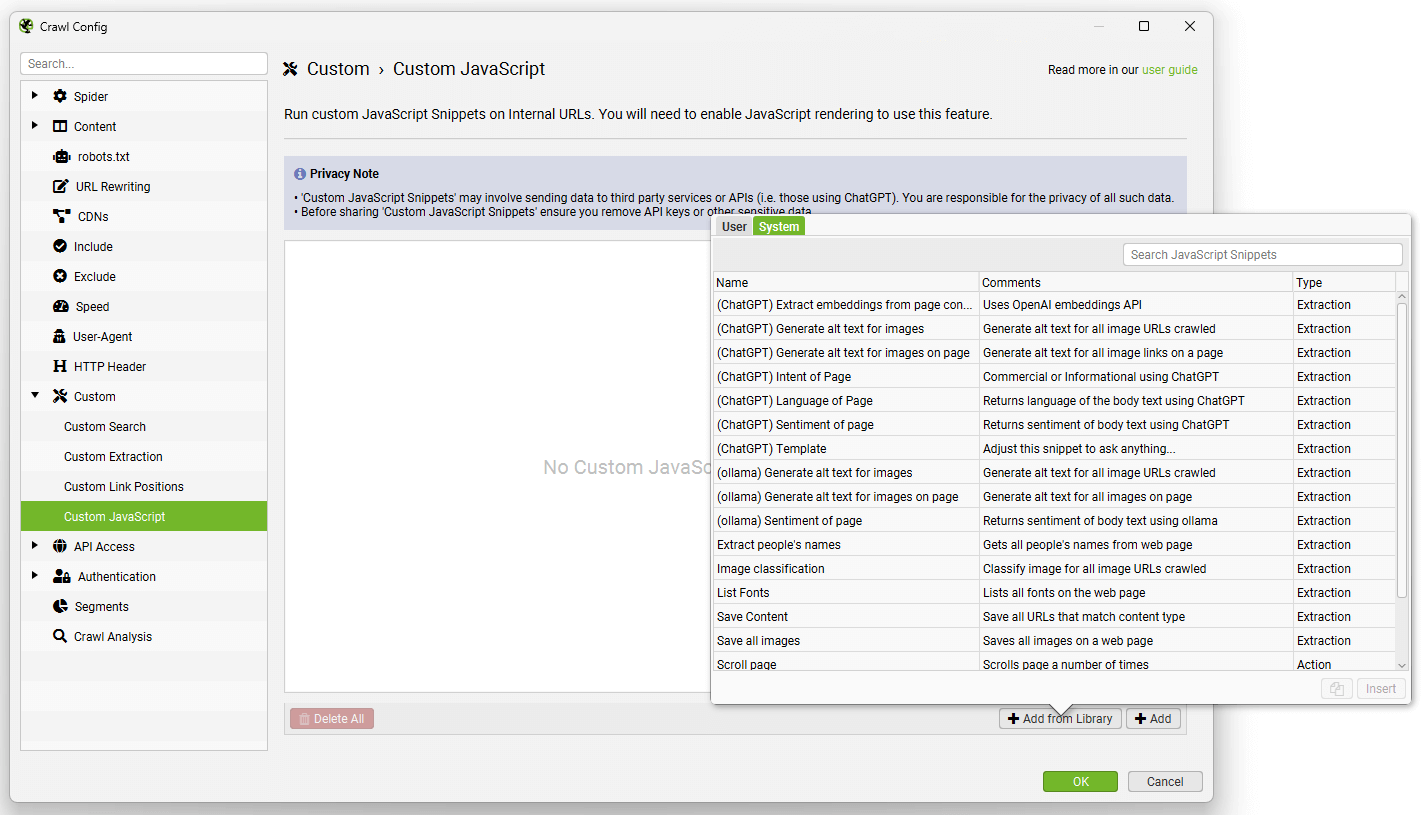
该库包含示例代码段,用于执行各种操作,以作为如何使用该功能的灵感,例如:
- 对页面内容进行情感、意图或语言分析。
- 为图像生成图像 alt 文本。
- 触发鼠标悬停事件。
- 滚动页面(以爬取某些无限滚动设置)。
- 从页面内容中提取嵌入。
- 在本地下载和保存各种内容(如图像)。
等等。
您可以按照其中的注释调整我们的模板代码段。
您可以设置内容类型过滤器,该过滤器将允许自定义 JavaScript 代码段仅针对某些内容类型执行。
结果将显示在“Custom JavaScript”(自定义 JavaScript)选项卡中。
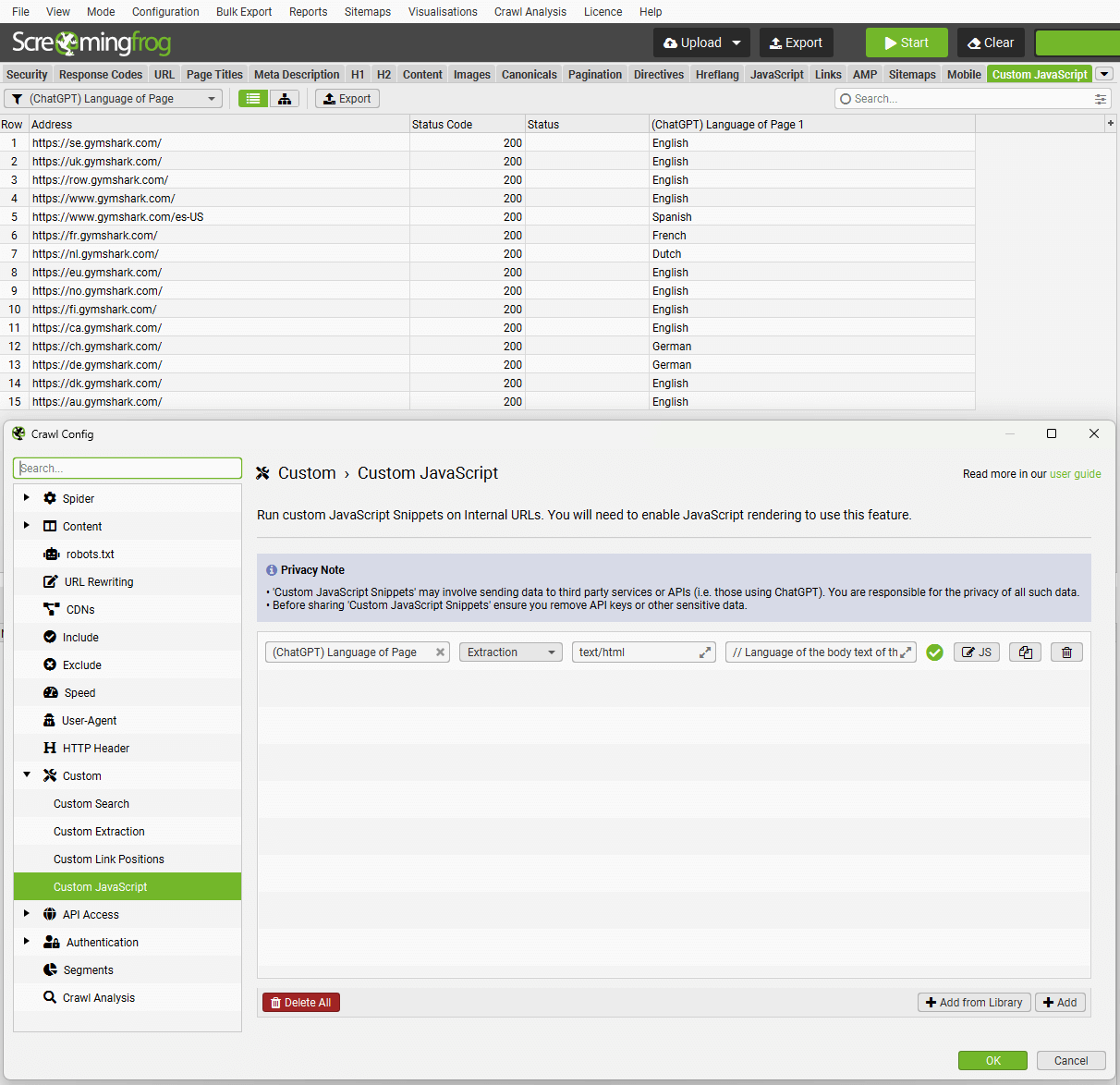
代码段有两种类型:Extraction(提取)和 Action(操作)。
Extraction Snippets(提取代码段)
-
Extraction(提取)类型的代码段返回一个值或值列表(数字或字符串),并在“Custom JavaScript”(自定义 JavaScript��)选项卡中将这些值显示为列。值列表中的每个值都将映射到选项卡中的列。
-
执行 Extraction(提取)代码段时,页面将停止加载所有资源并开始执行代码段。SEO Spider 将不会完成页面爬网,直到代码段完成。长时间运行的代码段可能会超时,并且页面将无法被爬取。
-
Extraction(提取)代码段还能够下载 URL 并写入文本文件。例如,我们有一个示例代码段可以下载网页中的所有图像,还有另一个示例代码段可以将网页中的所有形容词附加到 CSV 文件。
Action Snippets(操作代码段)
-
Action(操作)类型的代码段不返回任何数据,而仅执行操作。例如,我们有一个示例代码段可以向下滚动网页,从而允许爬取延迟加载的图像。
-
执行 Action(操作)代码段时,页面将继续加载资源,同时 Action(操作)代码段正在执行。但是,您必须为代码段提供一个以秒为单位的超时值。当计时器到期时,SEO Spider 将完成页面爬网。
需要注意的要点
-
您可以一次运行多个代码段。请注意,您的爬网速度将受到您运行的代码段的数量和类型的影响。
-
如果您有多个代码段,则所有 Action(操作)代码段将在 Extraction(提取)代码段之前执行。
-
如果您有多个具有不同超时值的 Action(操作)代码段,则 SEO Spider 将使用所有 Action(操作)代码段的最大超时值。
-
Extraction(提取)代码段会停止所有页面加载,因此不会发生更多请求。Action(操作)代码段没有此限制,但您需要设置超时值。
-
代码段可以访问 Chrome Console Utilities API。这允许代码段使用诸如 getEventListeners() 之类的方法,这些方法无法通过网页上的常规 JavaScript 访问。有关此示例,请参见“Trigger mouseover events”(触发鼠标悬停事件)示例代码段。
Extraction Snippet API Usage(提取代码段 API 用法)
对于 Extraction(提取)代码段,您可以使用 seoSpider 对象与 SEO Spider 进行交互,该对象是下面记录的 SEOSpider 类的实例。最基本的形式是按如下方式使用它:
// SEO Spider 将在单个列中显示“1” return seoSpider.data(1);
// SEO Spider 将在单独的列中显示每个数字 return seoSpider.data([1, 2, 3]);
// SEO Spider 将在单个列中显示“item1” return seoSpider.data("item1");
// SEO Spider 将在单独的列中显示每个字符串 return seoSpider.data(["item1", "item2"]);
您还可以从 Promise 将数据发送回 SEO Spider。SEO Spider 将等待 Promise 被实现。这允许您在将数据返回到 SEO Spider 之前执行异步工作,例如 fetch 请求。例如:
let promise = new Promise(resolve => {
setTimeout(() => resolve("done!"), 1000);
});
// 1 秒后将“done!”发送到 SEO Spider
return promise.then(msg => seoSpider.data(msg));
请注意
请注意,在上述所有 Extraction(提取)代码段示例中,即使对于 Promise 示例,您也必须调用“return”语句来结束函数执行。这是因为所有代码段代码都由 SEO Spider 隐式地包装在 IIFE(立即调用函数表达式)中。这是为了避免在运行代码段时发生 JavaScript 全局命名空间冲突。如果您不这样做,则 SEO Spider 将不会收到任何数据。
下面的示例显示了您的 JavaScript 代码段代码如何隐式地包装在 IIFE 中。它还显示了如何在插入代码之前为您创建 seoSpider 实例。
(function () {
// 为您的代码段创建 seoSpider 对象以供使用
const seoSpider = new SEOSpider();
// 您的 JavaScript 代码段代码将插入此处,即:
return seoSpider.data("data");
})();
SEOSpider Methods(SEOSpider 方法)
此类提供用于将数据发送回 SEO Spider 的方法。不要在此类上调用 new,而是为您提供一个名为 seoSpider 的实例。
data(data)
将提供的数据传递回 SEO Spider,以便在“Custom JavaScript”(自定义 JavaScript)选项卡中显示。data 参数可以是字符串或数字,也可以是字符串或数字的列表。如果数据是一个列表,则列表中的每个项目都将显示在“Custom JavaScript”(自定义 JavaScript)选项卡上的单独列中。
参数:
名称:data
类型:string | number | Array.<string> | Array.<number>
描述:传递回 SEO Spider 的数据
示例:
// 从页面获取所有 H1 和 H2 标题
let headings = Array.from(document.querySelectorAll("h1, h2"))
.map(heading => heading.textContent.trim());
return seoSpider.data(headings);
error(msg)
将任何错误消息传递回 SEO Spider。这些消息将显示在“Custom JavaScript”(自定义 JavaScript)选项卡的一列中。
参数:
名称:msg
类型:string
描述:要传递回 SEO Spider 的错误消息
示例:
return functionThatReturnsPromise()
.then(success => seoSpider.data(success))
.catch(error => seoSpider.error(error));
}
saveText(text, saveFilePath, shouldAppend)
将提供的文本保存到 saveFilePath。
参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| text | string | 将要保存的文本 |
| saveFilePath | string | 文本将要保存到的文件的完整路径。如果目录不存在,程序会自动创建 |
| shouldAppend | boolean | 如果文件应该被追加写入,则设置为 true |
示例:
return seoSpider.saveText('some text', '/Users/john/file.txt', false);
saveUrls(urls, saveDirPath)
下载提供的 URL 列表,并将每个 URL 保存到 saveDirPath。
参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| urls | Array.<string> | 将被下载和保存的 URL 列表 |
| saveDirPath | string | 文件将被保存到的目录的完整路径。如果目录不存在,程序会自动创建 |
示例:
return seoSpider.saveUrls(['https://foo.com/bar/image.jpeg'], '/Users/john/');
注意:
‘urls’ 参数中提供的每个 URL 将被保存在遵循 URL 路径的目录结构中。例如,在上面的示例中,URL 为:
'https://foo.com/bar/image.jpeg'
且 ‘saveDirPath’ 为:
'/Users/john/'
那么 URL 将被保存到以下文件夹结构中:
'/Users/John/https/foo.com/bar/image.jpeg'
loadScript(src) →
加载外部脚本以供 Snippet 使用。脚本异步加载。您可以在 ‘then’ 子句中编写代码,如下面的示例所示。
参数:
名称:src
类型:string
描述:您要加载的库的 URL
示例:
return seoSpider.loadScript("your_script_url")
.then(() => {
// 脚本已加载,您可以从这里开始使用它
...
// 将数据返回给 SEO Spider
return seoSpider.data(your_data)
})
.catch(error => seoSpider.error(error));
分享您的 Snippets
您可以设置自己的 snippets,它们将被保存在您的用户库中,然后导出/导入该库为 JSON 格式,以便与同事分享。
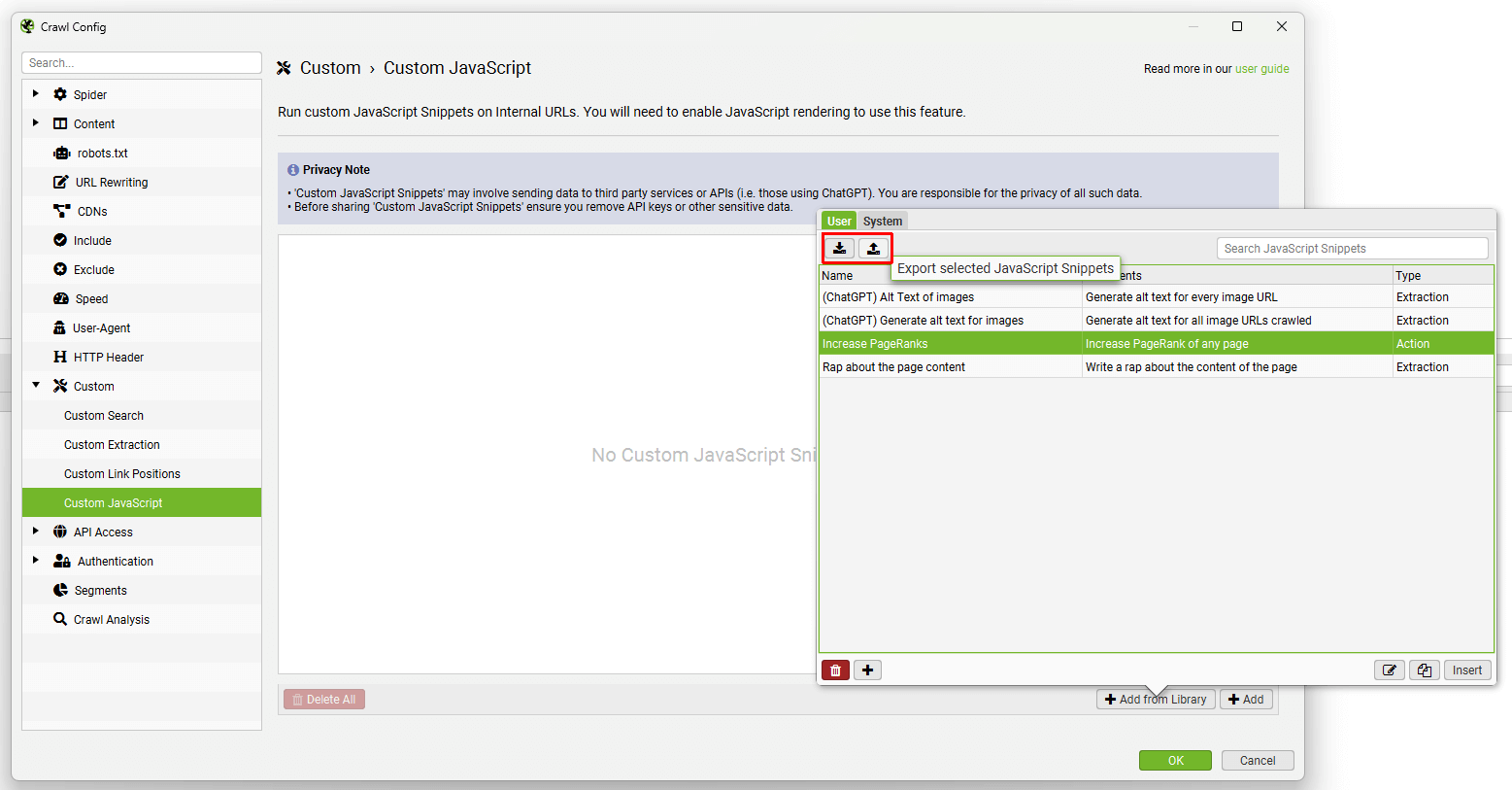
JavaScript snippets 也可以保存在您的配置中。
请不要忘记删除任何敏感数据,例如在与他人分享之前删除任何 API 密钥。
调试 Snippets
在使用自定义 JavaScript 时,您可能会遇到预设 JavaScript snippets 或您自己的自定义 JavaScript 出现问题,需要进行调试。
请阅读我们的如何调试自定义 JavaScript Snippets教程,该教程将引导您完成调试过程和常见错误。
Snippet 支持
由于此功能的技术性质,很遗憾,我们无法为编写和调试您自己的自定义 JavaScript snippets 提供支持。
Google Analytics 集成
配置 > API 访问 > Google Analytics 4
您可以连接到 GA4 API 并在抓取期间直接拉取数据。SEO Spider 可以获取用户和会话指标,以及关键事件和电子商务(交易和收入)数据,以便您可以查看在执行技术或内容审核时表现最佳的页面。
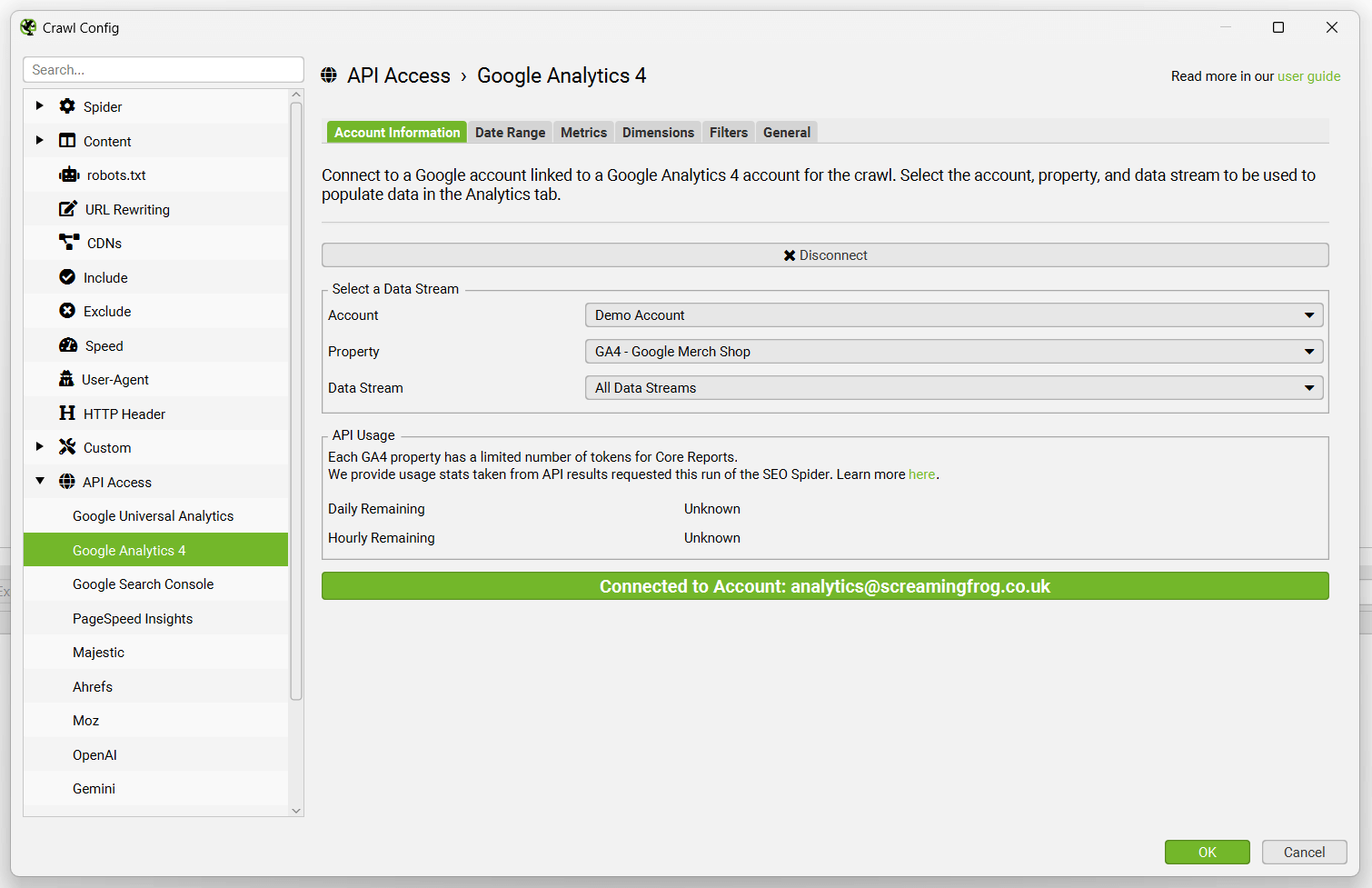
要进行设置,请启动 SEO Spider 并转到“配置 > API 访问”,然后选择“Google Analytics 4”。
接下来,通过授予“Screaming Frog SEO Spider”应用程序访问您的帐户以检索数据的权限,连接到 Google 帐户(该帐户有权访问您希望查询的 Analytics 帐户)。
Google API 使用 OAuth 2.0 协议进行身份验证和授权。SEO Spider 将记住您在列表中授权的任何 Google 帐户,因此您每次启动应用程序时都可以快速“连接”。
连接后,您可以选择 analytics 帐户、媒体资源和数据流。
然后只需选择您希望为 GA4 获取的指标 -
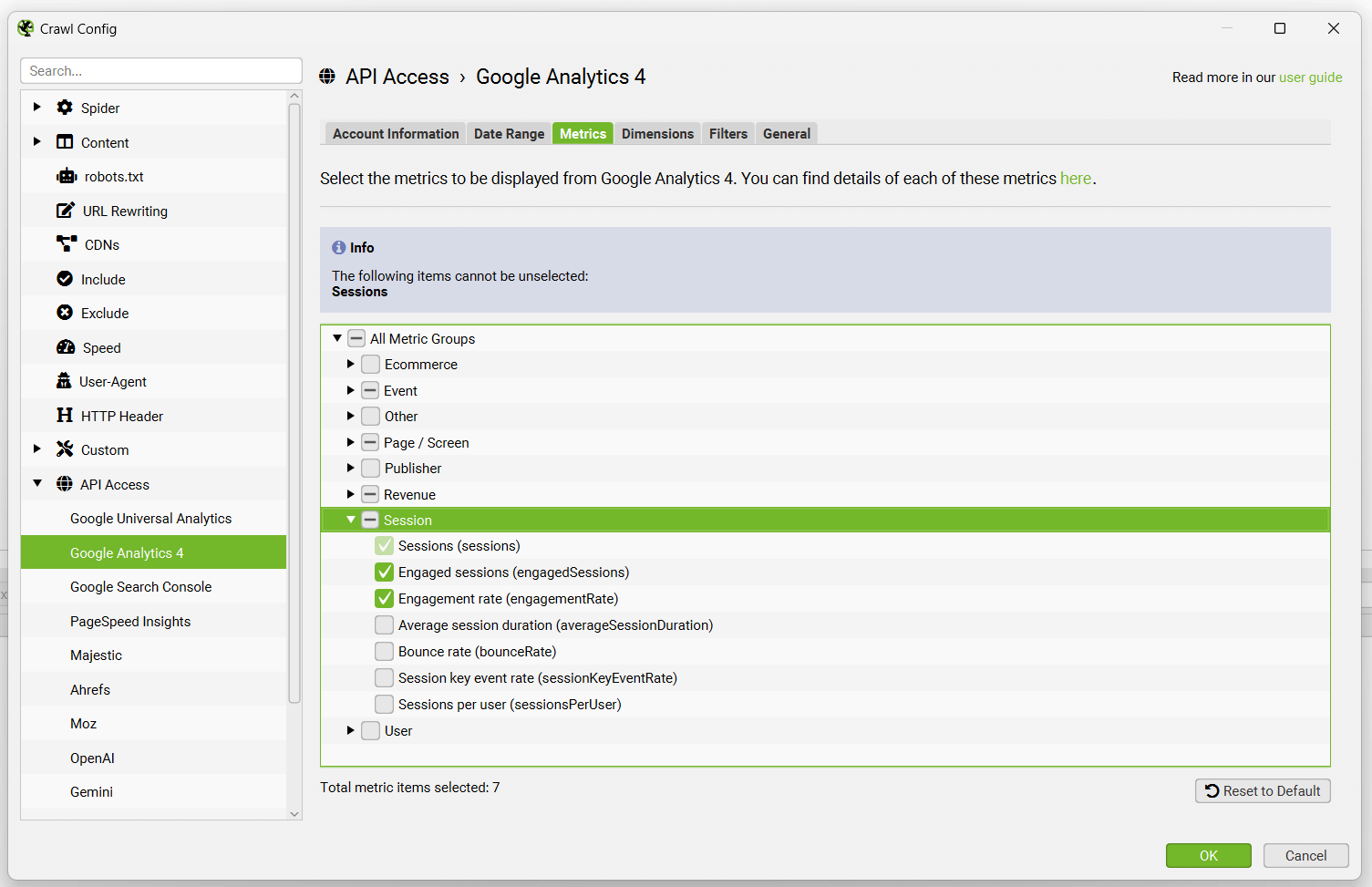
默认情况下,SEO Spider 在 GA4 中收集以下 7 个指标 -
- 会话数
- 互动会话数
- 互动率
- 浏览量
- 转化次数
- 事件计数
- 总收入
对于 GA4,您可以选择通过其 API 获得的最多 65 个指标。
您可以从 Google 的 GA4 维度和指标浏览器 中阅读有关可用指标以及每个指标的定义的更多信息。
您还可以将每个单独指标的维度设置为 完整页面 URL(UA 中的“页面路径”)或 着陆页,这两者截然不同(并且根据您的场景和目标都很有用)。
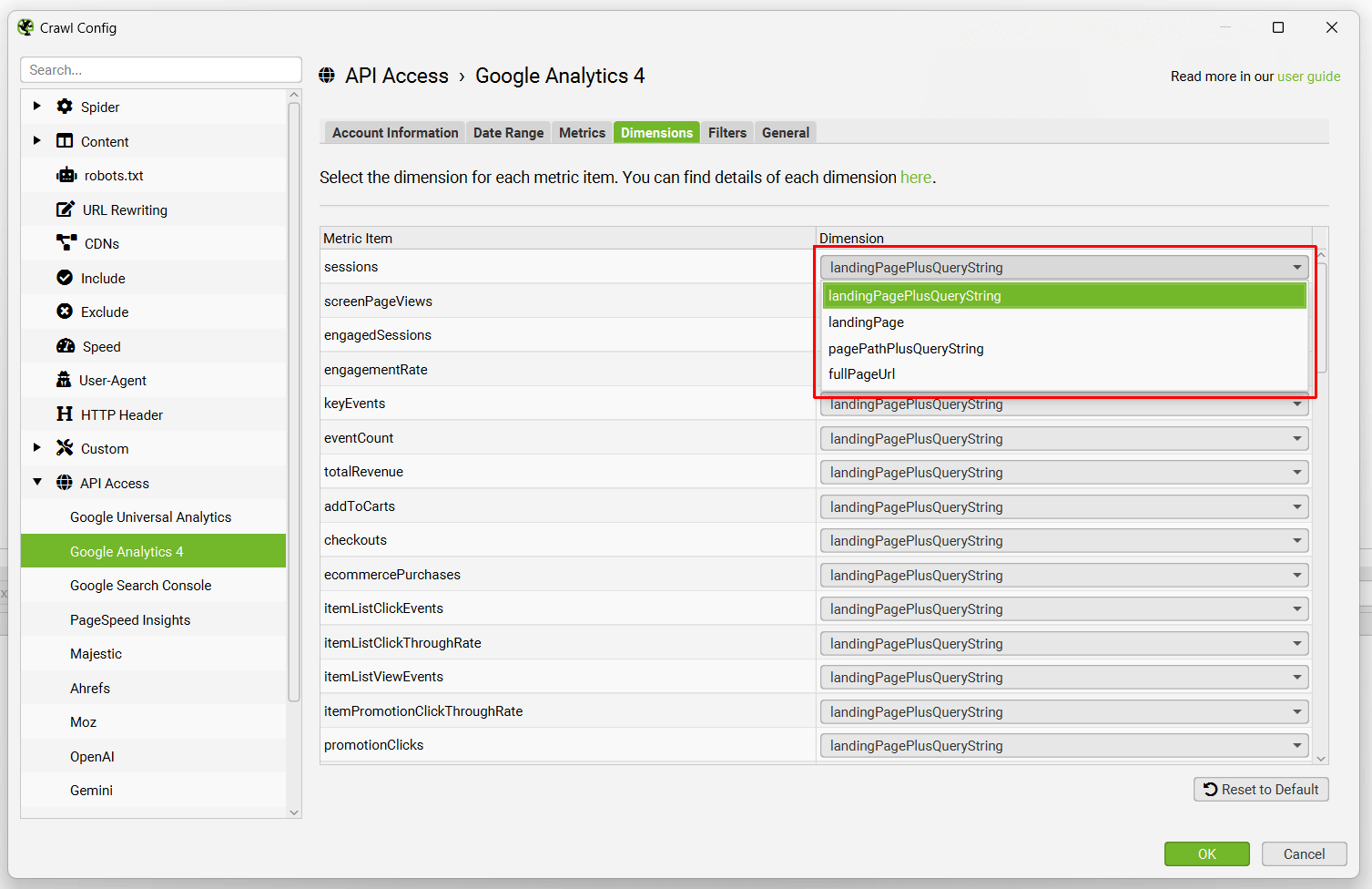
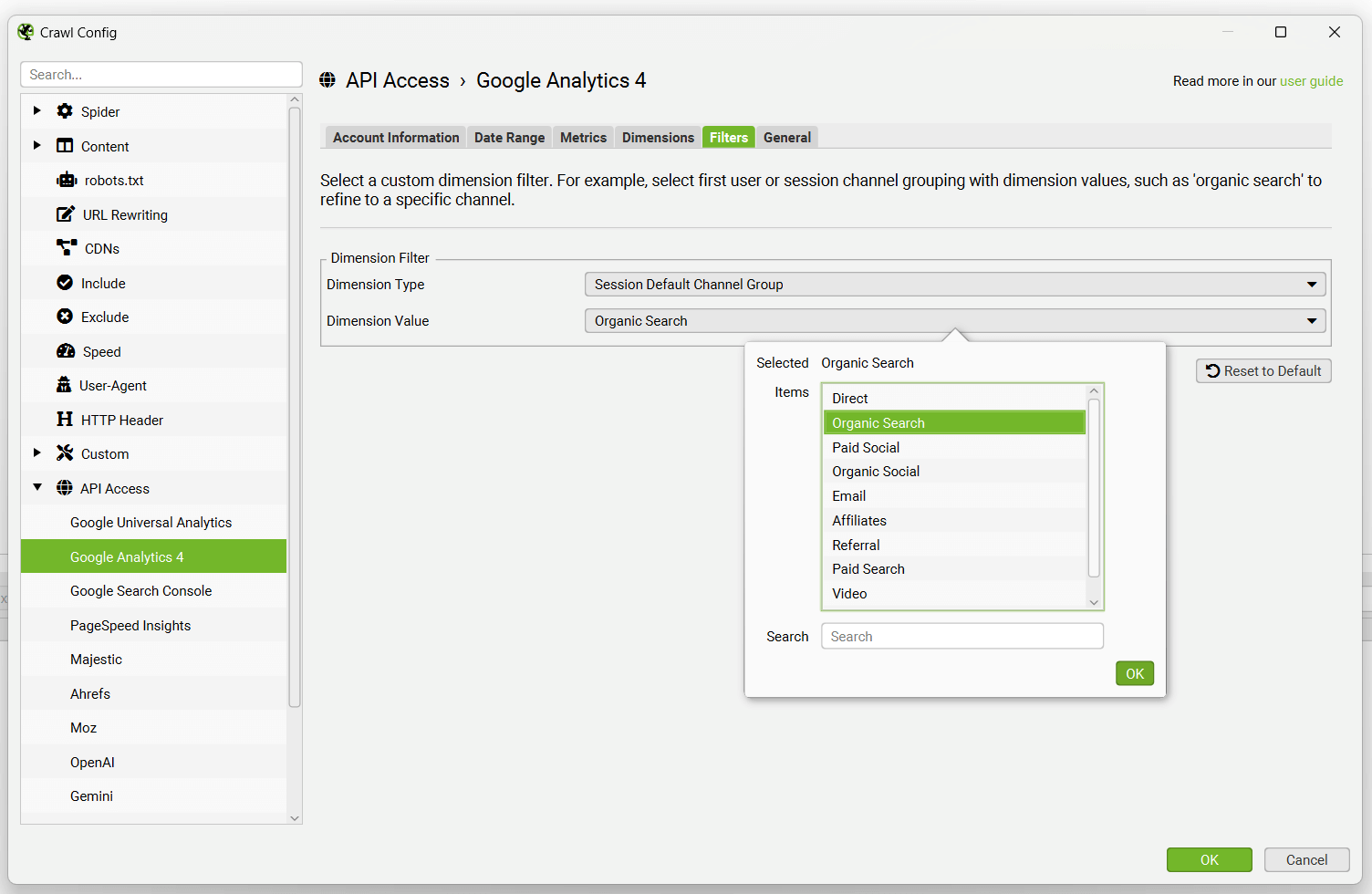
对于 GA4,还有一个“过滤器”选项卡,您可以在其中选择其他维度。例如,您可以选择具有维度值的第一个用户或会话渠道分组,例如“自然搜索”以细化到特定渠道。
在某些情况下,Google Analytics 中的 URL 可能与抓取中的 URL 不匹配,因此这些情况由自动匹配尾部和非尾部斜杠 URL 以及区分大小写(URL 中的大写和小写字符)来处理。Google 不通过其 API 传递协议(HTTP 或 HTTPS),因此这些也会自动匹配。
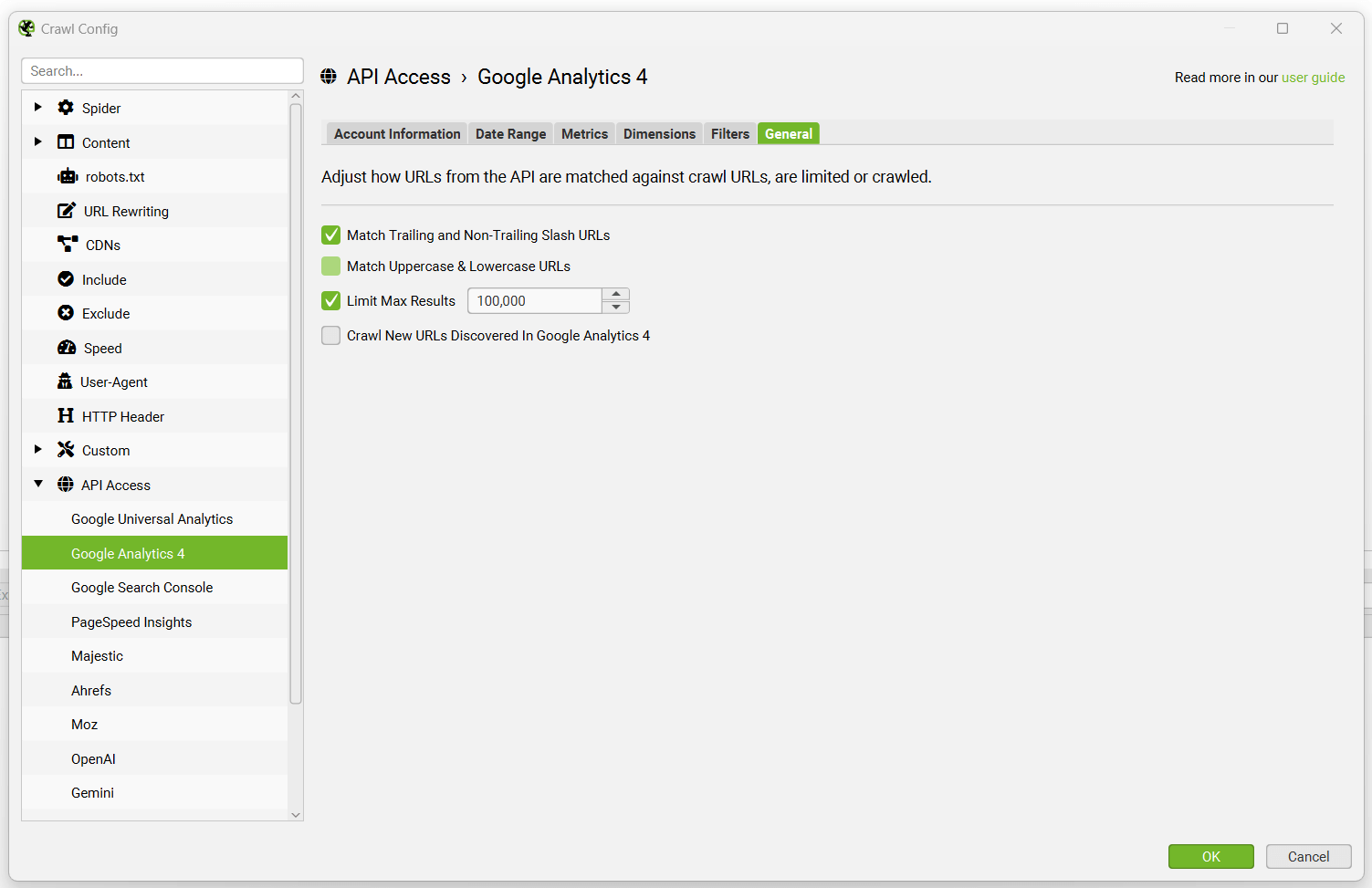
当选择上述任一选项时,请注意,Google Analytics 中的数据按会话排序,因此匹配是针对会话数最高的 URL 执行的。数据不会为这些 URL 聚合。
以下选项可用 -
- 匹配尾部和非尾部斜杠 URL – 允许 http://example.com/contact 和 http://example.com/contact/ 匹配来自 GA 的 http://example.com/contact 或 http://example.com/contact/,以会话数最高的为准。
- 匹配大写和小写 URL – 允许 http://example.com/contact.html、http://example.com/Contact.html 和 http://example.com/CONTACT.html 匹配来自 GA 的此 URL 的版本,以会话数最高的为准。
- 限�制最大结果数 – 如果您在 GA 中有成千上万个 URL,您可以选择限制要查询的 URL 数量,默认情况下按会话排序,以返回前 100,000 个 URL 的表现最佳的页面数据。
- 抓取在 Google Analytics 中发现的新 URL – 这意味着将在 Google Analytics 中发现的任何新 URL(未通过超链接找到)都将被抓取。如果未启用此选项,则通过 Google Analytics 发现的新 URL 只能在“孤立页面”报告中查看。它们不会添加到抓取队列,在用户界面中可见,并且会出现在相应的选项卡和过滤器下。请参阅我们关于查找孤立页面的指南。
Google Analytics 数据将在“内部”和“Analytics”选项卡中的相应列中获取和显示。
右上角有一个“API”进度条,当它达到 100% 时,分析数据将开始实时显示在 URL 上。查询的 URL 和指标越多,此过程可能需要的时间越长,但通常非常快。
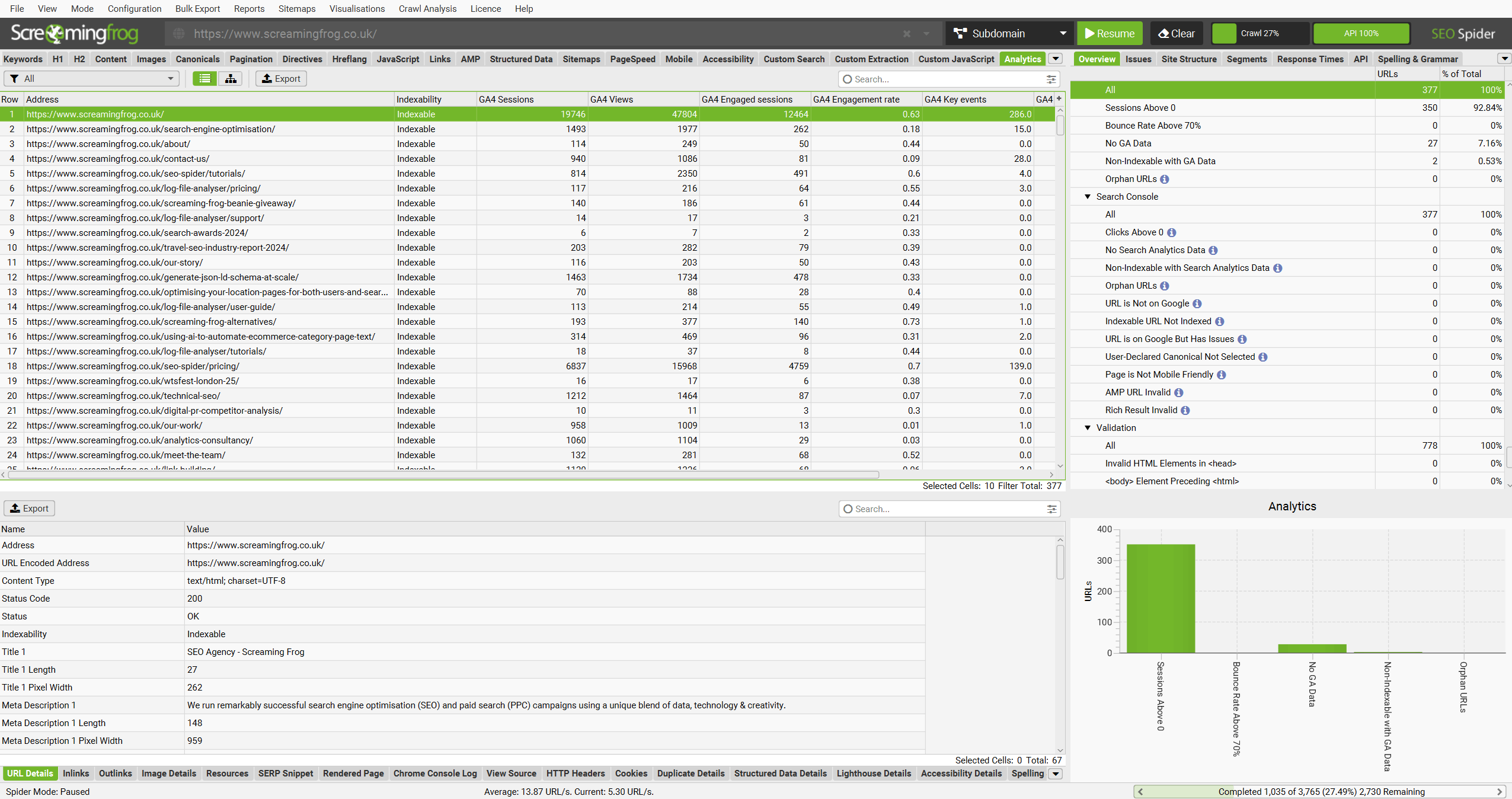
“Analytics”选项卡下目前有 5 个过滤器,您可以使用它们来过滤 Google Analytics 数据 -
- 会话数高于 0 – 这仅仅意味着相关 URL 具有 1 个或多个会话。
- 跳出率高于 70% – 这意味着 URL 的跳出率超过 70%,您可能希望对其进行调查。但在某些情况下,这是正常的!
- 无 GA 数据 – 这意味着对于查询的指标和维度,Google API 没有返回抓取中 URL 的任何数据。因此,URL 要么没有收到任何访问会话,要么抓取中的 URL 与 GA 中的 URL 因某种原因不同。
- 不可索引但具有 GA 数据 – 这意味着 URL 不可索引,但仍然具有来自 GA 的数据。
- 孤立 URL – 这意味着 URL 仅通过 GA 发现,并且在抓取期间未通过内部链接找到。
请阅读以下常见问题解答,了解在 SEO Spider 中访问 Google Analytics 数据的各种问题 -
- 为什么我在授予对我的 Google 帐户的访问权限时收到错误?
- 为什么我与 Google Analytics 的连接失败?
- 为什么 GA 数据没有填充到我的 URL 中?
- 为什么 SEO Spider 中的 GA API 数据与 GA 界面中报告的数据不匹配?
- 为什么我在连接我的 Google Analytics 帐户时看不到 GA4 媒体资源?
请注意,Google API 使用 OAuth 2.0 协议进行身份验证和授权,并且通过 Google Analytics 和其他 API 提供的数据只能在您的机器上本地访问。我们无法查看和存储这�些数据。请在我们的常见问题解答中查看更多信息。
使用 Google Analytics 4 API 受其核心令牌的标准媒体资源配额的约束。
Google Search Console 集成
配置 > API 访问 > Google Search Console
您可以连接到 Google Search Analytics 和 URL 检查 API,并在抓取期间直接拉取数据。
默认情况下,SEO Spider 将从 Search Analytics API 获取展示次数、点击次数、点击率和位置指标,以便您可以查看在执行技术或内容审核时表现最佳的页面。
或者,您也可以选择在 Search Analytics 数据旁边“启用 URL 检查”,这每天为每个媒体资源提供最多 2,000 个 URL 的 Google 索引状态数据。这包括“URL 在 Google 上”或“URL 不在 Google 上”以及覆盖率。
要进行设置,请转到“配置 > API 访问 > Google Search Console”。
通过授予“Screaming Frog SEO Spider”应用程序访问您的帐户以检索数据的权限,连接到 Google 帐户(该帐户有权访问您希望查询的 Search Console 帐户)。Google API 使用 OAuth 2.0 协议进行身份验证和授权。SEO Spider 将记住您在列表中授权的任何 Google 帐户,因此您每次启动应用程序时都可以快速“连接”。
连接后,您可以选择相关的网站媒体资源。
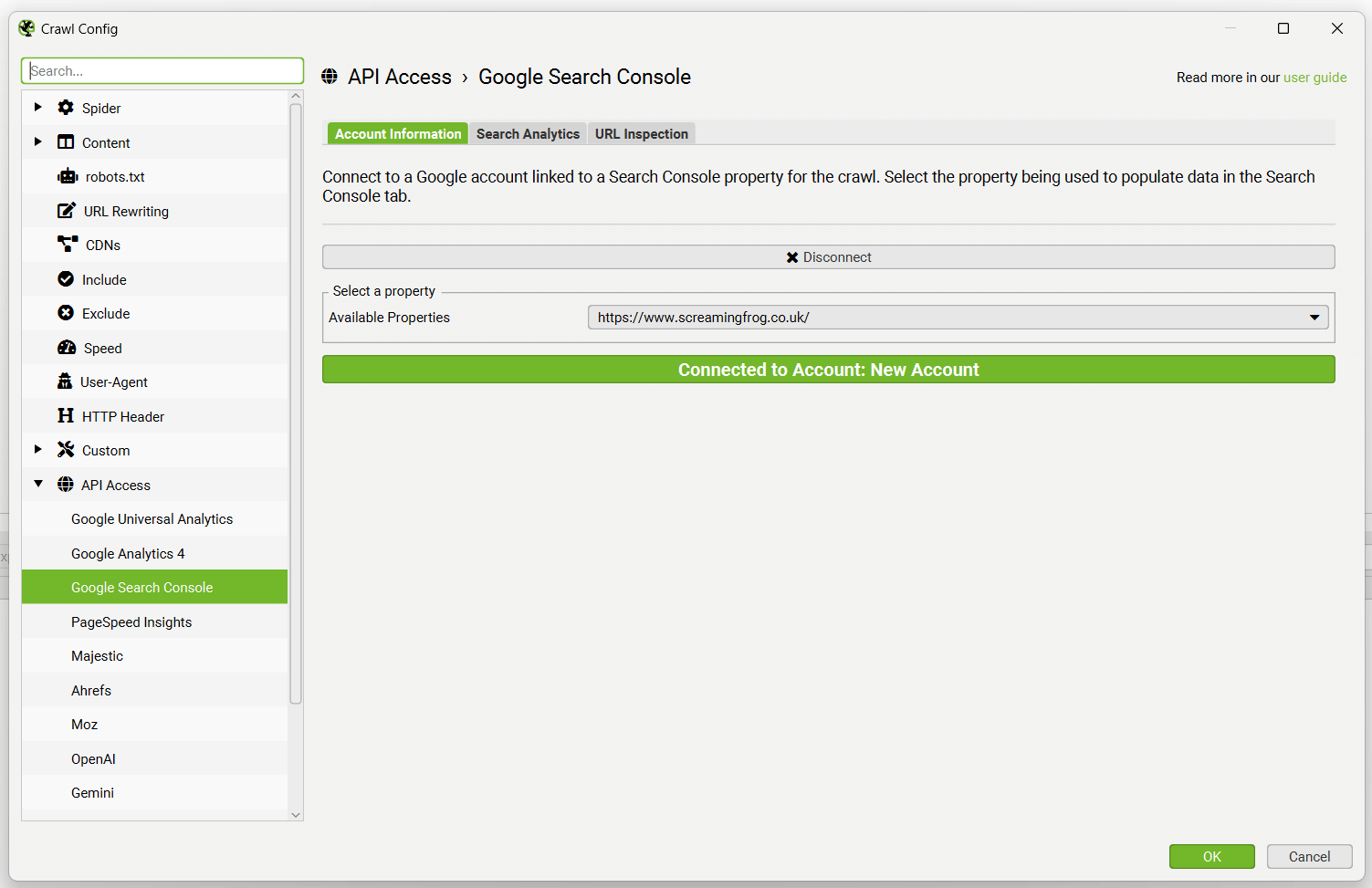
默认情况下,SEO Spider 会收集过去 30 天的以下指标 -
- 点击次数
- 展示次数
- 点击率
- 位置
阅读有关 Google 对每个指标的定义 的更多信息。
如果您单击配置中的“Search Analytics”选项卡,您可以调整日期范围、维度和各种其他设置。
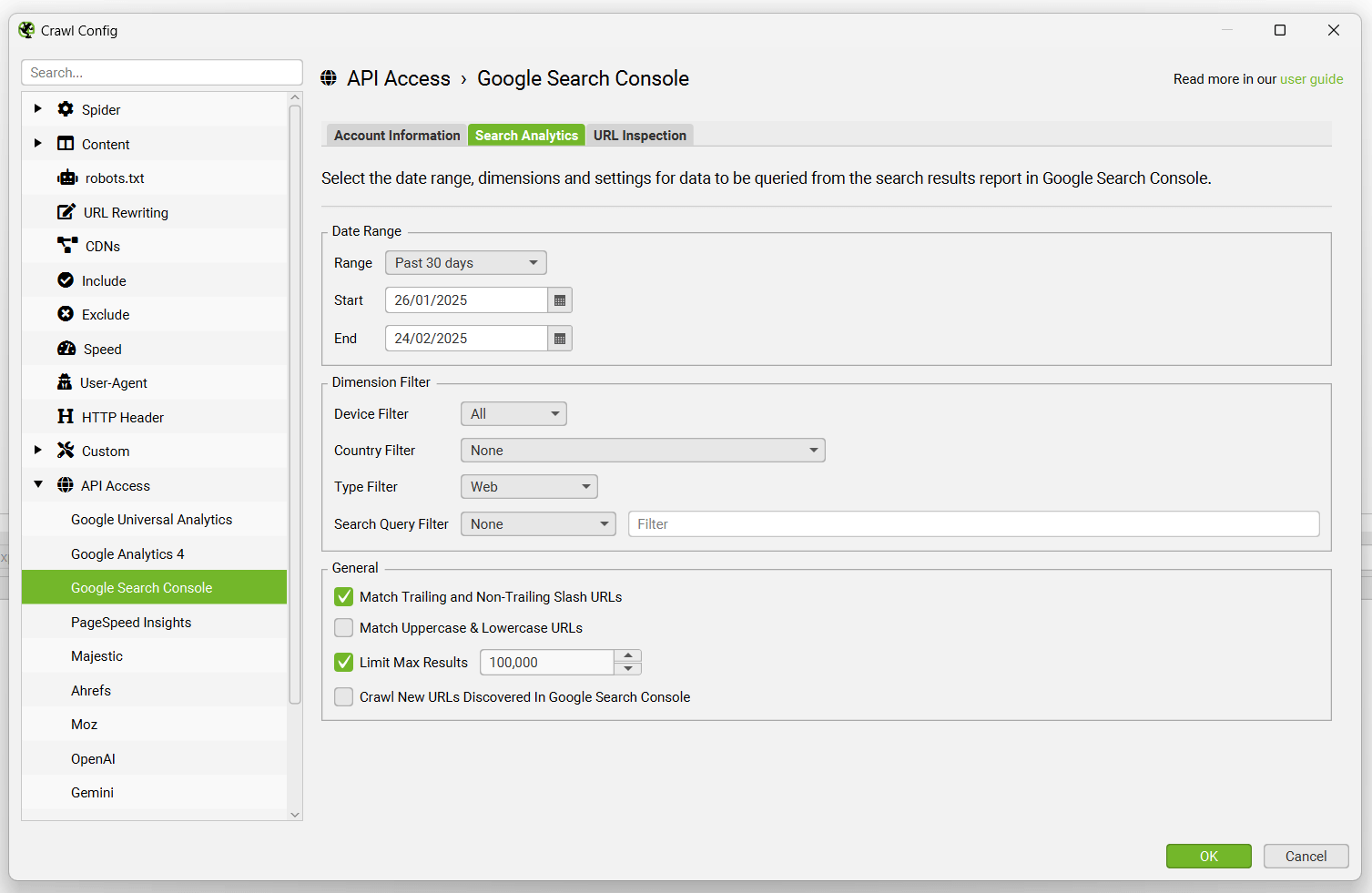
如果您希望抓取从 Google Search Console 发现的新 URL 以查找任何潜在的孤立页面,请记住启用如下所示的配置。
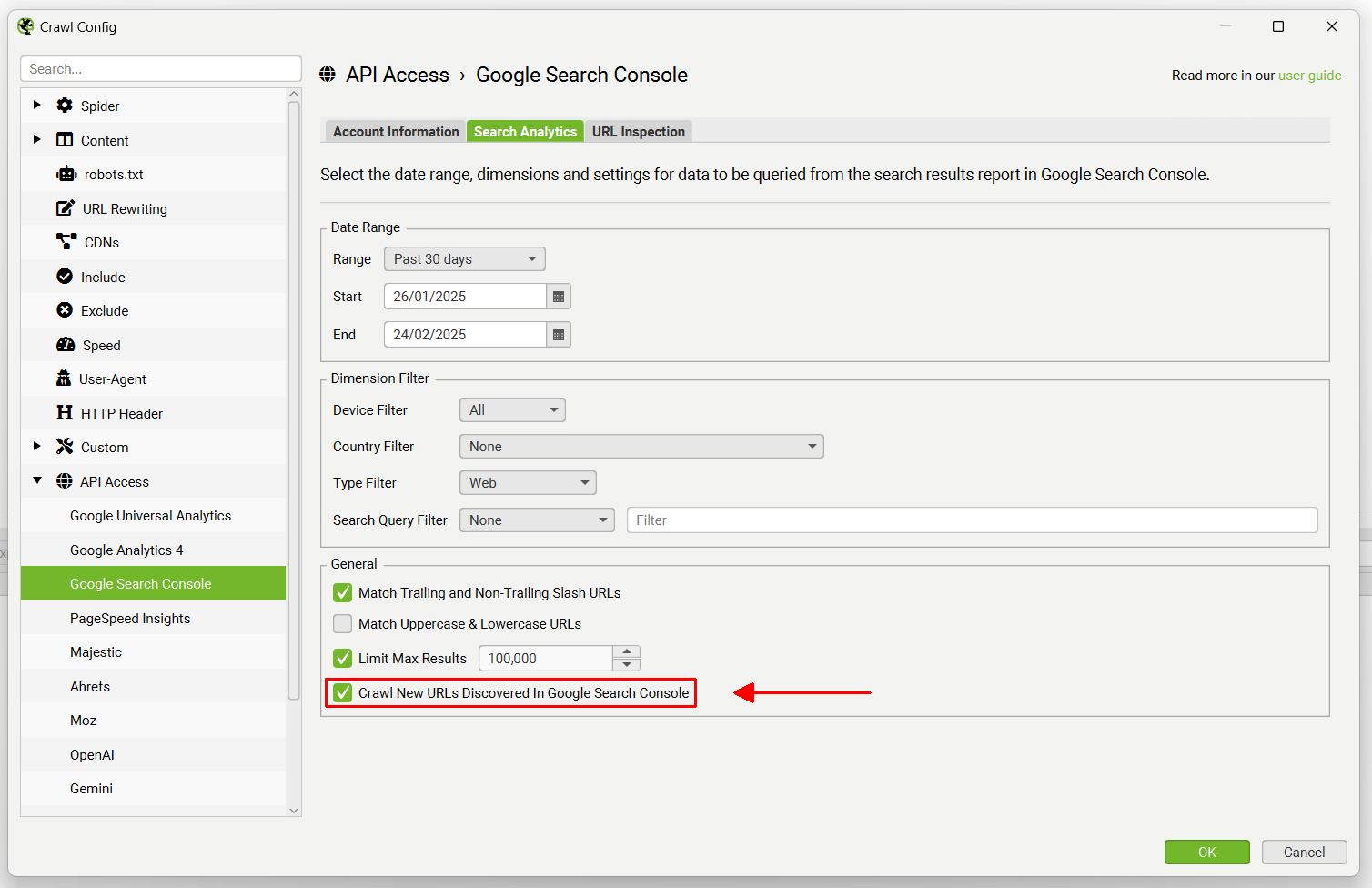
或者,您可以导航到“URL 检查”选项卡并“启用 URL 检查”以收集有关抓取中最多 2,000 个 URL 的索引状态的数据。
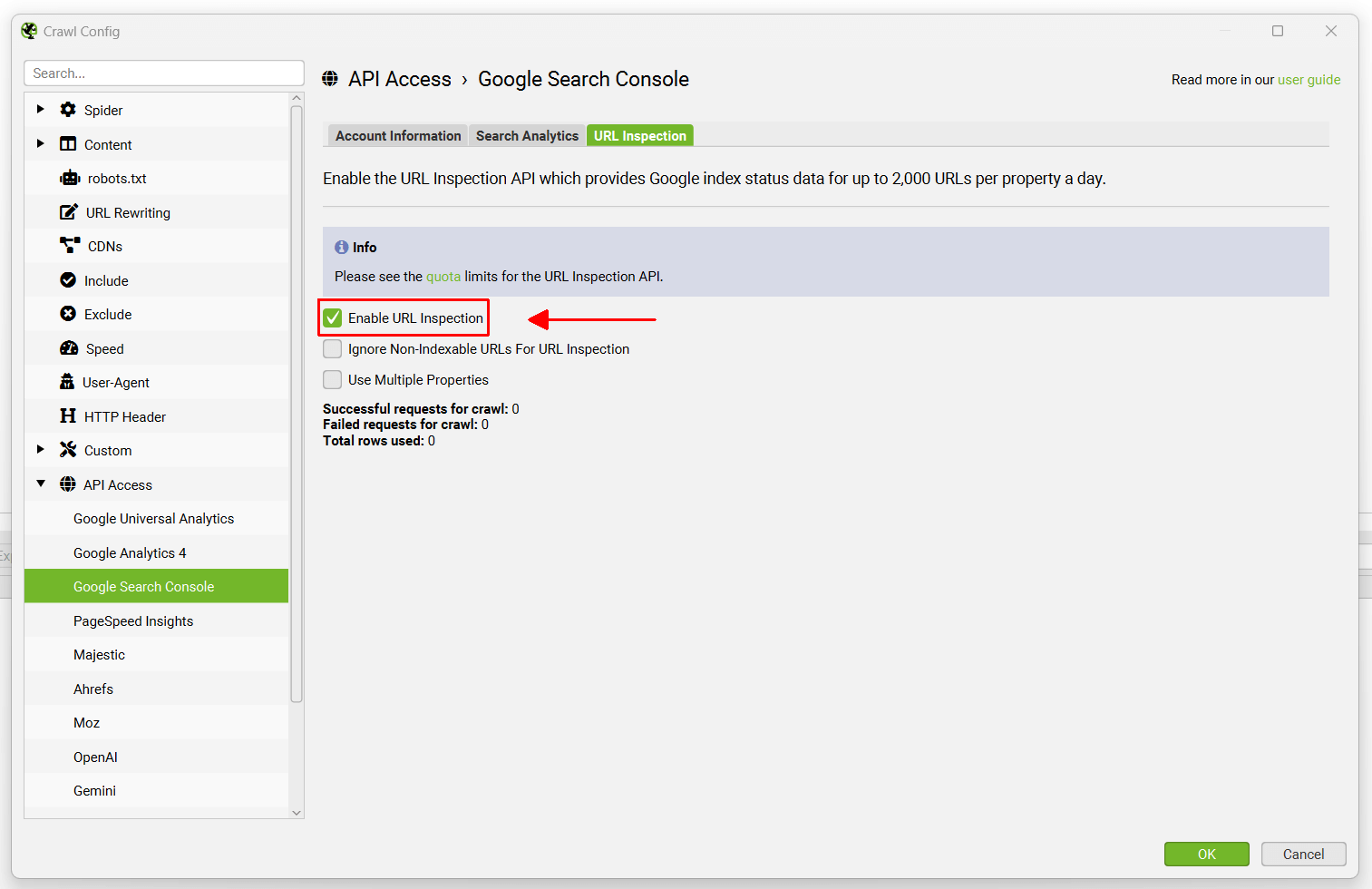
SEO Spider 默认情况下按广度优先抓取,这意味着通过从抓取开始页面的抓取深度。将查询发现的前 2k 个 HTML URL,因此请将抓取重点放在特定部分,使用 包含 和 排除 的配置,或 列表模式 以获取您需要的关键 URL 和模板的数据。
以下配置选项可用 -
- 忽略不可编入索引的 URL 以进行 URL 检查 – 这意味着抓取中任何被归类为“不可编入索引”的 URL 都不会通过 API 查询。只有可编入索引的 URL 才会查询,如果您对站点的设置有信心,这有助于节省您的检查配额。
- 使用多个属性 – 如果为同一域名验证了多个属性,SEO Spider 将自动检测帐户中的所有相关属性,并使用最具体的属性来请求 URL 的数据。这意味着,如果设置了多个属性,现在可以在单个抓取中获得远超 2k 个带有 URL Inspection API 数据的 URL,而无需执行多次抓取。
URL Inspection API 包括以下数据。
- 摘要 – 关于 URL 是否已编入索引并符合在 Google 搜索结果中显示的资格的顶级判断。“URL 在 Google 上”表示该 URL 已编入索引,可以出现在 Google 搜索结果中,并且在页面中发现的任何增强功能(富媒体搜索结果、移动设备、AMP)都没有发现问题。“URL 在 Google 上,但存在问题”表示该 URL 已编入索引,可以出现在 Google 搜索结果中,但移动设备可用性、AMP 或富媒体搜索结果存在一些问题,这可能意味着�它不会以最佳方式显示。“URL 不在 Google 上”表示该 URL 未被 Google 编入索引,也不会出现在搜索结果中。此过滤器可以包括不可编入索引的 URL(例如那些“noindex”的 URL)以及能够编入索引的可编入索引的 URL。
- 覆盖率 – 对 URL 状态的简短描述性原因,解释了 URL 为何在或不在 Google 上。
- 上次抓取 – Google 上次抓取此页面的时间,以您当地时间显示。此工具中显示的所有信息均来自上次抓取的版本。
- 抓取方式 – 用于抓取的用户代理类型(桌面设备或移动设备)。
- 允许抓取 – 指示您的站点是否允许 Google 抓取(访问)该页面,或者是否使用 robots.txt 规则阻止了它。
- 页面抓取 – Google 是否能够实际从您的服务器获取该页面。如果不允许抓取,则此字段将显示失败。
- 允许索引 – 您的页面是否明确禁止索引。如果禁止索引,则会解释原因,并且该页面不会出现在 Google 搜索结果中。
- 用户声明的规范网址 – 如果您的页面明确声明了规范 URL,它将在此处显示。
- Google 选择的规范网址 – Google 选择作为规范(权威)URL 的页面,当它在您的站点上找到相似或重复的页面时。
- 移动设备可用性 – 页面是否适合移动设备。
- 移动设备可用性问题 – 如果“页面不适合移动设备”,则此列将显示移动设备可用性错误的列表。
- AMP 结果 – 关于 AMP URL 是否有效、无效或有警告的判断。“有效”表示 AMP URL 有效且已编入索引。“无效”表示 AMP URL 存在阻止其被编入索引的错误。“有效但有警告”表示 AMP URL 可以被编入索引,但存在一些可能阻止其获得完整功能的问题,或者它使用已弃用的标签或属性,并且将来可能变为无效。
- AMP 问题 – 如果 URL 存在 AMP 问题,则此列将显示 AMP 错误的列表。
- 富媒体搜索结果 – 关于在页面上找到的富媒体搜索结果是否有效、无效或有警告的判断。“有效”表示已找到富媒体搜索结果并且符合搜索条件。“无效”表示页面上的一个或多个富媒体搜索结果存在阻止其符合搜索条件的错误。“有效但有警告”表示页面上的富媒体搜索结果符合搜索条件,但存在一些可能阻止其获得完整功能的问题。
- 富媒体搜索结果类型 – 在页面上发现的所有富媒体搜索结果增强功能的逗号分隔列表。
- 富媒体搜索结果类型错误 – 在页面上发现的所有存在错误的富媒体搜索结果增强功能的逗号分隔列表。要导出发现的特定错误,请使用“批量导出 > URL 检查 > 富媒体搜索结果”导出。
- 富媒体搜索结果警告 – 在页面上发现的所有存在警告的富媒体搜索结果增强功能的逗号分隔列表。要导出发现的特定警告,请使用“批量导出 > URL 检查 > 富媒体搜索结果”导出。
您可以阅读更多关于 来自 Google 的已编入索引的 URL 结果。
在“Search Console”选项卡下有 11 个过滤器,您可以使用这些过滤器来过滤来自两个 API 的 Google Search Console 数据。
- 点击次数大于 0 – 这仅仅意味着有问题的 URL 具有 1 次或更多次点击。
- 没有搜索分析数据 – 这意味着 Search Analytics API 没有返回抓取中 URL 的任何数据。因此,URL 要么没有收到任何展示,要么��抓取中的 URL 由于某种原因与 GSC 中的 URL 不同。
- 不可编入索引但具有搜索分析数据 – 被归类为不可编入索引但具有 Google 搜索分析数据的 URL。
- 孤立 URL – 通过 Google 搜索分析发现的 URL,而不是在抓取期间通过内部链接发现的 URL。此过滤器需要在 Google Search Console 配置窗口(配置 > API 访问 > Google Search Console)的“常规”选项卡下启用“抓取在 Google Search Console 中发现的新 URL”,并在填充“抓取分析”后启用。请参阅我们的如何查找孤立页面指南。
- URL 不在 Google 上 – 该 URL 未被 Google 编入索引,也不会出现在搜索结果中。此过滤器可以包括不可编入索引的 URL(例如那些“noindex”的 URL)以及能够编入索引的可编入索引的 URL。它是根据 API 显示的任何不在 Google 上的内容的包罗万象的过滤器。
- 可编入索引的 URL 未编入索引 – 在抓取中找到的、未被 Google 编入索引且不会出现在搜索结果中的可编入索引的 URL。这可以包括 Google 未知的 URL,或者已被发现但未编入索引的 URL 等。
- URL 在 Google 上,但存在问题 – 该 URL 已编入索引,可以出现在 Google 搜索结果中,但移动设备可用性、AMP 或富媒体搜索结果存在一些问题,这可能意味着它不会以最佳方式显示。
- 用户声明的规范网址未被选择 – Google 已选择索引与用�户在 HTML 中声明的 URL 不同的 URL。规范网址是提示,有时 Google 在这方面做得很好,有时则不太理想。
- 页面不适合移动设备 – 该页面在移动设备上存在问题。
- AMP URL 无效 – AMP 存在阻止其被编入索引的错误。
- 富媒体搜索结果无效 – 该 URL 在一个或多个富媒体搜索结果增强功能中存在错误,这将阻止富媒体搜索结果显示在 Google 搜索结果中。要导出发现的特定错误,请使用“批量导出 > URL 检查 > 富媒体搜索结果”导出。
请参阅我们的关于“如何自动化 URL Inspection API”的教程。
PageSpeed Insights 集成
配置 > API 访问 > PageSpeed Insights
您可以连接到 Google PageSpeed Insights API,并在抓取期间直接提取页面速度和移动设备可用性数据。
PageSpeed Insights 使用 Lighthouse,因此 SEO Spider 能够显示 Lighthouse 速度指标,大规模分析速度机会和诊断,并从 Chrome 用户体验报告 (CrUX) 收集真实世界的数据,其中包含来自真实用户监控 (RUM) 的 Core Web Vitals。Lighthouse 还能够报告移动设备可用性问题。
有两种运行 PageSpeed Insights 的选项,“远程”和“本地”。
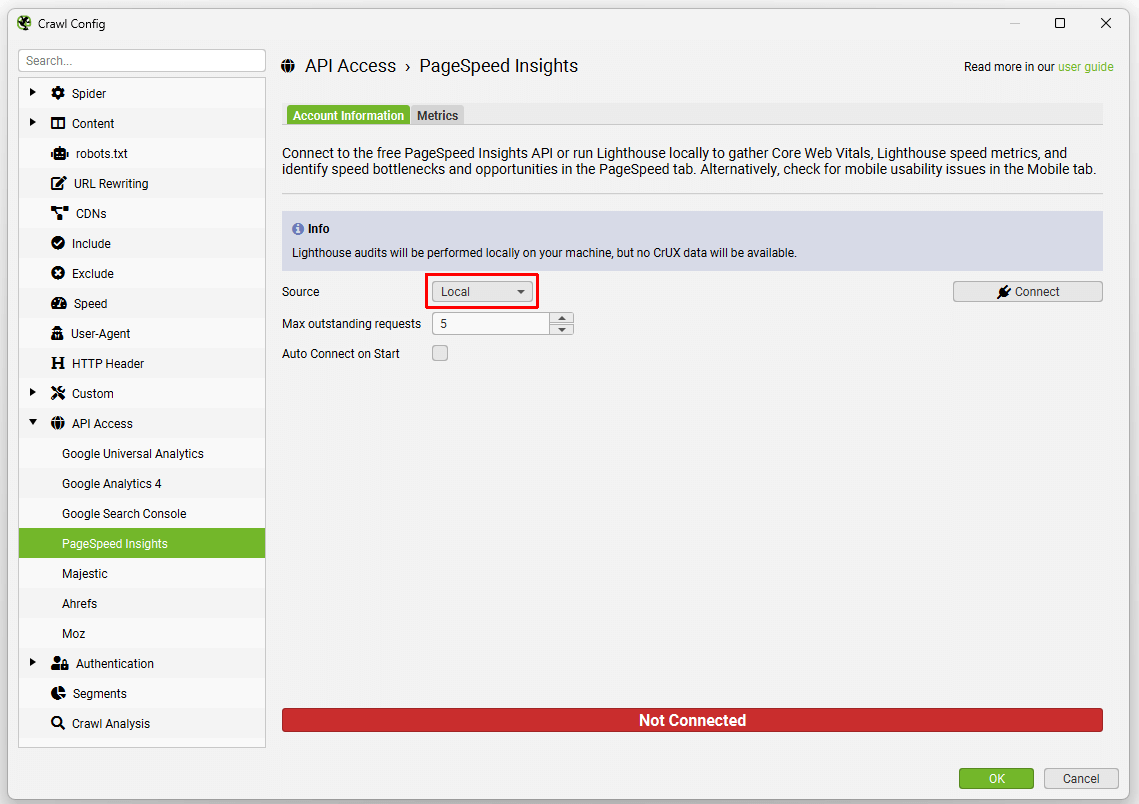
- 远程意味着 Lighthouse 在远程服务器上的 URL 上运行,数据通过 API 返回到 SEO Spider。好处是它不会消耗您的机器资源来运行 Lighthouse。它还可以获取 CrUX 页面速度数据。
- 本地意味着 Lighthouse 直接在用户的机器上运行。好处是这可以用于需要身份验证才能访问的站点,并且它不像 API 那样每天限制为 25k 个查询。但是,通过在本地运行 Lighthouse,CrUX 数据不可用。
启动 SEO Spider 并转到“配置 > API 访问 > PageSpeed Insights”,选择“源”,如有必要,输入免费的 PageSpeed Insights API 密钥,选择您的指标,连接并抓取。
设置 PageSpeed Insights API 密钥
要设置免费的 PageSpeed Insights API 密钥,请登录您的 Google 帐户,然后访问 PageSpeed Insights 入门页面。
进入页面后,向下滚动一段,然后单击“获取密钥”按钮。
然后按照创建密钥的过程进行操作 – 通过提交项目名称、同意条款和条件并单击“��下一步”。
然后它将为 PSI 启用密钥并提供可以复制的 API 密钥。
复制密钥,然后单击“完成”。
然后只需将其粘贴到 SEO Spider “密钥:”字段下的“配置 > API 访问 > PageSpeed Insights”中,然后按“连接”。此密钥用于在 https://www.googleapis.com/pagespeedonline/v5/runPagespeed 上调用 API。
就是这样,您现在已连接!SEO Spider 将记住您的密钥,因此您每次启动应用程序时都可以快速“连接”。
如果您发现您的 API 密钥显示“连接失败”,则可能需要几分钟才能激活。您还可以检查 PSI API 是否已按照我们的 FAQ 在 API 库中启用。如果未启用,请启用它 – 然后它应该允许您连接。
连接后,您可以选择要在“指标”选项卡下查询的指标和设备。
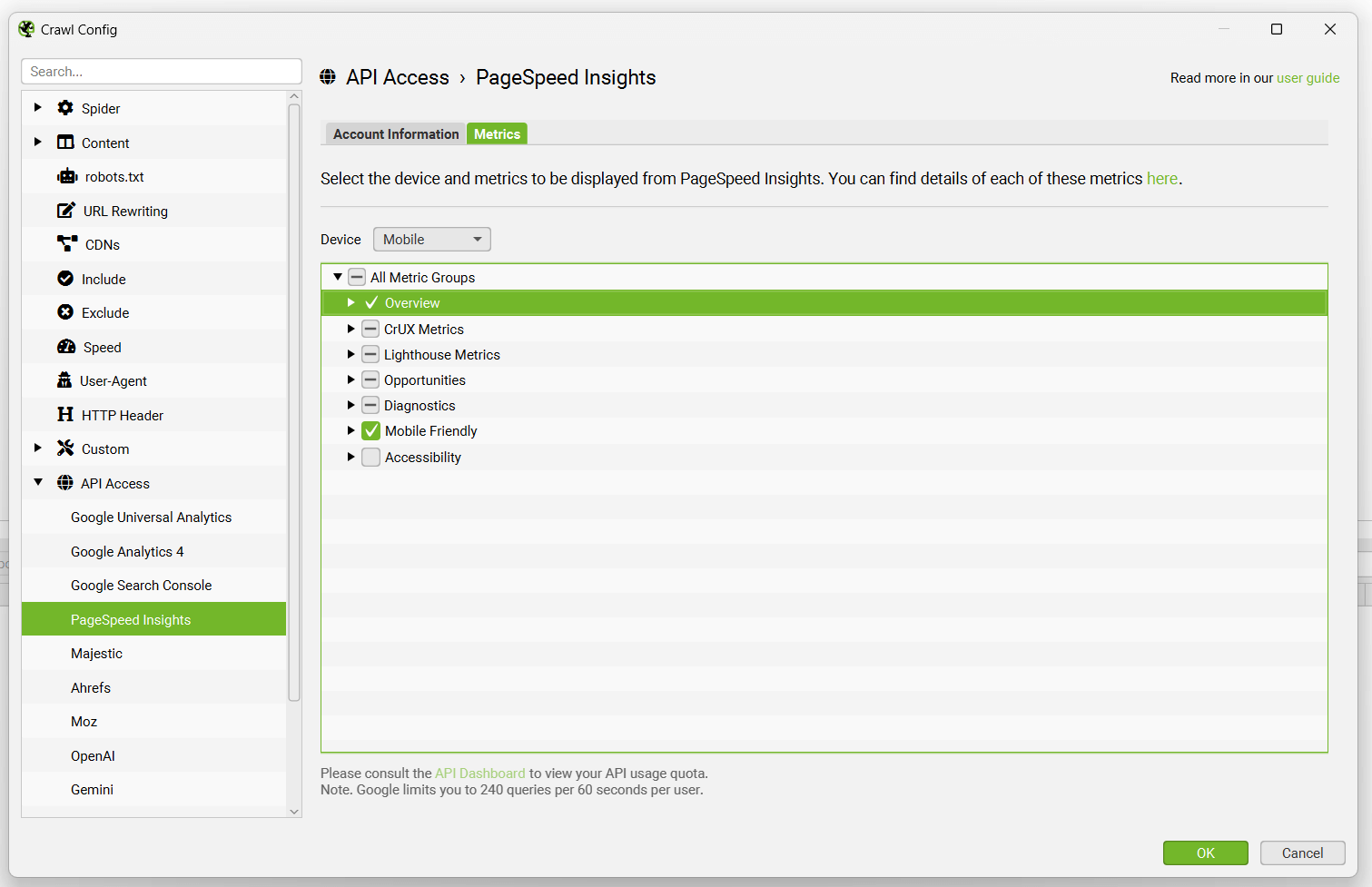
可以配置以下速度指标、机会和诊断数据,以通过 PageSpeed Insights API 集成收集。
概述指标
- 总大小节省
- 总时间节省
- 总请求数
- 总页面大小
- HTML 大小
- HTML 计数
- 图像大小
- 图像计数
- CSS 大小
- CSS 计数
- JavaScript 大小
- JavaScript 计数
- 字体大小
- 字体计数
- 媒体大小
- 媒体计数
- 其他大小
- 其他计数
- 第三方大小
- 第三方计数
CrUX 指标(PageSpeed Insights 中的“现场数据”)
- Core Web Vitals 评估
- CrUX 首次内容绘制时间(秒)
- CrUX 首次内容绘制类别
- CrUX 首次输入延迟时间(秒)
- CrUX 首次输入延迟类别
- CrUX 最大内容绘制时间(秒)
- CrUX 最大内容绘制类别
- CrUX 累积布局偏移
- CrUX 累积布局偏移类别
- CrUX 与下一次绘制的交互(毫秒)
- CrUX 与下一次绘制的交互类别
- CrUX 到第一个字节的时间(毫秒)
- CrUX 到第一个字节的时间类别
- CrUX 原始 Core Web Vitals 评估
- CrUX 原始首次内容绘制时间(秒)
- CrUX 原始首次内容绘制类别
- CrUX 原始首次输入延迟时间(秒)
- CrUX 原始首次输入延迟类别
- CrUX 原始最大内容绘制时间(秒)
- CrUX 原始最大内容绘制类别
- CrUX 原始累积布局偏移
- CrUX 原始累积布局偏移类别
- CrUX 原始与下一次绘制的交互(毫秒)
- CrUX 原始与下一次绘制的交互类别
- CrUX 原始到第一个字节的时间(毫秒)
- CrUX 原始到第一个字节的时间类别
Lighthouse 指标(PageSpeed Insights 中的“实验室数据”)
- 性能得分
- 到第一个字节的时间(毫秒)
- 首次内容绘制时间(秒)
- 首次内容绘制得分
- 速度指数时间(秒)
- 速度指数得分
- 最大内容绘制时间(秒)
- 最大内容绘制得分
- 交互时间(秒)
- 交互时间得分
- 首次有意义绘制时间(秒)
- 首次有意义绘制得分
- 最大潜在首次输入延迟(毫秒)
- 最大潜在首次输入延迟得分
- 总阻塞时间(毫秒)
- 总阻塞时间得分
- 累积布局偏移
- 累积布局偏移得分
机会
- 消除渲染阻塞资源节省(毫秒)
- 延迟屏幕外图像节省(毫秒)
- 延迟屏幕外图像节省
- 有效编码图像节省(毫秒)
- 有效编码图像节省
- 正确调整图像大小节省(毫秒)
- 正确调整图像大小节省
- 缩小 CSS 节省(毫秒)
- 缩小 CSS 节省
- 缩小 JavaScript 节省(毫秒)
- 缩小 JavaScript 节省
- 减少未使用的 CSS 节省(毫秒)
- 减少未使用的 CSS 节省
- 减少未使用的 JavaScript 节省(毫秒)
- 减少未使用的 JavaScript 节省
- 以下一代格式提供图像节省(毫秒)
- 以下一代格式提供图像节省
- 启用文本压缩节省(毫秒)
- 启用文本压缩节省
- 预连接到所需原始节省
- 服务器响应时间 (TTFB)(毫秒)
- 服务器响应时间 (TTFB) 类别(毫秒)
- 多个重定向节省(毫秒)
- 预加载关键请求节省(毫秒)
- 对动画图像使用视频格式节省(毫秒)
- 对动画图像使用视频格式节省
- 总图像优化节省(毫秒)
- 避免向现代浏览器提供旧版 JavaScript 节省
诊断
- DOM 元素计数
- JavaScript 执行时间(秒)
- JavaScript 执行时间类别
- 有效的缓存策略节省
- 最小化主线程工作(秒)
- 最小化主线程工作类别
- 文本在 Webfont 加载期间保持可见
- 图像元素没有明确的宽度和高度
- 避免大型布局偏移
移动设备友好
- 未设置视口
- 目标大小
- 内容宽度
- 字体显示大小
要查看发现的数据和问题,请查看 SEO Spider 中的 PageSpeed 标签 和 Mobile 标签。
有关发现的每个问题、��警告或机会的更多详细信息,请参阅我们的 SEO 问题 库。
请阅读 Lighthouse 性能审核指南,以获取上述每个机会和诊断的更多定义和解释。
可以通过“Reports > PageSpeed”菜单批量导出具有潜在节省速度的机会、源页面和资源 URL。
PageSpeed Insights API 限制
该 API 限制为每天 25,000 个查询,每个用户每 100 秒 60 个查询。 SEO Spider 自动控制请求速率,以保持在这些限制范围内。 在这些限制下,最佳情况是 SEO Spider 每分钟可以请求 36 个 URL。 因此,对于 10,000 个 URL 的爬网,这将花费 4.5 个多小时。
请查阅 API 仪表板 的“配额”部分,以查看您的 API 使用配额。
PageSpeed Insights API 错误
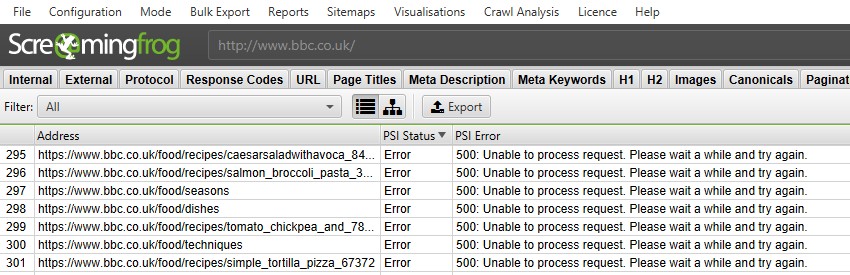
PSI 状态列显示 URL 的 API 请求是否成功,或者是否存在错误。“错误”通常反映 Web 界面,您将在其中看到相同的错误和消息。
以下是两个最常见的错误消息:
- “500: 无法处理请求。请稍等片刻,然后重试” – 此错误通常可以在 Web 界面中重现,我们的测试表明,PSI API 有时无法处理请求,可能是由于总体负载能力。 如果发生这种情况,我们建议暂停爬网 10 分钟,直到它再次可用并在 Web 界面中工作,然后右键单击并“重新爬取”URL。 这将重新请求所选 URL 的 PSI 数据,并继续爬取和请求其他 URL 的 API 数据。
- “500: Lighthouse 返回错误:ERRORED_DOCUMENT_REQUEST。 Lighthouse 无法可靠地加载您请求的页面。” – 此错误通常也可以在 Web 界面中重现,并且不是 SEO Spider 或 API 的问题,它与 PSI 执行的 Lighthouse 审核直接相关。 不幸的是,“重新爬取”这些 URL 以重新请求 API 数据通常没有帮助。 您可以直接在其 邮件列表 上向 Google 提供有关您遇到的任何错误的反馈,或者通过 Stack Overflow 提出问题。
请阅读我们的 PageSpeed Insights API 错误 常见问题解答,以获取更多信息。
Majestic
Configuration > API Access > Majestic
要使用 Majestic,您需要一个允许您从其 API 中提取数据的订阅。 然后,您只需导航到“Configuration > API Access > Majestic”,然后单击“generate an Open Apps access token”链接。
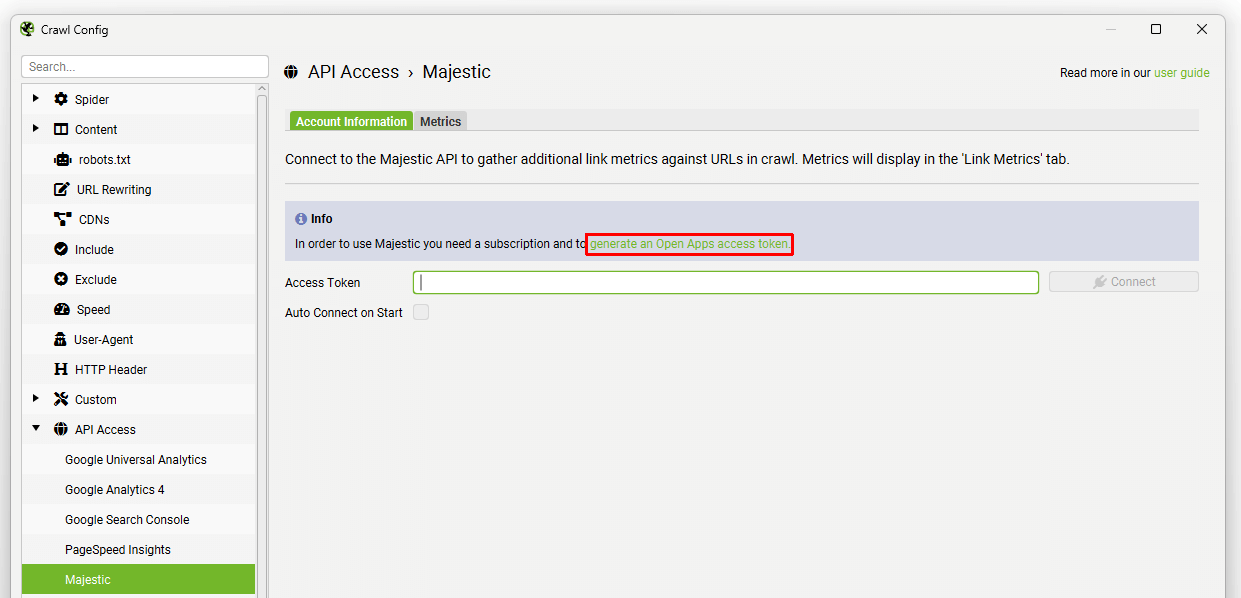
然后,您将被带到 Majestic,您需要在其中“授予”对 Screaming Frog SEO Spider 的访问权限。
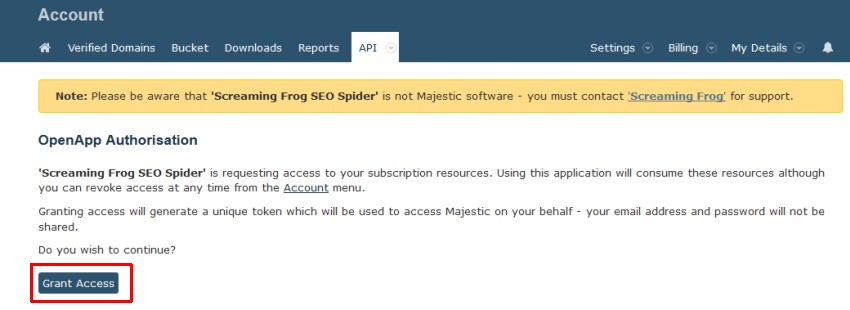
然后,您将从 Majestic 获得一个唯一的访问令牌。
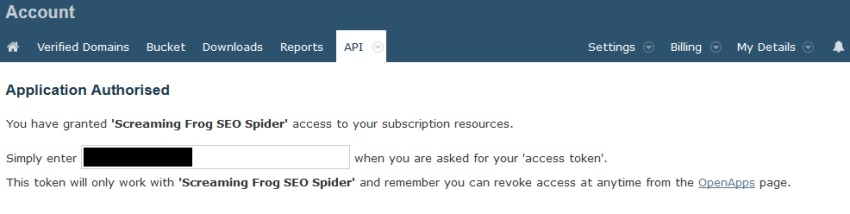
将此令牌复制并输入到 Majestic 窗口中的 API 密钥框中,然后单击“connect” –
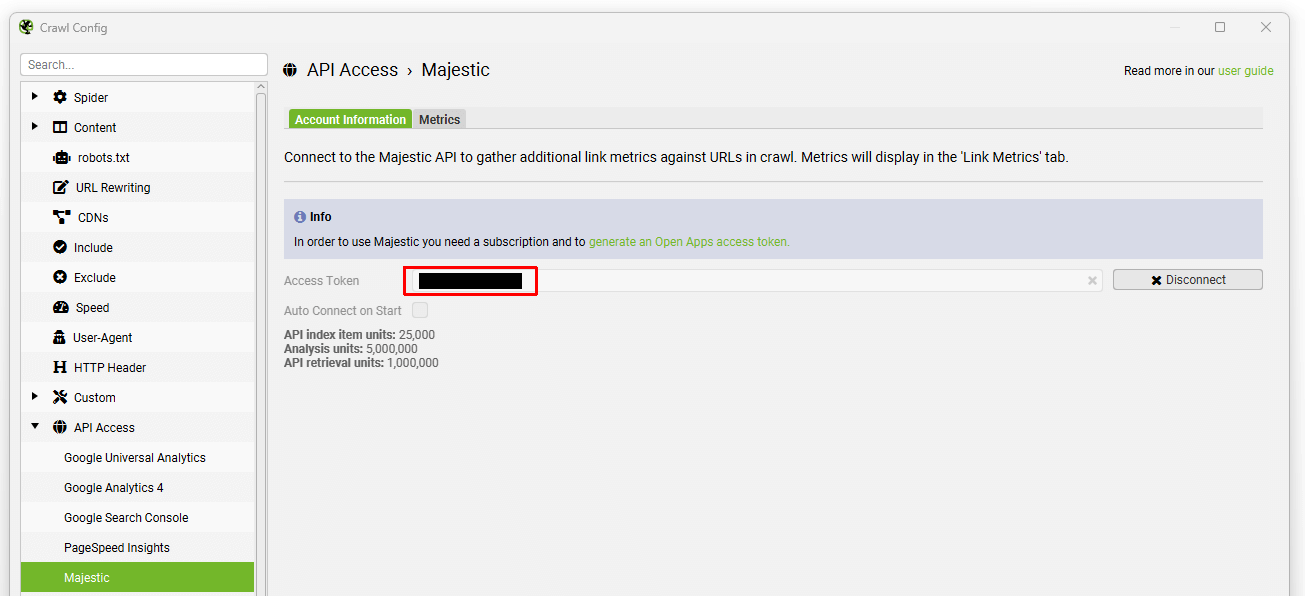
然后,您可以选择数据源(最新或历史)和指标,无论是在 URL、子域还是域级别。
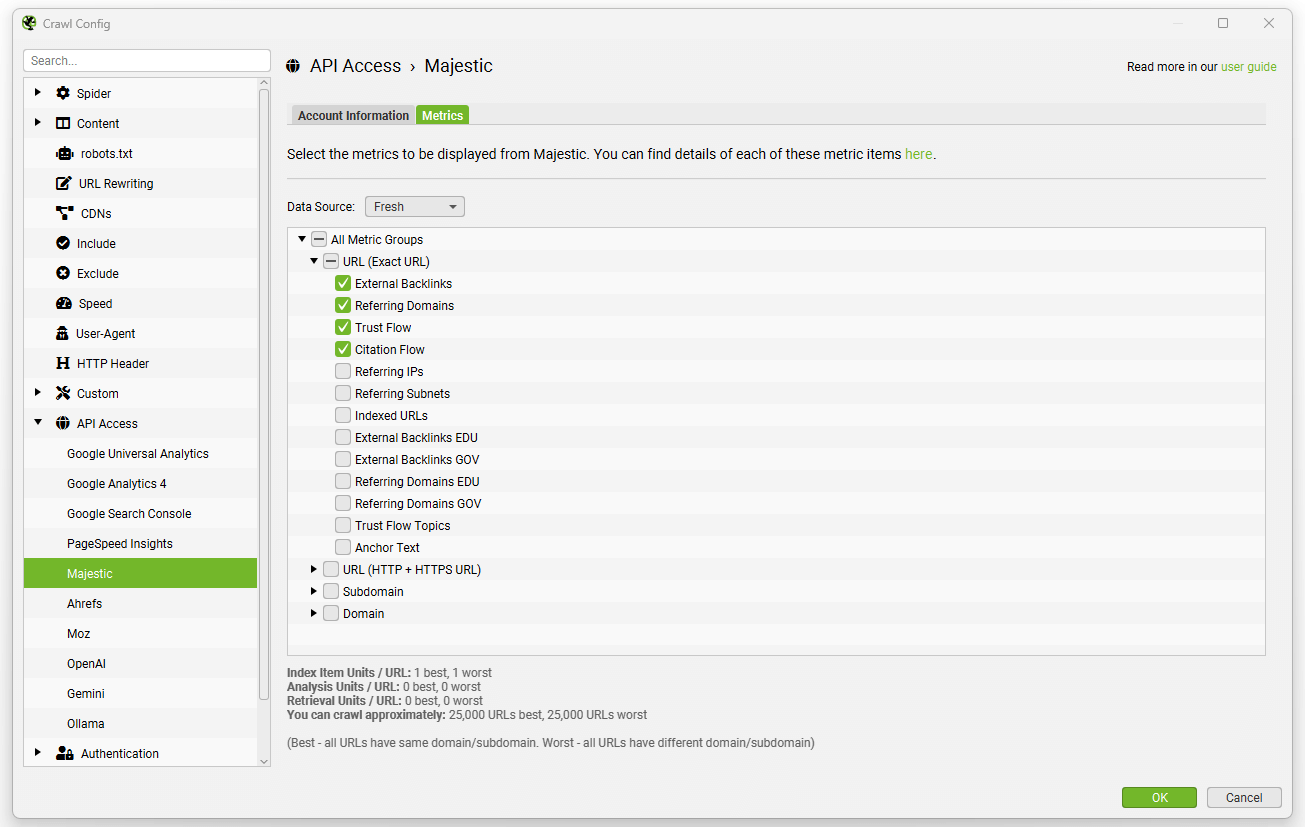
然后,只需单击“start”即可执行爬网,数据将通过其 API 自动提取,并且可以在“link metrics”和“internal”选项卡下查看。
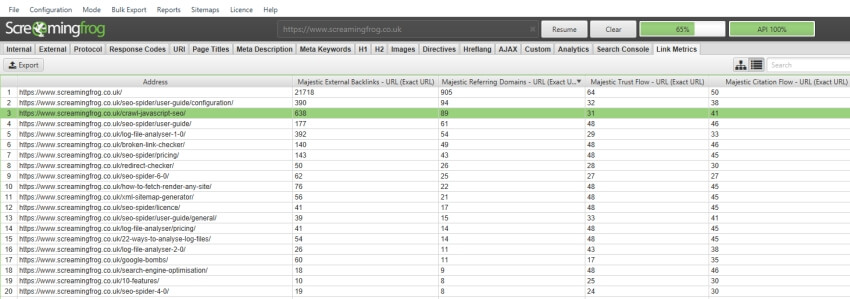
Ahrefs
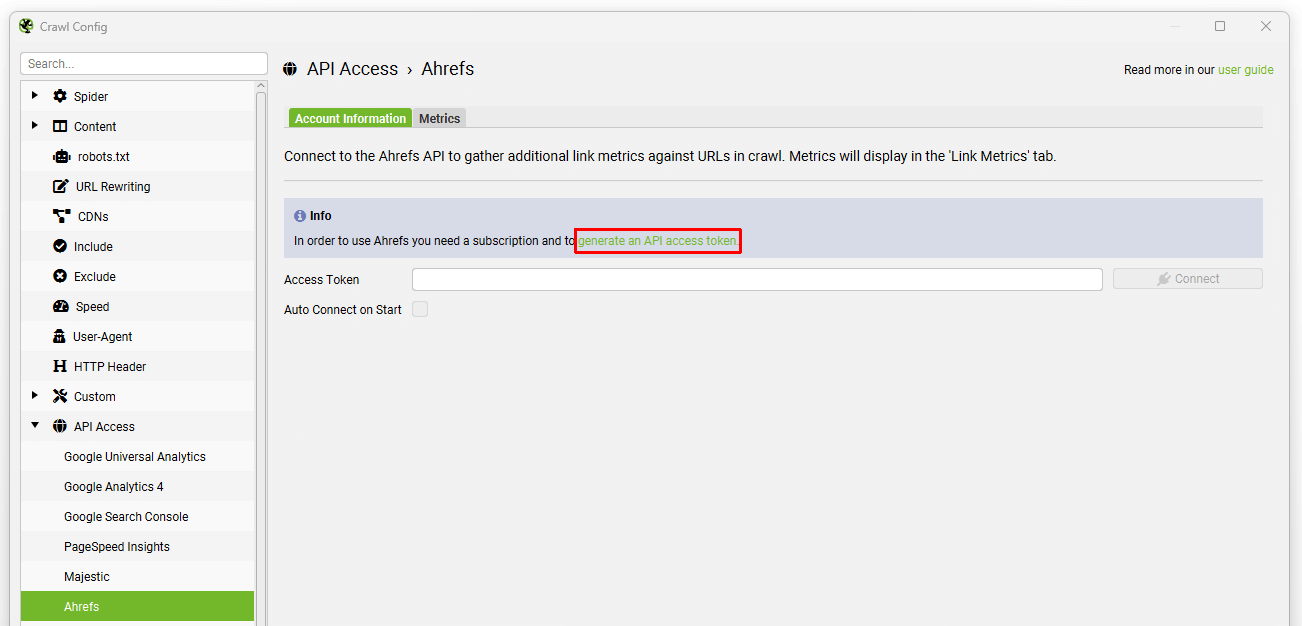
Configuration > API Access > Ahrefs
要使用 Ahrefs 集成,您需要付费订阅。 SEO Spider 使用 version 2 of their API,它不需要企业计划和特定的 API 单元。 它作为一个应用程序集成,并利用集成行。 每个订阅级别都有一个行限制。
要将 Ahrefs 与 SEO Spider 结合使用,您必须通过应用程序中的链接创建 API 访问令牌。 您无法在 Ahrefs 中创建 API 密钥,然后将其输入到工具中。
要进行设置,请导航到“Configuration > API Access > Ahrefs”,然后单击“generate an API access token”链接。
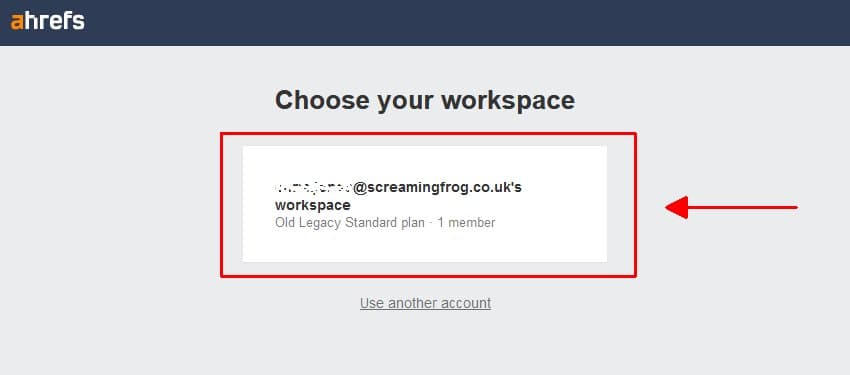
然后,您将被带到 Ahrefs,您需要在其中选择您的工作区。
然后“允许”访问 Screaming Frog SEO Spider。
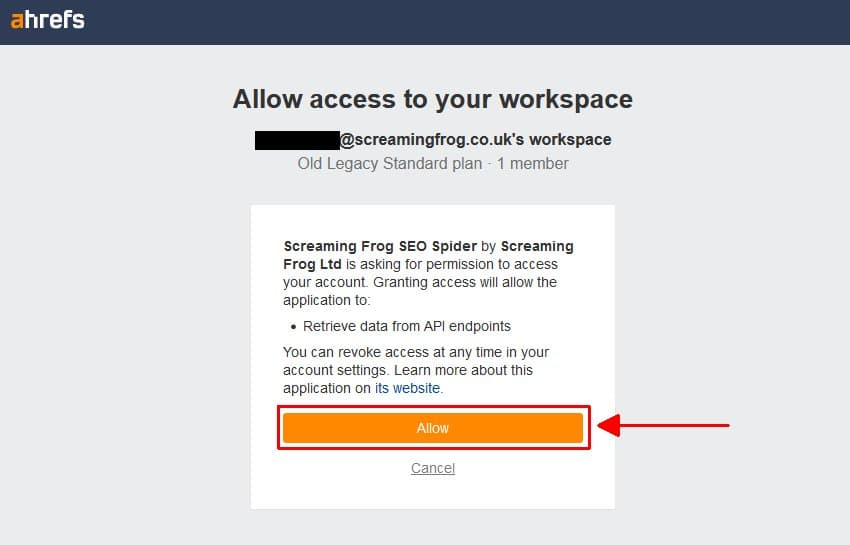
然后,您将从 Ahrefs 获得一个唯一的访问令牌(但托管在 Screaming Frog 域上)。
然后,将此令牌复制并输入到 Ahrefs 窗口中的 API 密钥框中,然后单击“connect” –
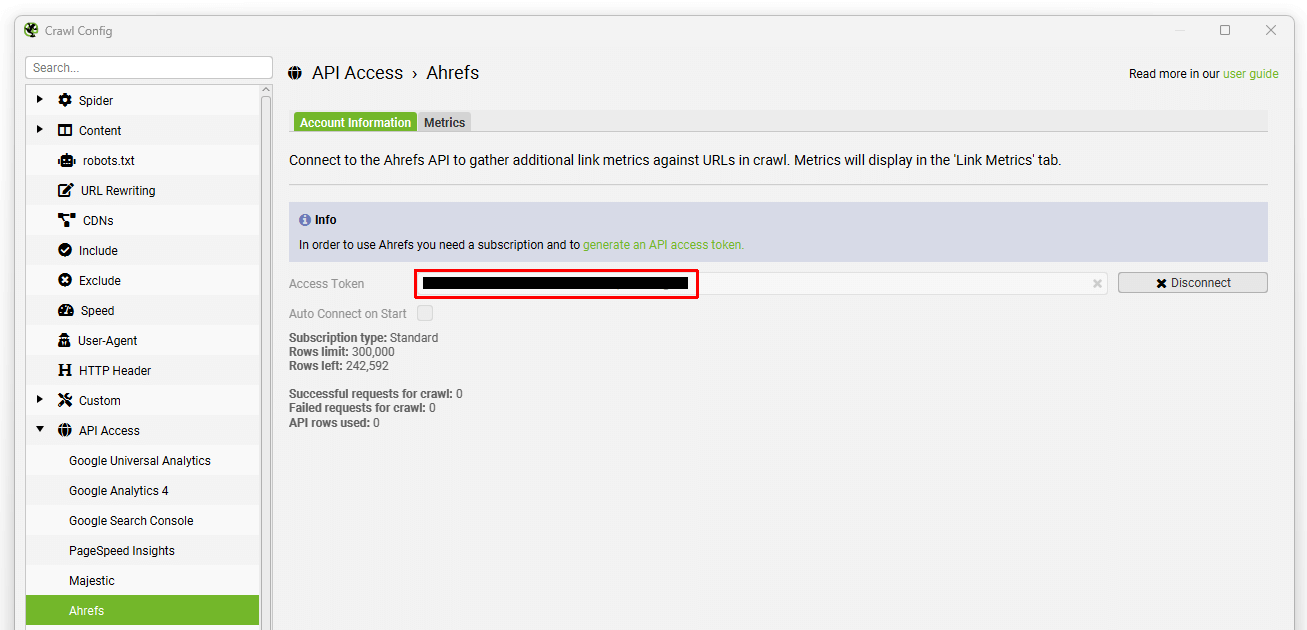
然后,您可以选择要在 URL、子域或域级别提取的指标。
然后,只需单击“start”即可执行爬网,数据将通过其 API 自动提取,并且可以在“link metrics”和“internal”选项卡下查看。
Moz
Configuration > API Access > Moz
您将需要一个 Moz 帐户才能从 Mozscape API 中提取数据。 Moz 提供免费的有限 API 和单独的付费 API,允许用户以更快的速度提取更多指标。 请注意,这是与标准 Moz PRO 帐户分开的订阅。
要访问 API,无论是使用免费帐户还是付费订阅,您只需登录到您的 Moz 帐户并查看您的 API ID 和密钥。
该 API 使用其 API 的 v.3,因此您只需将一个访问令牌插入到 SEO Spider 中。
通过“Config > API Access > Moz”将 Moz API 令牌复制并粘贴到“Access Token”字段中的 Moz 帐户信息对话框中,选择您的帐户类型(“free”或“paid”),然后单击“connect” –
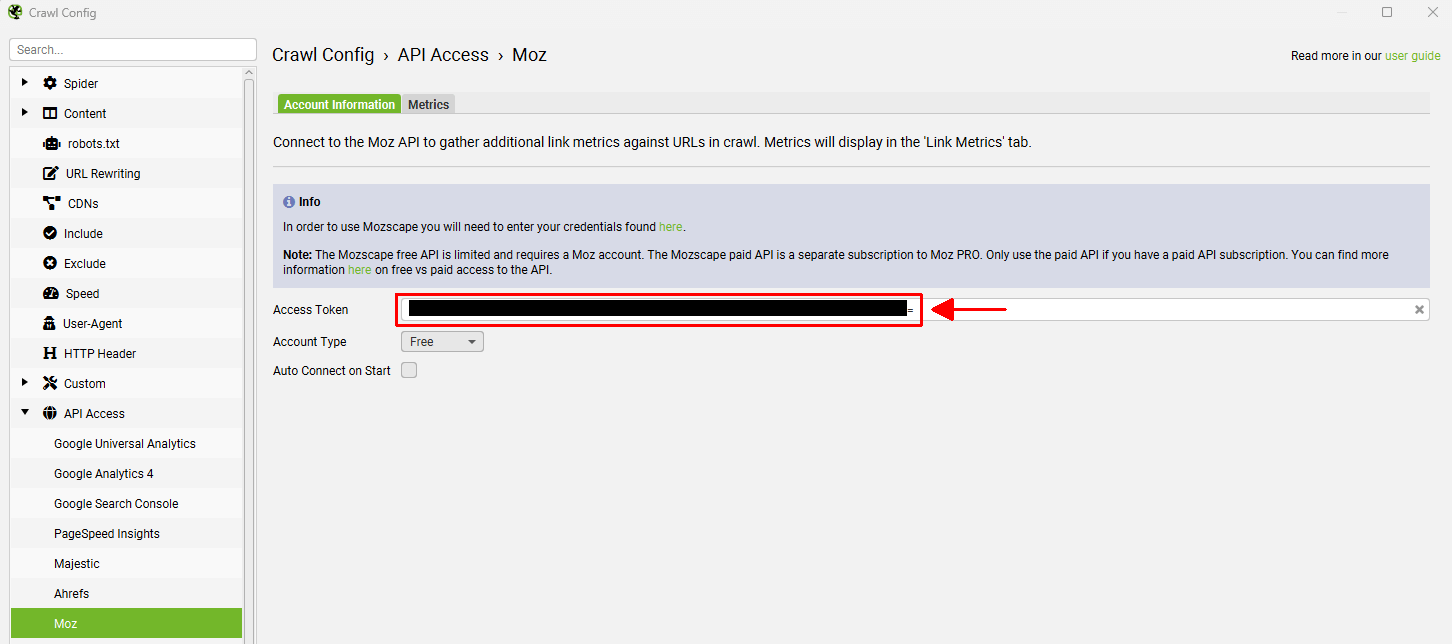
然后,您可以根据您的免费或付费计划选择可用的指标。 只需选择要在 URL、子域或域级别提取的指标。

然后,只需单击“start”即可执行爬网,数据将通过其 API 自动提取,并且可以在“link metrics”和“internal”选项卡下查看。
OpenAI
Configuration > API Access > AI > OpenAI
要连接到 OpenAI,您需要一个已充值的 OpenAI 帐户和一个 OpenAI API 密钥。 这与 ChatGPT 订阅不同。
您可以注册一个 OpenAI 帐户,选择您的用途为“API”,然后转到 结算部分 为帐户充值。
如果您不为帐户充值,它将无法工作。 您可以选择向帐户添加固定金额的信用额度,以及调整支出限额。 请仔细查看他们的 API 定价 和令牌成本。
当您拥有 API 密钥时,将其复制并粘贴到 OpenAI 帐户信息选项卡中的“API Key”字段中。
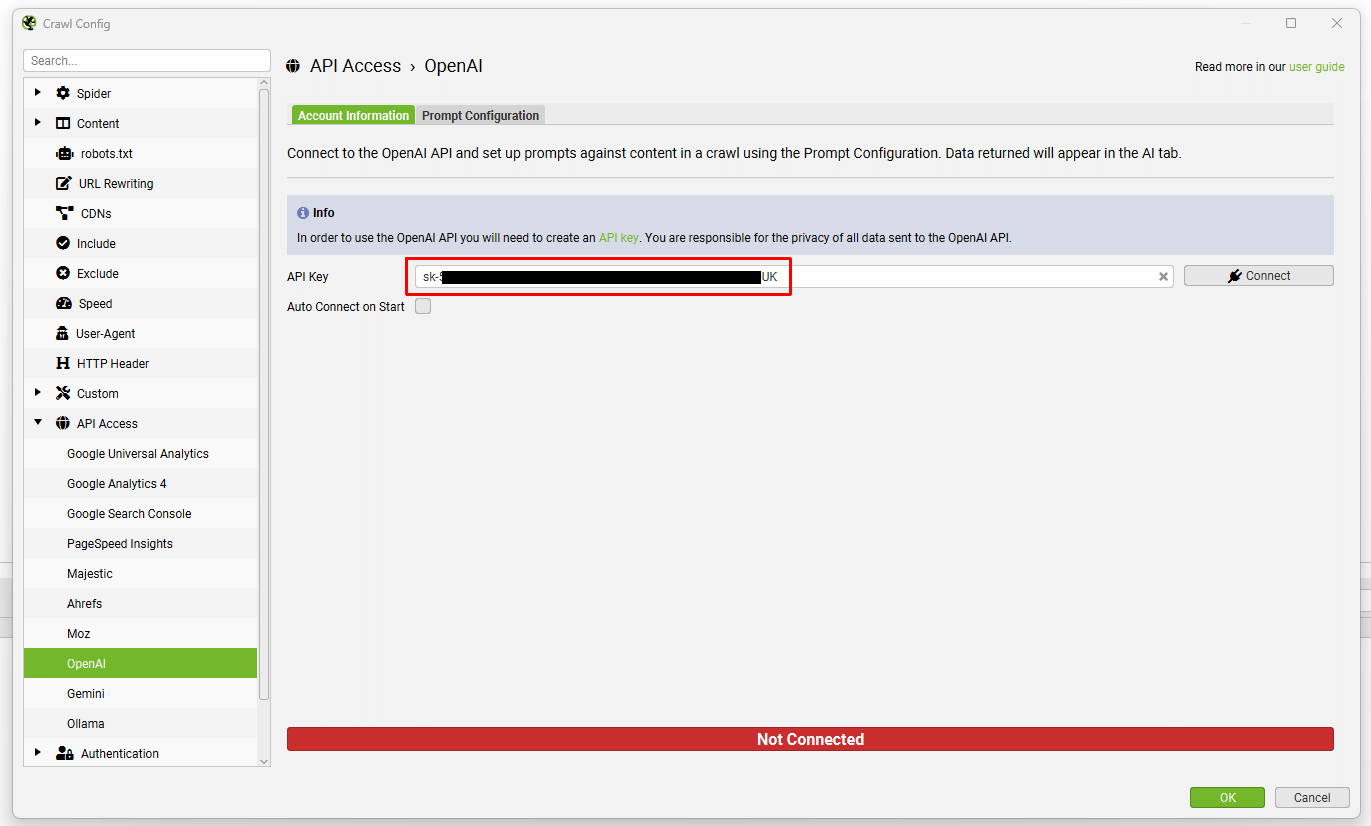
当您希望使用爬网设置时,单击“Connect”。
导航到“Prompt Configuration”选项卡,以针对爬网数据设置最多 100 个提示。
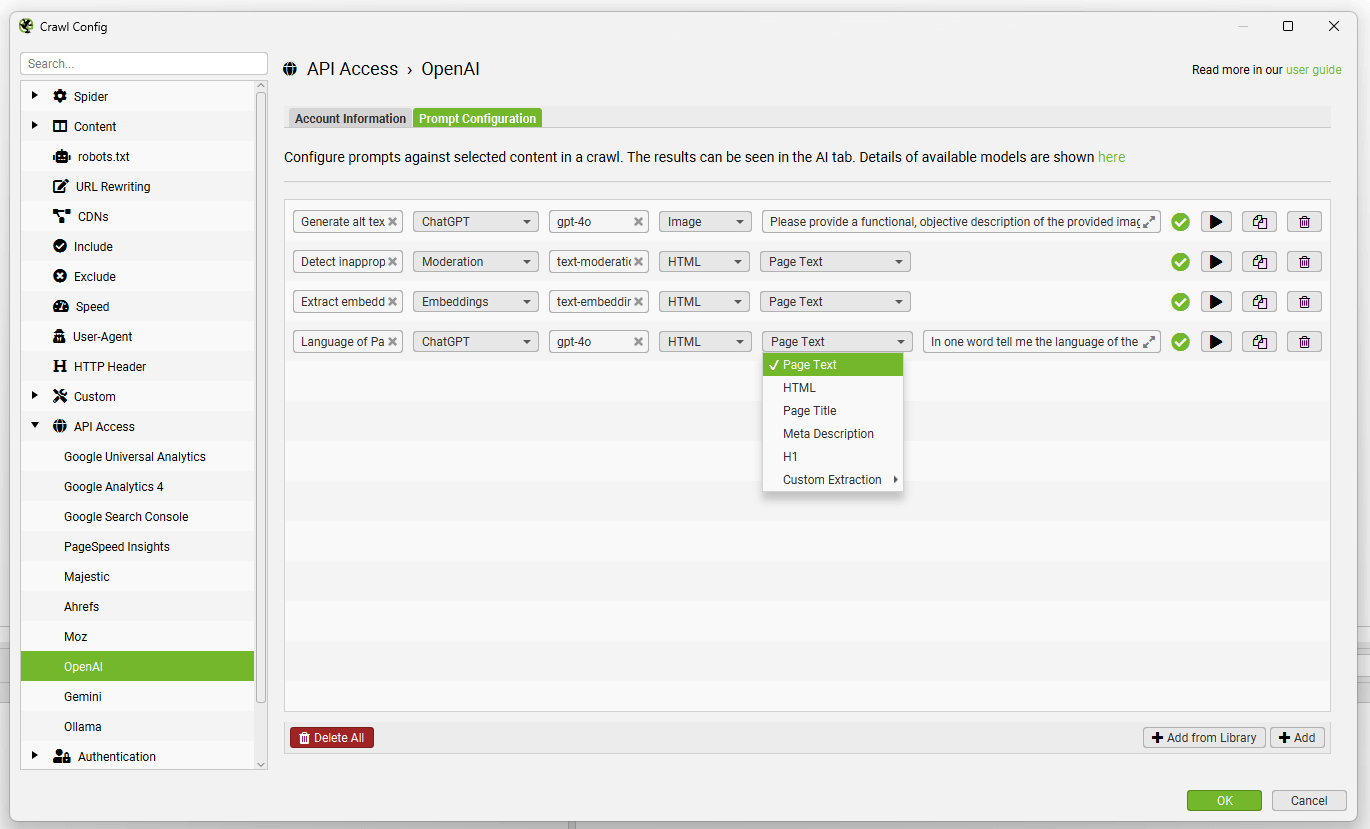
选择模型类别(ChatGPT、Moderation 或 Embeddings)、使用的 OpenAI 模型(例如,“gpt-4o”)、内容类型和用于提示的数据(例如正文、HTML 或自定义提取),以及编写您的自定义提示。
请注意: 要将“Page Text”或“HTML”用于提示,您需要通过“Config > Spider > Extraction”启用“Store HTML”。
要测试提示,请使用提示字段右侧的“播放”图标。
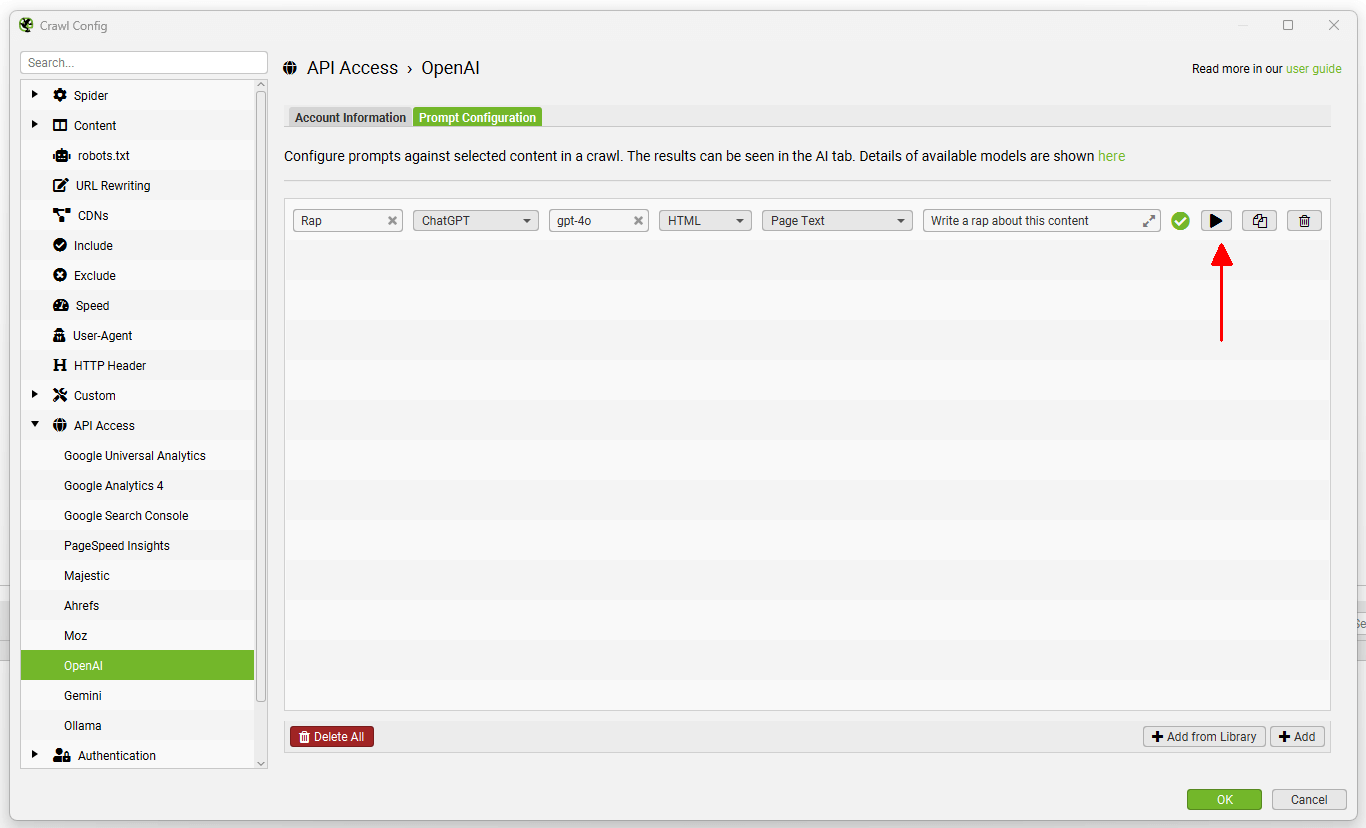
在 OpenAI 提示测试器中,输入要测试的 URL,然后单击“Test”按钮以显示提取和响应。
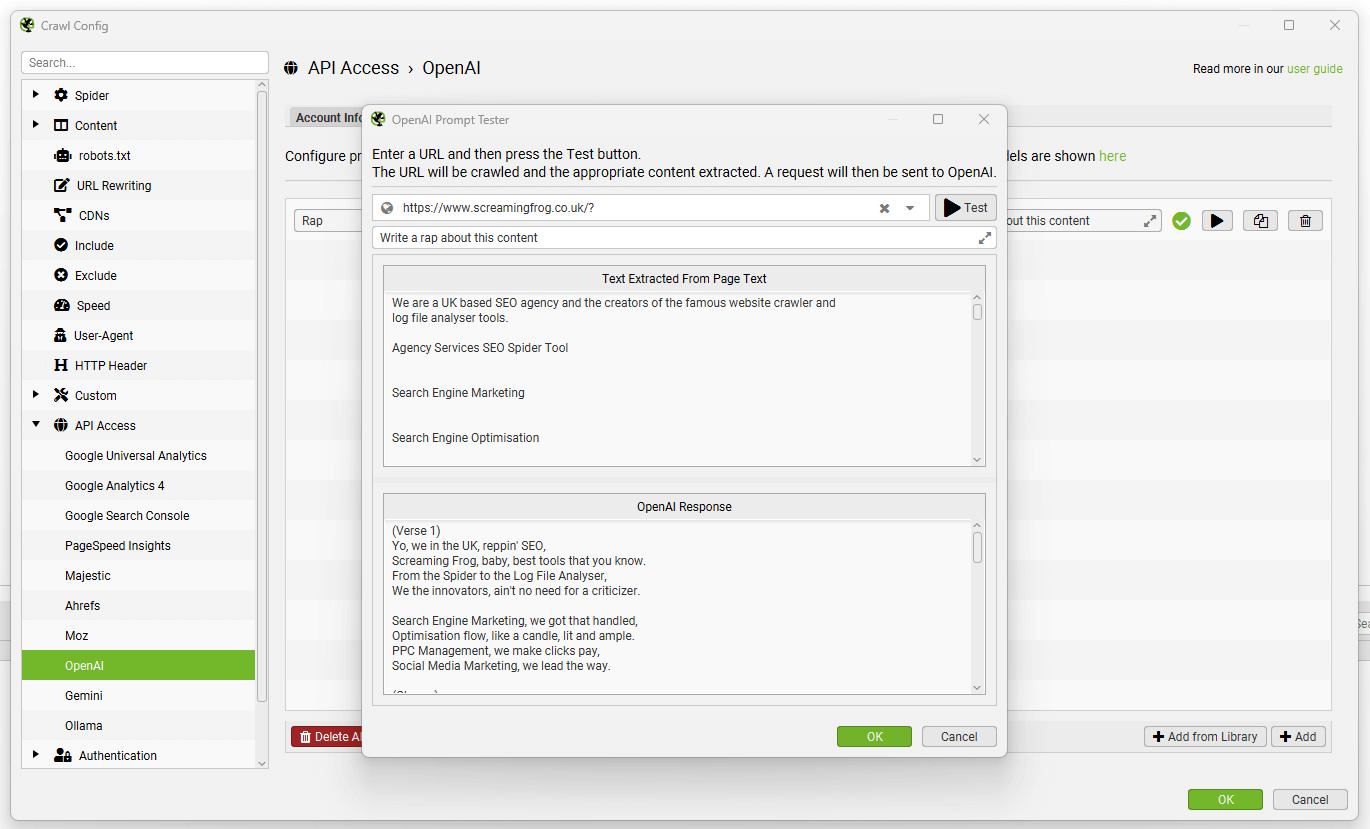
来自提示的数据将显示在 AI 选项卡中(以及 Internal 选项卡中,针对您的常规爬网数据)。
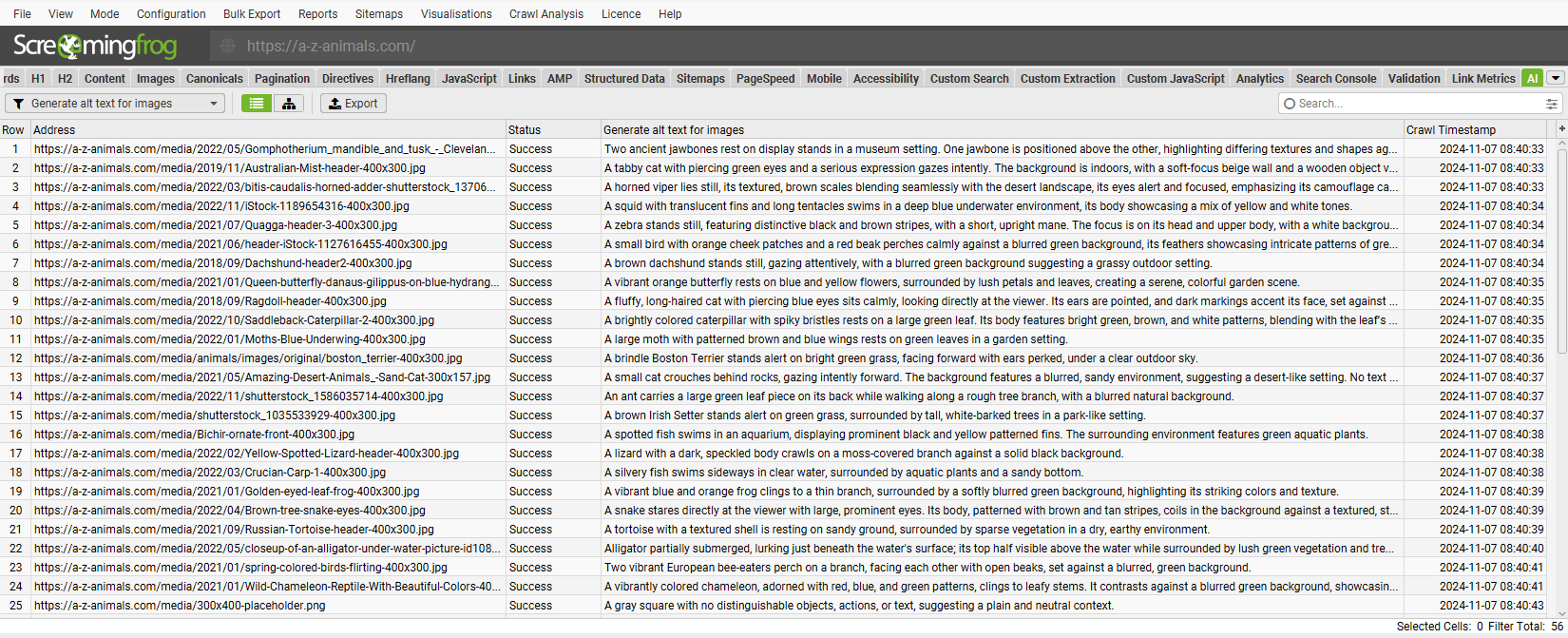
“Add from Library”功能包括六个提示,供您参考。
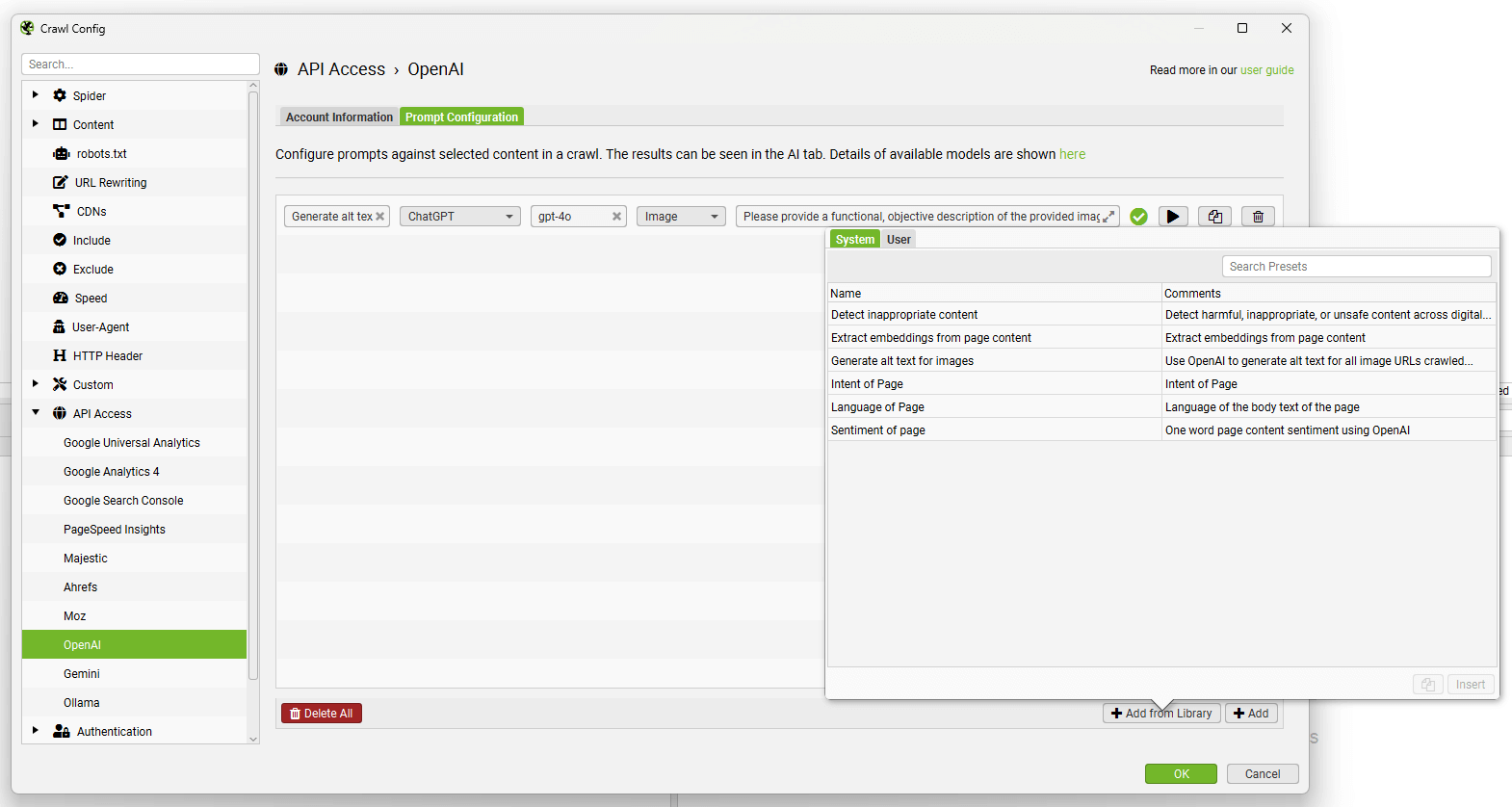
您可以使用“Add from Library”按钮,单击“User”和“+”按钮来添加和自定义您自己的提示。
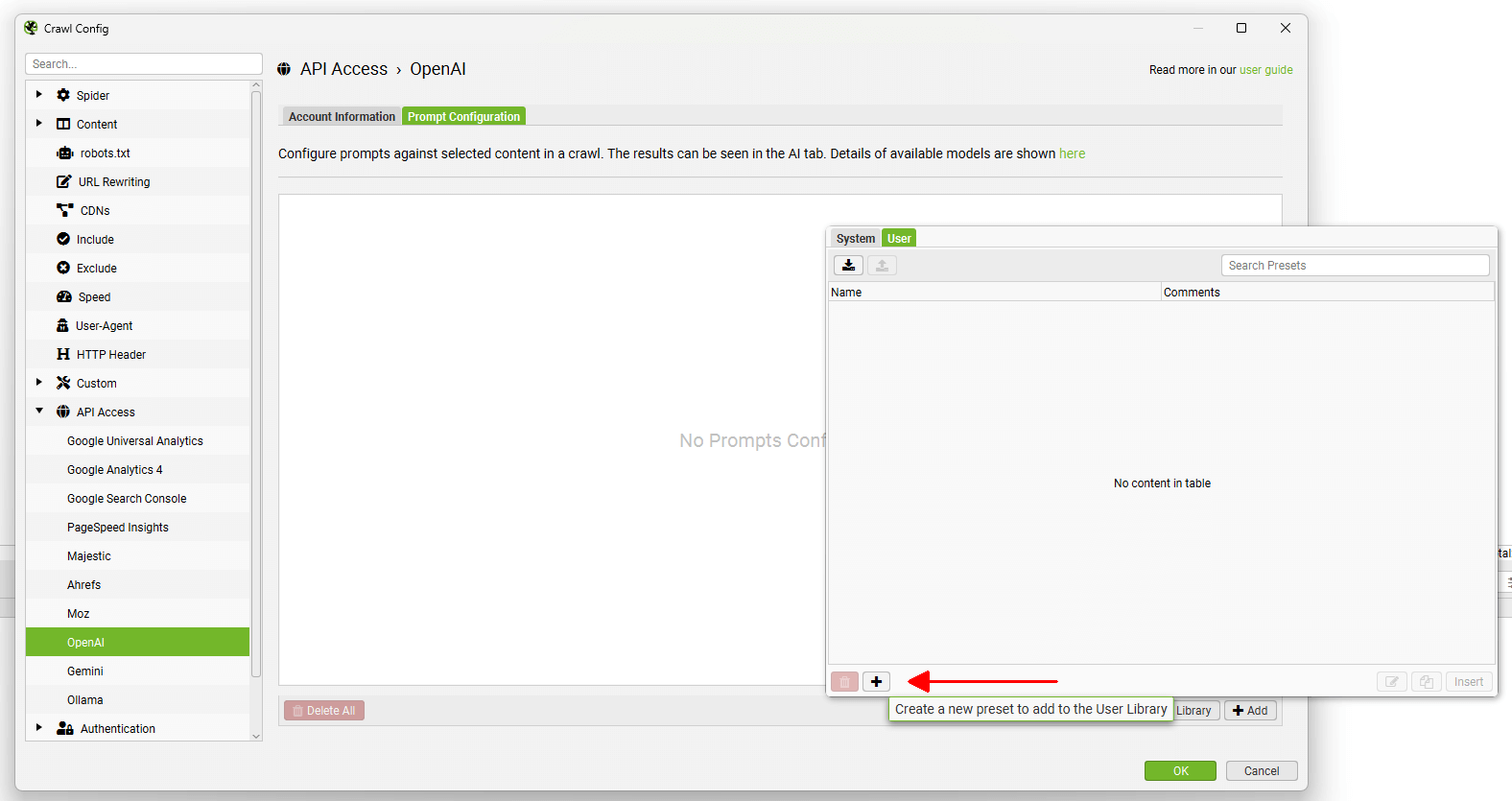
可以使用顶部的导出和导入按钮共享自定义提示。
Gemini
Configuration > API Access > AI > Gemini
要连接到 Gemini API,您需要一个 API 密钥。 您可以在 Google AI Studio 中创建一个密钥。
单击“Create API Key”,选择一个项目并设置一个 API 密钥。 Gemini 仅在特定区域可用,并且有免费和付费帐户类型,具有不同的速率限制。
当您拥有 API 密钥时,将其复制并粘贴到 Gemini 帐户信息选项卡中的“API Key”字段中。
选择“Account Type”,免费或付费,这将调整速率限制,并在您希望使用爬网设置时单击“Connect”。
导航到“Prompt Configuration”选项卡,以针对爬网数据设置最多 100 个提示。
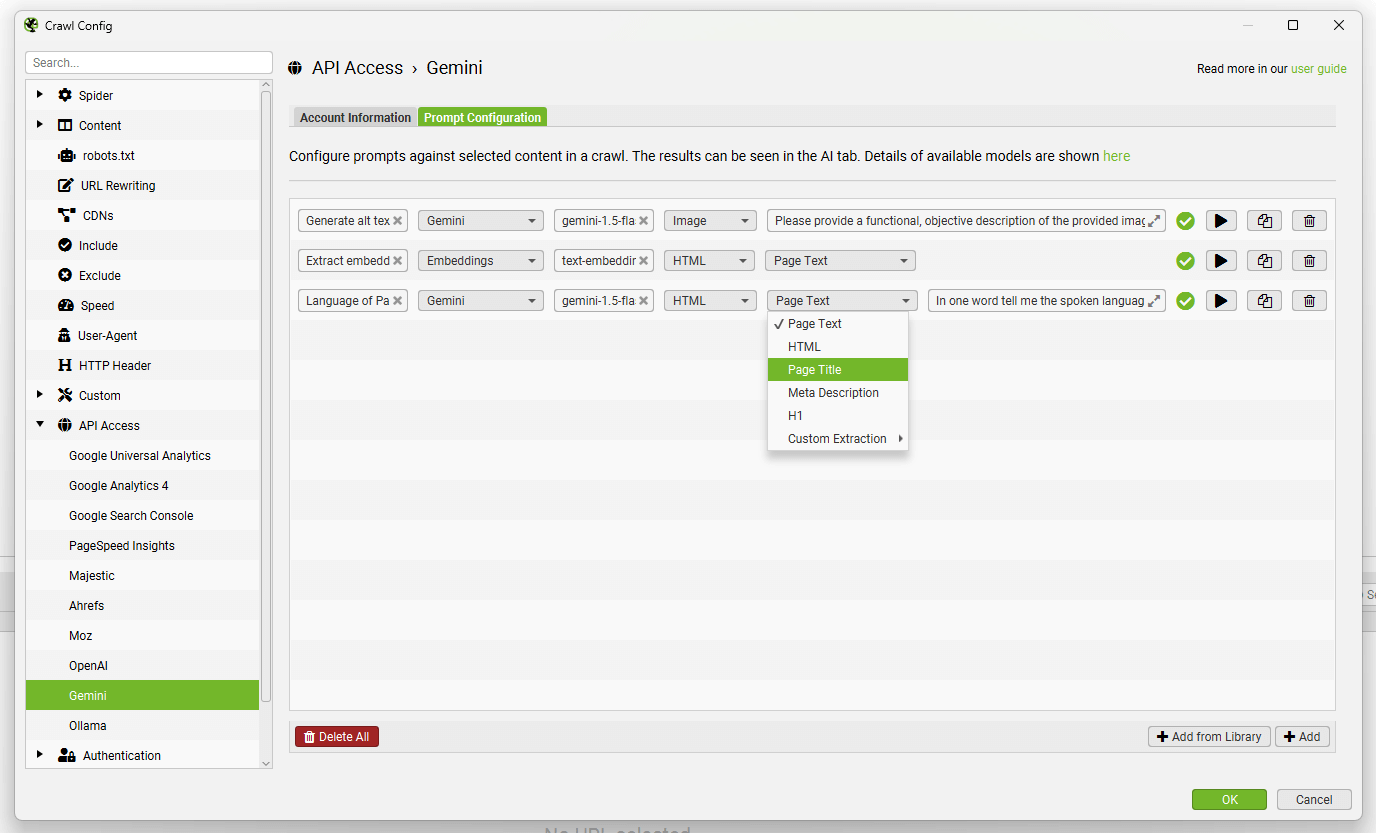
选择模型类别(Gemini 或 Embeddings)、使用的 Gemini 模型(例如,“gemini-1.5-flash”)、内容类型和用于提示的数据(例如正文、HTML 或自定义提取�),以及编写您的自定义提示。
请注意: 要将“Page Text”或“HTML”用于提示,您需要通过“Config > Spider > Extraction”启用“Store HTML”。
要测试提示,请使用提示字段右侧的“播放”图标。
在 Gemini 提示测试器中,输入要测试的 URL,然后单击“Test”按钮以显示提取和响应。
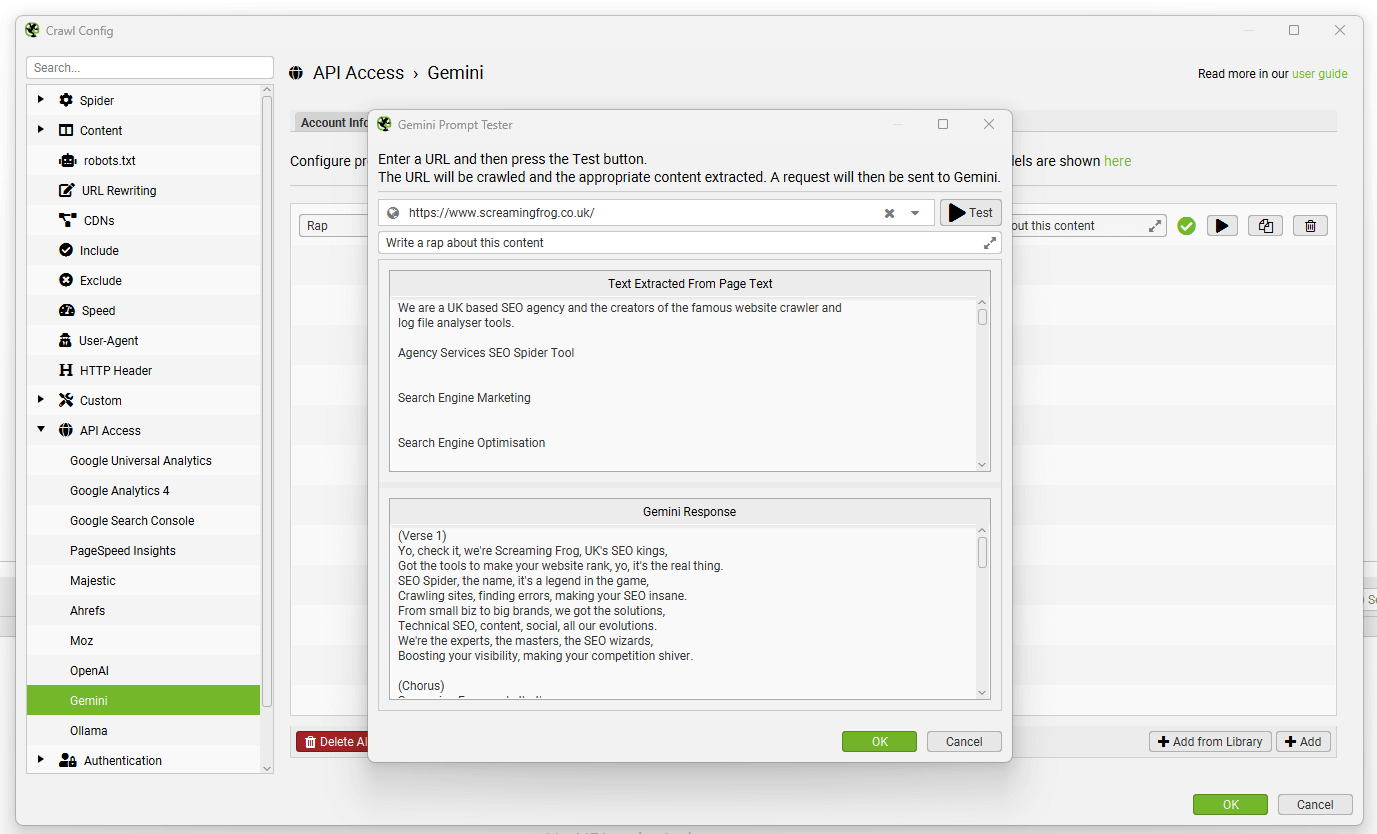
来自提示的数据将显示在 AI 选项卡中(以及 Internal 选项卡中,针对您的常规爬网数据)。
“Add from Library”功能包括六个提示,供您参考。
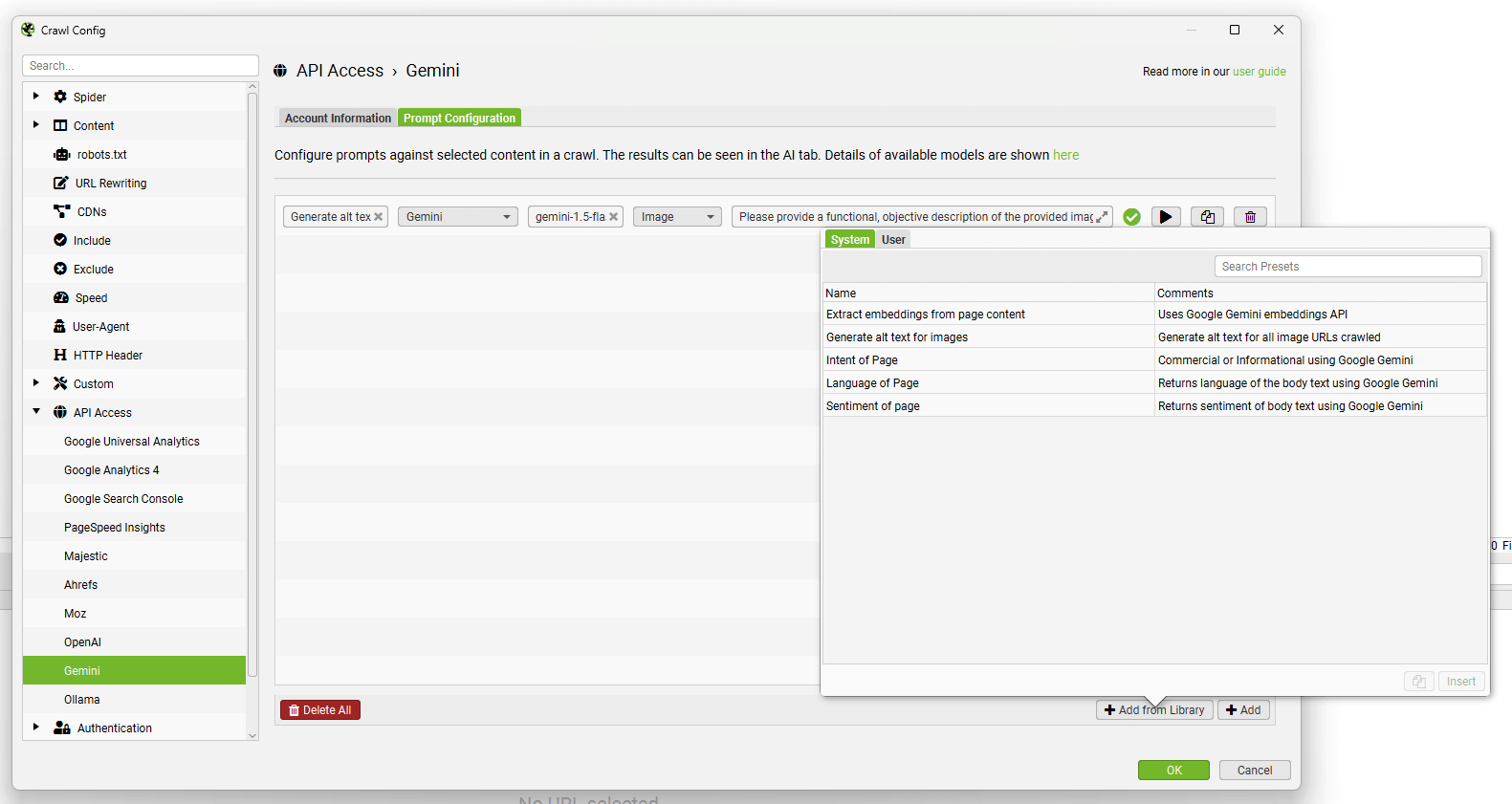
您可以使用“Add from Library”按钮,单击“User”和“+”按钮来添加和自定义您自己的提示。
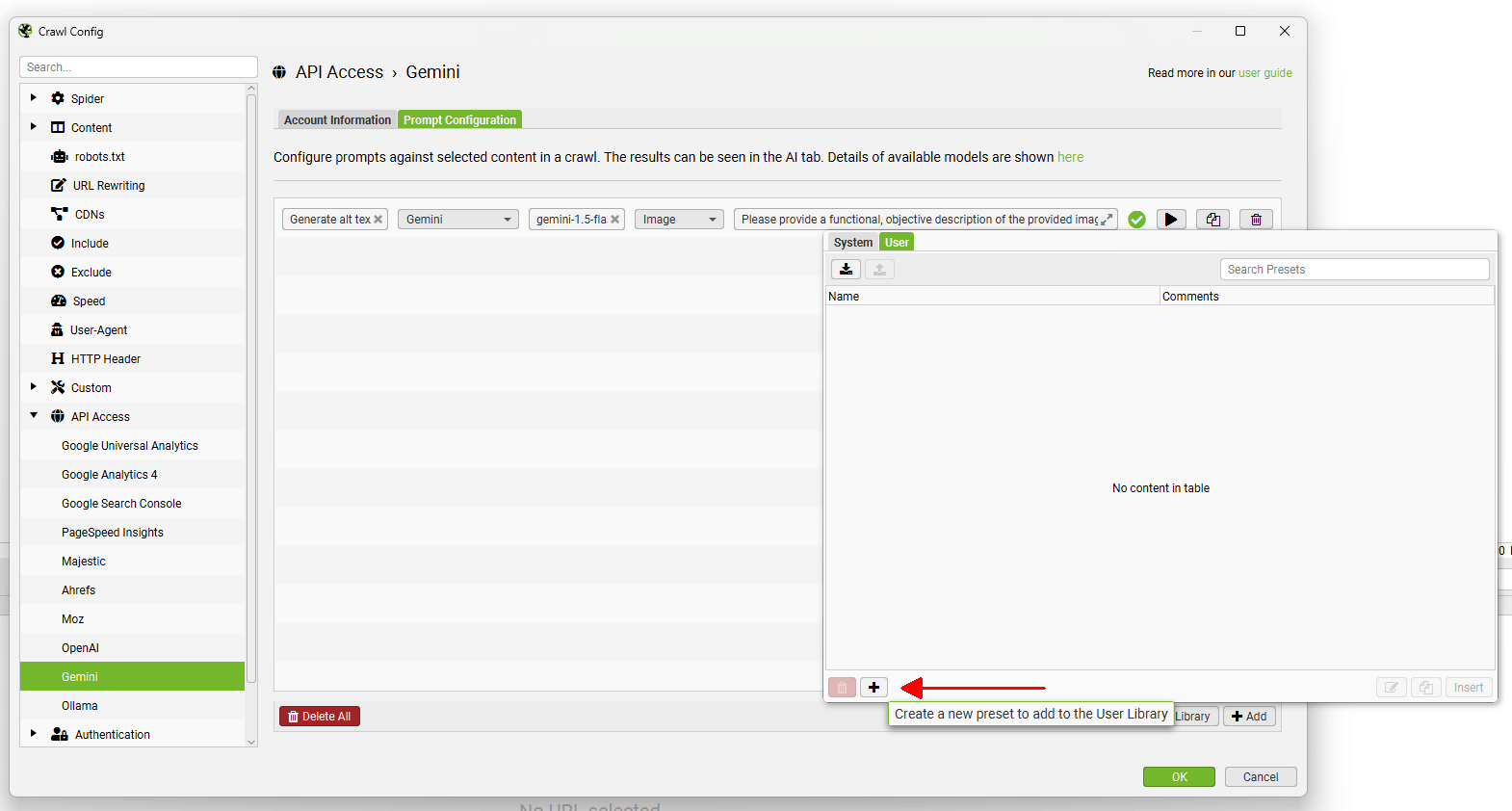
可以使用顶部的导出和导入按钮共享自定义提示。
Ollama
Configuration > API Access > AI > Ollama
要连接到 Ollama,您需要在本地计算机上下载并安装 LLM。
安装设置后,您需要使用命令提示符或终端下载您希望使用的模型,例如 ollama run llama3.1。
这需要一台功能强大的现代机器。
安装完成后,单击 Ollama 帐户信息选项卡上的“Connect”。 服务器 URL 字段可以保持不变 (http://localhost:11434)。
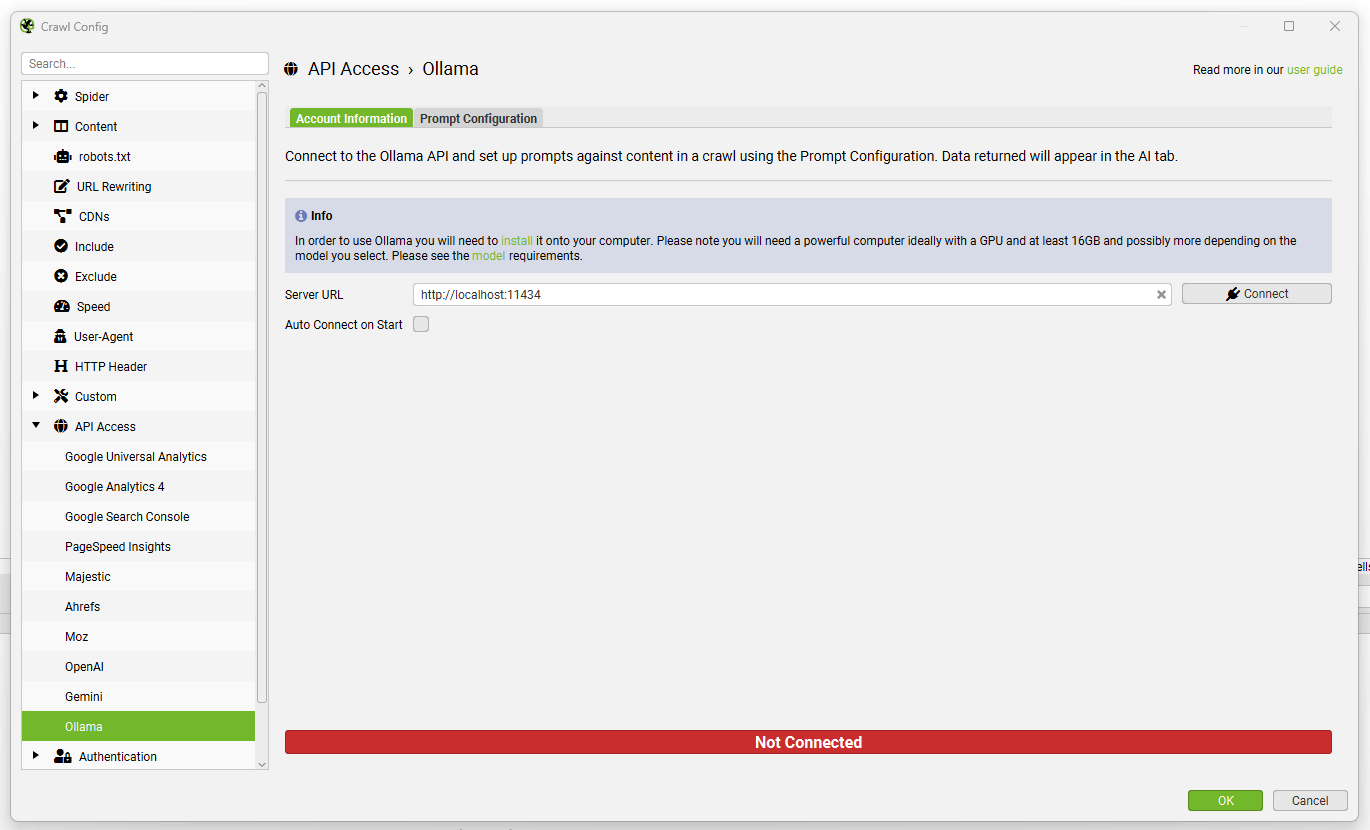
导航到“Prompt Configuration”选项卡,以针对爬网数据设置最多 100 个提示。
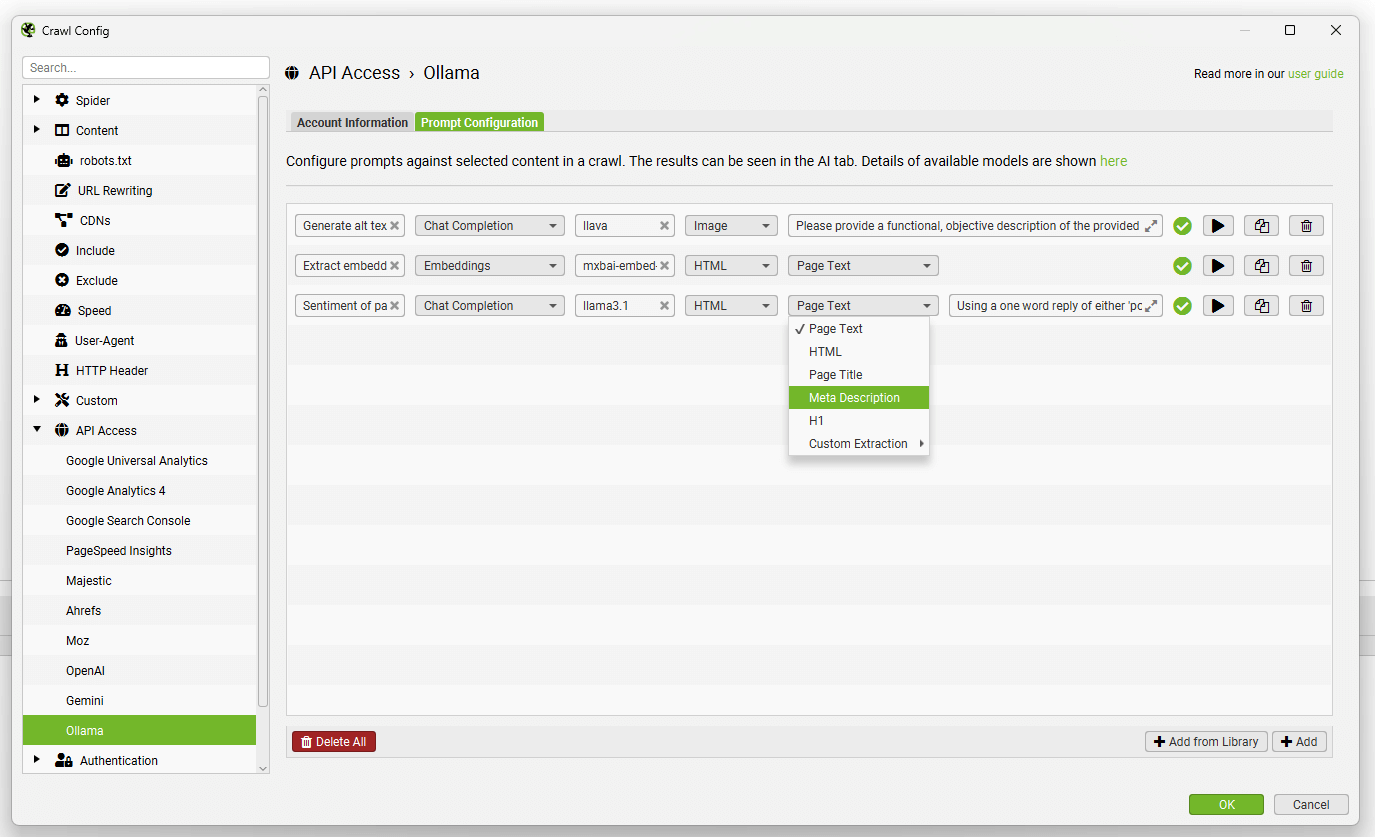
选择模型类别(Chat Completion 或 Embeddings)、使用的 Ollama 模型(例如,“llama3.1”)、内容类型和用于提示的数据(例如正文、HTML 或自定义提取),以及编写您的自定义提示。
请注意: 要使用提示中的“页面文本”或“HTML”,您需要通过“配置 > 爬虫 > 提取”启用“存储 HTML”。
要测试提示,请使用提示字段右侧的“播放”图标。
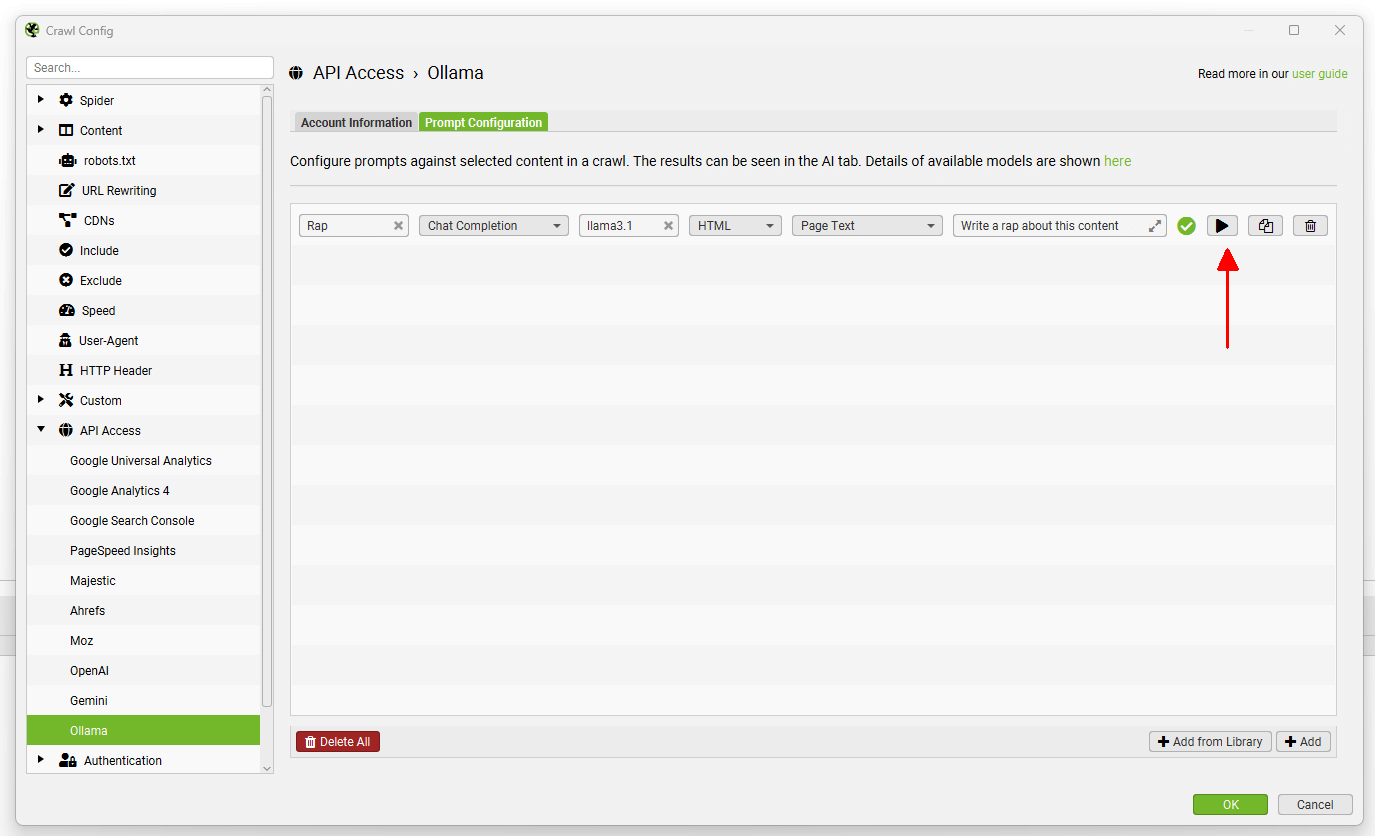
在 Ollama 提示测试器中,输入要测试的 URL,然后单击“测试”按钮以显示提取和响应。
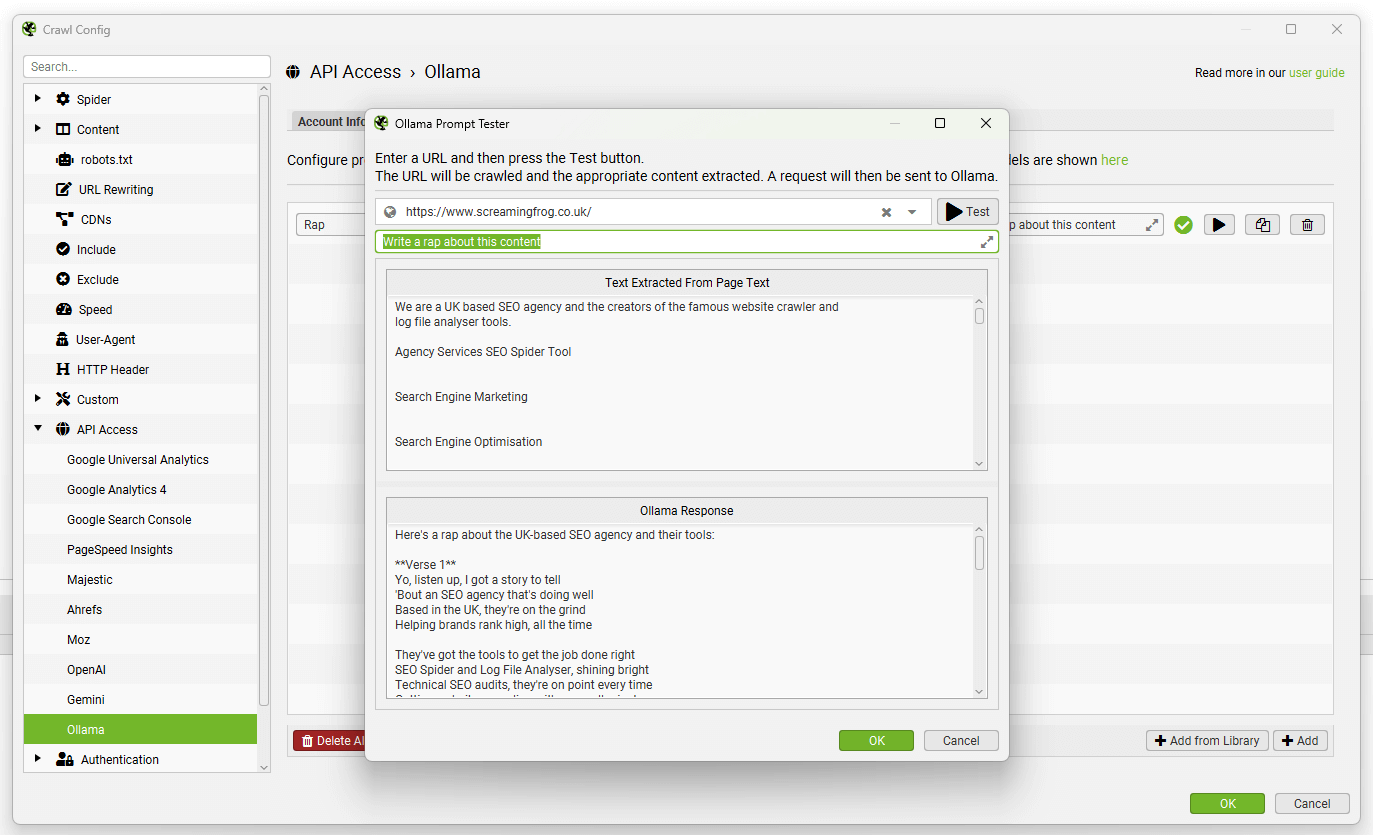
来自提示的数据将出现在 AI 选项卡(以及内部选项卡,与您的常规爬网数据相对)。
“从库添加”功能包含六个提示,可供您参考。
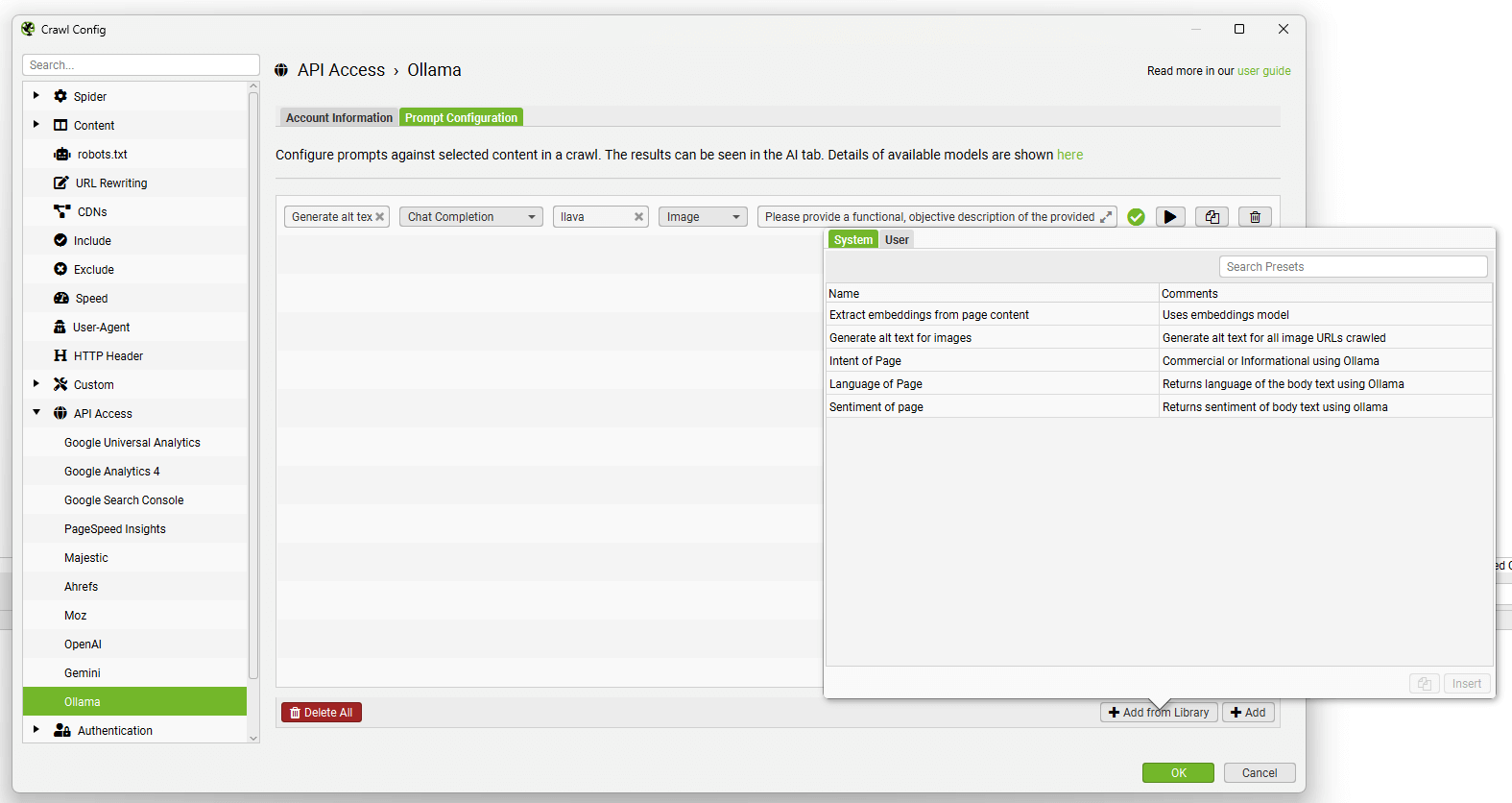
您可以使用“从库添加”按钮,单击“用户”和“+”按钮来添加和自定义您自己的提示。
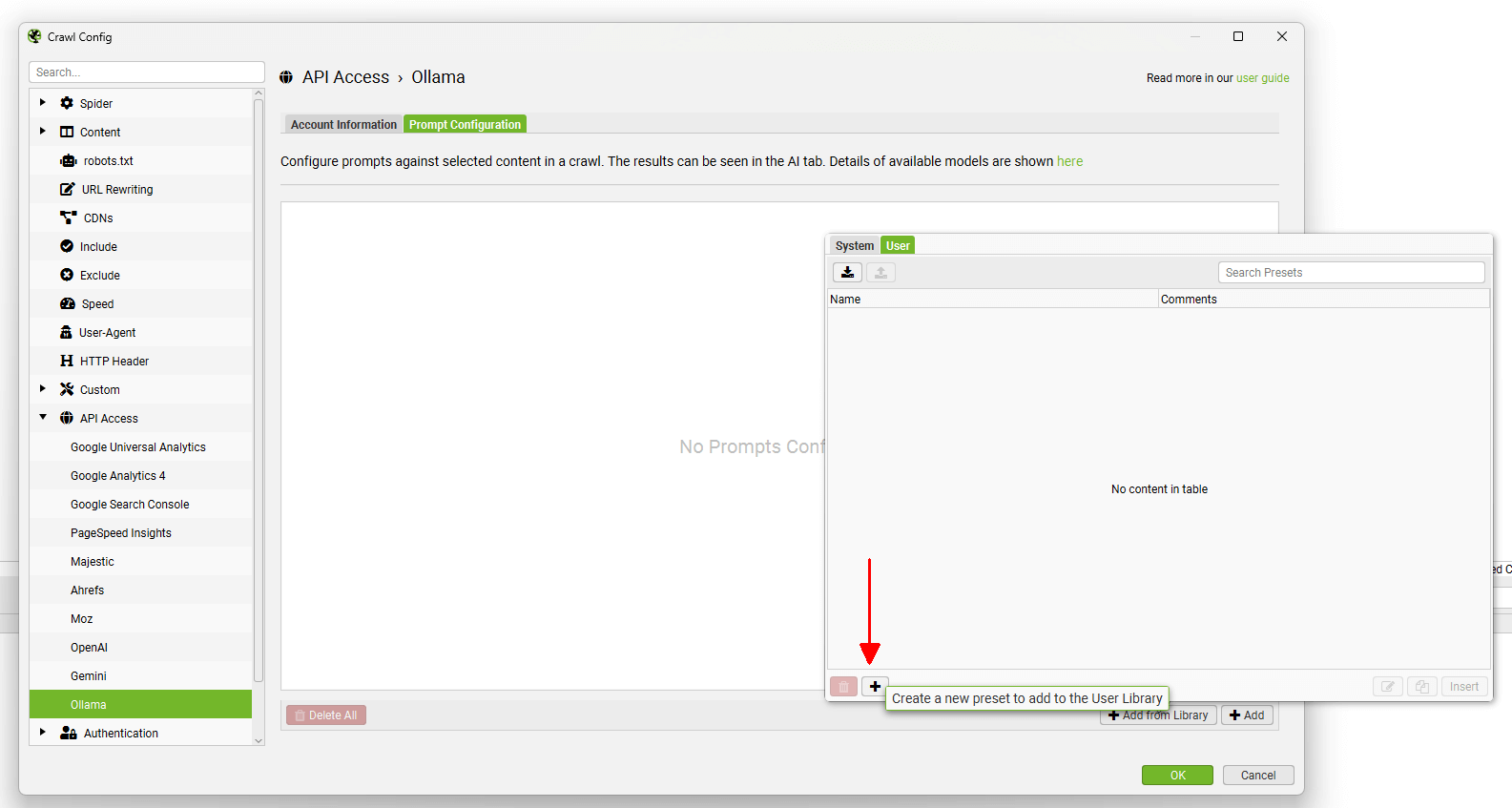
可以使用顶部的导出和导入按钮共享自定义提示。
Anthropic
配置 > API 访问 > AI > Anthropic
要连接到 Anthropic API,您需要一个 API 密钥。 您可以通过他们的 Build With Claude API 页面和“Start Building”按钮创建一个付费帐户。
创建帐户后,通过帐户设置页面生成 API 密钥。
获得 API 密钥后,将其复制并粘贴到 Anthropic 帐户信息选项卡中的“API 密钥”字段中。
如果您希望�使用该设置进行爬网,请单击“连接”。
导航到“提示配置”选项卡,以针对爬网数据设置最多 100 个提示。
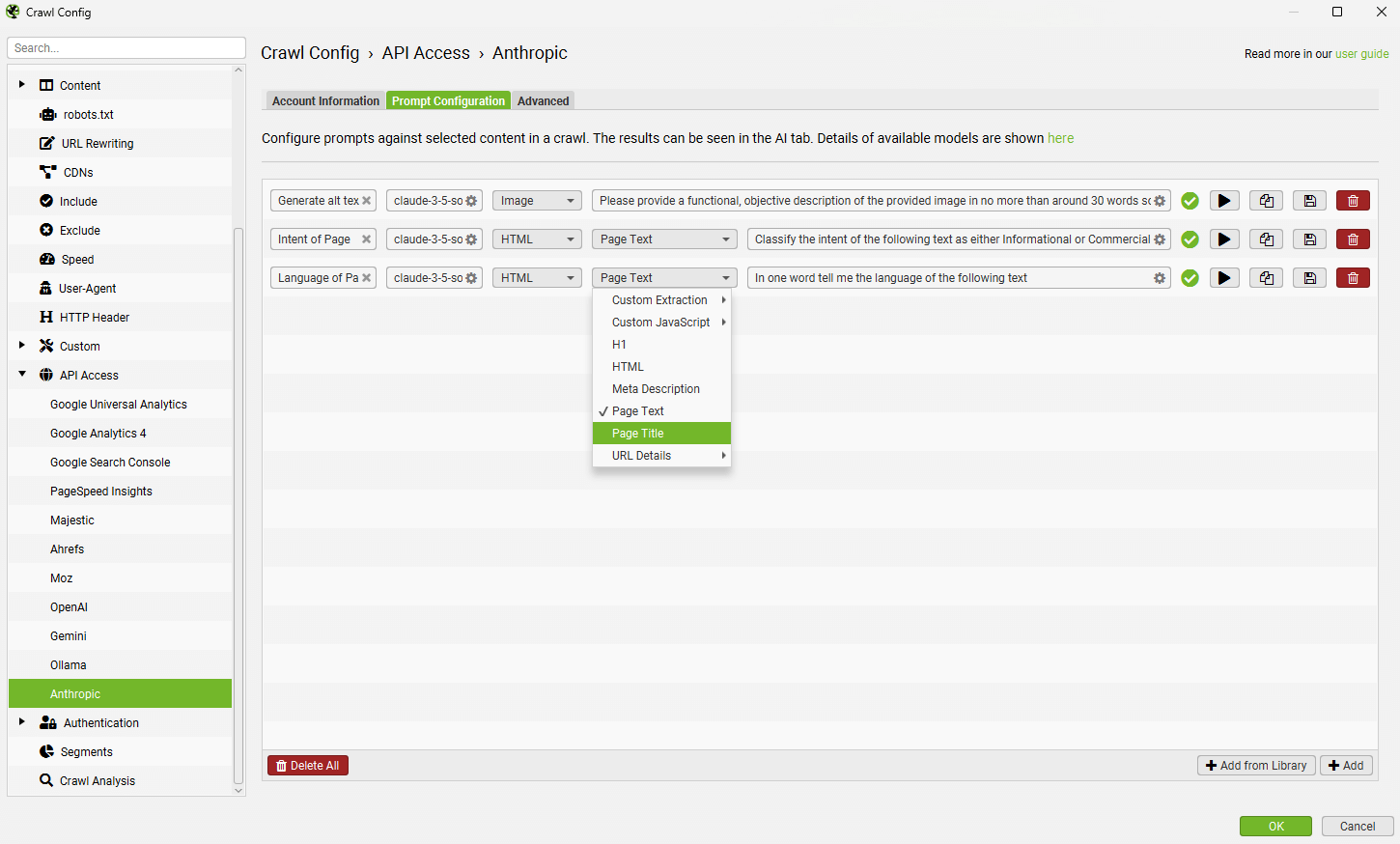
选择使用的模型(例如,“claude-3-5-sonnet-latest”)、内容类型和用于提示的数据,例如正文文本、HTML 或自定义提取,以及编写您的自定义提示。
请注意: 要使用提示中的“页面文本”或“HTML”,您需要通过“配置 > 爬虫 > 提取”启用“存储 HTML”。
要测试提示,请使用提示字段右侧的“播放”图标。
在 Anthropic 提示测试器中,输入要测试的 URL,然后单击“测试”按钮以显示提取和响应。
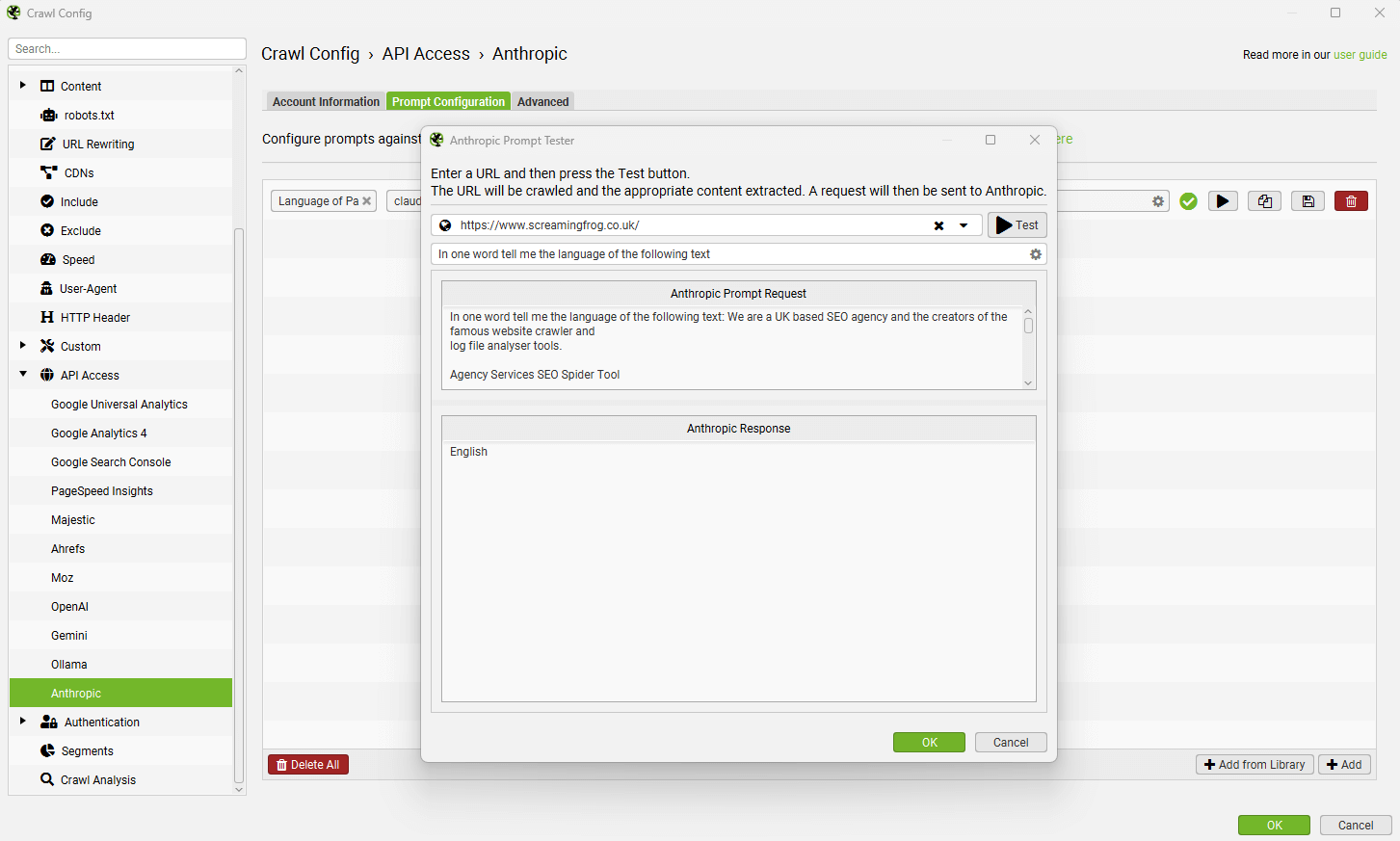
来自提示的数据将出现在 AI 选项卡(以及内部选项卡,与您的常规爬网数据相对)。
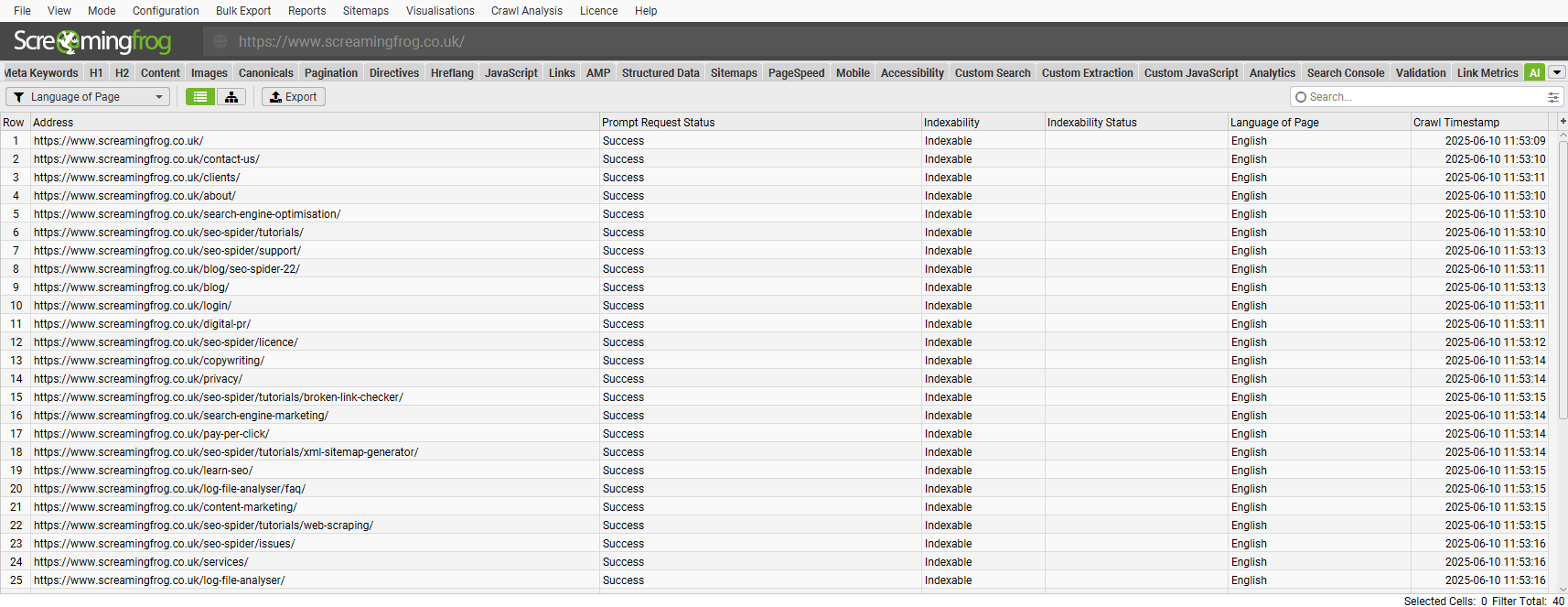
“从库添加”功能包含一些提示,可供您参考。
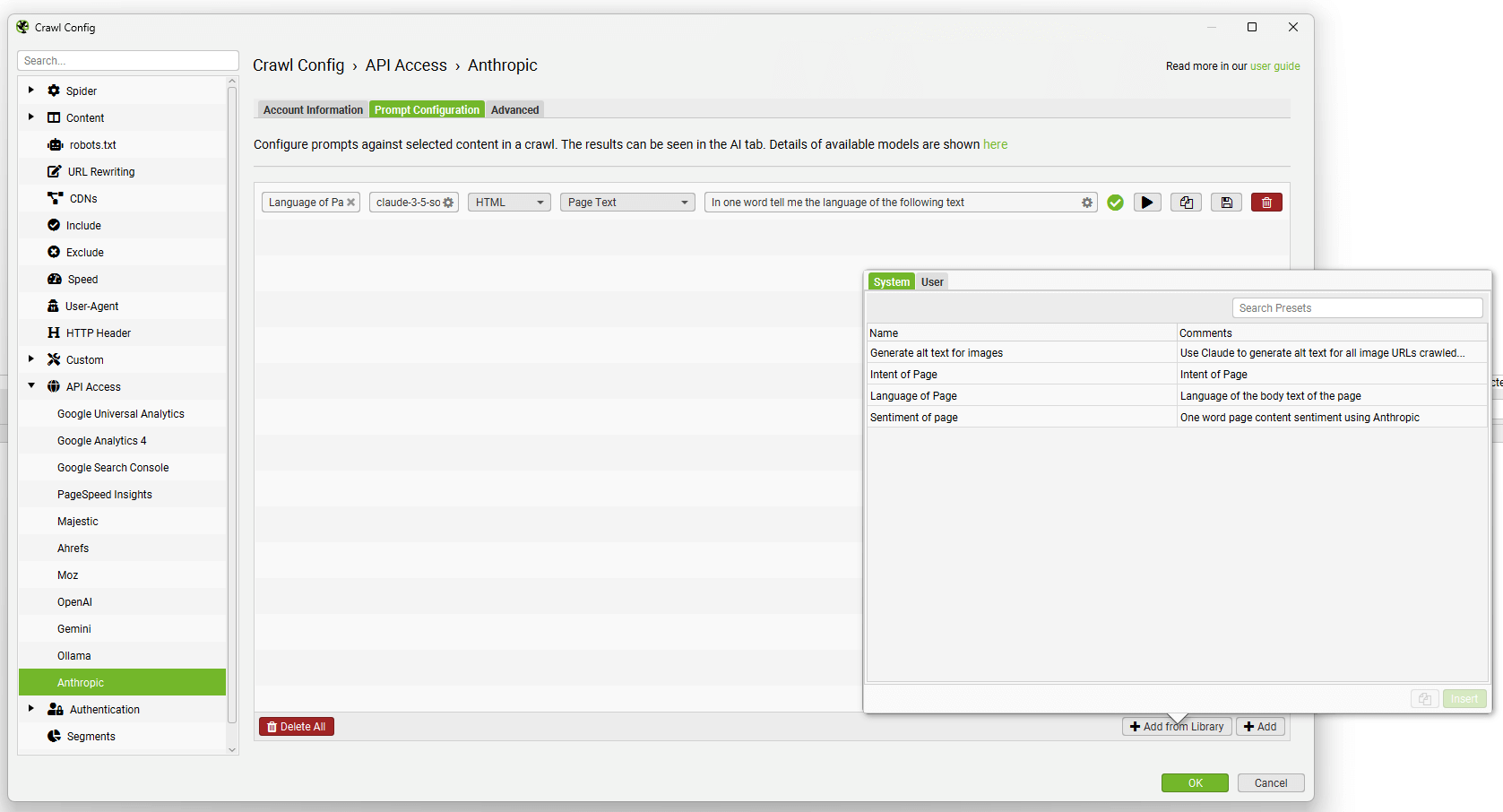
您可以使用“从库添加”按钮,单击“用户”和“+”按钮来�添加和自定义您自己的提示。
可以使用顶部的导出和导入按钮共享自定义提示。
身份验证
配置 > 身份验证
SEO Spider 支持两种形式的身份验证,基于标准的身份验证(包括基本身份验证和摘要身份验证)以及基于 Web 表单的身份验证。
请查看我们的视频指南,了解如何在登录后进行爬网,或继续阅读以下内容。
基本身份验证和摘要身份验证
基本身份验证和摘要身份验证不需要设置,它会在爬取需要登录的页面时自动检测到。 如果您访问网站并且您的浏览器弹出一个窗口,要求您输入用户名和密码,则这将是基本身份验证或摘要身份验证。 如果登录屏幕包含在页面本身中,则这将是 Web 表单身份验证,这将在下一节中讨论。
通常,开发中的站点也会通过 robots.txt 阻止,因此请确保情况并非如此,或者使用“忽略 robot.txt 配置”。 然后只需插入暂存站点 URL,进行爬网,就会出现一个弹出框,就像在 Web 浏览器中一样,要求您输入用户名和密码。
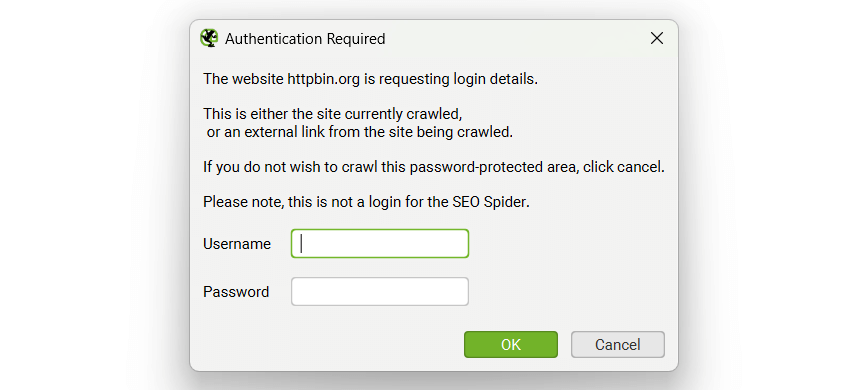
输入您的凭据,爬网将照常继续。
或者,您可以通过“配置 > 身份验证”并单击“基于标准”选项卡上的“添加”来预先输入登录凭据。
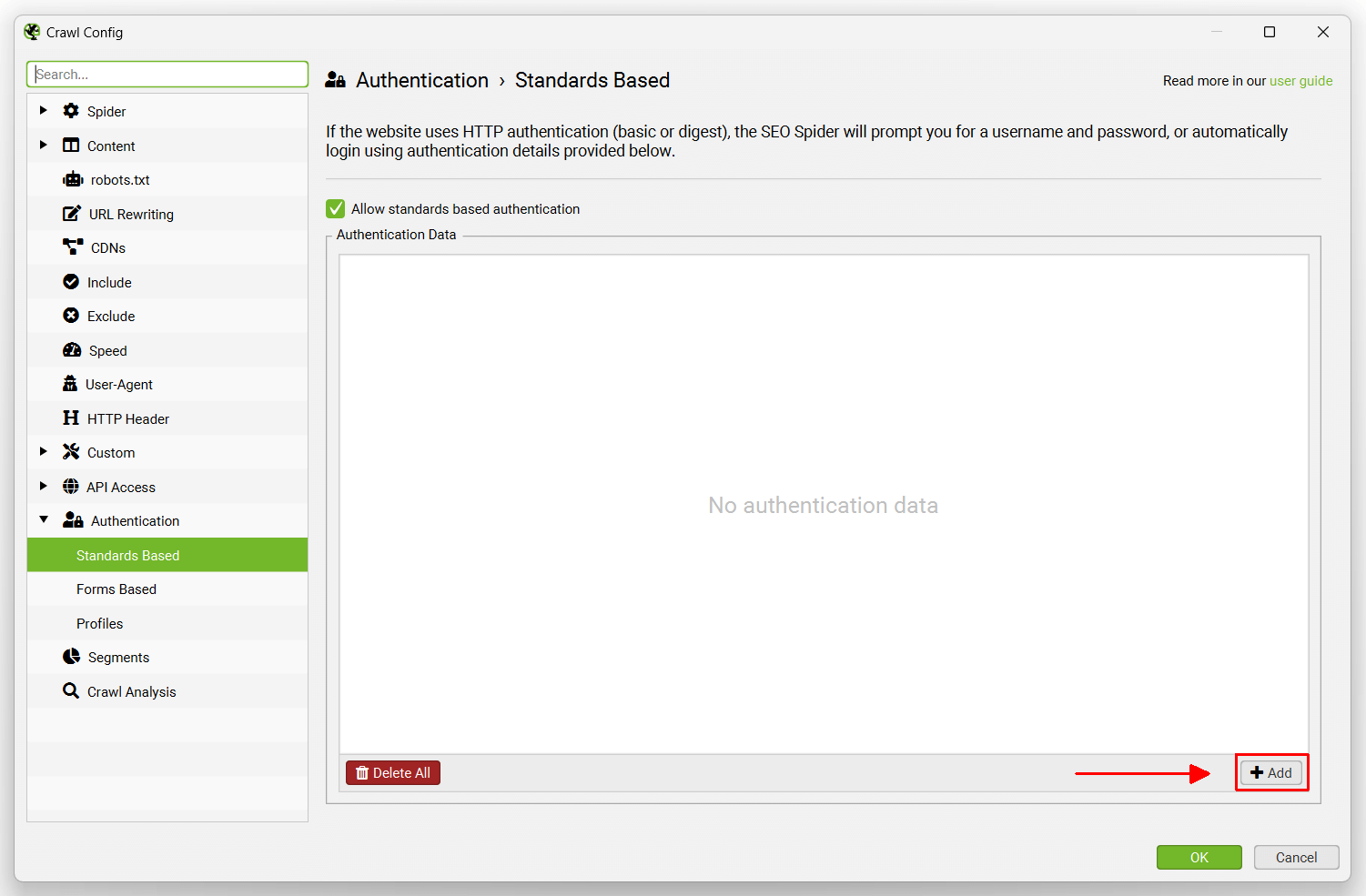
然后输入 URL、用户名和密码。
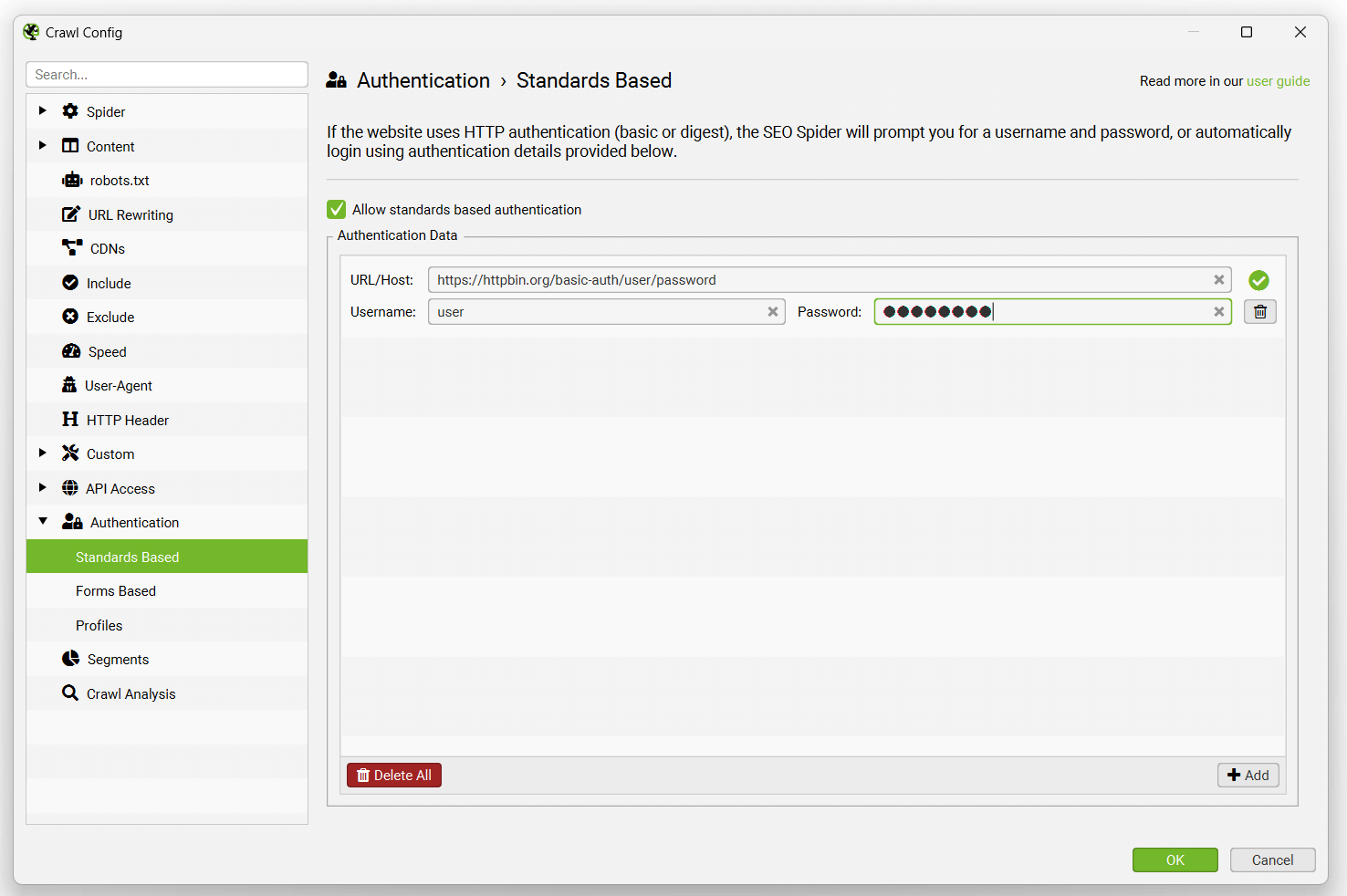
在身份验证配置中输入后,它们将被记住,直到被删除。
此功能不需要许可证密钥。 尝试以下页面,了解身份验证在您的浏览器或 SEO Spider 中的工作方式。
Web 表单身份验证
还有其他 Web 表单和区域需要您使用 Cookie 登录才能进行身份验证,以便能够查看或爬网它。 SEO Spider 允许用户在 SEO Spider 的内置 Chromium 浏览器中登录到这些 Web 表单,然后进行爬网。 此功能需要许可证才能使用。
要登录,请导航到“配置 > 身份验证”,然后切换到“基于表单”选项卡,单击“添加”按钮,输入要爬网的站点的 URL,然后会弹出一个浏览器,允许您登录。
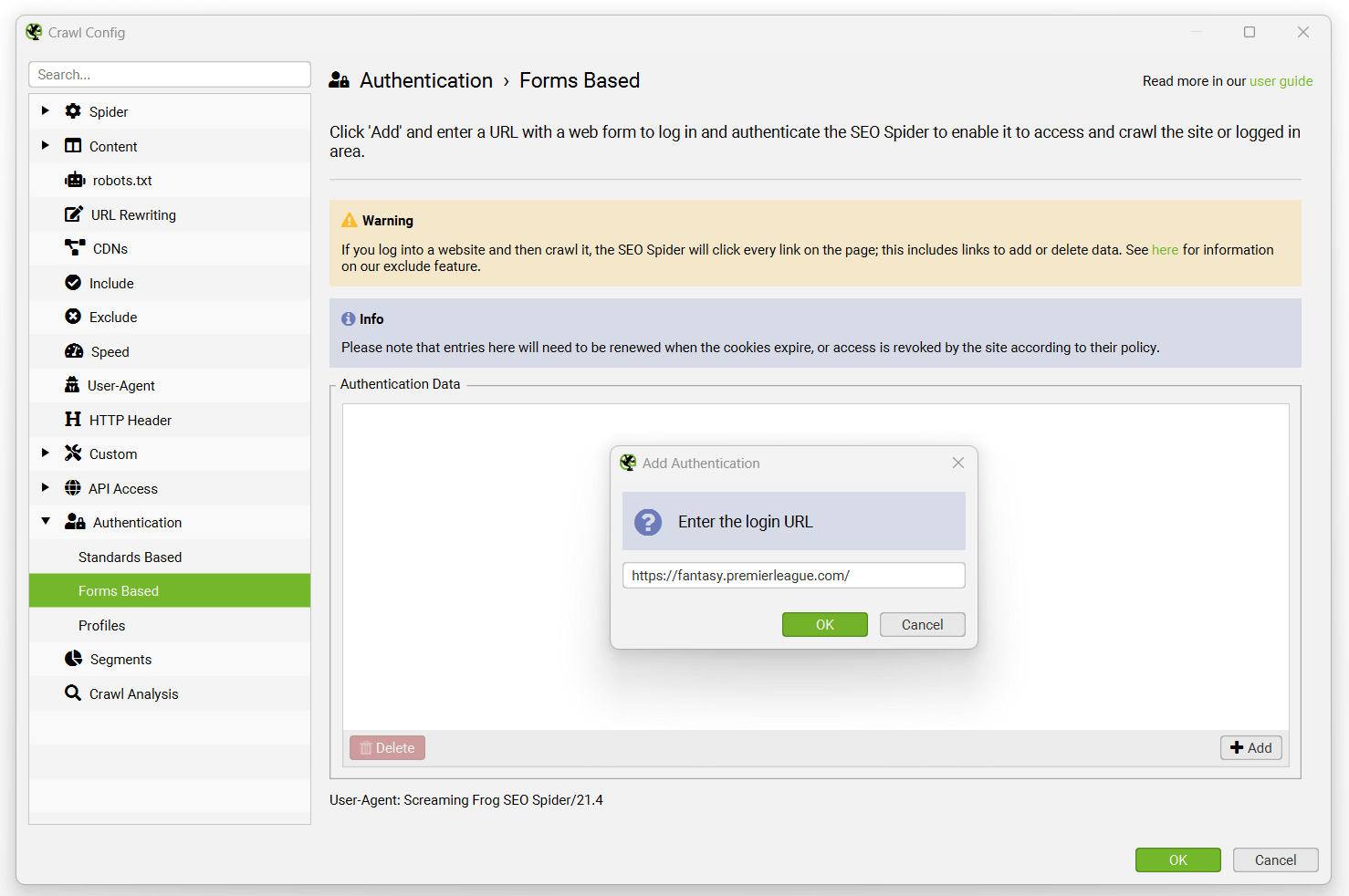
在使用此功能之前,请阅读我们的用户指南中关于爬网 Web 表单密码保护站点的指南。 某些网站可能还需要启用 JavaScript 渲染才能在登录后进行爬网。
请注意 - 这是一个非常强大的功能,因此应负责任地使用它。 SEO Spider 会单击页面上的每个链接; 当您登录时,这可能包括注销、创建帖子、安装插件甚至删除数据的链接。
身份验证配置文件
身份验证配置文件选项卡允许您导出身份验证配置以与计划或命令行一起使用。
这意味着 SEO Spider 可以�登录到基于标准和 Web 表单的身份验证以进行自动爬网。
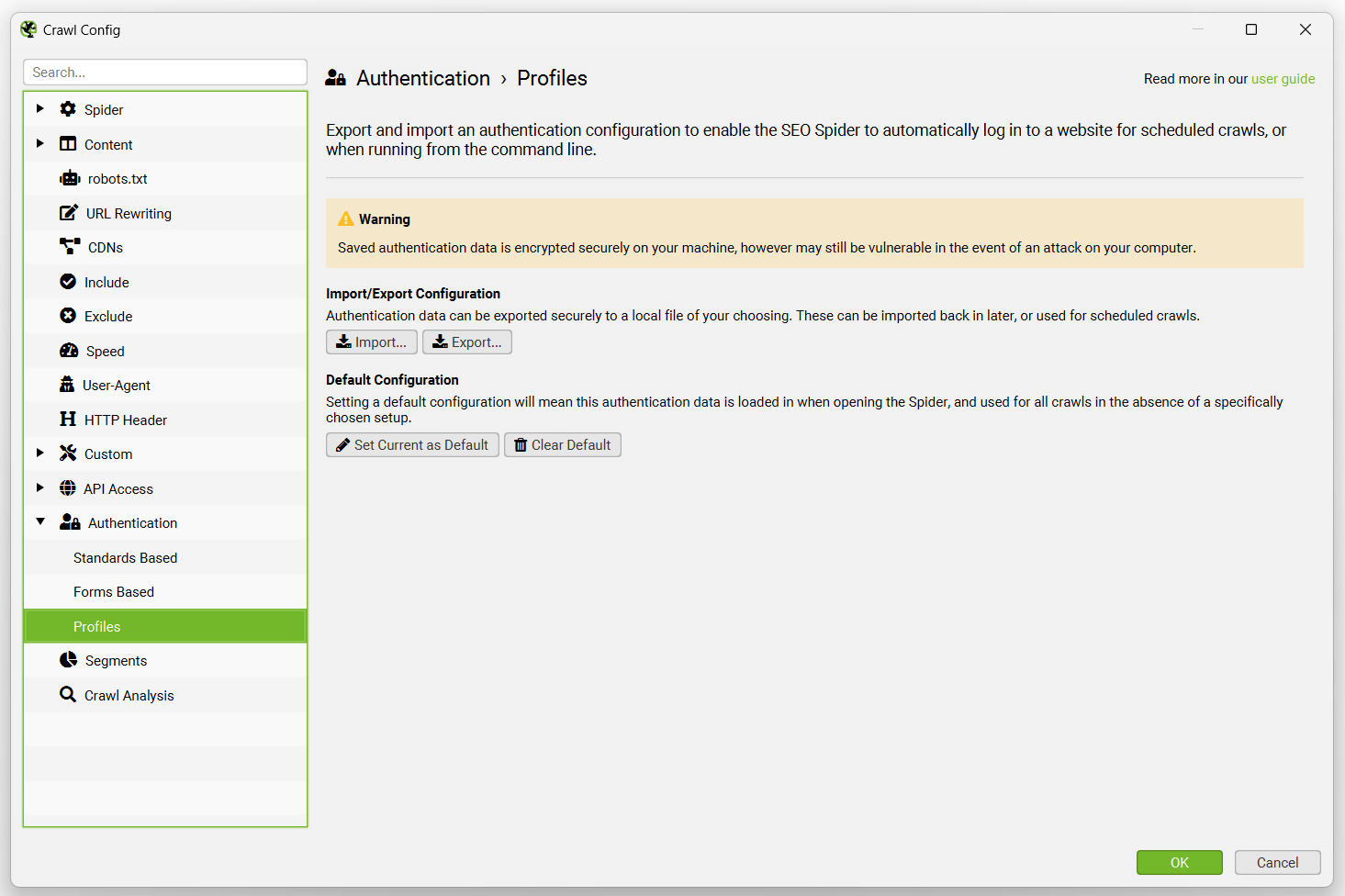
当您通过用户界面中的基于标准或 Web 表单的身份验证进行身份验证后,您可以访问“配置文件”选项卡,并导出 .seospiderauthconfig 文件。
这可以在计划中通过“启动选项”选项卡提供,或者使用命令行的“auth-config”参数提供,如 CLI 选项中所述。
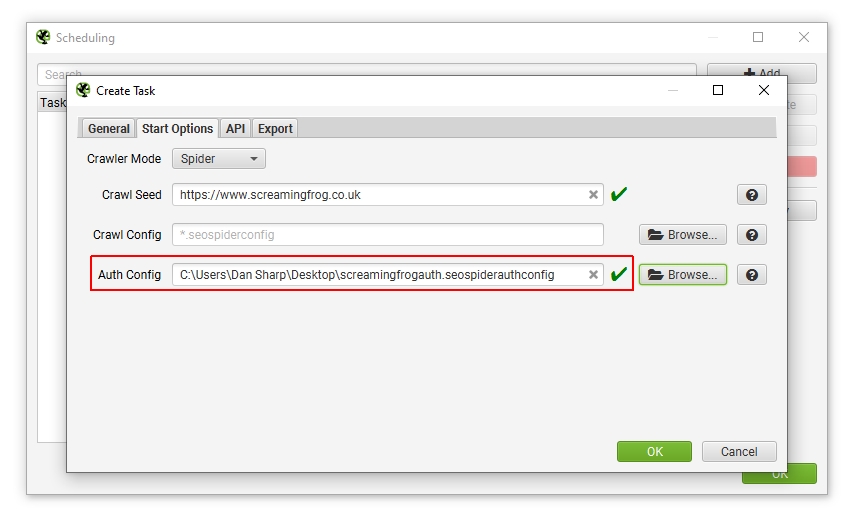
请注意 - 我们无法保证自动 Web 表单身份验证始终有效,因为某些网站会过期登录令牌或具有 2FA 等。 导出或保存默认身份验证配置文件会将身份验证凭据的加密版本使用 AES-256 Galois/Counter Mode 存储在磁盘上。
故障排除
- 基于表单的身份验证使用配置的用户代理。 如果您无法登录,也许可以尝试将其作为 Chrome 或其他浏览器。
分段
配置 > 分段
您可以对爬网进行分段,以更好地识别和监控来自不同模板、页面类型或优先区域的问题和机会。
观看我们的视频,或阅读我们下面的指南,了解如何设置分段。
只有在使用数据库存储模式时,才能使用分段右侧的选项卡和配置。
如果您尚未使用数据库存储模式,我们强烈建议您使用。 这可以通过“文件 > 设置 > 存储模式”进行调整,并且具有许多优点。
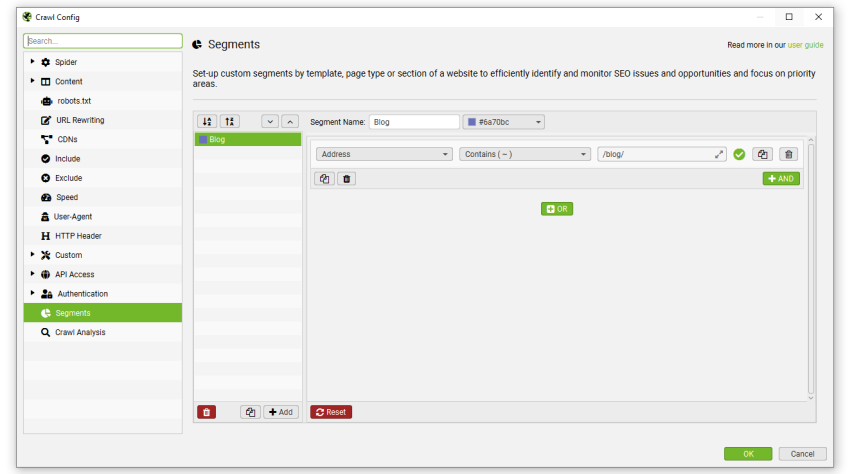
可以通过配置菜单或右侧的“分段”选项卡访问分段配置,它允许您根据在爬网中找到的任何数据进行分段,包括来自 GA 或 GSC 等 API 的数据,或爬网后分析。
您可以在爬网开始时、期间或结束时设置分段。 设置完成后,可以将分段与配置一起保存。
分段列将出现在每个选项卡中,其中包含针对每个 URL 及其分段的彩色标签。
设置分段后,右侧的“问题”选项卡包含一个分段栏,因此您可以快速查看站点上问题发生的位置。
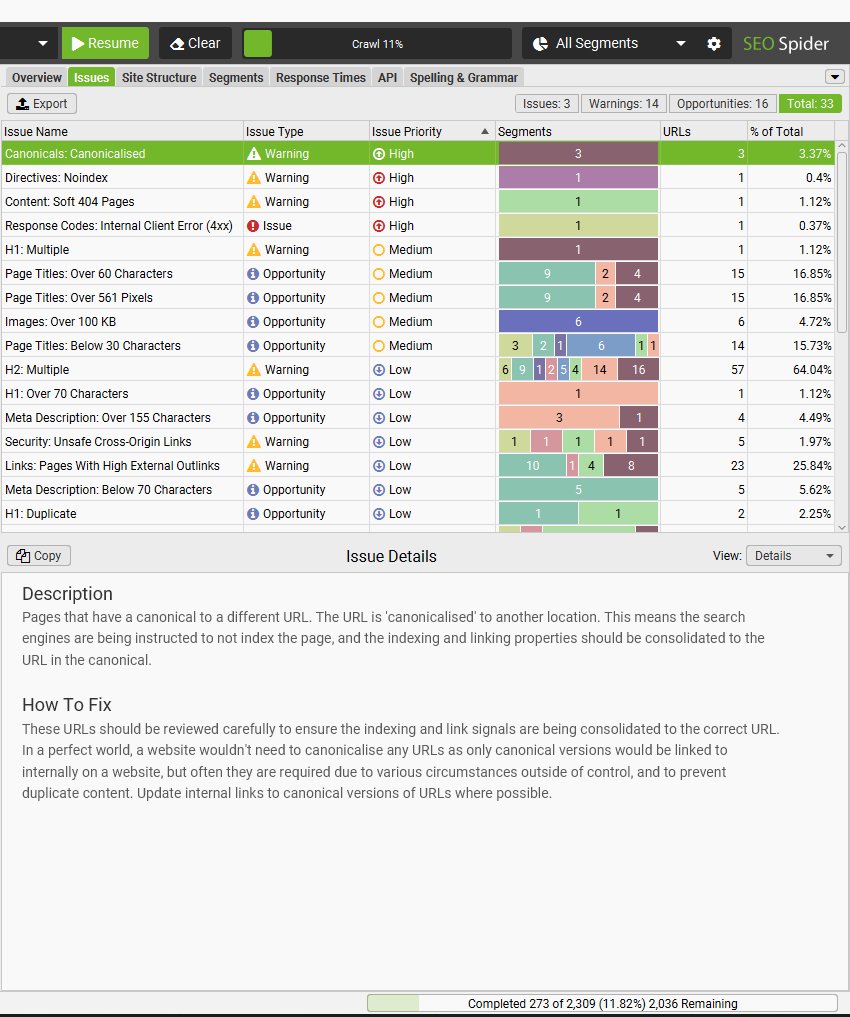
然后,您�可以使用右侧的分段过滤器,向下钻取到各个分段。
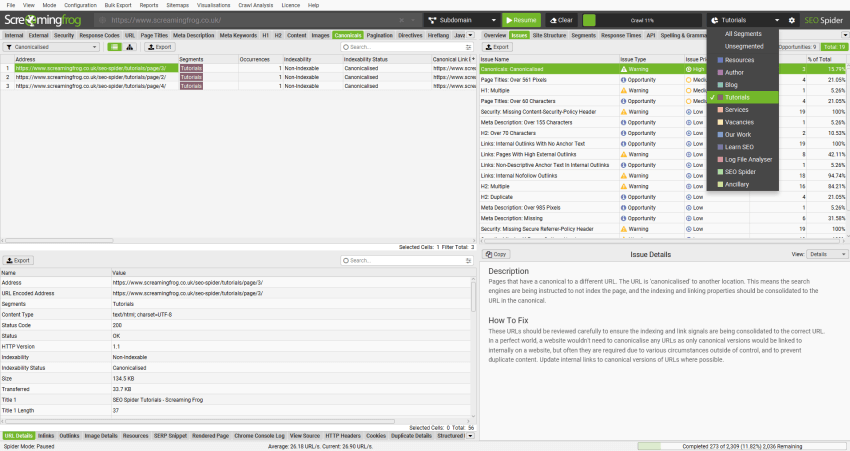
右侧的“分段”选项卡是一个聚合视图,可以快速查看按分段划分的问题发生的位置。
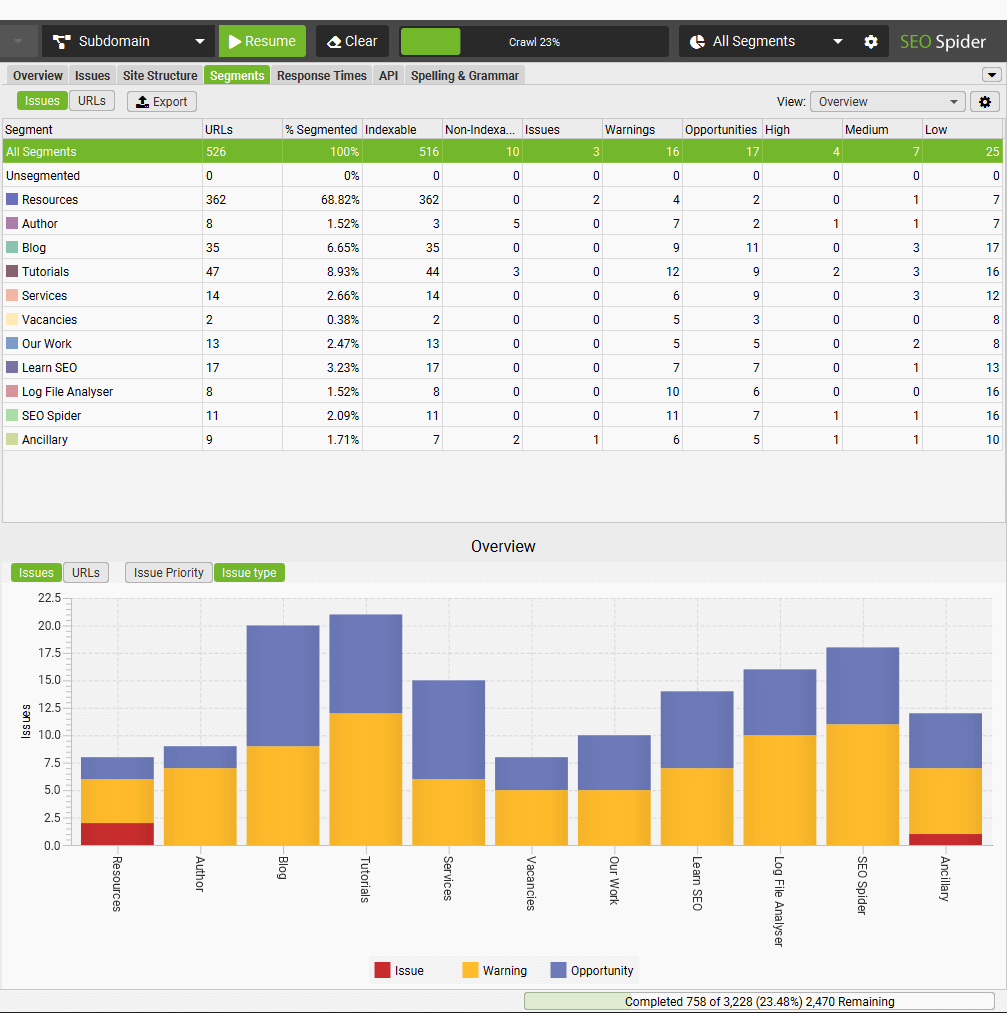
您可以使用“分段”选项卡“视图”过滤器来更好地分析项目,例如按分段划分的爬网深度,或哪些分段具有不同类型的问题。
请注意 - 您可以使用现有分段进行分段。 例如,您可能希望将 URL 包含在分段中,如果它尚未在现有分段中。 这通过优先级顺序起作用。 依赖项必须高于那些才能正常工作。
分段已完全集成到 SEO Spider 中的各种其他功能中。
- 您可以选择按分段对爬网可视化进行着色。
- 您可以选择按分段创建 XML 站点地图,SEO Spider 将自动创建一个引用每个分段站点地图的站点地图索引文件。
- 在为 Looker Studio 导出自动爬网报告时,当提供包含分段设置的已保存配置时,还将自动为每个分段创建一个单独的工作表。 这意味着您也可以在 Looker Studio 爬网报告中按分段监控问题。
爬网分�析
配置 > 爬网分析
SEO Spider 通常在运行时分析和报告数据,其中指标、选项卡和过滤器在爬网期间填充。 但是,“链接得分”和相对较少的过滤器需要在爬网结束时(或停止爬网时)进行计算。
下面可以查看需要“爬网分析”的完整项目列表,并在“配置 > 爬网分析”下看到。
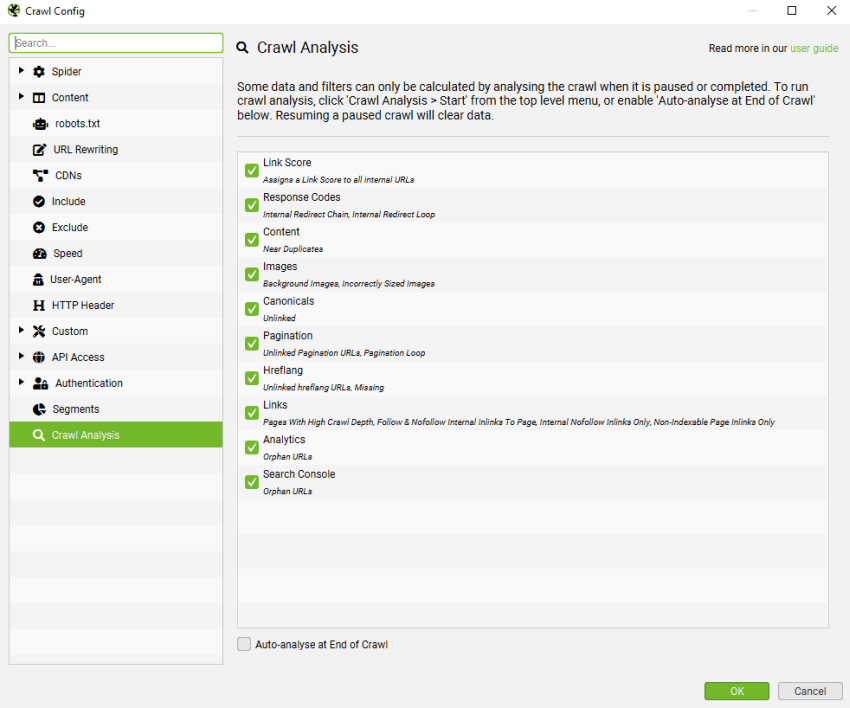
除了“链接得分”之外,以上所有内容都是各自选项卡下的过滤器,“链接得分”是一个指标,并在“内部”选项卡中显示为一列。
在右侧的“概述”窗口窗格中,需要进行“爬网后分析”的过滤器标有“需要爬网分析”,以进一步明确。 特别是“站点地图”过滤器,大多数都需要进行爬网后分析。
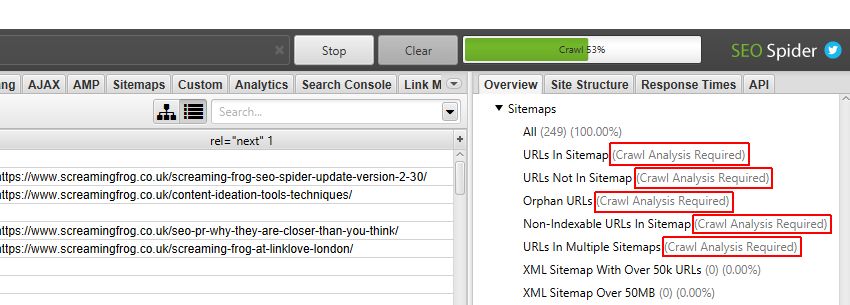
它们还在主窗口窗格中标记为“您需要执行爬网分析才能填充此选项卡的此过滤器”。
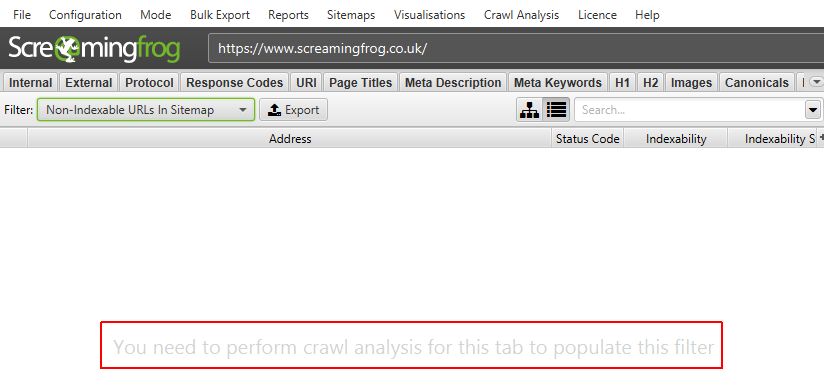
可以通过选中“配置”下的相应“在爬网结束时自动分析”复选框,在爬网结束时自动执行此分析,也可以由用户手动运行。
要运行爬网分析,只需单击顶部菜单中的“爬网分析 > 开始”。

当爬网分析正在运行时,您将看到“分析”进度条,其中包含完成百分比。 在此期间,SEO Spider 可以继续正常使用。

当抓取分析完成后,标有“需要抓取分析”的空过滤器将被填充大量有用的数据。
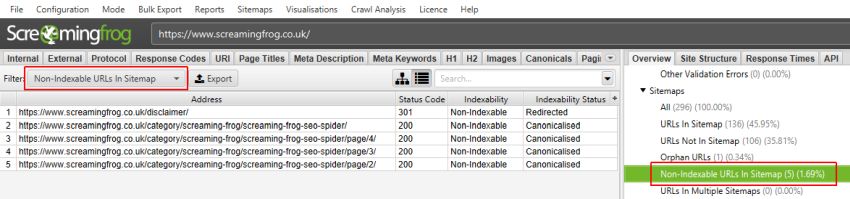
请注意 – 只有在您连接到 Analytics 和 Search Console 的 API,并在其“常规”选项卡下选择“抓取在 Google Analytics/Google Search Console 中发现的新 URL”时,Analytics 和 Search Console 的孤立 URL 过滤器才会被填充。否则,孤立 URL 只能在“报告 > 孤立页面”下查看。
有关更多信息,请观看我们的抓取分析视频指南。
用户界面
文件 > 设置 > 用户界面 (Windows, Linux)
Screaming Frog SEO Spider > 设置 > 用户界面 (macOS)
用户界面菜单下有一些配置选项。这些选项如下:
- 主题 > 浅色 / 深色 – 默认情况下,SEO Spider 使用浅灰色主题。但是,您可以切换到深色主�题(也称为“深色模式”、“蝙蝠侠模式”等)。此主题有助于减轻眼睛疲劳,尤其适合在弱光环境下工作的人。
- 强调色 – SEO Spider 使用绿色作为其默认颜色来突出显示行、单元格和其他 UI 选项。但是,您可以根据自己的喜好调整此颜色。
语言
文件 > 设置 > 语言 (Windows, Linux)
Screaming Frog SEO Spider > 设置 > 语言 (macOS)
GUI 提供英语、西班牙语、德语、法语和意大利语版本。它将在启动时检测您机器上使用的语言,并默认使用该语言。
也可以通过“文件 > 设置 > 语言”在工具中设置语言。
我们将来可能会支持更多语言,如果您希望我们支持某种语言,请通过 support 告知我们。
代理
文件 > 设置 > 代理 (Windows, Linux)
Screaming Frog SEO Spider > 设置 > 代理 (macOS)
代理功能允许您配置 SEO Spider 以使用代理服务器并提供凭据。
您需要在配置窗口中配置代理的地址和端口。要禁用代理服务器,请�取消选中“使用代理服务器”选项。
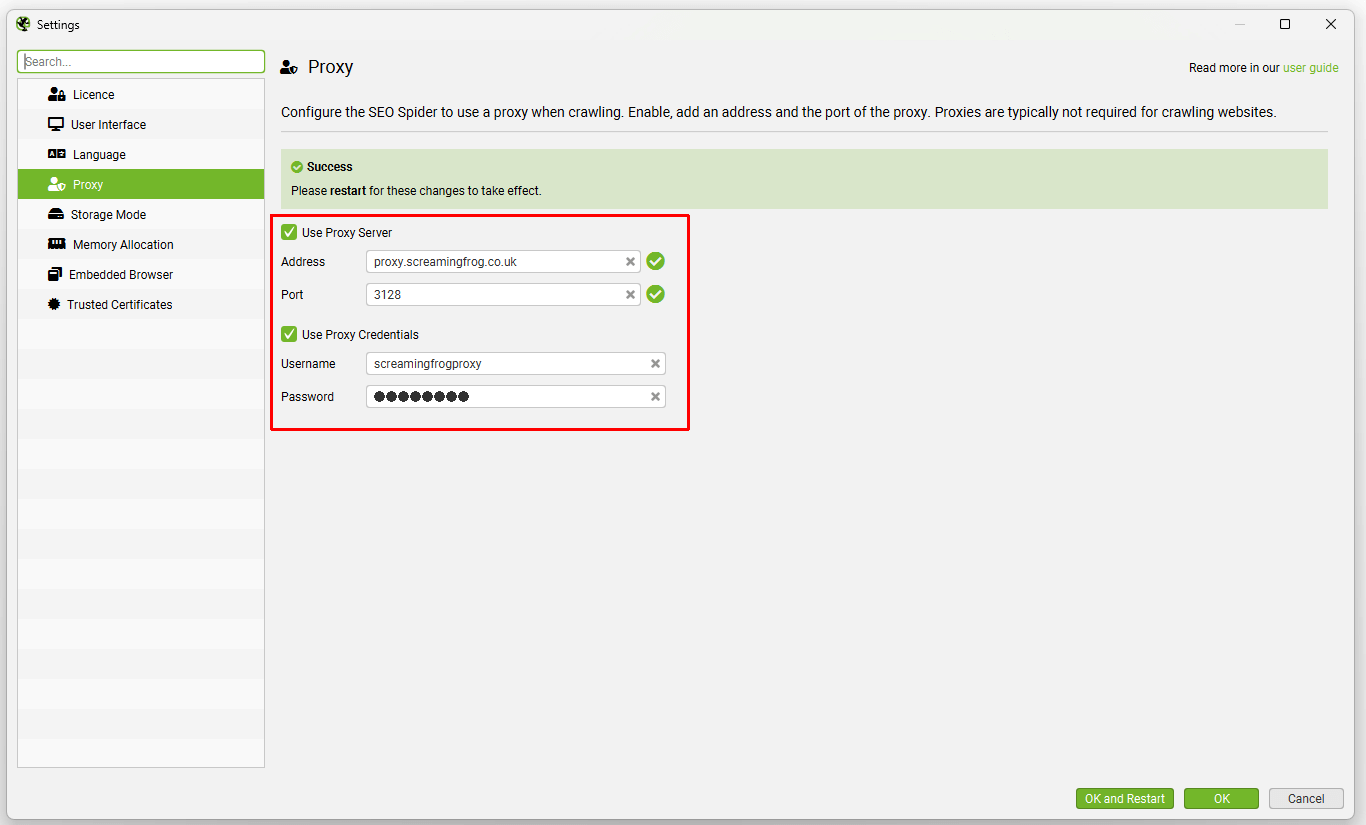
请注意:
- 只能配置 1 个代理服务器。
- 您必须重新启动才能使更改生效。
- 无法添加例外 – 所有 HTTP/HTTPS 流量要么通过代理,要么都不通过。
存储模式
文件 > 设置 > 存储模式 (Windows, Linux)
Screaming Frog SEO Spider > 设置 > 存储模式 (macOS)
Screaming Frog SEO Spider 使用可配置的混合引擎,允许用户选择将抓取数据存储在数据库中或 RAM 中。
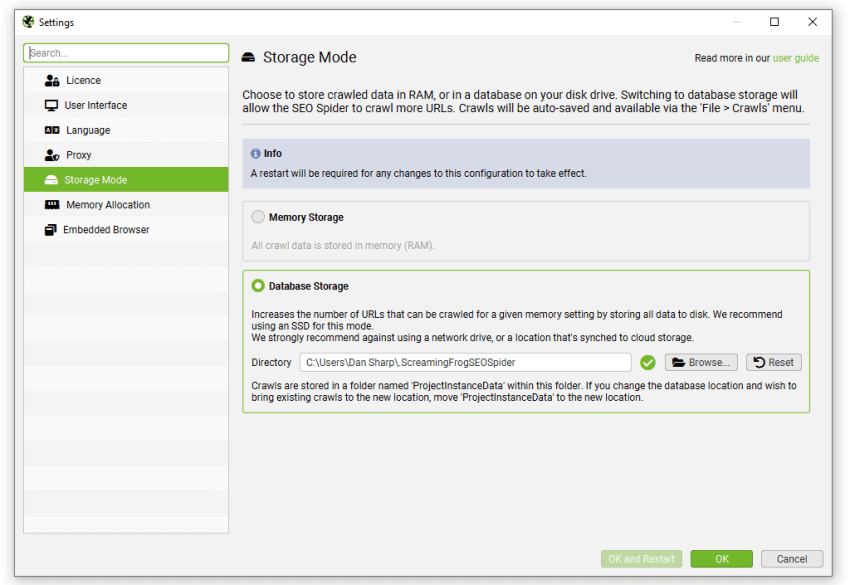
默认情况下,SEO Spider 将以数据库存储模式启动,并使用您的硬盘来存储和处理数据。这允许 SEO Spider 抓取比内存存储模式更多的 URL,还可以自动保存抓取,并允许更快地打开已保存的抓取。
从根本上讲,两种存储模式仍然可以提供几乎相同的抓取体验,从而可以实时报告、过滤和调整抓取。但是,存在一些关键差异,理想的存储将取决于抓取场景和机器规格。
数据库存储
我们建议将其作为具有 SSD 的用户的默认存储,并用于大规模抓取。
数据库存储模式允许在给定的内存设置下抓取更多 URL,对于具有固态驱动器 (SSD) 的设置,其抓取速度接近 RAM 存储。
数据库存储模式的全部优势包括:
默认的抓取限制为 500 万个 URL,但这不是一个硬性限制 – SEO Spider 能够在正确的设置下抓取更多 URL。例如,一台具有 500gb SSD 和 16gb RAM 的机器,应该允许您大约抓取多达 1000 万个 URL。
我们不建议在数据库存储模式下使用常规硬盘驱动器 (HDD),因为硬盘驱动器的写入和读取速度太慢,并且会成为抓取的瓶颈。
不支持使用网络驱动器 – 这将太慢且连接不可靠。由于这些进程会锁定文件,因此不支持使用远程同步的本地文件夹,例如 Dropbox 或 OneDrive。也不支持 Vault 驱动器。
内存存储
内存存储模式允许几乎所有设置进行超快速和灵活的抓取。但是,由于机器的 RAM 比硬盘空间少,这意味着 SEO Spider 通常更适合在内存存储模式下抓取 50 万个 URL 以下的网站。
用户能够在正确的设置下抓取更多内容,具体取决于正在抓取的网站的内存密集程度。作为一个非常粗略的指南,一台具有 8gb RAM 的 64 位机器通常允许您抓取几十万个 URL。
除了是较小网站的更好选择之外,还建议没有 SSD 或磁盘空间不足的机器使用内存存储模式。
查看我们关于存储模式的视频指南。
故障排除
- 如果数据库目录旁边显示红色 X 而不是绿色勾号,请将鼠标悬停在其上以查看错误消息。
- 如果错误消息包含“OverlappingFileLockException”,则表示您正在使用 ExFAT/MS-DOS (FAT) 文件系统,由于 JDK-8205404,macOS 不支持该文件系统。您需要选择具有不同格式的驱动器或将驱动器重新格式化为不同的格式才能解决此问题。您可以使用“磁盘实用工具”应用程序来查看当前格式并重新格式化驱动器。
内存分配
文件 > 设置 > 内存分配 (Windows, Linux)
Screaming Frog SEO Spider > 设置 > 内存分配 (macOS)
SEO Spider 使用 Java,Java 需要在启动时分配内存。默认情况下,SEO Spider 将为 32 位机器分配 1gb,为 64 位机器分配 2gb。
增加内存分配将使 SEO Spider 能够抓取更多 URL,尤其是在 RAM 存储 模式下,以及在 存储到数据库 时。
我们建议将内存分配设置为至少低于您的总物理机器内存 2gb,以便操作系统和其他应用程序可以运行。
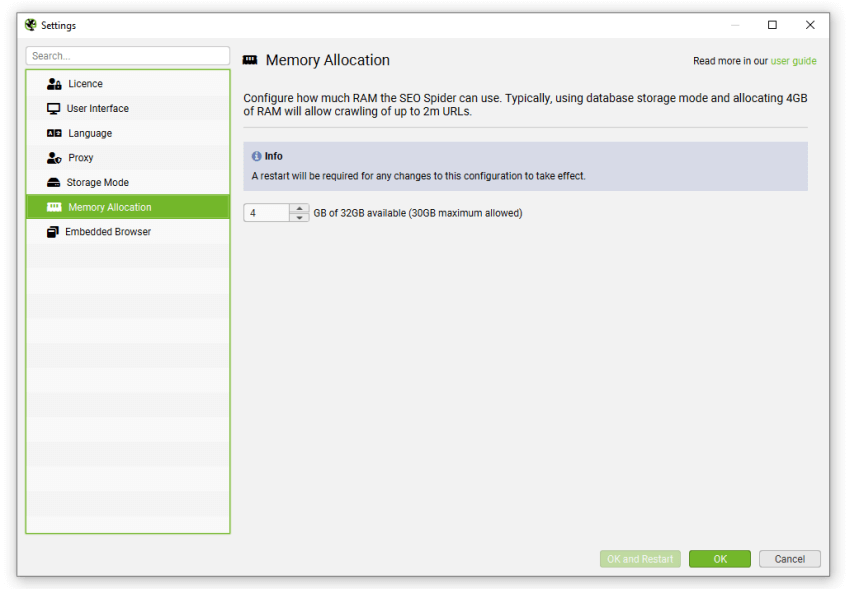
如果您想了解更多关于抓取大型网站、内存分配和可用存储选项的信息,请参阅我们关于 抓取大型网站 的指南。
受信任的证书
文件 > 设置 > 受信任的证书 (Windows, Linux)
Screaming Frog SEO Spider > 设置 > 受信任的证书 (macOS)
中间人 (MITM) 代理将重新签名 TLS 证书。如果重新签名的证书不是来自受信任的证书颁发机构 (CA),则 TLS 连接将被拒绝。
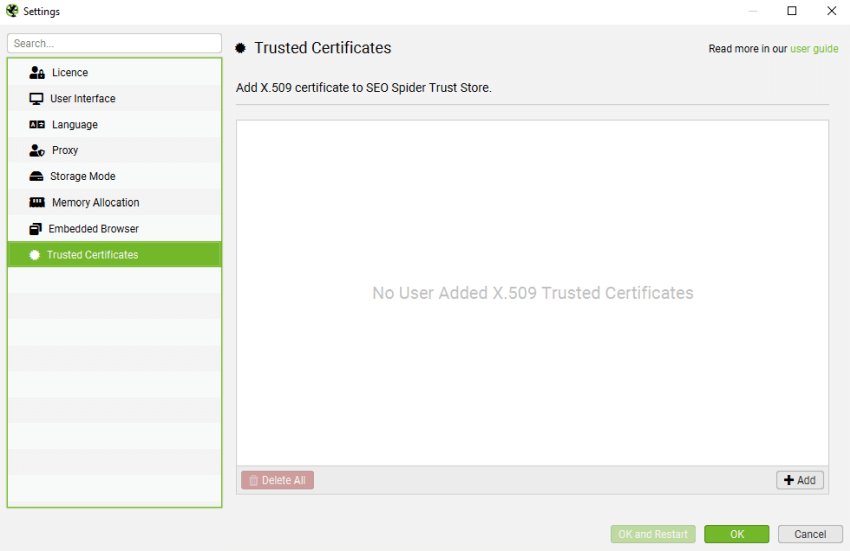
采用这种代理风格的公司通常会向员工分发 X.509 证书。SEO Spider 可以通过将其添加到“受信任的证书文件夹”来使用此 X.509 证书。
SEO Spider 仅接受具有以下扩展名的 X.509 证书:.crt、.pem、.cer 和 .der。
如何添加受信任的证书
当代理更改证书的颁发者时,可以在 Screaming Frog 中快速看到。在 Windows 上单击“文件 > 设置 > 受信任的证书”,或在 macOS 上单击“Screaming Frog SEO Spider > 设置 > 受信任的证书”,然后单击“发现”按钮。
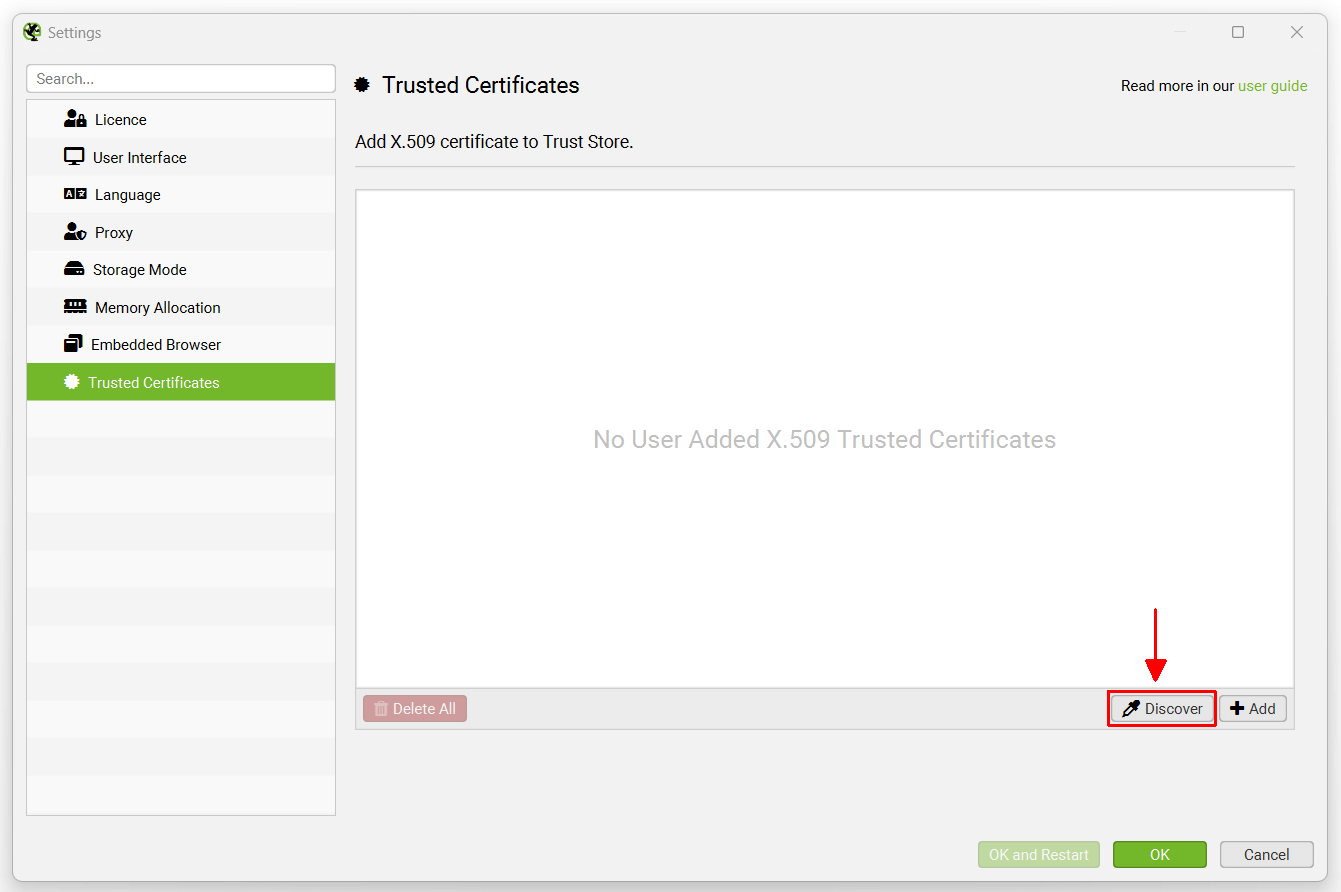
Screaming Frog 网站证书的真正颁发者是“GTS CA 1P5”,但是,您应该看到这是不同的东西 – 例如您的代理,例如 ZScaler 或 McAfee。这表明证书的颁发者正在您的网络环境中被更改。
如果您看到“ZScaler、McAfee”等作为颁发者证书,请单击其旁边的“添加”按钮。
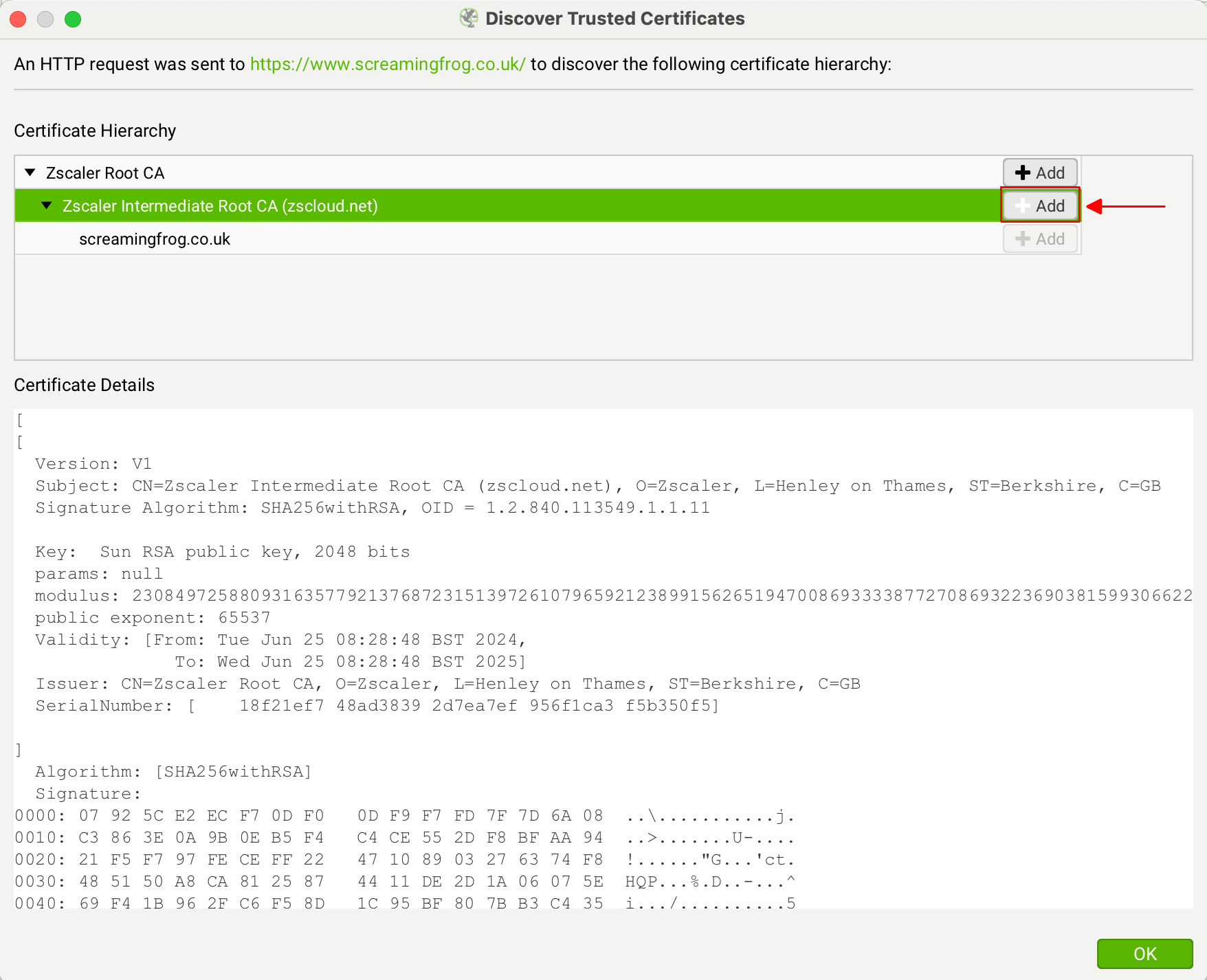
这会将证书文件添加到 SEO Spider 受信任的证书信任存储中。
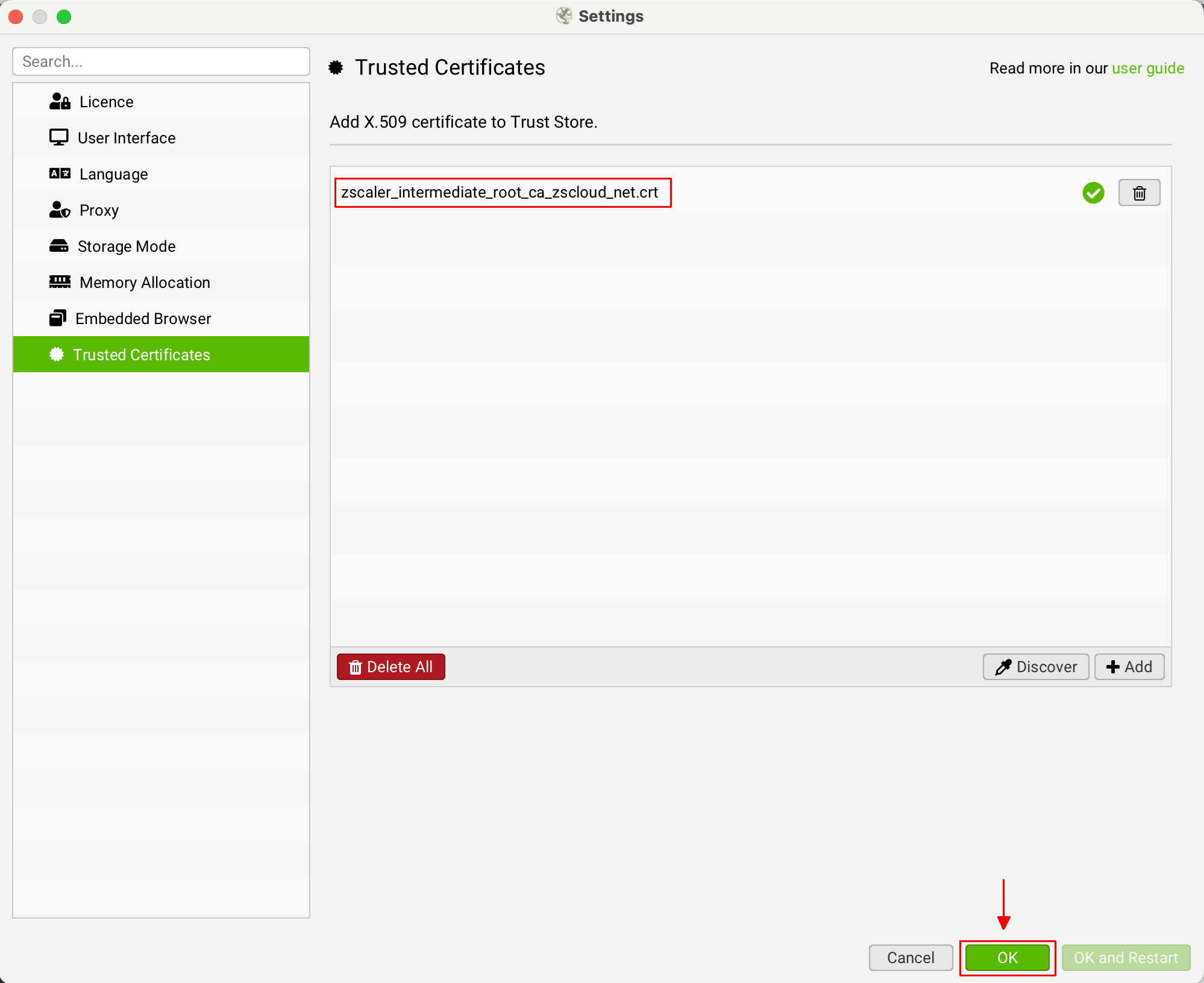
然后您可以单击“确定”。然后您应该能够验证您的许可证。
通知
文件 > 设置 > 通知 (Windows, Linux)
Screaming Frog SEO Spider > 设置 > 通知 (macOS)
通知设置允许您连接到电子邮件帐户,并在抓取完成后从此帐户向选定的电子邮件地址发送电子邮件。
您可以选择 Outlook 或 Gmail 帐户,或设置自定义 SMTP 设置以发送电子邮件通知。
如果您选择 Gmail,请记住在授权期间确认“代表您发送电子邮件”框,否则将不会发送电子邮件。
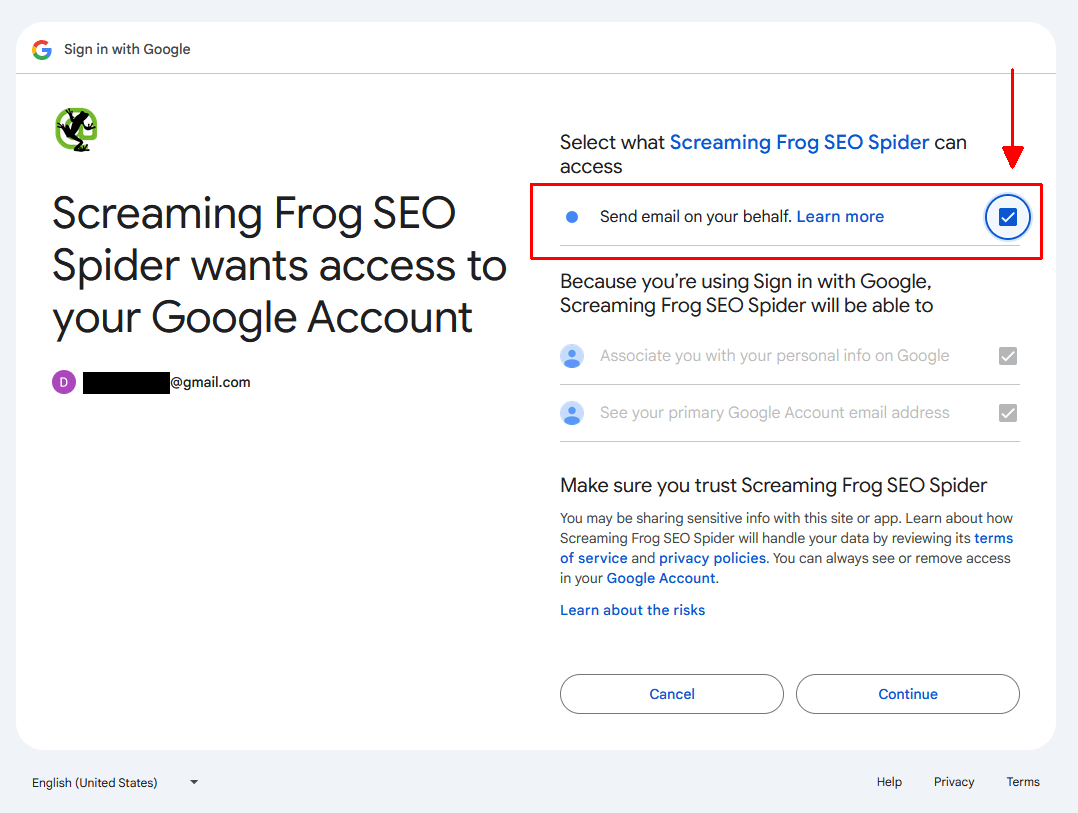
发送的电子邮件确认抓取完成,并提供来自抓取的顶级数据。
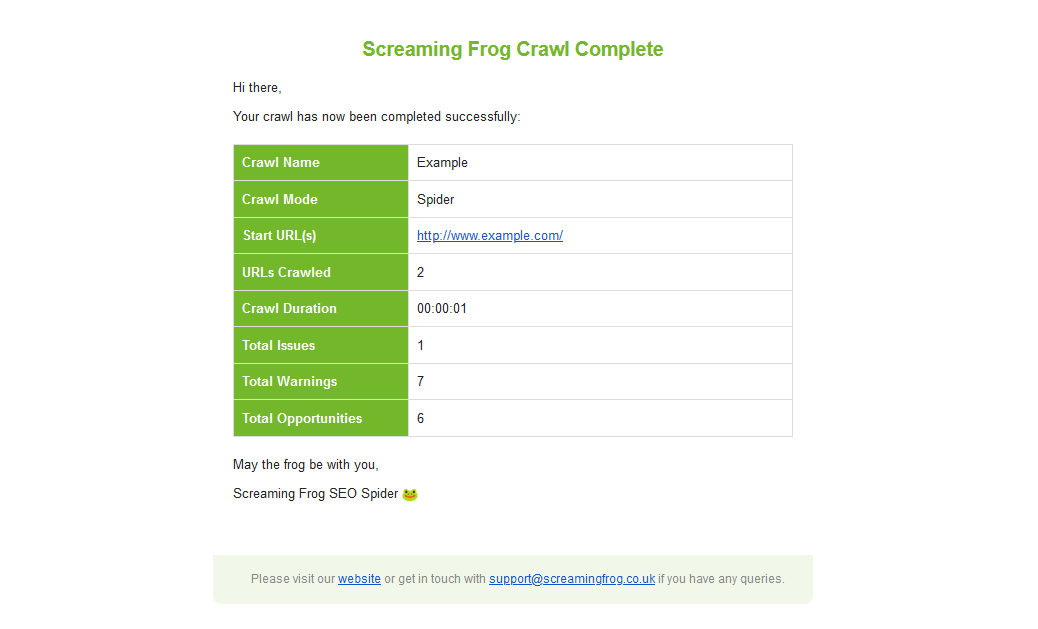
有两种方法可以在抓取完成后发送电子邮件。
所有抓取的电子邮件
启用“抓取完成时发送电子邮件”选项,以便在每次抓取完成后向指定的电子邮件地址发送电子邮件。
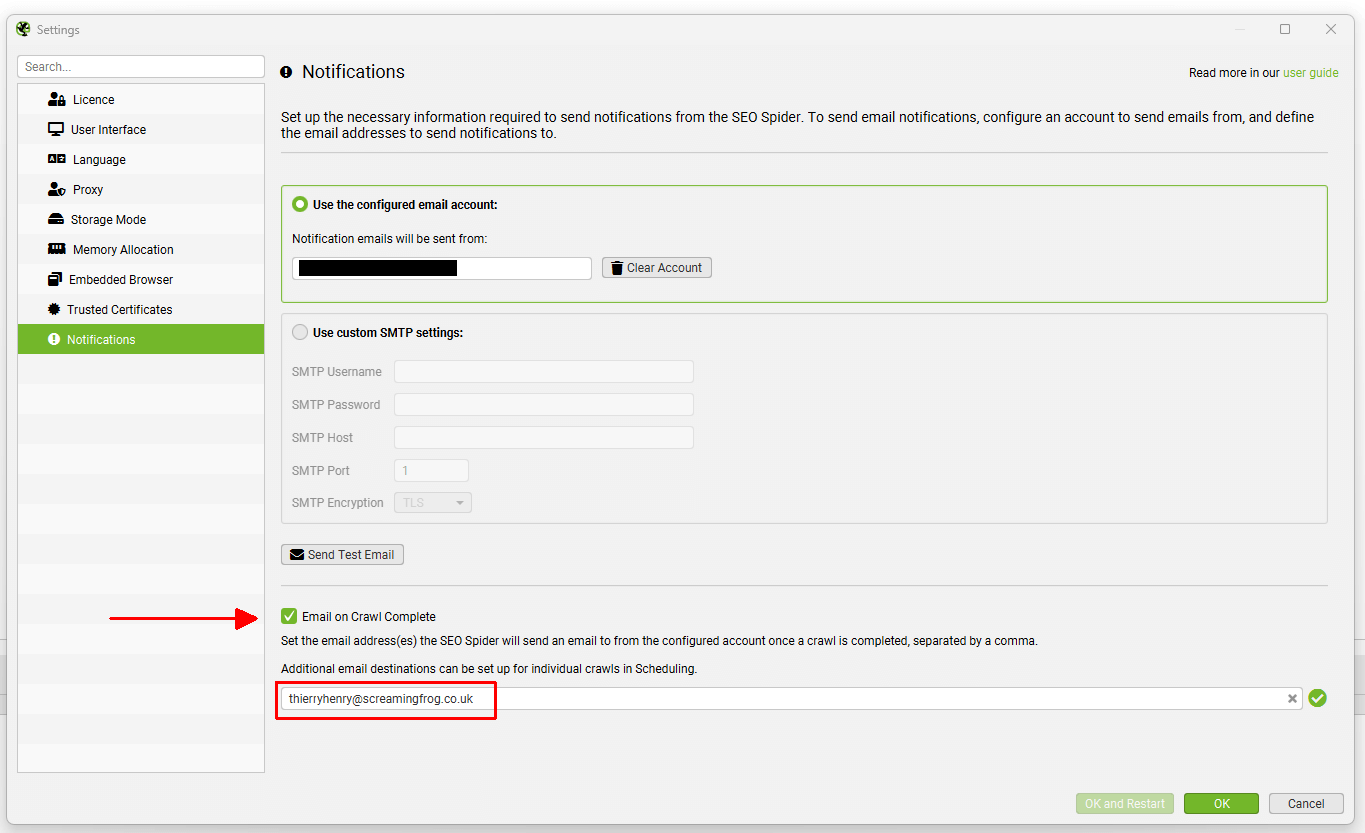
当用户或团队想要知道任何抓取何时完成时,这很有用。
计划抓取的电子邮件
或者,使用“文件 > 计划 > 计划抓取任务”通过计划抓取任务中的“通知”选项卡,在特定计划抓取完成后发送通知电子邮件。
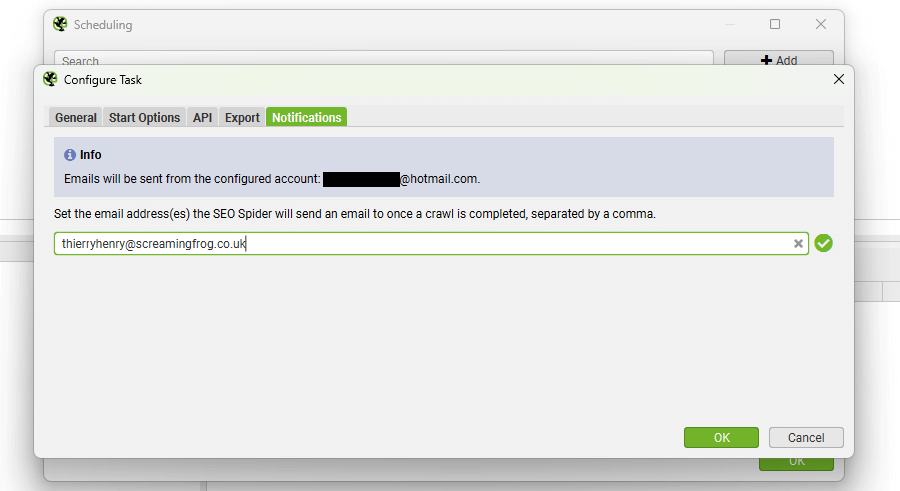
当用户或团队只想知道特定抓取何时完成时,这很有用。
请注意: 如果您收到关于“Screaming Frog 抓取完成”的电子邮件,则不是我们发送的。请查看您自己的设置,或与您合作的同事和代理机构联系,他们可能已设置这些设置以进行任何调整。
模式
模式 > Spider / List / SERP / Compare / APIs
Spider 模式
这是 SEO Spider 的默认模式。在此模式下,SEO Spider 将抓取网站,收集链接并将 URL 分类到各种选项卡和过滤器中。只需输入您选择的 URL,然后单击“开始”。
List 模式
在此模式下,您可以检查预定义的 URL 列表。此列表可以来自各种来源 – 简单的复制和粘贴,或 .txt、.xls、.xlsx、.csv 或 .xml 文件。将扫描文件以查找带有 http:// 或 https:// 前缀的 URL,所有其他文本将被忽略。例如,您可以直接上传 Adwords 下载,所有 URL 将自动找到。

如果您正在执行站点迁移并希望测试 URL,我们强烈建议使用“ 始终遵循重定向‘ 配置,以便 SEO Spider 找到最终目标 URL。查看这些 URL 的最佳方式是通过“重定向链”报告,我们在“ 如何审核重定向‘ 指南中进行了更详细的介绍。
List 模式将抓取深度设置更改为零,这意味着只会检查上传的 URL。如果您想检查这些 URL 中的链接,请在“配置 > Spider”中的“限制”选项卡中将抓取深度调整为 1 或更大。List 模式还默认将 Spider 设置为忽略 robots.txt,我们假设如果上传列表,则意图是抓取列表中的所有 URL。
如果您希望以与上传顺序相同的顺序导出 List 模式下的数据,请使用用户界面顶部“上传”和“开始”按钮旁边的“导出”按钮。

导出中的数据将与原始上传中的顺序相同,并包括原始上传中的所有确切 URL,包括重复项或执行的任何修复。
如果您想了解如何在列表模式下执行更高级的抓取,请阅读我们的如何使用列表模式指南。
SERP 模式
在此模式下,您可以将页面标题和元描述直接上传到 SEO Spider 中,以计算像素宽度(和字符长度!)。此模式不涉及任何抓取,因此它们不需要在网站上实际存在。
这意味着您可以从 SEO Spider 导出页面标题和描述,在 Excel 中进行批量编辑(如果您更喜欢这种方式,而不是在工具本身中进行编辑),然后将它们上传回工具,以了解它们在 Google 的 SERP 中的显示效果。
在“报告”下,我们有一个新的“SERP 摘要”报告,其格式是重新上传页面标题和描述所需的格式。我们只需要三个标题,分别是“URL”、“Title”和“Description”。
例如 –

您可以上传 .txt、.csv 或 Excel 文件。
比较模式
此模式允许您比较两次抓取,并查看数据如何随时间在选项卡和过滤器中发生变化。请参阅我们关于“如何比较抓取”的教程,以获取详细的演练指南。
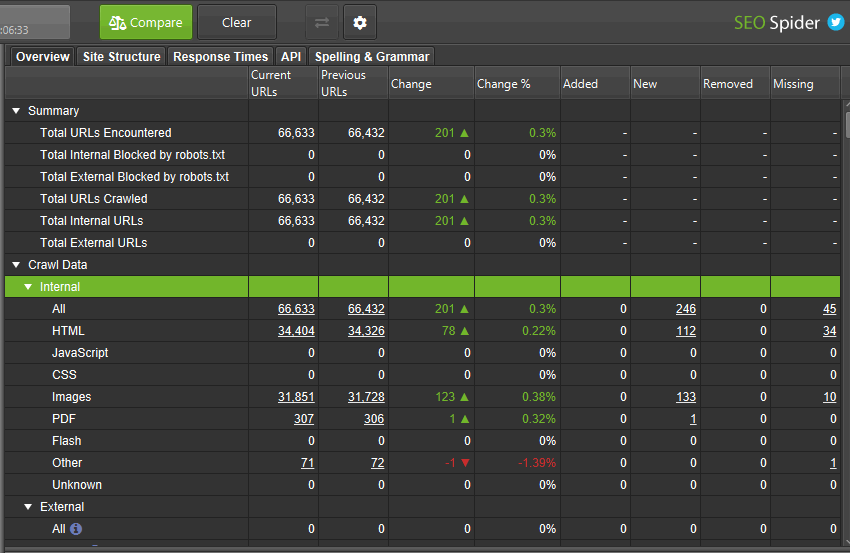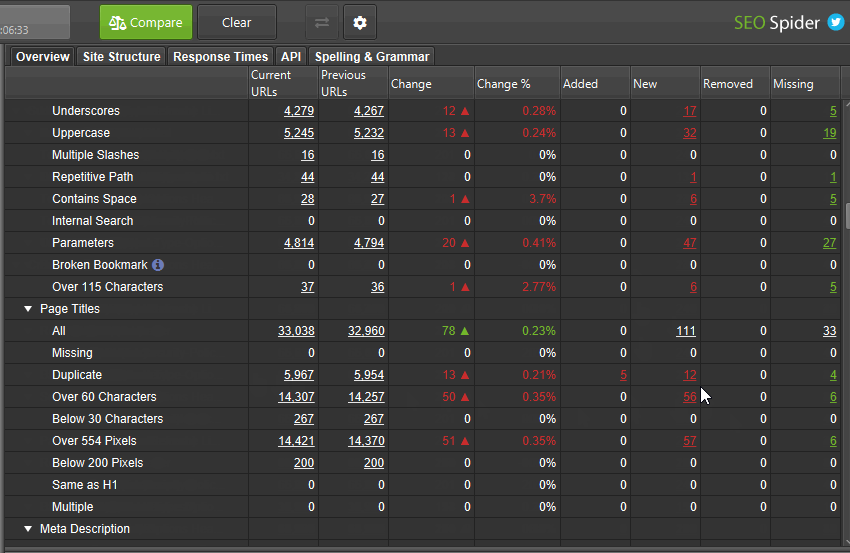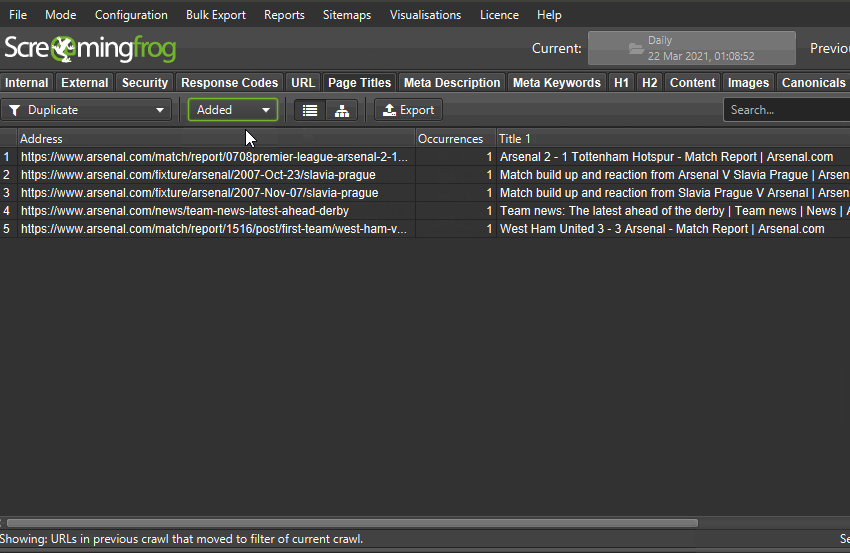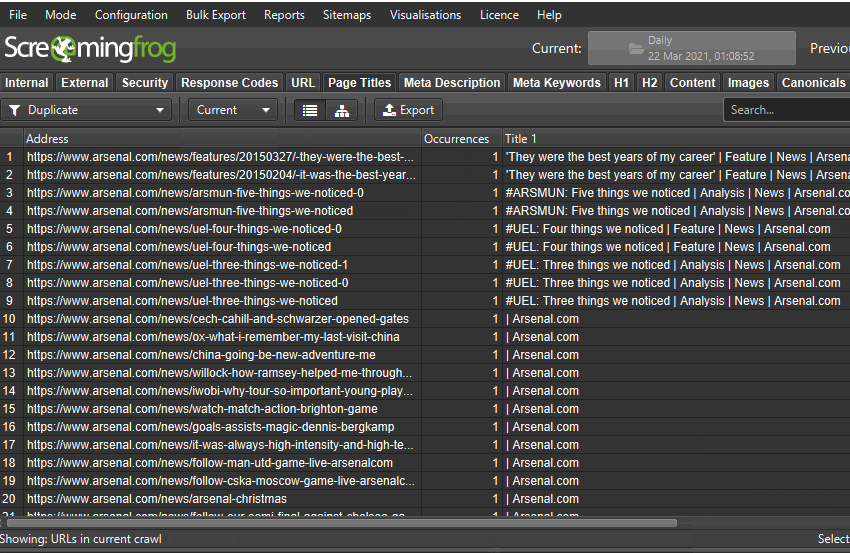
比较功能仅在具有许可证的数据库存储模式下可用。如果您尚未迁移,只需“File > Settings > Storage Mode”并选择“Database Storage”即可。
有两种比较抓取的选项 –
- 通过“Mode > Compare”切换到“compare”模式,然后通过顶部菜单单击“Select Crawl”以选择您要比较的两个抓取。

- 在“Spider”或“List”模式下,转到“File > Crawls”,突出显示两个抓取,然后“Select To Compare”,这将使您切换到“compare”模式。
然后,您可以通过“齿轮”图标或单击“Config > Compare”来调整比较配置。这允许您选择其他元素来分析更改检测。
然后单击“Compare”以运行抓取比较分析,并填充右侧的概览选项卡,以显示当前和以前的抓取数据以及更改。
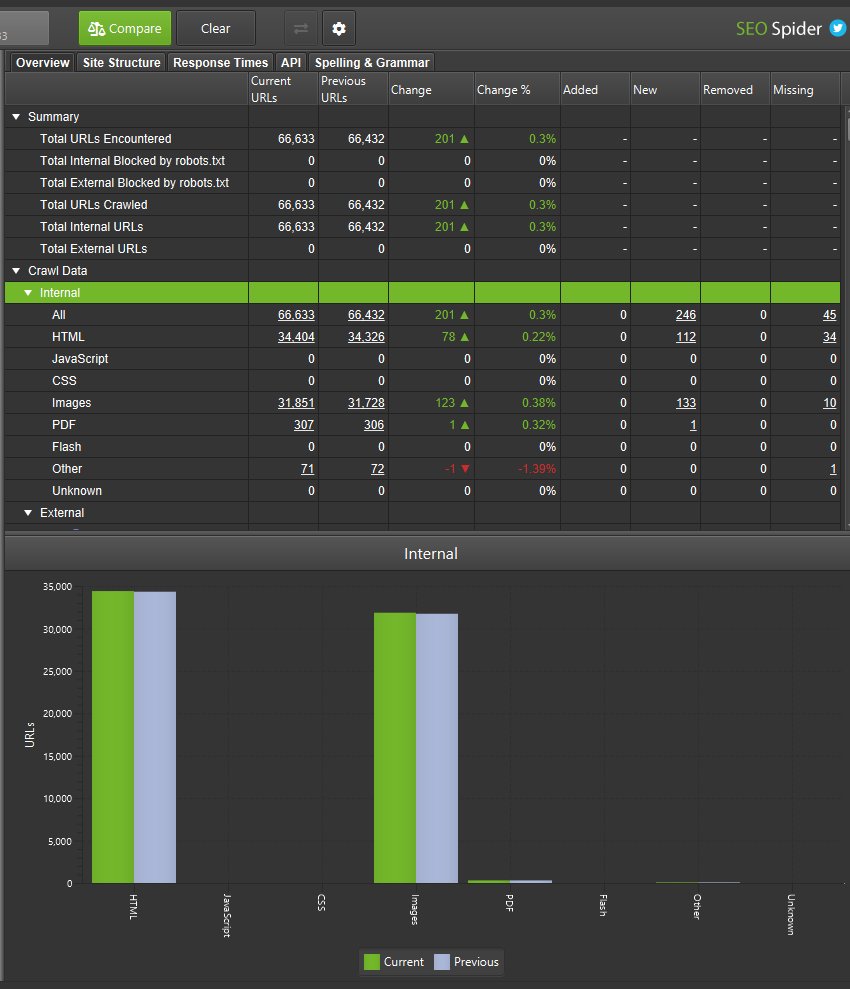
您可以单击列中的数字以查看哪些 URL 已更改,并使用主窗口视图上的过滤器在当前和以前的抓取之间切换,或添加、新建、删除或丢失的 URL。
有四个列和过滤器可以帮助分割移动到选项卡和过滤器中的 URL。
Added – 上次抓取中的 URL 移动到当前抓取的过滤器中。
New – 上次抓取中没有的新 URL,但在当前抓取和过滤器中。
Removed – 上次抓取的过滤器中的 URL,但不在当前抓取的过滤器中。
Missing – 在当前抓取中未找到的 URL,以前在过滤器中。
本质上,“added”和“removed”是当前和以前的抓取中都存在的 URL,而“new”和“missing”是仅存在于其中一个抓取中的 URL。
完成抓取比较后,一个小的比较文件会自动存储在“File > Crawls”中,这允许您打开和查看它,而无需再次运行分析。
此文件利用了比较的两个抓取。因此,需要存储这两个抓取才能查看比较。删除比较中的一个或两个抓取将意味着无法再访问该比较。
请参阅我们关于“如何比较抓取”的教程以获取更多信息。
APIs 模式
APIs 模式允许您上传 URL 并从任何 API 中提取数据,而无需进行任何抓取,从而提高速度。
它允许您连接到 Google Analytics, Search Console, PageSpeed Insights, Majestic, Ahrefs 和 Moz。